仿TCmalloc内存分配器
什么是内存池前面几章讲过,这里就不在多说了。
目录
一 内存池整体框架
thread_cache:
central_cache:
span_cache:
二 缓存设计
1. thread_cache:
结构代码:
2.Central_cache:
结构代码:
3.Span_cache:
结构代码:
三 公共函数
1. 自由链表
2. 向上对齐
3. 映射槽位
四 申请/释放逻辑
1. 申请逻辑
1. 入口函数
2. thread_cache 获取内存
1. Get_Memory(size):
2. Get_Central_Memory(nsize, index):
3. Barrel_Index_Nsize::Batch_Size(nsize):
2. Central_cache 获取内存:
1. Central_Cache::Get_S_C()->Get_One_Ranges(start, end, nsize, batch):
2. Get_Span(_CC[index],nsize):
3. Barrel_Index_Nsize::Page_Num(nsize):
3. Page_cache 获取内存:
1. Page_Cache::Get()->Get_Span(Barrel_Index_Nsize::Page_Num(nsize)):
2. 释放逻辑
1. 入口函数
2. Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT)):
3. TLS_ptr->Free_Memory(ptr, size):
4. Central_Cache::Get_S_C()->Give_Spans_Index(start, index):
五 高并发优化
一 内存池整体框架
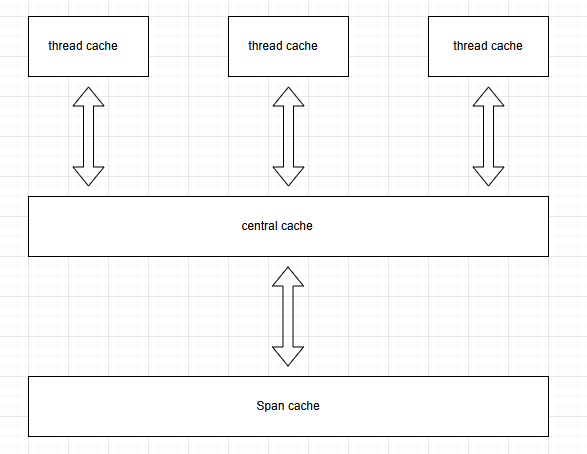
整体分为3层缓存,每层各自的左右不一样。
thread_cache:
1. 该缓存主要提供给用户需要的内存块进行分配/释放用户传入的内存块。
2. 所管理的都是不同大小的空闲的内存块。
3. 没有则取下一层去取内存块。
4. 采用单链表进行链接内存块。
5. 可能触发内存块的归还。
central_cache:
1. 以页为单位管理内存块,并把该内存块进行切割成小块内存块提供给 thread_cache 使用。
2. 可能归还以页为单位的内存块到 span_cache 。
3. 可能去 span_cache 里去取以页为单位的内存块并切成小块对象。
span_cache:
1. 以页为单位管理完整空闲的内存块,提供给 central_cache 使用。
2. central_cache 归还内存块可能触发合并前后相邻的内存块缓解内存碎片。
3. 可能向系统申请一大块内存来提供给 central_cache。
二 缓存设计
1. thread_cache:
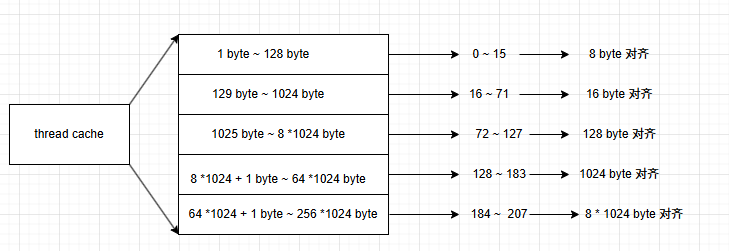
该缓存采用线程局部存储保证每个线程都有一个 thread_cache 对象实例避免多线程并发竞争同一资源造成线程安全的问题。
总共管理 208 个桶,每个区间的桶管理的内存块的大小不一样,并按一定的字节数进行对齐,这里可能有浪费,但整体保证浪费到 90%,虽然如果只申请 1 字节,最低给 8 字节,浪费百分之 90%,越靠后浪费率保证到 90% 。
用户申请的内存最少给 8 字节,因为该缓存采用单链表的形式储存,并没有使用 next* 指针来连接,而用实际的内存块的头 4/8 字节进行连接,所以至少要有 8 字节来连接内存块。
如果某个桶里没有小块对象则去 central_cache 进行申请内存块。
结构代码:
class List_Frees
{
public:// 获取资源void* Get_Memory(size_t size);// 释放资源void Free_Memory(void* ptr, size_t size);// 无资源向中心缓存申请void* Get_Central_Memory(size_t size, size_t index);
private:// 一共208个自由链表对象Free_list_FL _LF[BARREL_MAX];
};class Free_list_FL
{
private:// 自由链表的头void* _Free_ptr = nullptr;// 每次向 central_cache 申请内存块的个数size_t batch_size = 1; // 该槽位有多少个内存块size_t Size = 0;
}static __declspec(thread) List_Frees* TLS_ptr = nullptr;List_Frees:
Get_Memory(size_t size):和传统的 malloc 一样,传入实际需要的内存大小并返回内存块,这里需要内存对齐,central_cache 同一说。
Free_Memoty(void* ptr,size_t size):和传统的 free 一样,传入申请的内存块的起始地址并释放,这里添加了内存块的大小字段,后续会处理。
Get_Central_Memory(size_t size, size_t index):如果某个槽位没有内存块则去 central_cache 去取内存块。
Free_list_FL:
_Free_ptr:起始内存块。
batch_size:每次去 central_cache 申请内存块的个数。
Size:_Free_ptr 挂了多少个内存块。
static List_Frees* TLS_ptr:线程局部存储采用的是指针,是内置类型,声明静态防止多个头文件重复包含导致二义性和链接错误。
2.Central_cache:
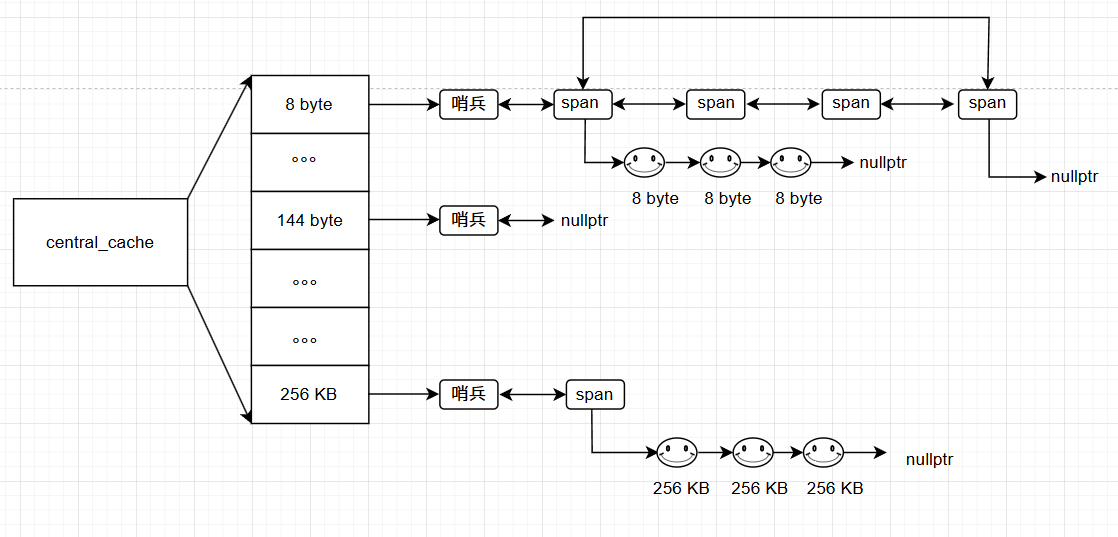
整体管理的内存大小和对齐关系和 thread_cache 一样,但管理的对象不一样。
