李宏毅深度学习教程 第10-11章 自监督学习self-supervised learning+自编码器
【2025版】22、第七节 自监督式学习 一 – 芝麻街与进击的巨人_哔哩哔哩_bilibili
目录
1. BERT 来自 Transformers 的双向编码器表示
1.1 使用方式 - 微调
1.2 有用的原因
1.3 多语言 BERT(multi-lingual)
1.4 语音图片上的自监督学习
2. 生成式预训练 GPT(应用于文本生成写作)
3. 自编码器
3.1 去噪自编码器
4. 自编码器的应用
4.1 语音特征解耦
4.2 离散隐表征
4.3 VQ-VAE 向量量化-变分自编码器
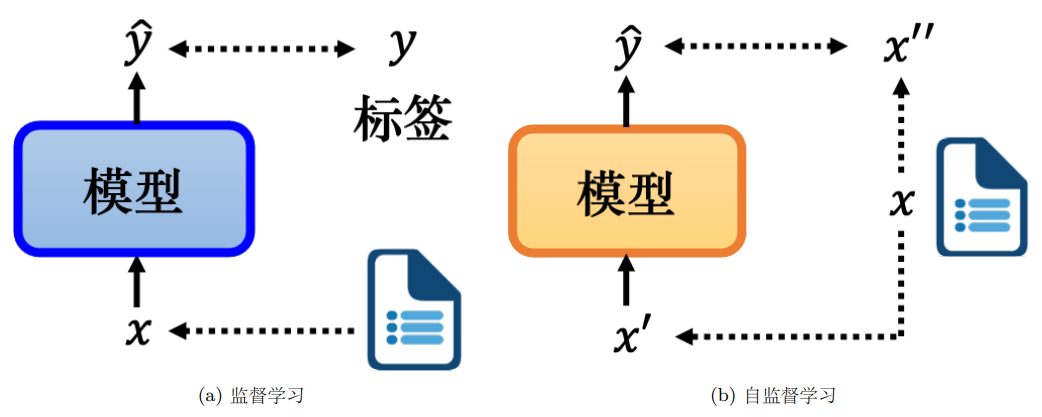
自监督学习:我们有未标注的文章数据,则可将一篇文章 x分为两部分:模型的输入 x ′ 和模型的标签 x ′′,将 x ′ 输入模型并让它输出 yˆ,想让 yˆ 尽可能地接近它的标签 x ′′(输出预测抽出部分)
1. BERT 来自 Transformers 的双向编码器表示
后文例子均为 NLP中的文本处理任务。BERT可以处理序列 当然也可以处理语音、图像等。
