课题学习4——将原系统的BERT换为SBERT
1 引言
本周任务
- 调查SBERT训练集为软标记还是硬标记
- 将系统中的BERT换为SBERT用于生成词向量
- 分析系统性能是否提升
2 SBERT训练集格式
自然语言推理(NLI)数据格式:由句子对和逻辑关系标签组成,标签分为蕴含(Entailment)、矛盾(Contradiction)、中性(Neutral) 。如 “Sentence 1, Sentence 2, Label” 形式
语义文本相似度(STS)数据格式:包含句子对及 0 - 5 范围的相似度分数,“0” 表示完全不相关,“5” 表示句子完全等价 。数据按 “Sentence 1, Sentence 2, Similarity Score” 格式呈现,模型通过最小化相似度预测值与真实值之间的误差进行优化。
对比学习数据格式:采用三元组形式,即 Anchor(锚点句子)、Positive(与 Anchor 语义相似的正例)、Negative(与 Anchor 语义不相似的负例) 。比如 “A man is eating, Someone is eating, A dog is barking”。训练目标是增大 Anchor 和 Positive 之间的相似度,减小 Anchor 和 Negative 之间的相似度。
自监督学习数据格式:基于单句子和数据增强生成的句子对,即 “Original Sentence, Augmented Sentence” 。例如对 “猫喜欢吃鱼” 进行同义词替换得到 “猫咪喜爱吃鱼”,形成自监督学习数据对。自监督目标是最大化增强句子对的相似性,最小化随机句子对的相似性。
2 BERT换为SBERT
2.1 模型选择
优先选择 支持中文的 SBERT 模型:
paraphrase-multilingual-MiniLM-L12-v2(轻量高效,适合中小数据集)paraphrase-multilingual-mpnet-base-v2(精度更高,适合大数据集)
2.2 安装依赖
pip install sentence-transformers flask jieba numpy原始系统测试

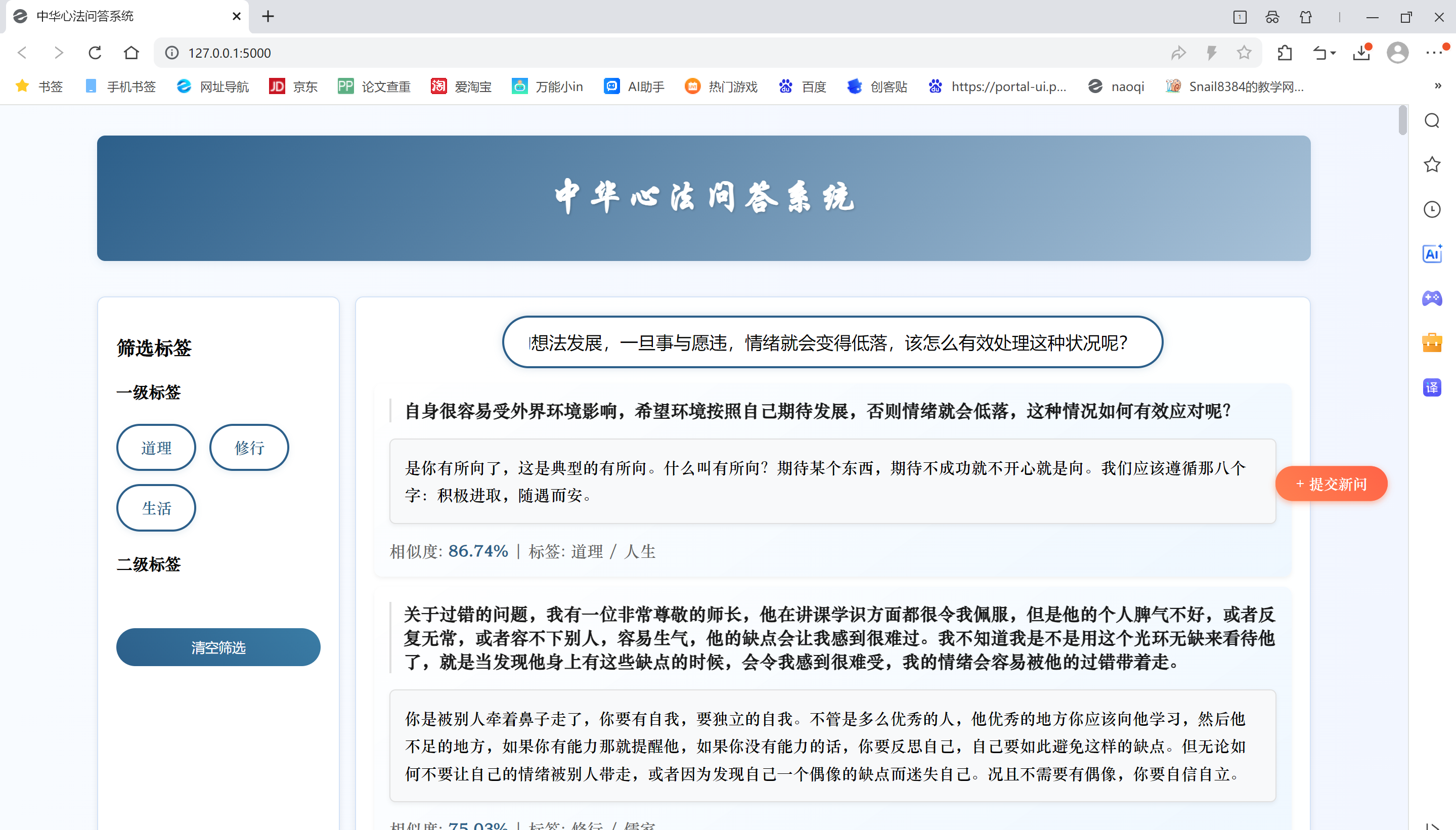
2.3 all-MiniLM-L6-v2
SBERT 的encode方法直接返回句子向量,无需处理 BERT 的隐藏层(hidden_states),因此可以删除代码中与LAYER_WEIGHTS相关的融合逻辑(如_get_embedding和_prepare_vectors中对多层隐藏状态的加权计算)。