首先是以双向带头循环链表进行管理和 thread_cache 的单向链表不同。
挂的内存块是以页为单位,即 span,span 可能是一页也可能是多页构成,一个 span 里的多个页是相邻的,且一个 span 会被切成小块内存块也就是和下标一一对应的对齐数大小,这里和 thread_cache相同。
span 挂的小块内存块可能是一个也没用,也可能用了一部分也可能一个小块内存块也没有。
结构代码:
class Central_Cache
{
public:static Central_Cache* Get_S_C(){return &_S_C;}void Give_Spans_Index(void*& start, size_t size);size_t Get_One_Ranges(void*& start, void*& end, size_t index, size_t batch);Span* Get_Span(SpanList& splist,size_t size);
private:SpanList _CC[BARREL_MAX];Central_Cache() {}Central_Cache(const Central_Cache& copy) = delete;static Central_Cache _S_C;
};class SpanList
{
public:SpanList(){_Sp = new Span;_Sp->_next = _Sp;_Sp->_prev = _Sp;}std::mutex _mtu;
private:Span* _Sp;
};这里 Span 类型下一层缓存讲。
Central_Cache:
下面4个对象用来实现单例模式(饿汉模式)来定义全局且唯一的实例 Central_cache。
Central_Cache* Get_S_C():静态对象编译初始化直接调用函数返回。
Central_Cache() {}:这里和下面 3 个对象全部私有防止拷贝构造和普通构造。
Central_Cache(const Central_Cache& copy) = delete:删除拷贝构造
static Central_Cache _S_C:静态对象编译初始化且在类外定义。Give_Spans_Index(void*& start, size_t size):根据 thread_cache 实际映射后的槽位来去 central_cache 对应的槽位去取 sapn。
Get_One_Ranges(void*& start, void*& end, size_t index, size_t batch):获取 span 之后进行拿取 span 挂的小块对象。
Get_Span(SpanList& splist,size_t size):central_cache 对应的槽位如果没有 span 则去 span_cache去取一个 span。SpanList _CC[BARREL_MAX]:双向带头循环链表的管理,一共 208个槽位,映射规则和对齐规则和 thread_cache 一模一样。
SpanList:
SpanList():设置哨兵头节点
std::mutex _mtu:每个槽位都需要一把锁,central_cache 是全局共享的。
Span* _Sp:Span 对象,下一层缓存讲。
3.Span_cache:
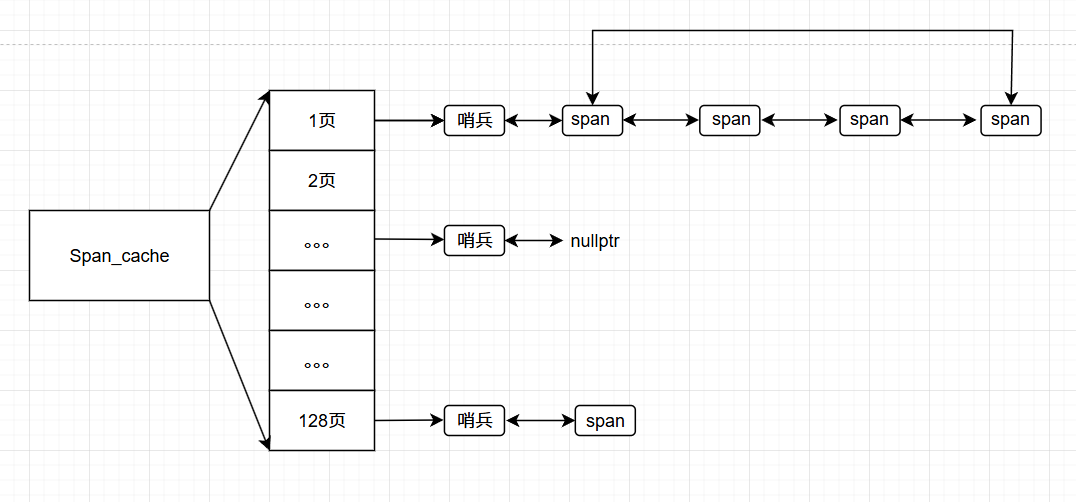
和 central_cache 类似都是以 span 为管理单位。
该层缓存一共 128 页大小的内存块,一页 8 KB,最大能分配的也就是 1024 KB,很明显超过了 thread_cache 的 256 KB的内存申请,在 256 ~ 1024KB之间则直接调用该层缓存分配出去。
该层缓存管理的 span 全部都是未使用空闲且没有被切成小块对象。
结构代码:
class Page_Cache
{
public:// 和 central_cache 一样采用单例模式static Page_Cache* Get() { return &_P_C; }// 根据传入的实际对齐后的内存块大小来分配一个对应的 spanSpan* Get_Span(size_t size);// 合并 span 前后相邻页缓解内存碎片void Merge_Span(Span* span);// 也要有个全局锁,著不过该锁是锁的整个 128 个桶std::mutex _mut;// 这里查找分配出去的 span 的小块对象和它自己对应的 span 的映射,这里后面讲void* Get_Span_Map(PAGE_ID pageid,void*& start){// 传入的指针按照 8 KB 进行向下取整得到 span 的其实页号if (Tree_Map.get(pageid) != NULL){return Tree_Map.get(pageid);}// 理论上不会找不到,否则直接断言else assert(false);// 下面注释过的后面会讲//_mut.lock();/*if (Map_Span.find(pageid) != Map_Span.end()){_mut.unlock();return Map_Span[pageid];}else{assert(false);}*/return nullptr;}
private:// 一共 128 个槽位SpanList _PC[PAGE_MAX];// 下面 2 个为了实现单例模式的饿汉模式而私有的成员函数Page_Cache() {}Page_Cache(const Page_Cache& copy) = delete;// 定制分配 span 对象Object_pool<Span> _obj;// 后面会讲TCMalloc_PageMap2<32 - PAGE_SHIFT> Tree_Map;//std::unordered_map<PAGE_ID, Span*> Map_Span;//std::map<PAGE_ID, Span*> Map_Span;// 饿汉模式使用的静态对象static Page_Cache _P_C;