自监督预训练 两个任务:
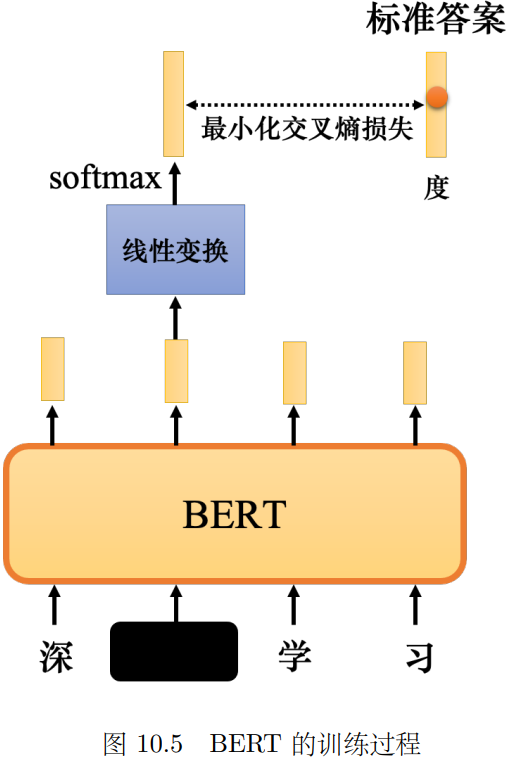
1. Masked掩码/替换一些字 让它完形填空; (破坏方式也可以为 插入删除打乱等等)
比如让它预测“度” 最小化交叉熵损失
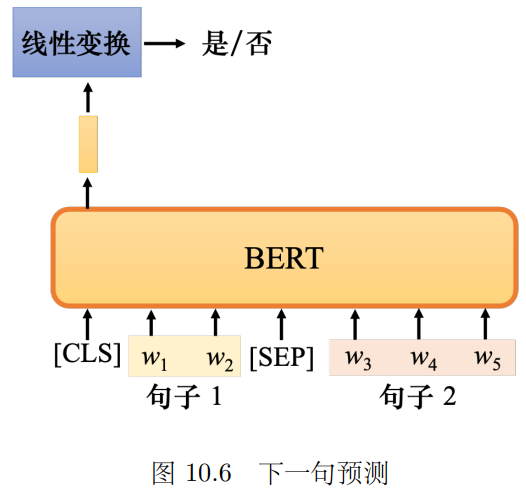
2. 判断B是不是A的下一句话 升级版为打乱句子顺序让它排序(句序预测SOP)
特殊符号有 [MASK]:填空占位符 [SEP]:分隔句子 [CLS]:分类标记
1.1 使用方式 - 微调
先通过两个任务 预训练出BERT 评估BERT的预训练效果:在一些任务集上 看他表现的平均值
经典的有 GLUE、 XLNET任务 比较人-机表现
想让它更深入地学习某项任务,需要再给一些标注数据 进行微调(fine-tuning)
预训练BERT是无监督的 下游任务微调时需要有标注的数据 整体看来是半监督的
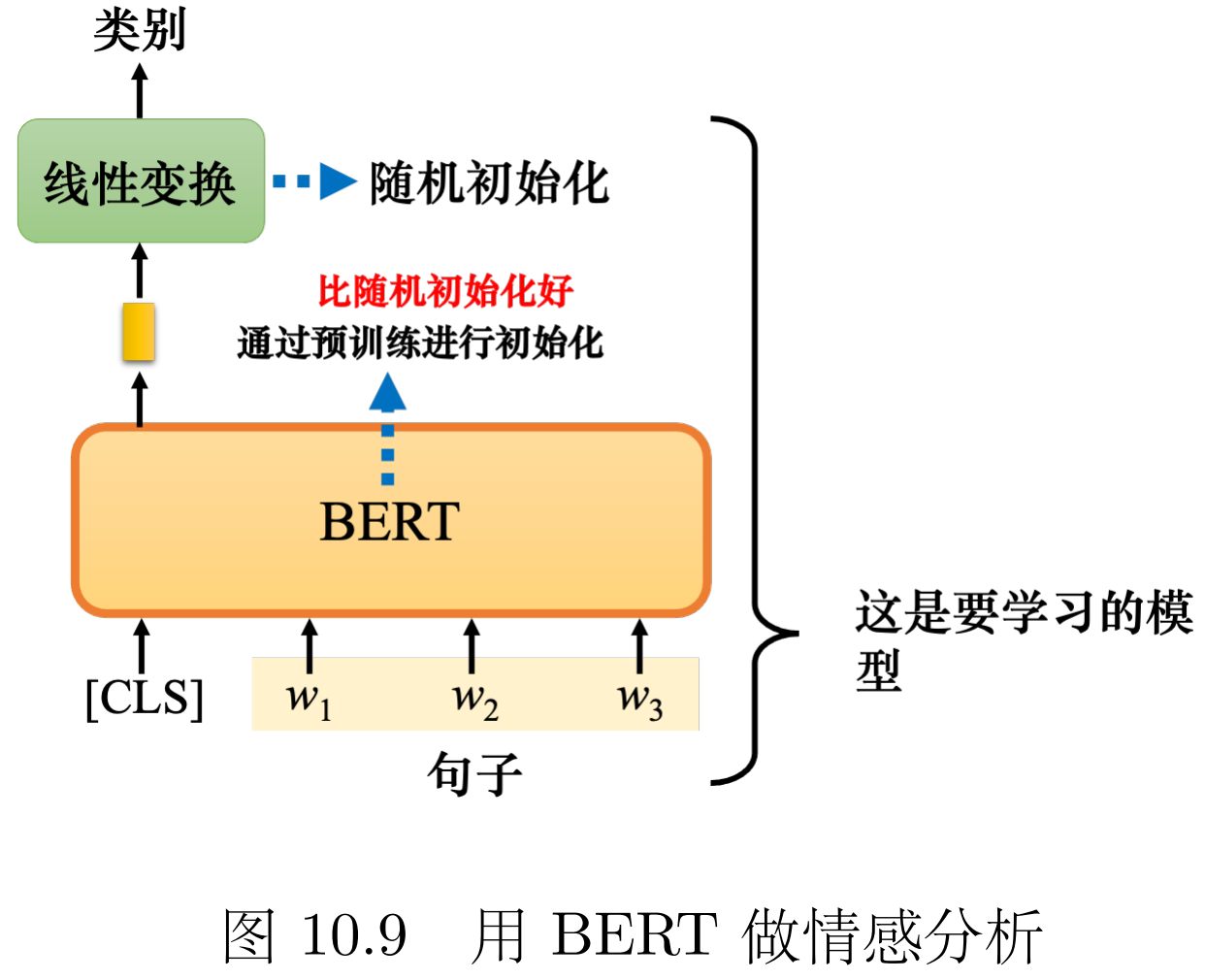
情形1:情感分析 判断句子是正面还是负面的 把[CLS]放在一个句子前 再把对应的向量线性变换
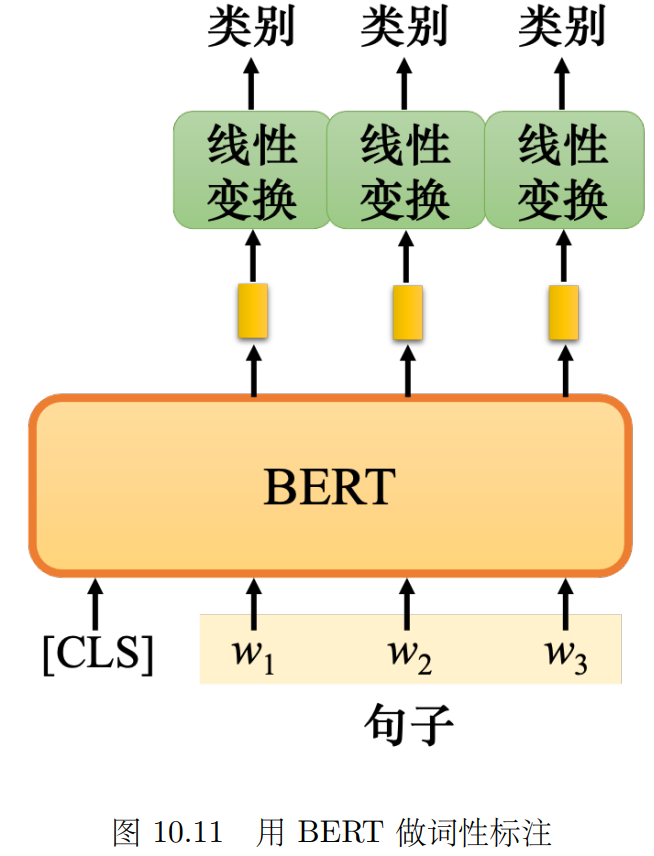
