[自动化Adapt] 数据脱敏 | 文本替换/图像模糊 | 引擎热插拔 | 多队列并行处理
第七章:隐私擦除(数据脱敏)
欢迎回来,OpenAdapt探索者~
在第六章:数据库管理中,我们了解了OpenAdapt如何严谨地存储和管理所有记录的操作和数据。这使得我们可以在需要时随时查找并回放自动化流程。
但如果我们记录的任务涉及敏感信息呢?设想以下自动化场景:
- 填写包含家庭地址或信用卡号的在线表格
- 处理包含医疗隐私信息(PHI)的文档
- 操作显示员工姓名或薪酬信息的内部系统
我们显然不希望这些机密数据以明文形式存储在记录中,存在被他人查看或意外泄露的风险。未经保护地存储此类数据可能带来安全隐患!
这正是**隐私擦除(数据脱敏)**功能的用武之地。
什么是隐私擦除?
我们可以将OpenAdapt的隐私擦除功能视为记录的**“隐私卫士"或"数字橡皮擦”**。其主要职责是检测并移除记录中的敏感信息——如个人姓名、地址、信用卡号及其他机密细节。
为什么需要这项功能?
在当今数据安全至关重要的环境下,如果自动化工作流意外存储或泄露敏感数据,可能导致严重的隐私违规和合规风险。OpenAdapt的擦除功能帮助我们:
- 保护敏感数据:确保隐私信息(个人身份信息-PII,或受保护健康信息-PHI)不会以明文形式存在于操作日志或截图中
- 合规性保障:通过预先脱敏处理,满足GDPR、HIPAA等隐私法规要求
- 安全共享:允许放心分享记录或演示,无需担忧隐私泄露
例如,当记录信用卡号输入过程时,擦除功能会将文本日志中的号码替换为星号(**** **** **** ****),并在截图中进行模糊处理。这对于确保自动化流程不会意外存储或暴露机密数据至关重要。
如何使用隐私擦除(简易方式)
通过OpenAdapt基于网页的仪表盘是使用隐私擦除功能最简便的方式。
首先确保在配置中启用擦除功能。通常可以在仪表盘"设置"菜单下的"擦除"选项中找到类似SCRUB_ENABLED的参数,确保其设置为True。
启动仪表盘命令:
python -m openadapt.app.dashboard.run
仪表盘启动后:
- 选择记录:导航至记录列表
- 启动擦除:选择目标记录,点击"擦除"或"脱敏"按钮
- 选择提供方(可选):根据需求选择不同的擦除引擎,新手建议保持默认
后续流程
启动擦除时,OpenAdapt会执行关键安全步骤:创建原始记录的完整副本。
所有脱敏操作都在副本执行,原始记录保持完整,方便后续调试或追溯。脱敏副本在仪表盘中会有特殊标识。
隐私擦除
流程图
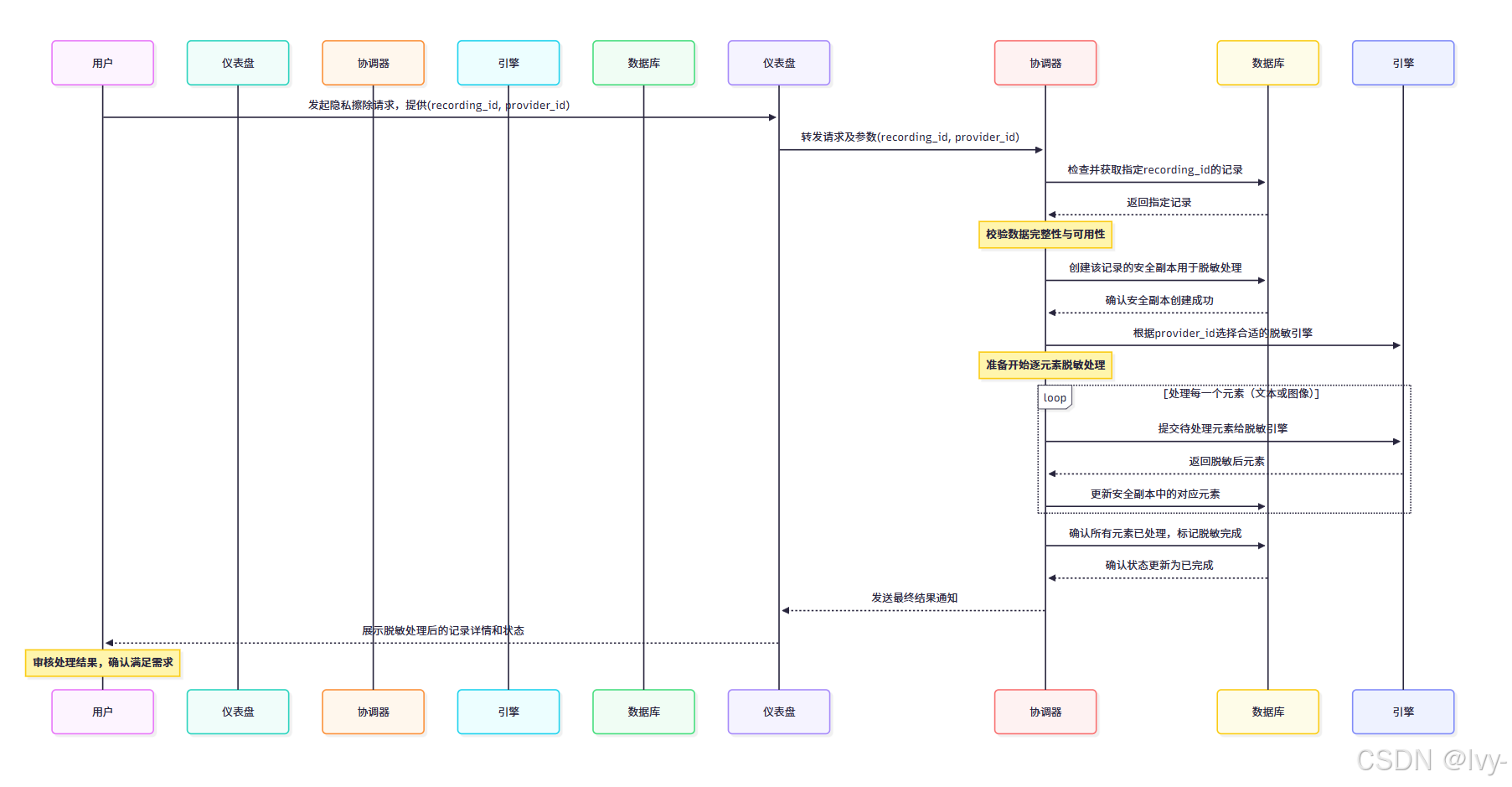
该流程包含记录复制、专用擦除引擎调用、数据库更新等关键阶段。
擦除引擎规范:openadapt/privacy/base.py
为确保不同擦除工具的一致性,OpenAdapt在openadapt/privacy/base.py中定义了基础规范类ScrubbingProvider:
# 简化自 openadapt/privacy/base.pyfrom PIL import Imageclass 数据类型:"""定义可处理的数据类型"""文本 = "TEXT"图像 = "PIL_IMAGE"class 擦除引擎基类:"""所有擦除工具必须继承的基类"""def 文本脱敏(self, 文本内容: str, 分段处理: bool = False) -> str:"""文本脱敏方法"""raise NotImplementedError # 具体引擎必须实现def 图像脱敏(self, 图像对象: Image, 填充色: int = ...) -> Image:"""图像脱敏方法"""raise NotImplementedError # 具体引擎必须实现
该基类定义了所有擦除工具必须实现的接口规范。数据类型枚举则明确支持的处理类型(文本/图像)。
定义了一个隐私脱敏处理的基础框架,主要包含两个核心部分:
-
数据类型枚举类
用常量明确标识支持处理的数据类型,当前版本支持两种:文本:普通字符串内容图像:PIL库的图片对象
-
抽象基类