};class Span
{
public:// 初始化哨兵节点Span(){_next = _prev;_prev = _next;}// span 对应的页号,也就是页号对应的起始虚拟地址PAGE_ID page = 0;// 该 span 一共有多少个页size_t _n = 0;// 该 span 切割的小块内存快的使用情况size_t usecount = 0;// 切割的内存块大小size_t _obj_size = 0;// 前后双指针Span* _next;Span* _prev;// 指向切好的小块内存的起始内存块void* _FreeList = nullptr;// 该 span 是否被使用bool _isuse = false;
};该层缓存也采用单例模式和上一层缓存一样,这里不再多说。
Page_Cache:
Get_Span(size_t size):获取一个 span 给 central_cache。
Merge_Span(Span* span):合并前后相邻的 span 缓解外碎片。
_mut:锁的是 128 个槽位,和 central_cache 不一样,他是锁的单个槽位的锁。因为这里涉及到合并,即使锁住当前的槽位,可能会和其他槽位进行合并,也要加锁,这里就简单一些加个大锁,central_cache 而是只针对单个槽位的操作不会影响到其他槽位,所以用的是单个槽位的锁,不过 page_cache 也可以用单个槽位的锁。
Get_Span_Map(PAGE_ID pageid,void*& start):为了让 thread_cache 的小块对象都归还到对应的 span,这里后面讲。
_PC[PAGE_MAX]:128 个槽位。
Object_pool<Span> _obj:自定义 new吗,为了完全避免语言提供的内存申请接口。
Span:
page:向系统申请出来的虚拟地址转换成页号。
_n:该 span 有多少个页。
usecount:该 span 切割的小块对象的使用情况。
_obj_size:切割的小块内存块的大小。
_FreeList:指向第一块小块内存块对象。
_isuse:该 span 是否被使用。
三 公共函数
1. 自由链表
thread_cache 管理的单向自由链表,以自由链表本身指向下一个自由链表。
static void*& Next_Ptr(void* ptr) {return *(void**)ptr; }ptr指向某一个虚拟地址,强转成 void** ,意思就是一个二级指针指向 ptr 指向的虚拟地址的前 4/8 字节,也就是 void* 的大小,在解引用就得到 ptr 指向的虚拟地址的前 4/8 字节。
为什么不直接强转成 void*?void* 是没类型的,只是得到 ptr 指向的虚拟地址。
比如:强转成 int* ,也就是访问指向的地址的前 int 大小,相对应的强转成 void**,也就是访问指向的地址的前 void* 大小。
2. 向上对齐
前面说了 thread_cache 和 central_cache 的槽位管理的内存块和映射关系是一样的,所以要有专门处理用户申请的实际字节大小转换成对齐数在映射到对应的桶。
static inline size_t _Up_Size(size_t size,size_t algin) {if (size % algin == 0)return size;else return algin * (size / algin + 1); } static inline size_t Up_Size(size_t size) {if (size <= 128){return _Up_Size(size, 8);}else if (size <= 1024){return _Up_Size(size, 16);}else if (size <= 8 * 1024){return _Up_Size(size, 128);}else if (size <= 64 * 1024){return _Up_Size(size, 1024);}else if (size <= 256 * 1024){return _Up_Size(size, 8 * 1024);}else{return _Up_Size(size, 1 << PAGE_SHIFT);}return -1; } // 整体控制在最多10%左右的内碎片浪费 // [1,128] 8byte对齐 freelist[0,16) // [128+1,1024] 16byte对齐 freelist[16,72) // [1024+1,8*1024] 128byte对齐 freelist[72,128) // [8*1024+1,64*1024] 1024byte对齐 freelist[128,184) // [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)3. 映射槽位
根据不同的内存大小需求得到对齐实际的内存块,这里如果超过 256 KB,则直对齐到以页为单位。这里采用了除模方式得到对齐后的值,如果能整除则不用对齐,否则先除得到商 + 1 表示得到余数,在乘以对齐数就算出对齐后的值。用位运算也可以达到效果。