情形2:词性标注 把句子中每个词分类成 动词/名词/形容词等 把[CLS]放在一个句子前 输出向量对应每个词的类别
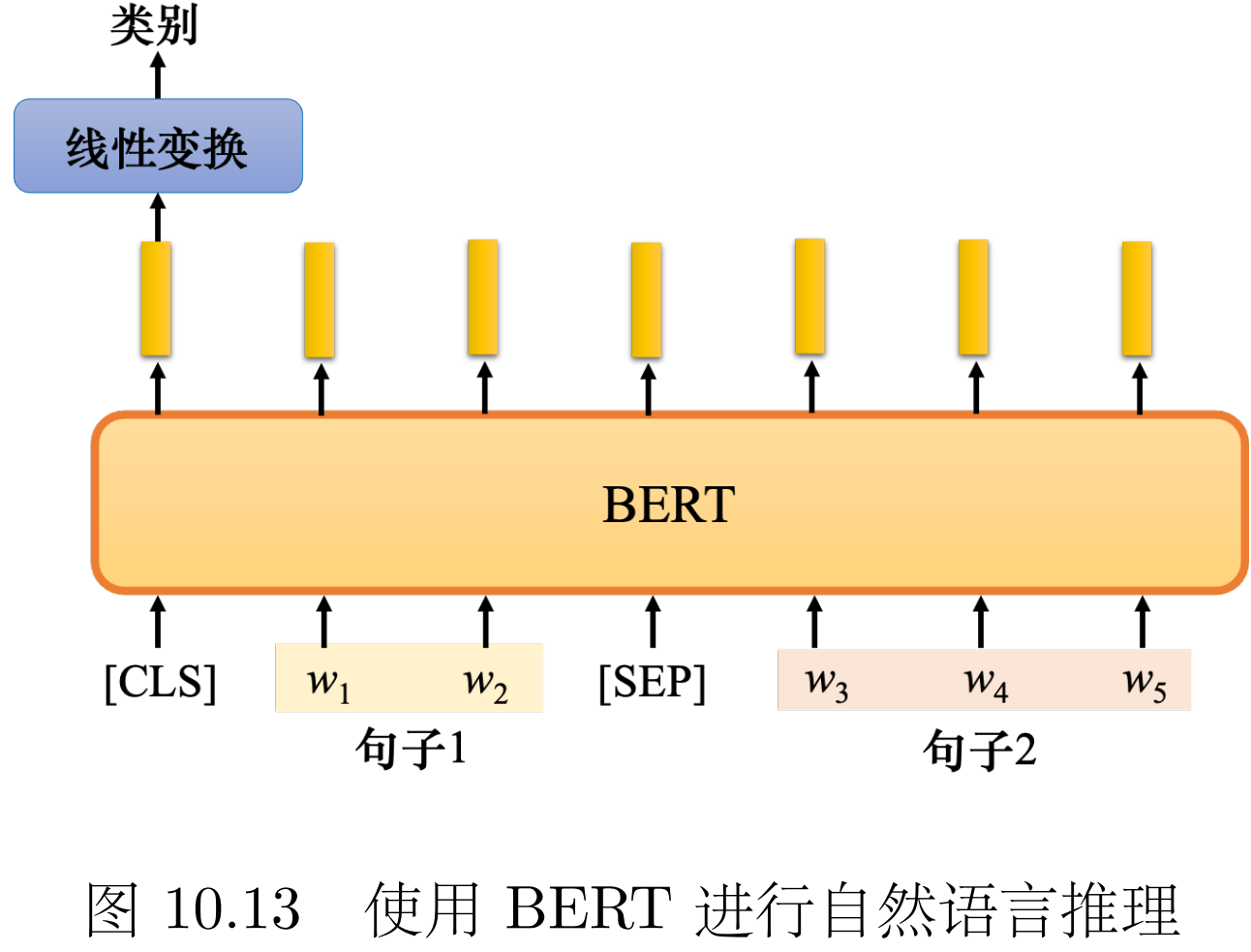
情形3:自然语言推理 逻辑判断 判断文本A和文本B的关系 如是否能由A推出B A和B是否矛盾等
可用于立场分析 文章后的留言是支持文章还是反对:只需把文章作为A 留言最为B 让模型输出关系
可用[SEP]分隔两句话,[CLS]位置输出判断结果
情形4:基于提取的问答(答案一定是文章中的一个片段) 文章D 问题Q 分别对应两个序列,
要求输出两个正整数s e,代表第 s 个单词到第 e 个单词的片段就是正确答案。
做内积训练橙色向量和蓝色向量;分别找开头s位置和结尾d位置
1.2 有用的原因
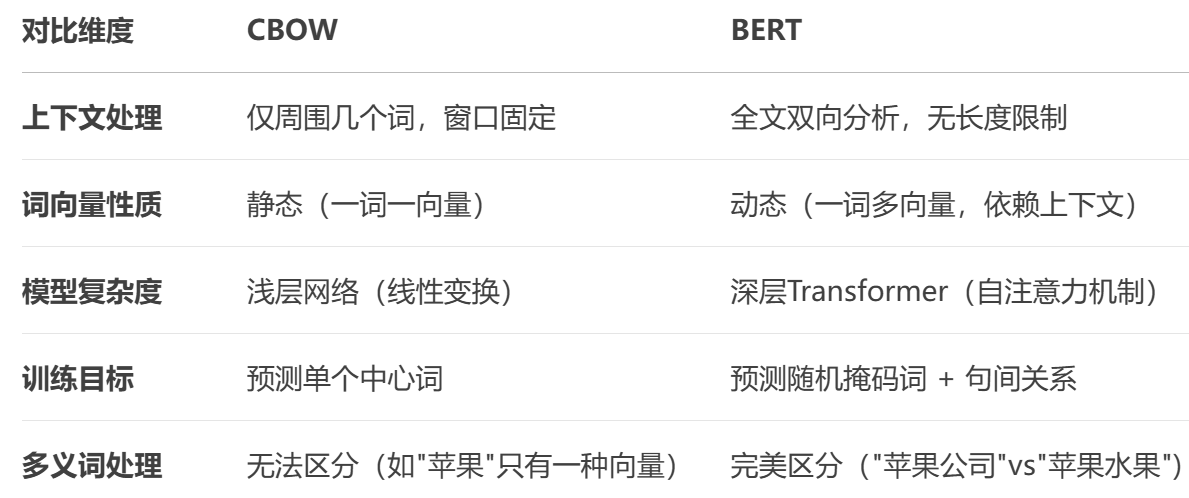
传统静态词向量(如Word2Vec)无论上下文,"苹果"的向量永远相同。
→ 问题:无法区分"吃苹果"(水果)和"苹果手机"(品牌)。
BERT的动态词向量 语境化嵌入(Contextual Embedding): → 根据上下文实时更新词意。