所有具体脱敏工具(如姓名擦除、车牌打码等)必须继承这个基类,并实现两个强制方法:文本脱敏():处理字符串的隐私内容(如手机号替换为***)图像脱敏():处理图片中的敏感区域(如人脸打马赛克)
关键设计思想:
-
标准化接口
不同功能的脱敏工具(文本/图像)必须遵循相同的方法命名和参数规范,确保调用方式统一。 -
强制实现
基类方法直接抛出NotImplementedError,要求子类必须重写这些方法,否则运行时会报错。 -
扩展性
新增数据类型(如视频)只需在数据类型类中添加新常量,并在基类中补充对应处理方法。
引擎选择机制:openadapt/privacy/providers/__init__.py
通过工厂类实现不同擦除引擎的动态加载:
# 简化自 openadapt/privacy/providers/__init__.pyclass 擦除引擎工厂:"""管理可用擦除引擎"""PRESIDIO = "PRESIDIO" # Microsoft解决方案PRIVATE_AI = "PRIVATE_AI" # 第三方方案@classmethoddef 获取引擎(cls, 引擎名称: str) -> "擦除引擎基类":"""根据名称加载对应引擎"""if 引擎名称 == cls.PRESIDIO:from openadapt.privacy.providers.presidio import Presidio擦除引擎return Presidio擦除引擎()elif 引擎名称 == cls.PRIVATE_AI:# 返回PrivateAI引擎实例pass # 其他引擎实现else:raise ValueError(f"不支持的引擎: {引擎名称}")
当需要特定擦除引擎时,调用擦除引擎工厂.获取引擎()即可获得对应实例。
实战引擎示例:openadapt/privacy/providers/presidio.py
以Microsoft的Presidio引擎实现为例:
# 简化自 openadapt/privacy/providers/presidio.pyfrom PIL import Image
from openadapt.privacy.base import 数据类型, 擦除引擎基类, 文本擦除增强class Presidio擦除引擎(擦除引擎基类, 文本擦除增强):"""基于Microsoft Presidio的擦除实现"""名称: str = "PRESIDIO"支持类型: List[str] = [数据类型.文本, 数据类型.图像]def 文本脱敏(self, 文本内容: str, 分段处理: bool = False) -> str:"""使用Presidio进行实体识别和脱敏"""if 文本内容 is None:return None# 实际实现中会识别姓名、地址、信用卡号等实体脱敏文本 = 文本内容.replace("张三", "[姓名已脱敏]")脱敏文本 = 脱敏文本.replace("北京市朝阳区", "[地址已脱敏]")return 脱敏文本def 图像脱敏(self, 图像对象: Image, 填充色: int = ...) -> Image:"""图像区域模糊处理"""脱敏图像 = 图像对象 # 此处为示意,实际实现区域检测和模糊return 脱敏图像
实现了一个基于Microsoft Presidio隐私保护工具的数据脱敏引擎,主要用于处理文本和图像中的敏感信息。
在文本处理时会识别敏感实体并进行替换,图像处理则实现区域模糊。
核心组件说明
类定义
Presidio擦除引擎继承自两个基类:擦除引擎基类和文本擦除增强- 声明该引擎的名称为"PRESIDIO"
- 支持处理的数据类型包括文本和图像
文本脱敏方法
- 接收文本内容和可选的分段处理标志作为参数
- 检查文本内容是否为空
- 示例中直接替换特定敏感信息(实际实现会使用Presidio检测更多实体)
- 将"张三"替换为"[姓名已脱敏]"
- 将"北京市朝阳区"替换为"[地址已脱敏]"
- 返回处理后的脱敏文本
图像脱敏方法
- 接收图像对象和可选填充色参数