static inline size_t _Barrel_Index(size_t nsize,size_t algin) {if (nsize % 8 == 0)return nsize / algin - 1;else return nsize / algin; } static inline size_t Barrel_Index(size_t nsize) {assert(nsize <= TYPES_MAX);int arr[4] = { 16,56,56,56 };if (nsize <= 128){return _Barrel_Index(nsize,8);}else if (nsize <= 1024){return _Barrel_Index(nsize - 128,16) + arr[0];}else if (nsize <= 8 * 1024){return _Barrel_Index(nsize - 1024,128) + arr[1] + arr[0];}else if (nsize <= 64 * 1024){return _Barrel_Index(nsize - 8 * 1024,1024) + arr[2] + arr[1] + arr[0];}else if (nsize <= 256 * 1024){return _Barrel_Index(nsize - 64 * 1024,8*1024) + arr[3] + arr[2] + arr[1] + arr[0];}else assert(false);return -1; }根据对齐后的内存大小计算映射后的槽位。传入的必须小于等于 256 KB。如果 nsize 是对齐后的值则直接 nsize / algin - 1 ,- 1 是下标从0开始,否则直接 nsize / algin,丢的余数就不用 - 1 了。
四 申请/释放逻辑
1. 申请逻辑
1. 入口函数
void* Get_Memory(size_t size)
{// 如果大于 256 KB 直接向 span_cache 获取以页为单位的内存块if (size > TYPES_MAX){// 按页对齐size_t nsize = Barrel_Index_Nsize::Up_Size(size);// 加锁Page_Cache::Get()->_mut.lock();Span* span = Page_Cache::Get()->Get_Span(nsize >> PAGE_SHIFT);span->_obj_size = nsize;Page_Cache::Get()->_mut.unlock();// 根据返回的 span 里的页号得到实际的虚拟地址,也就是 * 8 KBvoid* ptr = (void*)(span->page << PAGE_SHIFT);return ptr;}else{// 如果 thread_cache 静态对象为空则申请一个 thread_cacheif (TLS_ptr == nullptr){static Object_pool<List_Frees> _obj;TLS_ptr = _obj.New();//TLS_ptr = new List_Frees;}// 获取内存//return TLS_ptr->Get_Memory(size);void* ptr = TLS_ptr->Get_Memory(size);return ptr;}
}这里首先根据用户申请的内存大小,如果大于 256 KB 则直接向 span_cache 获取 span,并计算 span 里的页号转换成实际的 虚拟地址,这里 span 初始化页号是 除 8KB,所以这里要 * 8KB。
否则小于 256 KB 大小,首先判断 thread_cache 是不是为空,如果为空则初始化,否则直接向 thread_cache 里申请内存,这里可能有多线程,不同的线程各自私有自己的 thread_cache,所以每一个新的线程都要先申请一个新的 thread_cache。
2. thread_cache 获取内存
1. Get_Memory(size):
void* List_Frees::Get_Memory(size_t size)
{assert(size > 0 && size <= TYPES_MAX);size_t nsize = Barrel_Index_Nsize::Up_Size(size);size_t index = Barrel_Index_Nsize::Barrel_Index(size);if (!_LF[index].empty()){return _LF[index].pop_back();}void* ptr = Get_Central_Memory(nsize, index);return ptr;
}首先是断言必须大于 0 并且小于 256 KB,然后计算对齐数和映射槽位。
然后就是判断该槽位是否有自由链表,如果有直接弹出,否则去 cenral_cache 去取一定范围的小块内存对象。
_LF[index].empty():
bool empty() { return _Free_ptr == nullptr; }_LF[index].pop_back():
void* pop_back() {assert(_Free_ptr != nullptr);void* obj = _Free_ptr;_Free_ptr = Next_Ptr(obj);Size--;return obj; }让 obj 指向该槽位的第一个自由链表,然后把第一个自由链表给弹出去并让该槽位指向第一个自由链表的下一个自由链表,也就是指向第一个自由链表的前 4/8 字节,也就是下一个自由链表。
2. Get_Central_Memory(nsize, index):
void* List_Frees::Get_Central_Memory(size_t nsize, size_t index)
{// 要批量,慢增长size_t batch = min(Barrel_Index_Nsize::Batch_Size(nsize), _LF[index].Getbatech_size());if (batch == _LF[index].Getbatech_size()){_LF[index].Getbatech_size()++;}void* start = nullptr;void* end = nullptr;// 实际给多少个size_t Actual_size = Central_Cache::Get_S_C()->Get_One_Ranges(start, end, nsize, batch);assert(Actual_size>0);if (Actual_size == 1){assert(start == end);return start;}// 拿一个,剩下挂里面void* tmp = start;_LF[index].push_Ranges(Next_Ptr(start), end, Actual_size - 1);Next_Ptr(tmp) = nullptr;return tmp;