→ 示例: 输入"喝苹果汁" → "果"的向量靠近"橙子、葡萄"(水果类)。
输入"苹果发布会" → "果"的向量靠近"三星、华为"(品牌类)。
计算这两类苹果 余弦相似度矩阵。 可以发现前五个之间相似度高,后五个之间相似度高。
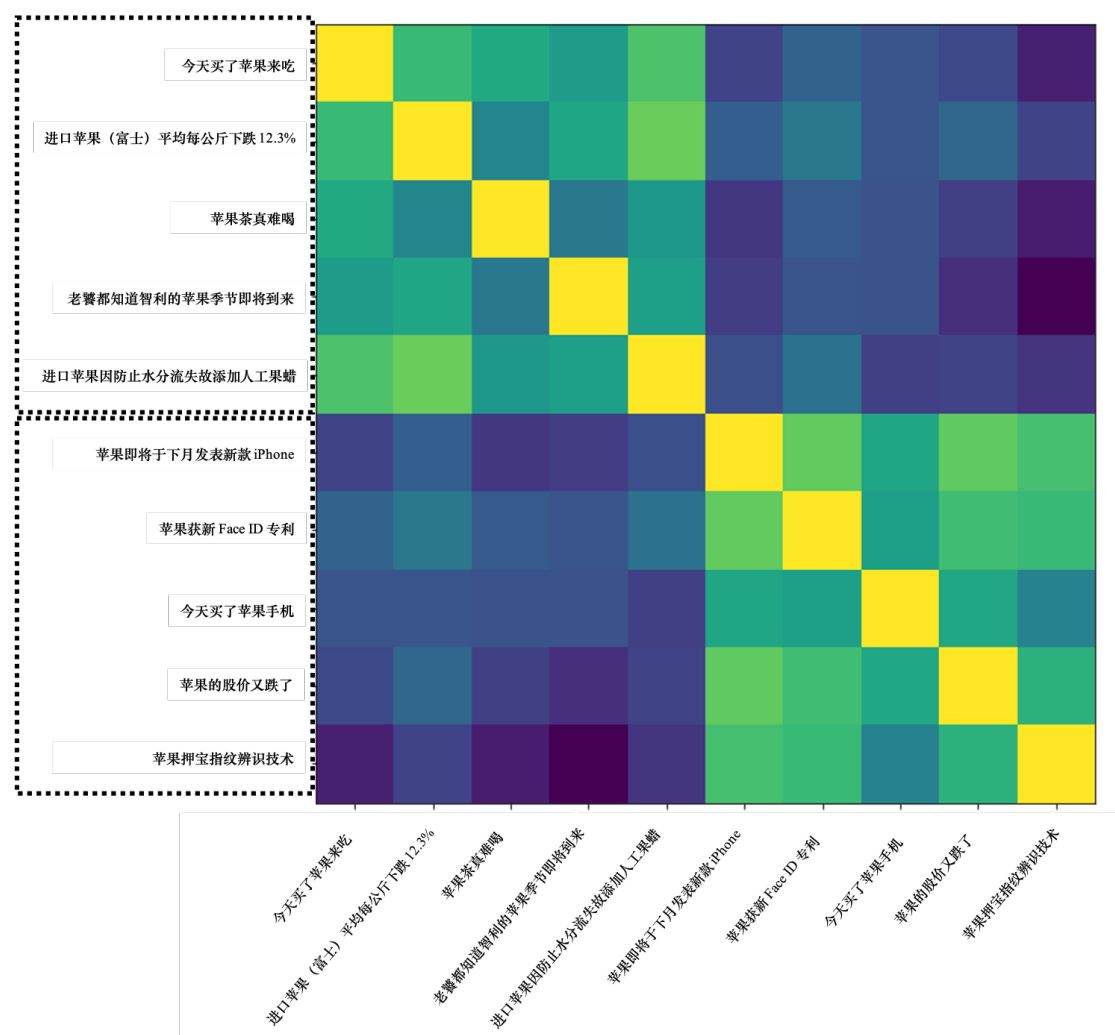
一个词的意思取决于它的上下文,可以通过经常和它一起出现的词 判断它的词意
BERT的填空训练: → 任务:给定"深[MASK]学习很有趣",预测"度"。
→ 如何猜中?必须从上下文("深"、"学习")提取语义线索 → 被迫学会理解词义关系!
词嵌入中 连续词袋CBOW 是线性简单版本(浅层神经网络预测中心词)静态词向量
还可以对DNA/音乐 编码碱基/氨基酸/音符为单词等 转化为语言模型问题
优势:BERT相对于直接监督学习 预训练了很好的初始化参数 使得后续训练更容易收敛
1.3 多语言 BERT(multi-lingual)
多语言 BERT 有非常神奇的功能,如果用英文问答数据训练它,它会自动学习如何做中文问答
训练时 中文英文相同意思的词的词嵌入向量距离很近 比如跳和 jump;鱼和 fish;游和 swim
所有英文单词的嵌入平均 - 所有中文单词的嵌入平均 = 英文与中文的差距 即可实现中英文互转。
