数据结构:反转链表(reverse the linked list)
目录
通过交换元素值实现反转(reverse by swapping elements)
滑动指针(sliding pointers)
使用滑动指针反转链表(Reversing a Linked List using Sliding Pointers)
对比分析
如何用递归(Recursion)反转一个单链表
通过交换元素值实现反转(reverse by swapping elements)
为什么我们要讲这个“交换值法”而不是先讲“指针反转”?
因为指针反转属于结构反转,要修改链表的连接方式(更复杂)
而“交换值法”是数据反转,结构不变,只是调换节点里的值,适合入门理解。
(可以参考类似问题:
数据结构:数组:反转数组(Reverse the Array)-CSDN博客
数据结构:反转字符串(Reversing a String)_string反转字符串方法-CSDN博客)
第一性分析:什么是“反转链表”?
假设你有如下链表:
head → [1] → [3] → [5] → [7] → NULL
反转之后应该是:
head → [7] → [5] → [3] → [1] → NULL
你可以看到:链表结构(指针连接顺序)完全不动,只是每个节点的 data 内容被调换了。
那么,第一性问题来了:
❓ 单链表只能顺着走,你怎么访问“最后一个节点”?
我们要反转链表的“数据内容”,但不能直接随机访问链表,因为单链表只能一个方向逐个访问。
所以,我们换一个角度:
用数组作为“中间容器”,把链表的数据转移出来操作,然后再拷贝回链表。
为什么可以这样做?
-
数组支持随机访问,反转变得容易
-
链表结构不变,只是内容(
data字段)被替换 -
指针不涉及改动 → 安全、简单
① 创建数组,边遍历链表边复制 data
int arr[SIZE]; // 假设链表最多 SIZE 个节点
int count = 0;struct Node* temp = head;
while (temp != NULL) {arr[count++] = temp->data;temp = temp->next;
}
② 再次遍历链表,这次写入反转值
temp = head;
for (int i = count - 1; i >= 0; i--) {temp->data = arr[i];temp = temp->next;
}
⚠️ 注意:
-
你需要预估链表最多多少个节点(用
#define SIZE 100) -
或者你可以动态分配数组
完整代码实现
#include <stdio.h>
#include <stdlib.h>#define SIZE 100 // 预设最大节点数struct Node {int data;struct Node* next;
};void reverseDataWithArray(struct Node* head) {int arr[SIZE];int count = 0;struct Node* temp = head;// Step 1: 复制 data 到数组中while (temp != NULL) {arr[count++] = temp->data;temp = temp->next;}// Step 2: 再次遍历链表,写入反转值temp = head;for (int i = count - 1; i >= 0; i--) {temp->data = arr[i];temp = temp->next;}
}void printList(struct Node* head) {while (head != NULL) {printf("%d → ", head->data);head = head->next;}printf("NULL\n");
}struct Node* createList() {struct Node* a = malloc(sizeof(struct Node));struct Node* b = malloc(sizeof(struct Node));struct Node* c = malloc(sizeof(struct Node));struct Node* d = malloc(sizeof(struct Node));a->data = 10; a->next = b;b->data = 20; b->next = c;c->data = 30; c->next = d;d->data = 40; d->next = NULL;return a;
}int main() {struct Node* head = createList();printf("Original list:\n");printList(head);reverseDataWithArray(head);printf("After reversing data (using array):\n");printList(head);return 0;
}
滑动指针(sliding pointers)
第一性推导:从链表遍历说起
单个指针遍历链表:
你最开始遍历链表时,通常会写这样的代码:
struct Node* temp = head;
while (temp != NULL) {// 做点什么,比如打印 temp->datatemp = temp->next;
}
这没问题,但注意:
当你执行
temp = temp->next;之后,你就永远失去了对原来temp的访问
❗问题出现:
如果你想在遍历的过程中修改链表结构,比如:
-
删除当前节点
-
插入新节点
-
调换两个节点顺序
-
反转链表指向方向
你会发现只用一个 temp 指针是不够的。在某些操作后失去访问某个节点 → 链表断开 → 崩溃
举个例子:尝试改变指针方向
想象链表这样:
head → [10] → [20] → [30] → NULL
你拿着 curr = head,执行:
curr->next = NULL;
你现在就彻底失去了对 [20] 和 [30] 的访问!因为链条被断开,你再也找不到它们
🔍 第一性结论:
在进行结构操作(比如反转、插入、删除)时,你必须在操作之前保存“下一步”的信息
所以你就需要多个指针同时存在,它们滑动地一起遍历链表,互相帮助保存位置
这就是“滑动指针”的由来。
滑动指针是指你使用多个指针同时向前推进,每个指针记录链表当前不同的“位置状态”,它们就像滑动的窗口一样,彼此协同完成操作。
举例说明最基本的三个滑动指针:
假设我们有这些:
struct Node* prev = NULL;
struct Node* curr = head;
struct Node* next = NULL;
含义如下:
| 指针名称 | 含义 |
|---|---|
prev | 当前节点的前一个节点 |
curr | 当前正在处理的节点 |
next | 当前节点的下一个节点(提前保存) |
它们在遍历中这样滑动:
每次迭代:
-
提前保存
curr->next到next -
修改
curr->next = prev(如果你打算反转) -
整体滑动向前:
prev = curr;
curr = next;
图示(从左往右):
prev → curr → next → ...