}首先根据该槽位里的 _LF[index].Getbatech_size() 也就是 batch_size 字段 和 Barrel_Index_Nsize::Batch_Size(nsize) 根据传入的对齐后的内存大小,来计算实际要多少个自由链表,这里最开始初始化的时候 batch_size 字段为 1。
3. Barrel_Index_Nsize::Batch_Size(nsize):
static inline size_t Batch_Size(size_t size) {size_t nbatch = 0;if (TYPES_MAX / size < 2)nbatch = 2;else if (TYPES_MAX / size > 512)nbatch = 512;else nbatch = TYPES_MAX / size;return nbatch; }根据对齐后的大小计算实际要的内存块个数。
如果被 256 KB 除后小于 2,则给 2 个,比如:256 KB / 256 KB。
如果被 256 KB 除后大于 512,则给 512 个,比如 256 KB / 8 byte。
否则直接按 256 KB / size。
所以在槽位里的 batch_size 字段和 Barrel_Index_Nsize::Batch_Size(nsize) 算出的个数取最小的那个,如果选择的是 batch_size 字段则让他 ++,后面会不断的要更大的数量,直到比 Barrel_Index_Nsize::Batch_Size(nsize) 更大,然后返回指针。
否则如果槽位没有自由链表则去 central_cache 去取一个范围的内存块。
2. Central_cache 获取内存:
1. Central_Cache::Get_S_C()->Get_One_Ranges(start, end, nsize, batch):
size_t Central_Cache::Get_One_Ranges(void*& start, void*& end, size_t nsize, size_t batch) {// 加桶锁size_t index = Barrel_Index_Nsize::Barrel_Index(nsize);_CC[index]._mtu.lock(); // 这里是向中心缓存申请的时候加的锁Span* span = Get_Span(_CC[index],nsize);// 不可能为空assert(span && span->_FreeList != nullptr);start = span->_FreeList;end = start;// 取一段范围,不够拿实际取的范围size_t cnt = 1;size_t k = 0;while (Next_Ptr(end) != nullptr && k < batch-1){cnt++;end = Next_Ptr(end);}span->usecount += cnt;span->_FreeList = Next_Ptr(end);Next_Ptr(end) = nullptr;_CC[index]._mtu.unlock();return cnt; }首先去 central_cache 槽位取 span 必须加对应的桶锁,这里可能获取不到则去下一层去取,假设获取到了,则去取一个范围的内存块并进行切割,这里可能取不到实际想要的批量,比如只有一个内存块,但要 10 个批量的,所以用个计数器来记录实际获取到了多少个内存块,循环条件则是以当前后面的内存块不能为空和符合一个批量内存块结束,结束 span 里的 usecount += 实际拿的批量内存块,并链接 span 的 _FreeList 指针指向拿的批量的最后一个内存块的下一个内存块,可能为空,并让拿到的这个批量的最后一个内存块的下一个内存块为空,并解锁返回给 thread_cache 拿去头部一个剩余的挂到 thread_cache 对应的桶里。
2. Get_Span(_CC[index],nsize):
Span* Central_Cache::Get_Span(SpanList& splist,size_t nsize) {auto it = splist.Begin();// 如果有直接返回while (it != splist.End()){if (it->_FreeList != nullptr){return it; //然后你在这里把锁解开了 你的}else it = it->_next;}// 桶锁解了,后续可能回收span给页缓存splist._mtu.unlock();// 获取span,加大锁Page_Cache::Get()->_mut.lock();Span* span = Page_Cache::Get()->Get_Span(Barrel_Index_Nsize::Page_Num(nsize));span->_obj_size = nsize;span->_isuse = true;Page_Cache::Get()->_mut.unlock();// 算页号对应的地址和结束地址char* start = (char*)(span->page << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;span->_FreeList = start;start += nsize;void* tail = span->_FreeList;// 切成小块对象挂起来int cnt = 1;while (start < end){cnt++;Next_Ptr(tail) = start;tail = Next_Ptr(tail);start += nsize;}Next_Ptr(tail) = nullptr;// 头插到桶里splist._mtu.lock();splist.Push_Front(span);return span; }刚才获取一个批量的函数里调用了获取一个 Span,那么这个 Span 至少有一个内存块。