# 替换BERT模型加载和向量生成部分
from sentence_transformers import SentenceTransformerclass QASystem:def __init__(self, config: Config):self.config = config# 加载SBERT模型(替换原BERT模型)self.model = SentenceTransformer('all-MiniLM-L6-v2') # 轻量级SBERT模型self._load_data()self._prepare_vectors() # 生成句子向量(无需权重融合)def _get_embedding(self, text: str) -> np.ndarray:# SBERT直接输出句子向量,无需处理隐藏层return self.model.encode(text, convert_to_numpy=True)def _prepare_vectors(self):# 批量生成所有问题的向量questions = [pair["cleaned_question"] for pair in self.qa_pairs]self.question_vectors = self.model.encode(questions, convert_to_numpy=True)修改后测试

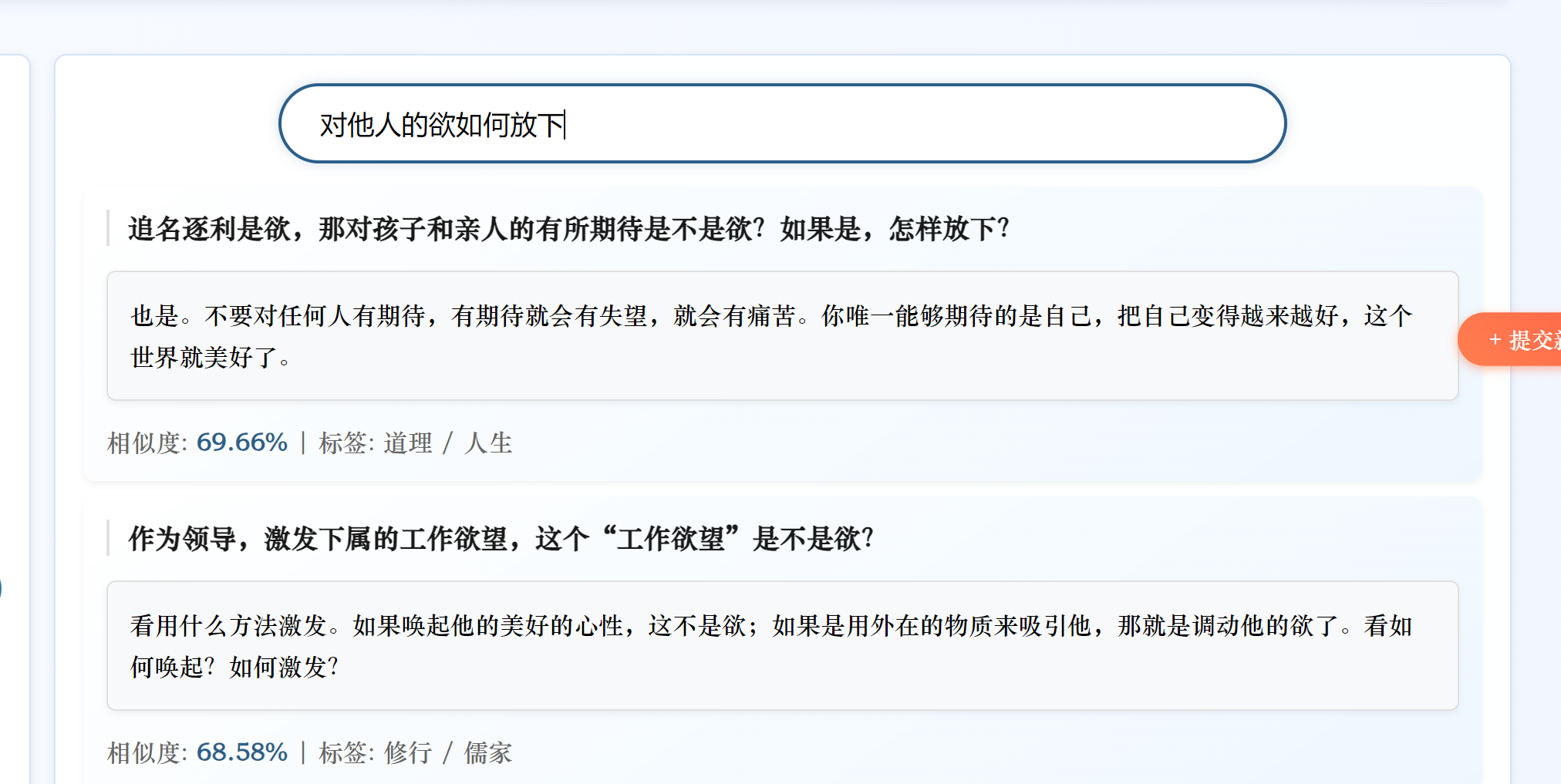
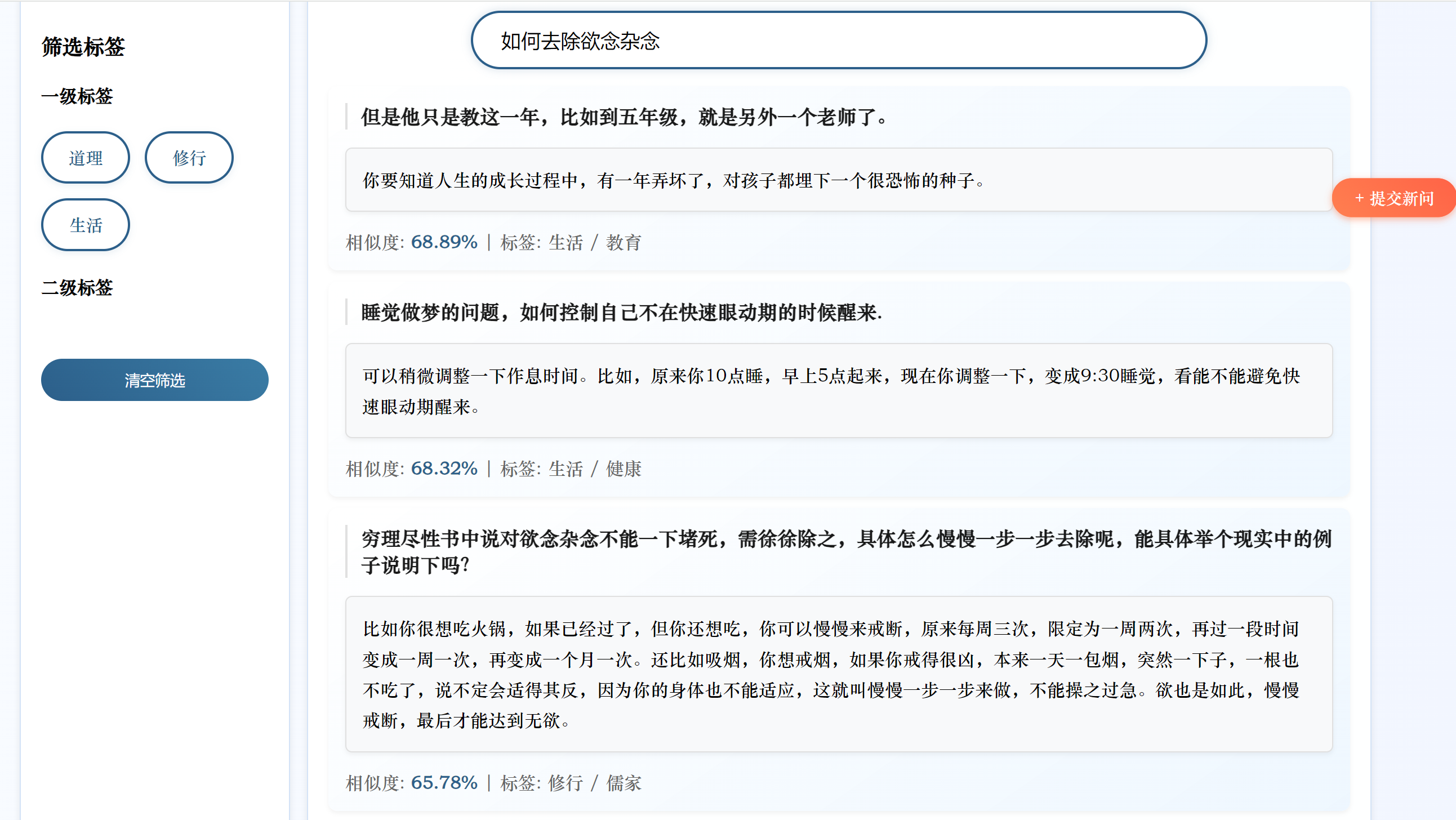
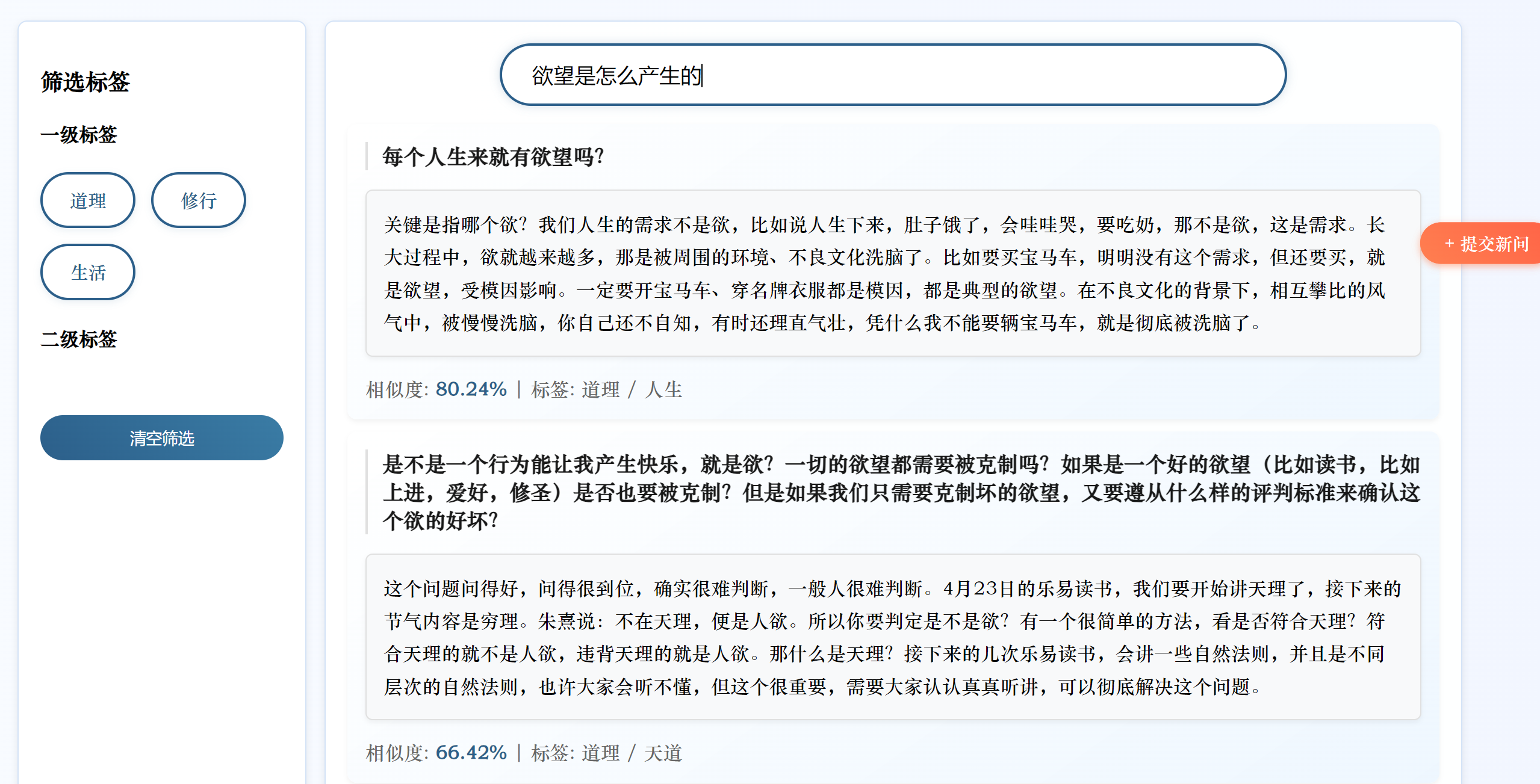
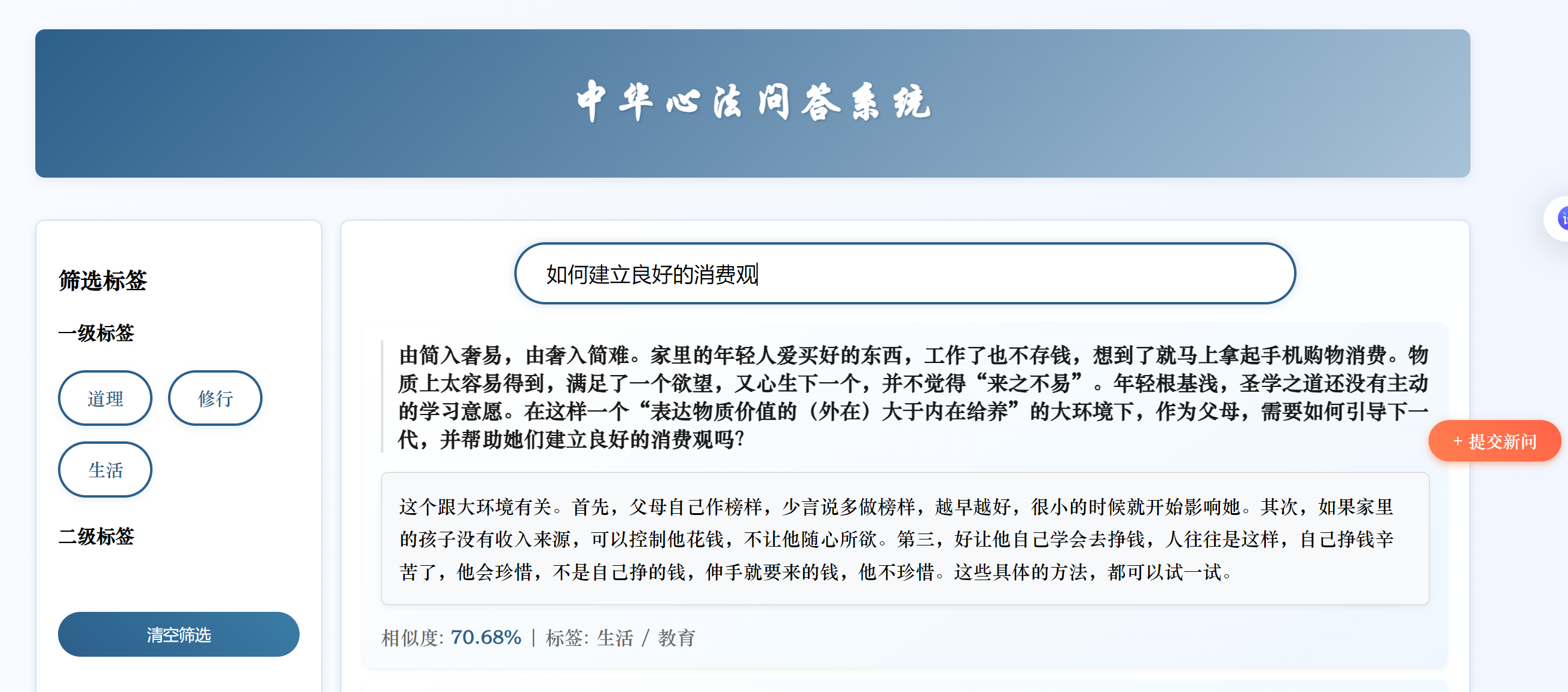
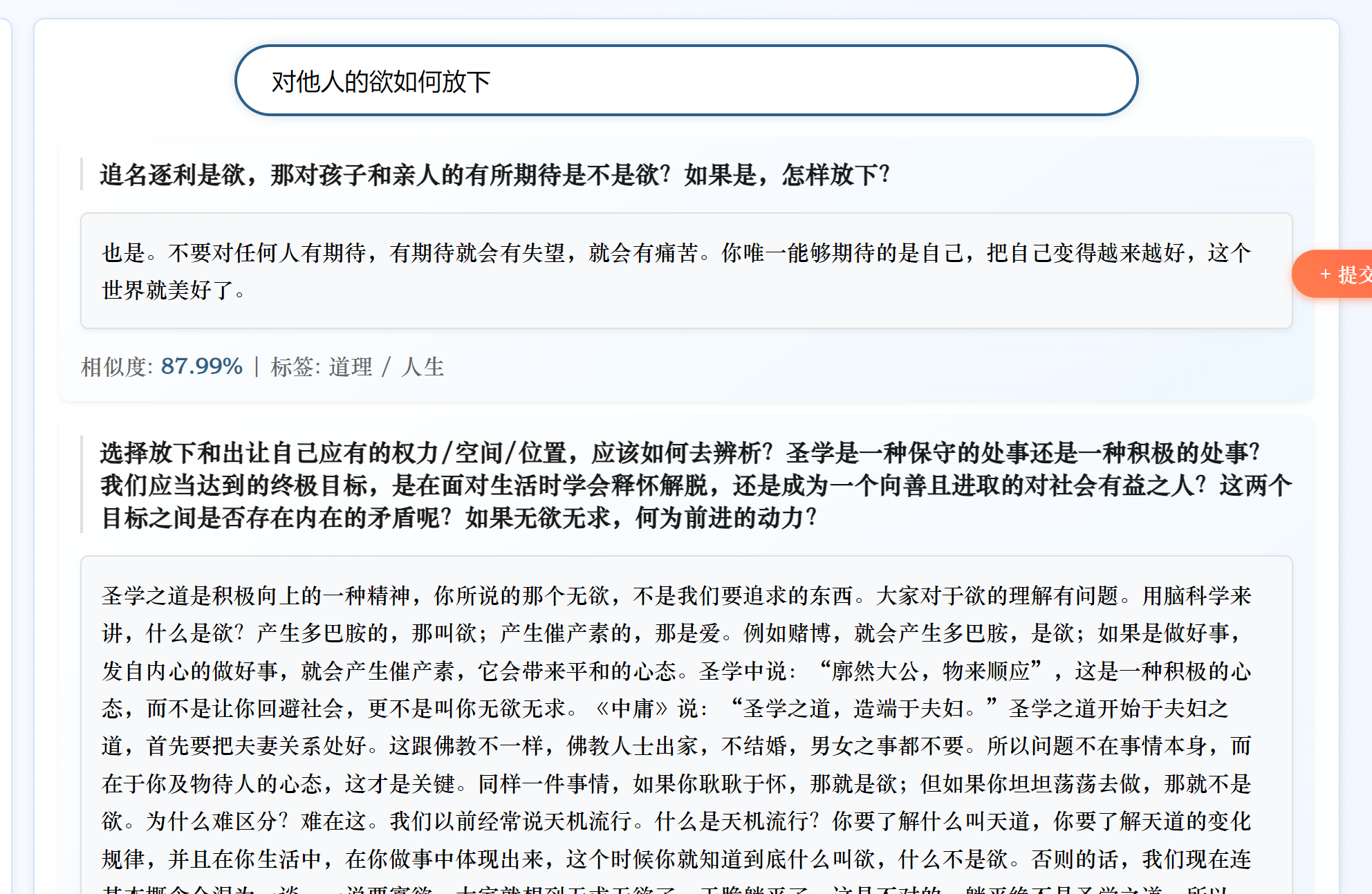
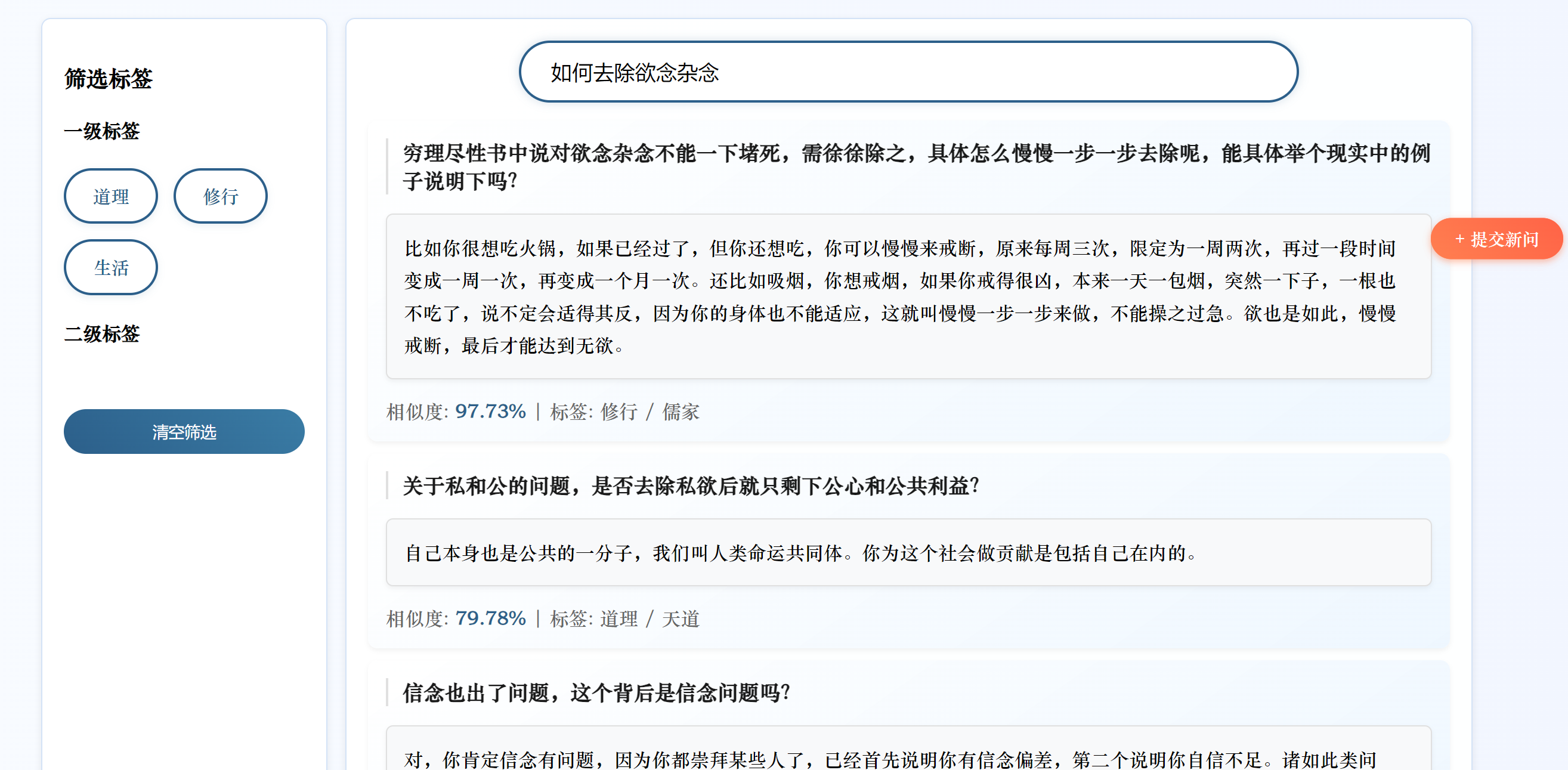
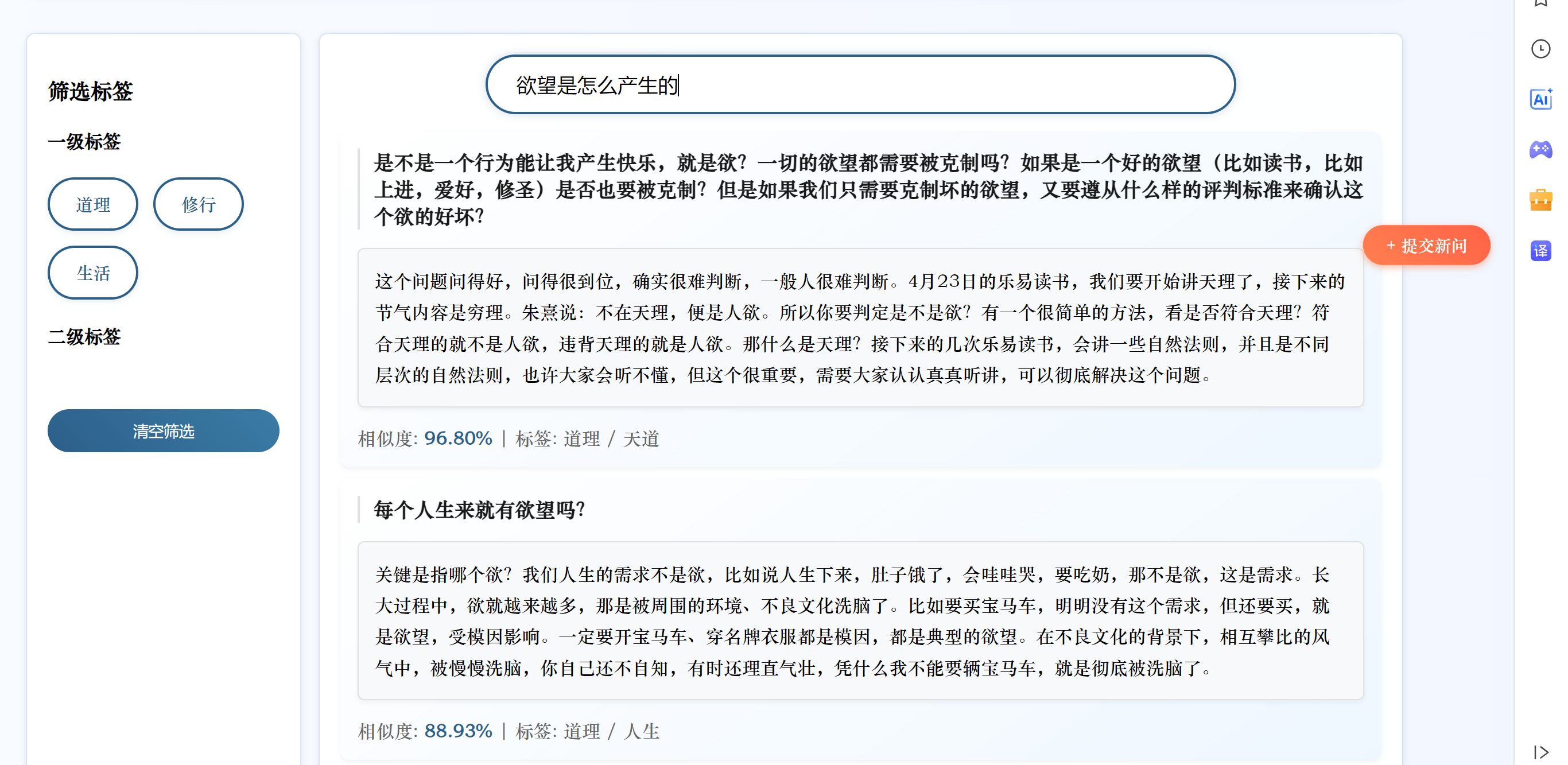
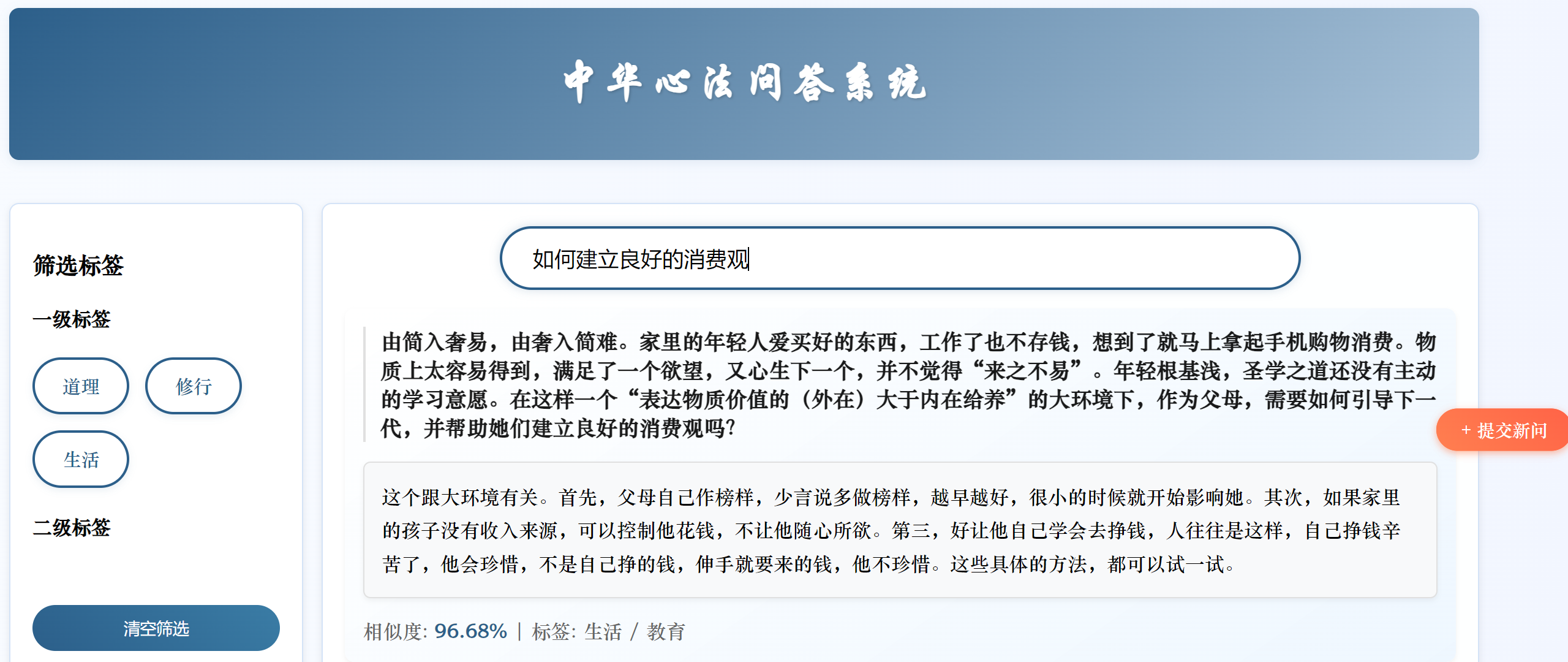
今天只是简单地将BERT换成了SBERT,未进行微调。我将原始问题中提取一部分进行测试,虽然匹配到的是同一个答案,但是相似度变低了,我无法判断这是SBERT对输入的问题产生了理解更深更贴近这个问题本身的向量还是SBERT生成的向量语义更不准确的缘故。