但不会出现问英文问题回答中文的情况 可能因为BERT知道语言符号信息

作用:可以打破语言壁垒 训练一种语言 其他语言也收益。
此外可以训练数据比较多的语言如英语 带动数据比较少的冷僻的语言进步
1.4 语音图片上的自监督学习
自监督学习应用到语音训练上,要mask一长串的feature,不要一次只mask一个feature,迫使机器去解比较难的问题。因为声音相邻向量往往内容非常接近,任务太简单学不到东西。
自监督学习 应用到图片就是 拆分一张图为几个部分,问机器两个部分的位置关系。

对比学习(contrastive learning) 目标:让模型学会区分"相似"和"不相似"的数据
正样本对:同一图片的不同视角(如裁剪/旋转后的版本) 负样本对:不同图片(如猫和狗的图片)。
训练方式有:SimCLR:拉近正样本对,拉远负样本对。
MoCo:用动态队列存储负样本,增加对比难度。

为提高训练效果 训练时拿出来的两张异类图需要比较接近(难区分)
比如我要训练猫相关的 我拿苹果的图片 太不一样 很容易就区分并且学不到关键的特征
可以拿老虎 豹子等图片去训练猫
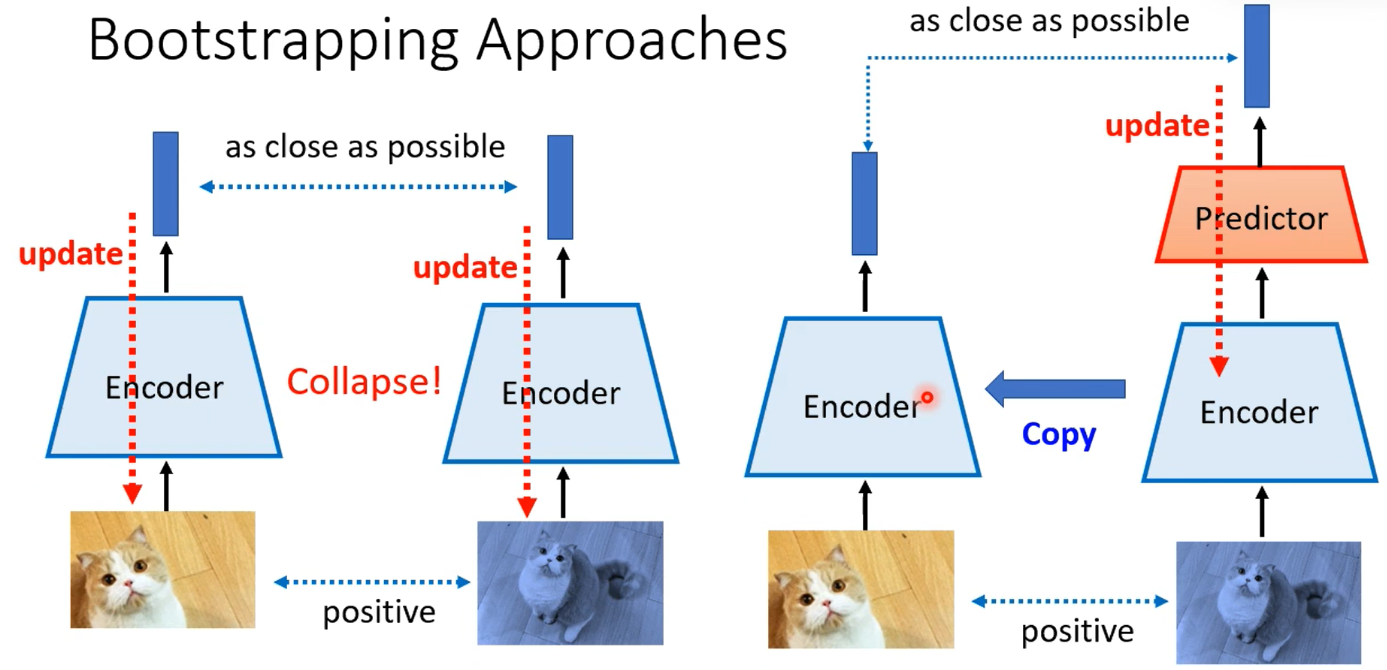