首先遍历 central_cache 该槽位所有的 Span 并找到一个至少有一个内存块的 Span,如果有直接返回,否则取 Span_cache 缓存去取,这里如果去 Span_cache 去取则可以解 central_cache 的桶锁,因为去 Span_cache 会加他自己的全局大锁,即使有多个线程同时去 Span_cache 去取 Span 也只有一个线程能申请到 Span。
假设获取到了一个完整的 Span,则设置该 Span 的参数字段,_obj_size:该 Span 管理的内存块大小,_isuse:该 Span 是否被使用,然后解锁,因为只有一个线程能获取到 Span 且该 Span 已经从 Page_cache 移除,其他线程拿不到。
然后根据 Span 的页号 *= 8 KB得到起始的虚拟地址并计算他的总共有多少内存,也就是 n *= 8 KB,n 是一共有多少页,加上起始地址就是该 Span 的结束地址,得到 Span 的起始地址和结束地址,就可以按照管理的小块内存快进行切割挂起来,结束并加锁,因为这里要挂到 central_cache 里,后续返回到获取一个范围的内存块函数后面会解锁。
3. Barrel_Index_Nsize::Page_Num(nsize):
static inline size_t Page_Num(size_t size) {int n = Batch_Size(size);int page = n * size;page >>= PAGE_SHIFT;if (page == 0)page = 1;return page; }假设 size == 8,这里 n 算出来的是 512 ,然后 /= 8 KB 等于 0.至少给 1 页。
假设 size == 256 KB,这里 n 算出来的是 2,2 * 256 KB,然后 /= 8KB 等于 64页。
3. Page_cache 获取内存:
1. Page_Cache::Get()->Get_Span(Barrel_Index_Nsize::Page_Num(nsize)):
Span* Page_Cache::Get_Span(size_t k) {if (k > PAGE_MAX - 1){void* ptr = Get_Big_Memory(k);Span* span = _obj.New();//Span* span = new Span;span->page = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;//Map_Span[span->page] = span;Tree_Map.set(span->page, span);return span;}// 有直接返回if (!_PC[k].Empty()){Span* span = _PC[k].Pop_Front();for (size_t i = span->page;i < span->page + span->_n;i++){//Map_Span[i] = span;Tree_Map.set(i, span);}return span;}// 向后找for (int i = k + 1;i < PAGE_MAX;i++){if (!_PC[i].Empty()){// 切分Span* kspan = _obj.New();//Span* kspan = new Span;Span* nspan = _PC[i].Pop_Front();kspan->page = nspan->page;kspan->_n = k;nspan->page += k;nspan->_n -= k;_PC[nspan->_n].Push_Front(nspan);/*Map_Span[nspan->page] = nspan;Map_Span[nspan->page + nspan->_n - 1] = nspan;*/Tree_Map.set(nspan->page,nspan);Tree_Map.set(nspan->page + nspan->_n - 1,nspan);for (size_t i = kspan->page;i < kspan->page + kspan->_n;i++){//Map_Span[i] = kspan;Tree_Map.set(i, kspan);}return kspan;}}// 一个也没有向系统申请128页的spanvoid* ptr = Get_Big_Memory(PAGE_MAX - 1);Span* Big_Span = _obj.New();//Span* Big_Span = new Span;Big_Span->page = (PAGE_ID)ptr >> PAGE_SHIFT;Big_Span->_n = PAGE_MAX - 1;_PC[Big_Span->_n].Push_Front(Big_Span);return Get_Span(k); }根据 Barrel_Index_Nsize::Page_Num(nsize) 算出的页。
首先判断如果该页大于 128 页则直接向系统分配,并 new 一个 Span 对申请的虚拟地址进行管理,设置字段页号和页数量,并让页号 Span 进行映射后续释放要用到,这里后面说。
否则直接去对应的 Span 桶里找 Span,如果有先拿出来并把他的所有的页数量全部都和他锁管理的 Span 进行映射。