我将原有的问题换一种表达方式,修改后的系统无法匹配到正确答案
分析原因:
- 使用的
all-MiniLM-L6-v2是轻量级 SBERT 模型(6 层 Transformer,384 维向量),参数规模远小于原始 BERT(12 层,768 维)。对于复杂语义或专业领域(如 “心法问答” 涉及传统文化术语),轻量级模型可能难以捕捉细微语义差异,导致准确率下降。- 原始 BERT 代码中,融合了语义向量相似度和关键词匹配权重(
0.7*similarities + 0.3*keyword_weights),这种混合策略可能在系统中更有效。替换为 SBERT 后,虽然保留了关键词融合逻辑,但 SBERT 的向量空间与 BERT 不同,若未重新调整权重比例(如0.7和0.3的比例是否适配 SBERT),可能导致融合效果下降。
2.4 paraphrase-multilingual-mpnet-base-v2
| 模型 | 优势 | 劣势 | 对你的场景适配性 |
|---|---|---|---|
all-MiniLM-L6-v2 | 速度快、轻量 | 语义捕捉能力有限,对复杂中文场景适配弱 | 中(适合快速测试,精度一般) |
paraphrase-multilingual-mpnet-base-v2 | 多语言支持强,语义理解深,对同义异构问题敏感 | 速度略慢,模型体积较大 | 高(适合中文复杂语义匹配) |
all-mpnet-base-v2 | 英文语义匹配强 | 中文支持弱于多语言版本 | 中高(英文场景更优) |
Transformer 基座模型不同
all-MiniLM-L6-v2:编码部分基于MiniLM架构(一种轻量级 Transformer),仅包含 6 层 Transformer 编码器(“L6” 即 6 层),参数少(约 2300 万),计算效率高,但捕捉复杂语义的能力较弱。
all-mpnet-base-v2:编码部分基于MPNet架构(融合了 BERT 和 XLNet 的优势,对长距离依赖更敏感),包含 12 层 Transformer 编码器,参数约 1.1 亿,编码能力更强,能捕捉更细腻的语义关系。
paraphrase-multilingual-mpnet-base-v2:编码部分基于多语言 MPNet(可理解为 MPNet 的跨语言版本,结合了 XLM-R 的多语言训练数据),同样是 12 层 Transformer 编码器,但训练数据覆盖 50 + 语言,编码时能更好地对齐不同语言的语义空间。