所以异类选择要注意 那如果不用异类呢?只学习拉近正类(不用异类)会出现坍塌的问题
反正要的就是要正类尽可能像(而且没有拉远的需求) 直接把所有点放一起
只用正类不用异类 还有一种 Bootstrapping Approaches 操作,
一边有predictor 再copy到另一边。 利用架构不同 不会坍塌 并且只需要正类的数据
2. 生成式预训练 GPT(应用于文本生成写作)
GPT自监督学习时要做的任务是 只根据上文预测下一个词。 基于Transformer解码器 掩码注意力
输入:"<BOS> 深" → 预测 "度" 输入:"<BOS> 深 度" → 预测 "学"
还需研究如何把这种 “接龙”创作能力应用到下游任务。
语境学习 如何让GPT学会翻译任务? 不微调模型,直接通过举例提示让GPT理解任务。

生成功能应用到: 生成语音(预测下一段声音讯号) 生成图像(预测下一个像素)
3. 自编码器
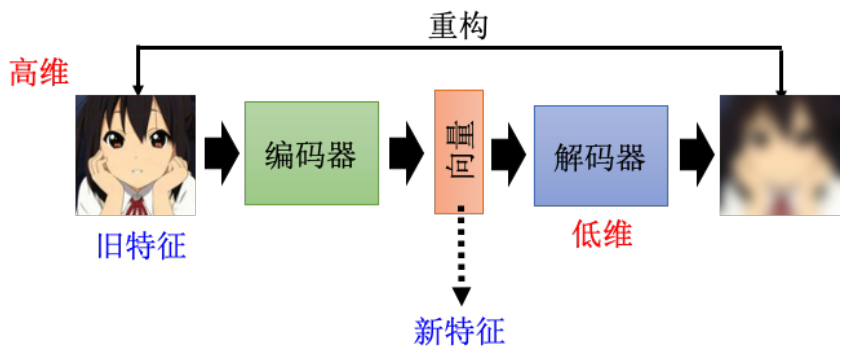
编码器压缩 解码器重构;希望重构后的结果接近最开始的输出(类似Cycle GAN)
自编码器可以实现很好的降维 发掘数据的内在联系 化繁为简