- 示例中直接返回原图(实际会检测敏感区域并进行模糊处理)
- 返回处理后的脱敏图像
应用场景
- 文本处理:自动识别并隐藏姓名、地址、银行卡号等隐私信息
- 图像处理:自动检测并模糊人脸、车牌等敏感区域
流程协调中心:openadapt/scrub.py
擦除流程的核心调度逻辑:
# 简化自 openadapt/scrub.pyimport multiprocessing
from queue import Queue
from threading import Threadfrom openadapt.db import crud
from openadapt.models import 操作事件, 屏幕截图
from openadapt.privacy.providers import 擦除引擎工厂def 执行擦除(记录ID: int, 引擎名称: str, 释放锁: bool = False) -> None:"""擦除流程总控:1. 创建记录副本2. 加载指定擦除引擎3. 并行处理所有事件元素"""# 获取原始记录并创建副本会话 = crud.获取新会话(只读=True)原始记录 = crud.按ID获取记录(会话, 记录ID)会话.close()写会话 = crud.获取新会话(读写=True)新记录ID = crud.复制记录(写会话, 记录ID)新记录 = crud.按ID获取记录(写会话, 新记录ID)# 加载擦除引擎实例擦除器 = 擦除引擎工厂.获取引擎(引擎名称)# 构建事件处理队列操作事件队列 = Queue()for 事件 in 新记录.操作事件集:操作事件队列.put(事件.id)# 类似构建截图队列等# 定义工作线程任务def 单元素处理(元素ID: int, 模型类: any) -> None:"""工作线程执行的单个元素处理"""crud.擦除元素(写会话, 元素ID, 模型类, 擦除器)# 启动多线程并行处理Thread(target=启动工作线程,args=("擦除-操作事件", 单元素处理, 操作事件队列, 操作事件)).start()# 类似启动其他队列处理线程# 标记完成状态crud.标记擦除完成(写会话, 新记录ID)写会话.close()
该协调器实现记录复制、多队列并行处理、状态更新等关键流程,实现了一个数据擦除的协调系统,主要用于高效处理大批量的隐私数据擦除任务:
记录复制阶段
创建原始记录的完整副本,所有擦除操作都在副本上进行,避免影响原始数据。通过数据库会话获取原始记录,然后生成具有新ID的副本。
擦除引擎加载
根据传入的引擎名称参数,动态加载对应的数据擦除处理器。不同的引擎可以实现不同的擦除算法(如文本模糊化、图像打码等)。
并行处理架构
采用生产者-消费者模式构建多队列处理系统:
- 将需要处理的事件ID放入队列
- 工作线程从队列获取ID并执行擦除
- 不同类型的数据(操作事件、截图等)使用独立队列处理
线程工作流程 每个工作线程执行相同逻辑:
获取队列中的元素ID →调用CRUD模块的擦除方法 →使用指定引擎处理具体内容 →更新数据库
状态管理
全部处理完成后,在数据库中标记该记录已完成擦除状态。整个过程保持数据库会话的合理开关,确保资源释放。
技术特点
- 零数据丢失:所有操作在副本执行
- 弹性扩展:可轻松添加新的处理队列
- 引擎热插拔:通过工厂模式支持不同擦除算法
- 高效并行:CPU密集型任务由多进程处理,IO密集型由多线程处理
典型应用场景包括批量清理用户行为日志中的敏感信息,或对录屏数据中的隐私内容进行模糊化处理。
⭕引擎热插拔
通过工厂模式动态加载或替换不同擦除算法模块,无需重启系统即可切换实现。
工厂模式实现 :
定义抽象基类声明统一接口,派生类实现具体算法:
class ErasureAlgorithm {
public:virtual void erase() = 0;
};class SecureErase : public ErasureAlgorithm {void erase() override { /* 安全擦除实现 */ }