下一轮:
prev → curr → next → ...
 什么时候需要滑动指针?
什么时候需要滑动指针?
你需要三个滑动指针的操作包括但不限于:
-
反转链表
-
删除当前节点
-
插入节点前后结构
-
在不丢失链表结构的情况下做复杂重构
⚠️ 为什么不只用一个或两个指针?
你可以自己试一下用一个或两个指针做“指针反转”这种操作,你会发现:
总是有一个节点你无法访问,就没法完成链表重构,操作顺序也错了。
滑动指针让你在每一步都有“前后备份”,所以操作安全可控。
操作顺序
next = curr->next; // 提前保存下一步
curr->next = prev; // 操作当前指针(反转、插入、删改)
prev = curr; // 所有指针前滑
curr = next;
💡 第一性总结:
| 概念 | 解释 |
|---|---|
| 为什么用多个指针 | 避免失去访问链表节点的能力 |
| 指针的职责 | prev:记录已处理区域,curr:当前操作,next:保存未来节点 |
| 应用场景 | 修改链表结构时必须使用 |
| 本质思想 | 一边操作链表,一边维持三个位置的状态,让链不断、访问安全 |
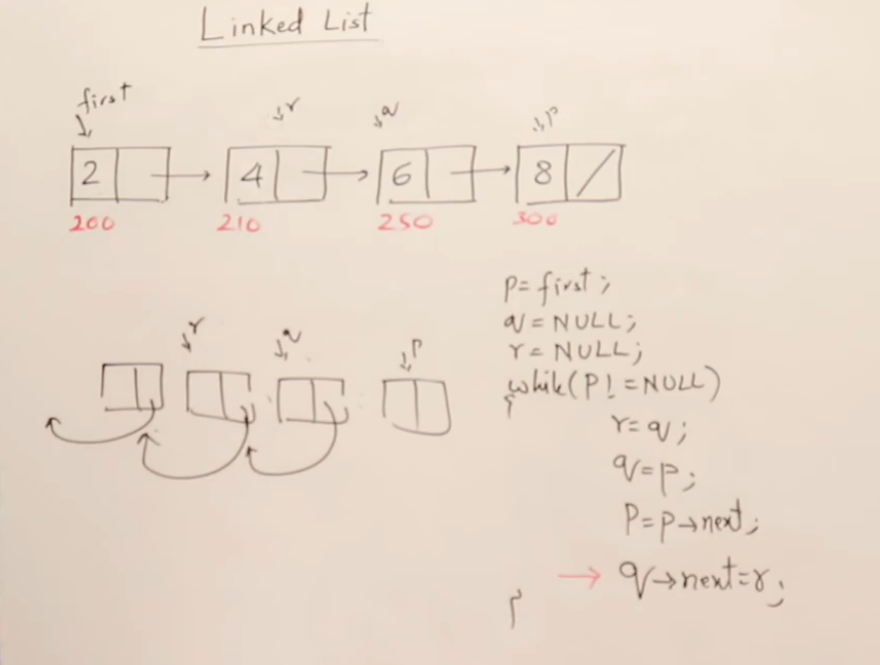
使用滑动指针反转链表(Reversing a Linked List using Sliding Pointers)
注意:不是改变节点里面的值,而是改变指针方向。
🚨 单链表只能从前往后遍历
你不能往回走。所以:
每当你打算修改
curr->next,你必须 提前保存curr->next
所以,我们必须使用三个滑动指针:
struct Node* prev = NULL;
struct Node* curr = head;
struct Node* next = NULL;
| 名字 | 含义 |
|---|---|
prev | 当前节点反转后应该指向的“前一个” |
curr | 当前正在访问的节点 |
next | 提前保存的下一个节点 |
第一性步骤:每一次“滑动”都做这三步
-
next = curr->next;→ 保存下一步 -
curr->next = prev;→ 改变指向方向 -
prev = curr; curr = next;→ 所有指针前移
空链表、一个节点怎么办?
