datasets库 的map方法num_proc=16并行踩坑
下图是tensorboard记录的评估数据集的准确率的变化,如下图所示,准确率低于0.01。
这个模型训练的结果,显然不对,出现这种情况大概率是数据集出问题了。
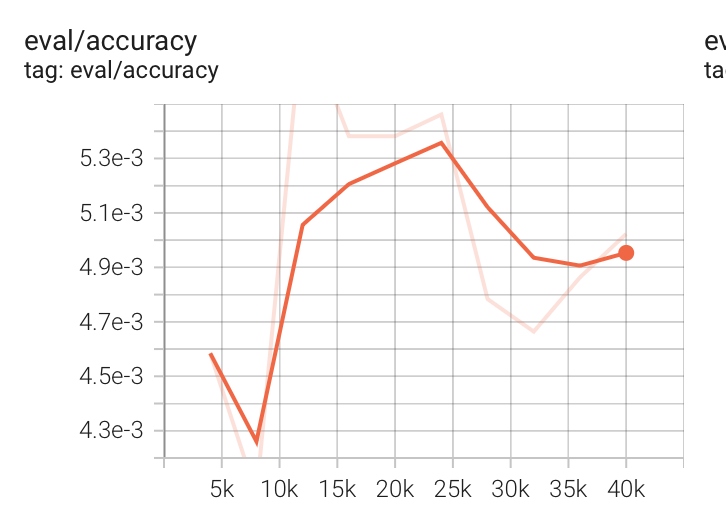
因为我没有更改代码,只更改了数据集。很快就反应过来是数据的问题,是label设置的不对。
LABEL_D = {}
def func(item):"""给label编号"""label_name = item["label_name"]if label_name not in LABEL_D:LABEL_D[label_name] = len(LABEL_D)item["label"] = LABEL_D[label_name]return itemnew_dataset = loaded_dataset.map(func,num_proc=16
)
代码中使用了num_proc=16进行并行处理,这会启动 16 个进程同时执行func函数。但LABEL_D是一个全局变量,在多进程场景下:
- 每个进程会拥有LABEL_D的独立副本(进程间内存不共享)
- 不同进程可能对同一个new_label_name生成不同的编号(例如两个进程同时检测到某个新标签,都认为它不在LABEL_D中,分别分配编号 0 和 1)
- 最终导致new_dataset中标签编号混乱,且LABEL_D的最终状态不可控(仅保留最后一个进程的修改)
【注意】:num_proc=1,依然也不行。虽然是单进程模式,但是依然不对。
这种 “动态累加标签编号” 的方式存在隐患。最可靠的方式仍是 先收集所有标签生成映射表,再应用映射。
在读取标签的时候,可以使用多进程进行读取。
改进
改进后的代码如下,提前把LABEL_D构建好:
## 设置 LABEL_D
LABEL_D = {name: i for i, name in enumerate(set(loaded_dataset["train"]["label_name"]))}def func(item):"""给label编号"""label_name = item["label_name"]if label_name not in LABEL_D:LABEL_D[label_name] = len(LABEL_D)item["label"] = LABEL_D[label_name]return itemnew_dataset = loaded_dataset.map(func,num_proc=16
)