中间降低到的最低维度 称为瓶颈bottleneck
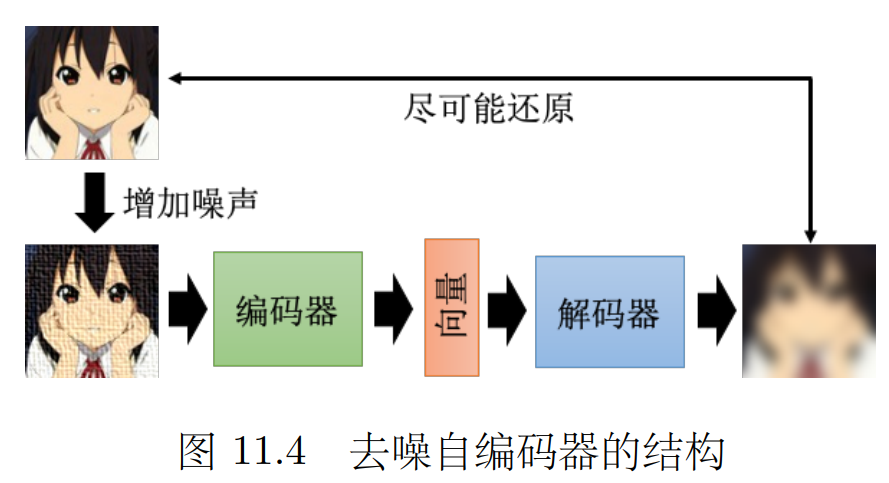
3.1 去噪自编码器
可以在压缩过程中过滤掉 无关信息(噪声) 进而在还原时还原出去噪的图像
4. 自编码器的应用
编码器单独拿出来 就是一个压缩器;解码器单独拿出来 就是一个生成器
4.1 语音特征解耦
特征解耦:在训练一个自编码器的时候, 知道嵌入的哪些维度代表了哪些信息。
比如 100 维的向量, 知道前 50 维代表这句话的内容,后 50 维代表了说话人的特征。
生成的语音有多个特征(内容/风格/音色等) 解码器可以把一个向量转化成一个复杂的东西
所以我们想 给这个向量压缩一些我们想要的特征 再让它解码
如果想实现一个变声器 即要求输出 A的内容 B的音色的音频
一种训练方式是 找很多组成对的“文本-目标人物说这句话的音频” 但找很多这样的训练数据不切实际。
特征解耦操作 提取出A的内容 压缩成针对内容的向量;提取B的音色 压缩成针对音色的向量
再把这两个向量拼在一起 送到解码器去解码。
4.2 离散隐表征
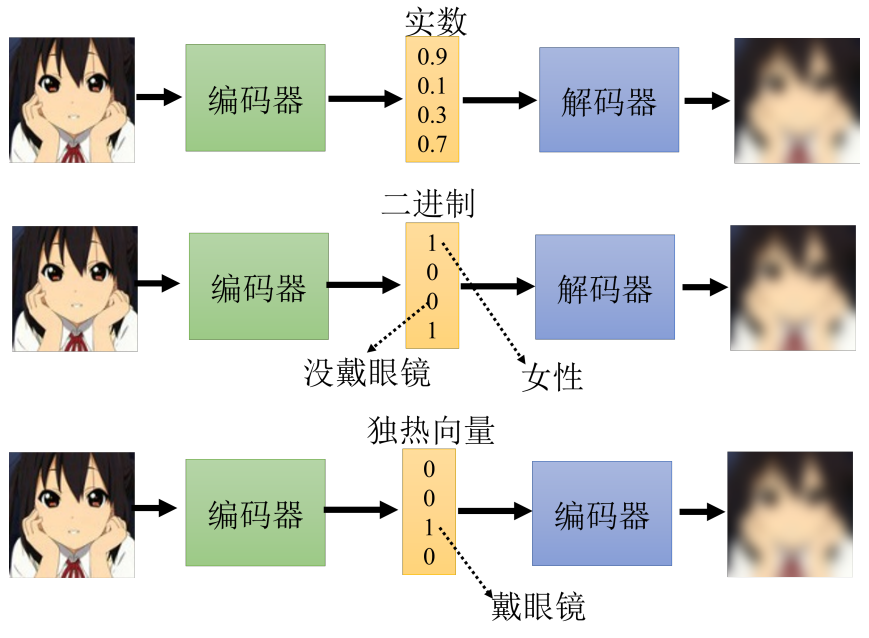
