力扣106:从中序与后序遍历序列构造二叉树
力扣106:从中序与后序遍历序列构造二叉树
- 题目
- 思路
- 代码
题目
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
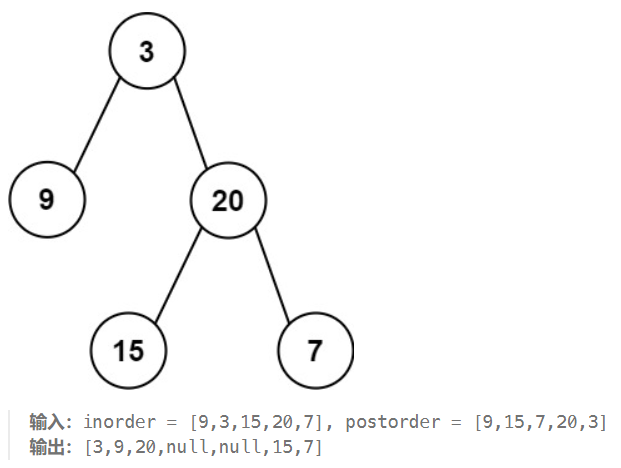
思路
我们首先要知道中序遍历和后序遍历分别都是什么。
中序遍历是依照左子树,根节点,右子树的顺序来进行遍历。
后序遍历是依照左子树,右子树,根节点的顺序来进行遍历。
我们观察这两个遍历得到的数组看能得到什么信息,首先最明显的是我们通过后序遍历可以确定整个二叉树的根节点也就是后序数组的最后一个位置除此之外也没啥了,接下来是中序数组,中序数组乍一看没啥信息可言但是我们来看其中根节点的位置,再看它的左边和右边我们可以发现整个数组我们只要确定了根节点的位置就可以划分成三部分:左子树,根节点和右子树。那么再找到左子树和右子树的根节点不就可以继续划分下去了吗直到根节点是一个叶子节点没有左子树和右子树。这不就是分治的思想吗,先进行拆分再进行组合。所以这道题我们可以使用分治来做,从根节点开始构建节点然后再构建左子树再构建右子树,同样左子树的根节点继续构建它的两个子树。
在这个过程中我们必须要有两个信息:每次构建时根节点的值以及左右子树在中序数组的范围。
首先是根节点的值,这个我们可以通过后序数组来得到,右子树的根节点下标我们只需要在当前的下标进行–就可以得到了,重点是左子树的根节点的下标。
代码
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:unordered_map<int,int> um;TreeNode* merge(int root,int left,int right,vector<int>& postorder){//结束的条件是左子树的下标不小于右子树if(left > right){return nullptr;}//构建节点TreeNode* node = new TreeNode(postorder[root]);//得到root位置在中序遍历的下标int i = um[postorder[root]];//构建左子树和右子树//重点解释一下左子树的根节点怎么找//我们肯定也是在后序数组中找其次后序是左,右,根的顺序//左子树的根节点和当前树的根节点只差了一个右子树的长度//所以我们通过中序数组来找到右子树的长度也就是right-i//因为right是有边界,i是根节点在中序数组的下标所以right-i就是右子树的长度//在减去右子树的数量后我们还需要减1node->left = merge(root-(right-i)-1,left,i-1,postorder);node->right = merge(root-1,i+1,right,postorder);return node;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {//通过后序遍历我们可以确定根节点的位置//通过中序遍历我们可以得到该节点的左子树和右子树//所以我们可以使用分治的办法将一棵树从根节点开始向下构建for(int i = 0;i < inorder.size();i++){//记录在中序遍历中节点的值所对应的下标um[inorder[i]] = i;}return merge(postorder.size()-1,0,inorder.size()-1,postorder);}
};