完全没问题。curr == NULL 时循环直接跳过。
一个节点时,只走一轮,head 自动变成自己,反转不出错
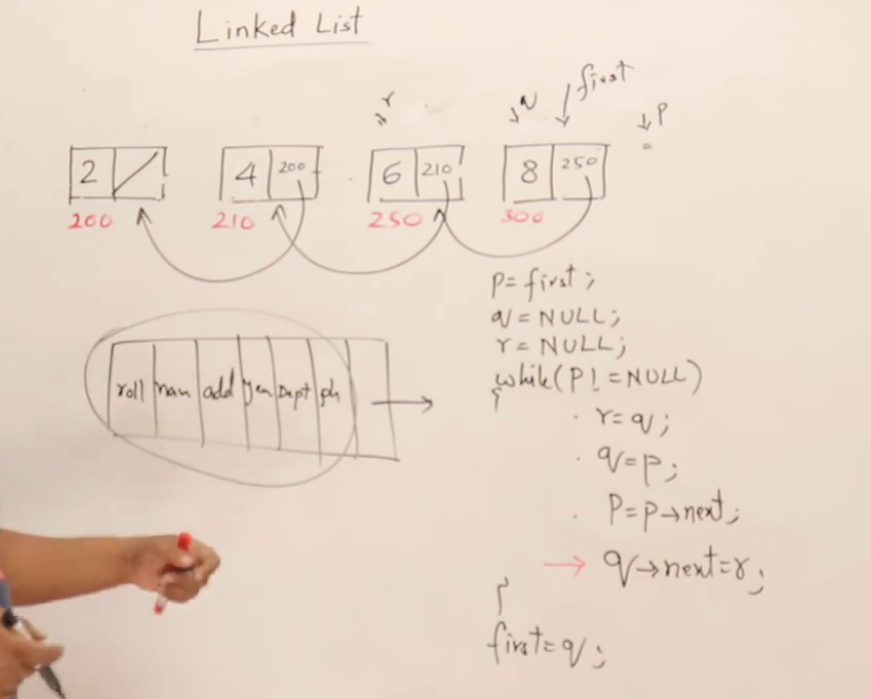
| 步骤 | 目的 |
|---|---|
| 保存下一节点 | 防止修改 curr->next 后丢失后续链 |
| 修改 curr->next | 实现反转(原来向右,现在向左) |
| 滑动三个指针 | 向前推进处理下一组节点 |
| 更新 head | 将最终的 prev 作为新的链表头 |
一步步构建反转函数:reverseUsingPointers
void reverseUsingPointers(struct Node** head) {struct Node* prev = NULL;struct Node* curr = *head;struct Node* next = NULL;while (curr != NULL) {// Step 1: 提前保存下一步next = curr->next;// Step 2: 改变方向curr->next = prev;// Step 3: 所有指针滑动prev = curr;curr = next;}// 最终 prev 是新的头部*head = prev;
}
对比分析
我们要比较两种单链表反转方式:
| 方法名称 | 核心思路 |
|---|---|
| 方法一:拷贝数据法 | 将链表的 data 拷贝到数组,反转后再写回 |
| 方法二:滑动指针法(改变结构) | 修改链表中每个节点的 next 指针方向 |
我们将从它们的本质、适用性、性能、安全性等方面一一分析。
1. 操作对象本质
数据拷贝法:
只动数据,不动结构(next 不变)
arr[i] = temp->data;
temp->data = arr[j];
所以它适合在结构不能变动的情况下做反转(如考试题、受限数据结构)
滑动指针法:
完全不动数据,只动结构(指针方向反过来)
curr->next = prev;
这本质上是“链表重构”,适合任何允许你改变链结构的环境,效率也更高
2. 数据结构的复杂性影响
❗ 如果每个节点只存一个 int,拷贝没什么压力
但现实中常常这样设计链表节点:
struct Node {char name[100];int id;float salary;struct Node* next;
};
这时候每个节点里的 data 是一个结构体(甚至可能更复杂)
→ 如果你用“拷贝数据法”,你必须完整复制这些字段
→ 可能需要自定义拷贝函数、深拷贝、数组容量等问题
当节点的
data很复杂(结构体、嵌套对象、大量数据)时,滑动指针法明显更好
3. 时间复杂度对比
| 操作 | 时间复杂度 | 原因 |
|---|---|---|
| 数据拷贝法 | O(n) + O(n) = O(n) | 两次遍历:拷贝 + 写回 |
| 滑动指针法 | O(n) | 一次遍历:边滑动边反转指针 |
虽然复杂度都是 O(n),但滑动指针法更省,只有一次遍历和一次拷贝
4. 空间复杂度对比
| 方法 | 空间开销 | 说明 |
|---|---|---|
| 拷贝数据法 | O(n) 额外数组空间 | 存储每个 data 的值 |
| 滑动指针法 | O(1)(只用 3 个指针) | 不需要额外数组 |
5. 安全性与一致性
滑动指针法:
-
不会拷贝错误
-
不关心 data 内容是什么(结构再复杂都不管)
-
不会遇到内存越界等数组问题
数据拷贝法:
-
要保证数组空间够大
-
要小心拷贝结构体或深拷贝问题
-
容易写错或越界(尤其是动态链表)
因此,滑动指针法更通用、更安全、更节省空间,更适合实际工程和复杂数据结构, 数据拷贝法仅适合学习、数据简单、结构不允许改动时使用 。
你应该选择滑动指针法的理由总结:
-
不管节点里放什么,它都不在乎
-
永远只用三个指针,不会爆内存
-
一次遍历搞定,比拷贝更省时间
-
改变结构更符合“链表反转”的语义
如何用递归(Recursion)反转一个单链表
第一性原则出发点:什么是递归?