修改点
- 移除原生 BERT 模型及手动向量生成代码(如隐藏层融合、自定义层权重计算),改用
SentenceTransformer加载paraphrase-multilingual-mpnet-base-v2模型,直接通过model.encode()生成句子向量。 - 向量标准化:用
sklearn.preprocessing.normalize批量处理向量,替代原手动计算 L2 范数的方式,提升效率。 - 移除原 Sigmoid 函数校准及复杂权重融合(如
0.2*raw_similarities + 0.8*calibrated),改用向量点积计算相似度,并通过np.clip限制范围在 [0,1]。 - 将原来的0.7余弦相似度+0.3关键词匹配改为0.8余弦相似度+0.2关键词匹配,因为SBERT生成的句向量已经能较好区分语义
SBERT 生成的向量经过预训练优化,其余弦相似度本身已在合理范围(通常集中在 [-1,1]),且分布更符合语义匹配的实际需求。而 Sigmoid 转换是针对 BERT 向量的特性设计的校准手段,对 SBERT 来说并非必需。
Sigmoid 函数会将数值挤压到 [0,1] 区间,且在极端值附近梯度平缓,可能弱化原本显著的相似度差异。例如,0.8 和 0.9 的原始相似度经 Sigmoid 处理后,差异可能被缩小,影响排序准确性。而 SBERT 的原始相似度已能较好区分语义远近,直接用
np.clip限制范围更简单有效。
修改后测试

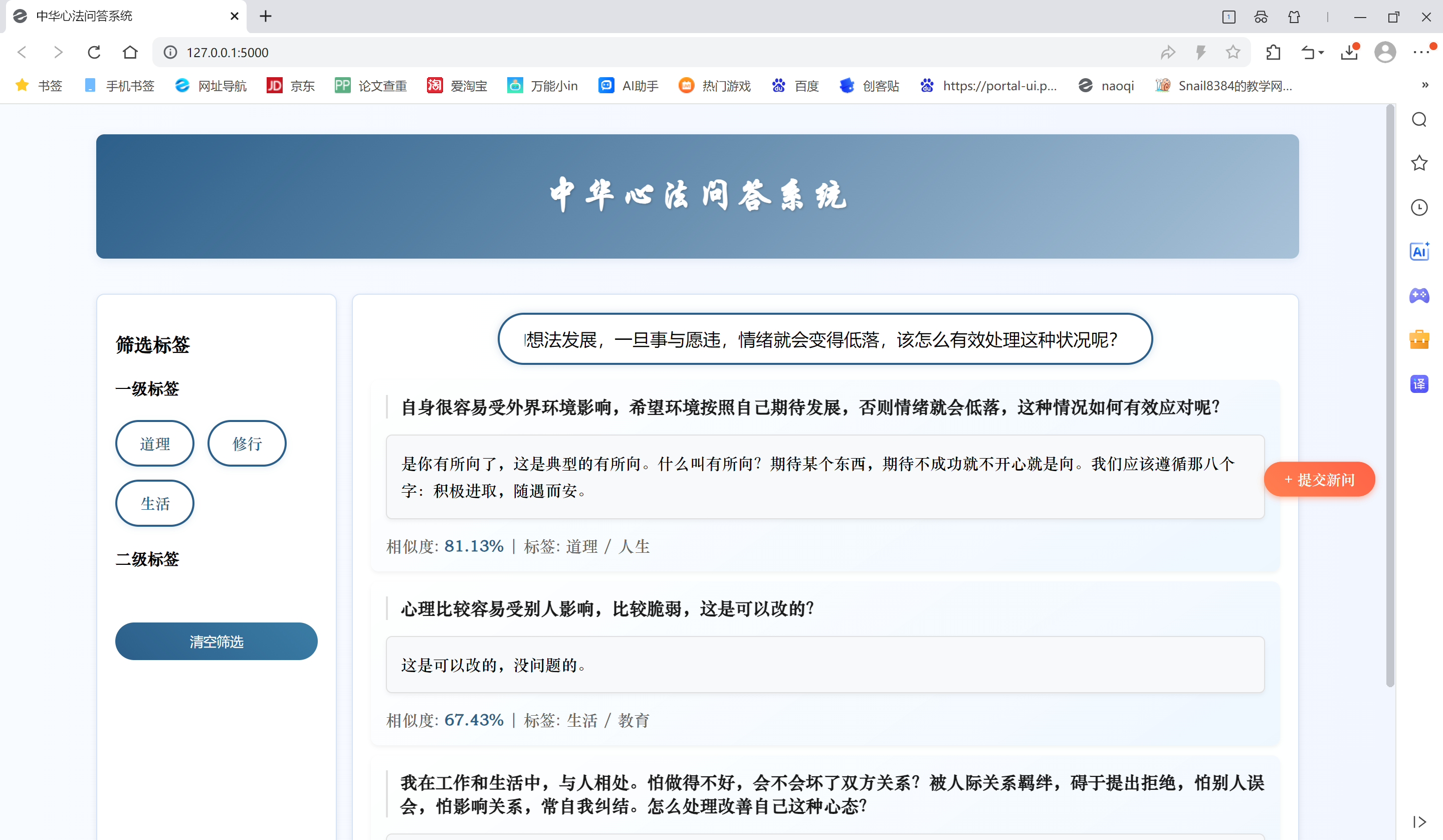
换为paraphrase-multilingual-mpnet-base-v2后与all-MiniLM-L6-v2相比准确度提高了,但是还是不如原系统。
3 总结
我认为对于心法系统属于专业领域,单纯的使用模型不进行微调生成句向量的质量有限,原系统也是进行了微调,后续将进行微调再作测试
原系统的局限在测试时进一步显现,如果资料库中存在与输入问题词重复率高的已有问题,即使语义不同,相似度也会很高,用SBERT优化后这种情况确实避免了。all-MiniLM-L6-v2对于同义不同表达的句子也会收到句子结构表达方式的影响
4 疑惑
- 如何验证系统性能提升存,这周只是手动输入问题,进行主观判断,有没有更客观的方法?
- 如何微调模型