};class QuickErase : public ErasureAlgorithm {void erase() override { /* 快速擦除实现 */ }
};
动态加载机制
工厂类根据配置返回具体实例,通过动态库(.dll/.so)实现运行时切换:
std::unique_ptr<ErasureAlgorithm> createAlgorithm(const std::string& type)
{if (type == "secure") return std::make_unique<SecureErase>();if (type == "quick") return std::make_unique<QuickErase>();throw std::runtime_error("Unsupported algorithm");
}
应用场景:
- 数据销毁工具中灵活切换擦除标准(如DoD 5220.22-M vs Gutmann)
- 嵌入式设备根据存储介质选择最优算法
脱敏数据存储:scrubbed_text与scrubbed_canonical_text
当处理文本类操作事件时,OpenAdapt通过数据库迁移脚本(如186316d4f3ca_add_scrubbed_columns.py)在action_event表中新增两个字段:
# 简化自 openadapt/alembic/versions/186316d4f3ca_add_scrubbed_columns.pyfrom alembic import op
import sqlalchemy as sadef 升级():with op.batch_alter_table("action_event") as batch_op:batch_op.add_column(sa.Column("scrubbed_text", sa.String(), nullable=True))batch_op.add_column(sa.Column("scrubbed_canonical_text", sa.String(), nullable=True))def 降级():with op.batch_alter_table("action_event") as batch_op:batch_op.drop_column("scrubbed_canonical_text")batch_op.drop_column("scrubbed_text")
新增字段专门存储脱敏后的文本内容,原始数据仍保留在原有字段。这种设计既满足隐私保护需求,又保留原始数据可追溯性。
隐私擦除功能概要
关键特性总结:
| 维度 | 描述 | OpenAdapt实现方案 |
|---|---|---|
| 核心目标 | 保护记录中的敏感数据(PII/PHI) | 文本替换/图像模糊 |
| 用户交互 | 通过仪表盘操作,需在配置启用SCRUB_ENABLED | 图形界面交互,配置参数管理 |
| 处理流程 | 创建新副本进行脱敏,原始记录保持不变 | crud.copy_recording复制记录 |
| 文本处理 | 敏感信息替换为占位符 | ScrubbingProvider.scrub_text()处理,存储至scrubbed_text字段 |
| 图像处理 | 敏感区域检测与模糊 | ScrubbingProvider.scrub_image()实现 |
| 引擎扩展性 | 支持多种脱敏引擎 | ScrubbingProvider基类规范,擦除引擎工厂动态加载 |
| 处理效率 | 高效处理大规模记录 | scrub.py中多队列并行处理架构 |
总结
至此我们已经全面掌握OpenAdapt强大的隐私擦除功能
这项"隐私卫士"通过智能检测和脱敏处理,有效保护文本日志和截图中的敏感信息。理解副本创建机制、模块化引擎设计和并行处理架构,可以帮助我们安全地开展自动化任务,兼顾效率与合规性。
掌握隐私保护机制是准备自动化记录的重要环节。接下来我们将深入探讨如何利用这些精心处理的记录来实现计算机自动化操作。
下一章:回放策略