嵌入如果没有要求的话输出实数,但不用解码器就很难挖掘其实际意义
可以限制嵌入 只输出0-1 就可以做一些特征的二分类(比如男/女 是否戴眼镜之类)
如果限制嵌入为 独热编码,只有一个位置为1 就可以转化为分类问题
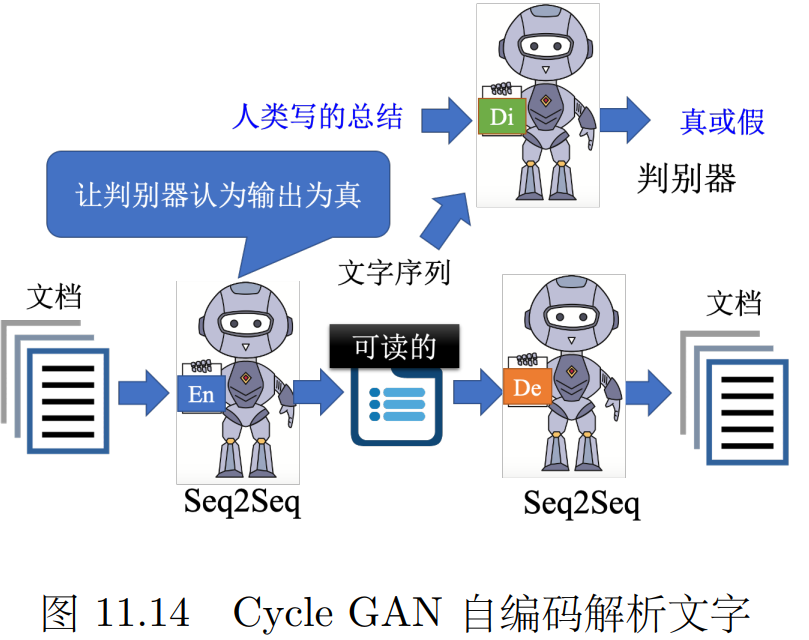
如果限制嵌入为一段文字,就可以起到压缩文字(写概要)的效果。
问题是 输出的这个压缩版本不一定是 “人类写的总结”风格的 有可能会冒出奇奇怪怪的符号,
所以可以加一个GAN 判别器用来判断 使得这个压缩版本接近人类写的风格。
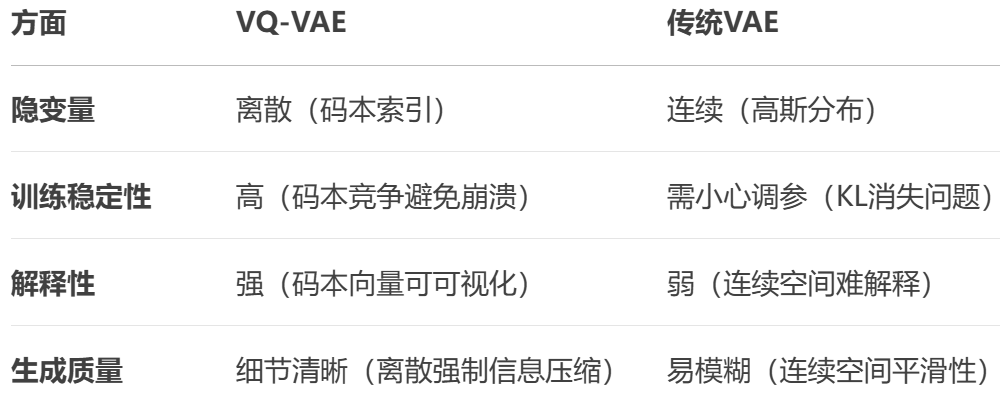
4.3 VQ-VAE 向量量化-变分自编码器
将编码器输出 替换为码本中最近邻的向量,再送给解码器。
离散化迫使模型学习有意义的原型特征,避免连续空间中的"模糊表达"。
如音标/拼音本身只有固定的那些种类,使得生成的音频更准确。
在图像中 连续化可能使得输出是模糊的 而压缩向量的离散化可以使得输出质量更高。

![]()
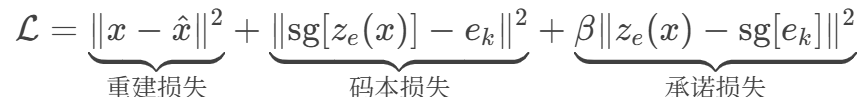
![]()
编码器梯度:通过重建损失 + 承诺损失反向传播 码本梯度:仅通过码本损失更新