递归是指:一个函数在内部调用自己,并且有:
-
基本情况(Base Case):终止条件
-
递归情况(Recursive Case):把当前问题拆分成更小问题交给自己来做
第一步:递归函数的思考
❓我们要问:我们可以用递归处理谁?
答案是:
让递归先反转链表的后面部分,我们只处理“当前节点和它的 next”
所以递归函数的含义可以设定为:
void Reverse(Node* prev, Node* curr)
-
curr:当前节点(当前要处理的) -
prev:当前节点 curr 的前驱(上一个)
这是一个滑动指针式递归反转方案。
你会从头开始调用:
Reverse(NULL, head);
每一次递归,你都把当前 curr 当作下一轮的 prev,curr->next 当作下一轮的 curr
也就是说,每一层你都像这样“向前推进”:
Reverse(curr, curr->next);
一层层推进(调用栈):
| 调用层 | prev | curr |
|---|---|---|
| 1 | NULL | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
| 4 | 3 | 4 |
| 5 | 4 | NULL ← base case |
第二步:Base Case(终止条件)
当你递归到最后一个节点,链表已经不能再往下了:
if (curr == NULL) {first = prev;return;
}
-
如果当前处理节点 curr 已经是 NULL,说明我们走到了原链表的末尾
-
此时 prev 是最后一个有效节点,应该变成新的头节点
-
所以设置
first = prev(这个变量是全局的链表头)
第三步:Recursive Case(递归处理)
每一层执行:
Reverse(curr, curr->next);
也就是说:
-
下一轮,curr 成为 prev
-
curr->next成为新的 curr
这相当于向后滑动一格,保持一个“两个指针的窗口”,像滑动指针一样
第四步:反转指针
递归完成之后,再回来时:
curr->next = prev;
你把当前节点的 next 指向前一个节点
🔄 反转动作在哪里发生?
不是在前进时做的,而是在递归“回溯”过程中做的
用第一性逐层模拟
假设链表为:[1] → [2] → [3] → NULL
初始调用:
Reverse(NULL, 1)
→ 递归进入 Reverse(1, 2)
→ 递归进入 Reverse(2, 3)
→ 递归进入 Reverse(3, NULL)
→ 此时:curr == NULL, 执行:first = prev → 即 first = 3
然后回溯阶段
curr = 3, prev = 2 → 3->next = 2
curr = 2, prev = 1 → 2->next = 1
curr = 1, prev = NULL → 1->next = NULL
得到新链表
first → [3] → [2] → [1] → NULL
| 阶段 | 操作 | 含义 |
|---|---|---|
| 递归推进 | Reverse(curr, curr->next) | 保存前一个和当前节点,深入到末尾 |
| 递归终止 | if (curr == NULL) | 到达末尾,设置新的链表头 first = prev |
| 回溯反转指向 | curr->next = prev | 每层反转指向,把当前节点指向前一个节点 |
完整代码
void Reverse(Node* prev, Node* curr) {if (curr != NULL) {Reverse(curr, curr->next); // 向后推进curr->next = prev; // 回溯过程中修改指向} else {first = prev; // 递归到底,设置新头}
}
为什么这种方法优雅?
-
结构清晰,变量少(只用两个滑动指针)
-
不需要返回值,不需要临时数组
-
完全递归思维,没有额外变量干扰
-
最后由最深层设置头结点,不需要手动更新
head = ...
改进建议(可选):
如果你希望去掉全局变量 first,可以把第三个参数传进去(如 Node** head)
或者让 Reverse 返回新的头结点(需要改写递归结构)
但在这个思路在学习递归本质、滑动窗口逻辑上是极好的。
⚠️ 补充:递归的缺点
虽然递归很优雅,但它有函数调用栈的开销,在链表很长(如几万节点)时,可能会造成栈溢出
如果你要处理长链表,推荐用迭代方式(滑动指针法)