比如:页号是 10,页数量是 5,把 10,11,12,13,14 全部都和他所管理的 Span 进行映射。
否则对应的槽位找不到则去比他大的页号里面去取 Span 并切成 2 块不同的 Span ,一块返回,一块插入到剩余的槽位里。
比如:需要一个10 页是 Span,找到一个 15 页的 Span。
首先 new 一个 Span 对象,并让这个 Span 的页号等于 15 页的 Span 的页号,并让这个 Span 的页数量等于 10,并让 15 页的 Span 的页号 += 10 页跳过中间的 10 页,因为给 new 出来的 Span 用来,然后让他的页数量 -= 10。
然后这个 15 页的 Span 变成 5 页的 Span 并插入到 5 页的槽位。
当获取到 Span 和前面获取大于 128 页的一样,把他从页号开始的每个页按页数量进行映射他所管理的 Span,这里额外多了一部操作,就是把 5 页的 Span 的起始地址和结束地址都进行了和他所管理的 Span 进行映射,和切出去的不一样,这里切出去的是为了后续归还小块内存块,这个 5 页的 Span 是为了后续进行合并前后相邻页,要查找与该页号相邻的页是否空闲,如空闲则合并。
否则一个找不到,则直接去向系统申请 128 页的 Span。
并设置他的字段,前面超过 128 页的分配和这里一样,只不过这里不需要映射,因为 128 页不需要和任何页合并,否则只会合出超过 128 的页不合理,前面超过 128 页的分配映射是为了归还的时候要找到对应的 Span,不需要合并,因为大于 128 KB 的页不归 Span_cache管,然后进行递归重新查找合适的页。
至此申请逻辑结束。
2. 释放逻辑
1. 入口函数
void Free_Memory(void* ptr)
{// 直接索引对应的span//Span* span = Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT));Span* span = (Span*)Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT), ptr);size_t size = span->_obj_size;if (size > TYPES_MAX){// > 32k || > 128k Page_Cache::Get()->_mut.lock();Page_Cache::Get()->Merge_Span(span);Page_Cache::Get()->_mut.unlock();}// <= 32kelse TLS_ptr->Free_Memory(ptr, size);
}
首先申请内存块的时候,central_cache 会从 Span_cache 拿去一个 span 并把这个 span 的页号和页数量依次和该 span 进行映射,所以这里释放先把指针转成页号在根据曾经的映射的 span 进行索引查找得到实际的 span,如果得出来的 span 管理的小块内存大于 256 KB,则直接归还到系统并且加 Span_cache 的全局锁。
2. Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT)):void Page_Cache::Merge_Span(Span* span) {// 大于128pageif (span->_n > PAGE_MAX - 1){void* ptr= (void*)(span->page << PAGE_SHIFT);Free_Big_Memory(ptr);_obj.Recovery_space(span);//delete span;return;}while (1){PAGE_ID previd = span->page - 1;//auto merspan = Map_Span.find(previd);Span* merspan = (Span*)(Tree_Map.get(previd));if (merspan == NULL)break;//if (merspan->second->_isuse == true)break;if (merspan->_isuse == true)break;//if (merspan->second->_n + span->_n > PAGE_MAX - 1)break;if (merspan->_n + span->_n > PAGE_MAX - 1)break;// 合并/*span->page = merspan->second->page;span->_n += merspan->second->_n;*/span->page = merspan->page;span->_n += merspan->_n;//_PC[merspan->second->_n].Pop_Front();//_PC[merspan->second->_n].Erase(merspan->second);_PC[merspan->_n].Erase(merspan);//_obj.Recovery_space(merspan->second);_obj.Recovery_space(merspan);//delete merspan->second;}while (1){PAGE_ID previd = span->page + span->_n;//auto merspan = Map_Span.find(previd);Span* merspan = (Span*)(Tree_Map.get(previd));//if (merspan == Map_Span.end())break;if (merspan == NULL)break;//if (merspan->second->_isuse == true)break;if (merspan->_isuse == true)break;//if (merspan->second->_n + span->_n > PAGE_MAX - 1)break;if (merspan->_n + span->_n > PAGE_MAX - 1)break;// 合并//span->_n += merspan->second->_n;span->_n += merspan->_n;//_PC[merspan->second->_n].Pop_Front();//_PC[merspan->second->_n].Erase(merspan->second);_PC[merspan->_n].Erase(merspan);//_obj.Recovery_space(merspan->second);//delete merspan->second;_obj.Recovery_space(merspan);} //插入/*Map_Span[span->page] = span;Map_Span[span->page + span->_n - 1] = span;*/Tree_Map.set(span->page, span);Tree_Map.set(span->page + span->_n - 1, span);span->_isuse = false;_PC[span->_n].Push_Front(span); }如果得出来的 span 的页数量大于 128 页则直接归还给系统,根据页转换成虚拟地址并释放给系统。
否则:合并前后相邻页。
合并前面相邻页:
假设 span 页号是 10,页数量是 5,也就是 10 ~ 14 属于这个 span,查找页号是 9 的 span 是否在某个槽位,如果找不到或者找到了但是被 central_cache 使用或者合并之后超过 128 页则直接退出,如果找到了则:
前面相邻的 kspan 页号是 x,页数量是 x,让当前的 span 的页号等于 kspan 的页号,页数量 += kspan 的页数量即可,并从 span_cache 槽位弹出并释放 kspan。
合并后面相邻页:
假设 span 页号是 10,页数量是 5,也就是 10 ~ 14 属于这个 span,查找页号是 15 的 span 是否在某个槽位,如果找不到或者找到了但是被 central_cache 使用或者合并之后超过 128 页则直接退出,如果找到了则:
后面相邻的 kspan 页号是 y,页数量是 y,当前 span 的页号不变,页数量 += kspan 即可,并从 span_cache 槽位弹出并释放 kspan。
最后再次把 合并后的 span 的起始虚拟地址和结束虚拟地址进行个 span 映射,这里可能没合并,映射则会无效,因为之前这个 span 本身就已经映射了。
注意上述的 kspan 释放的时候不会结束映射关系,因为只要 span 被弹出拿出去用了才会建立映射,空闲的 span 是不会映射的。
再次转到入口函数:
void Free_Memory(void* ptr) {// 直接索引对应的span//Span* span = Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT));Span* span = (Span*)Page_Cache::Get()->Get_Span_Map(((PAGE_ID)ptr >> PAGE_SHIFT), ptr);size_t size = span->_obj_size;if (size > TYPES_MAX){// > 32k || > 128k Page_Cache::Get()->_mut.lock();Page_Cache::Get()->Merge_Span(span);Page_Cache::Get()->_mut.unlock();}// <= 32kelse TLS_ptr->Free_Memory(ptr, size); }如果得到的 span 管理的小块内存块不大于 256 KB 则直接还到 thread_cache 里。
3. TLS_ptr->Free_Memory(ptr, size):
void List_Frees::Free_Memory(void* ptr,size_t size) {assert(ptr != nullptr && size > 0);size_t index = Barrel_Index_Nsize::Barrel_Index(size);_LF[index].push_front(ptr);// 大于一个批量归还if (_LF[index].Get_Size() >= _LF[index].Getbatech_size()){void* start = nullptr;void* end = nullptr;_LF[index].Pop_Ranges(start, end, _LF[index].Getbatech_size());Central_Cache::Get_S_C()->Give_Spans_Index(start, index);} }根据传入的指针和小块内存块的大小放到对应的 thread_cache 槽位。
如果该槽位的自由链表的数量大于该槽位向 central_cache 申请的批量内存块个数时,则把该槽位按批量的个数从头开始还到 central_cache 里。并让 2 个指针指向这个批量内存块的头和尾。
4. Central_Cache::Get_S_C()->Give_Spans_Index(start, index):
void Central_Cache::Give_Spans_Index(void*& start, size_t index) {_CC[index]._mtu.lock();while (start != nullptr){// 存下一个小对象void* tail = Next_Ptr(start);PAGE_ID ret = (PAGE_ID)start >> (PAGE_SHIFT);// 索引 pageid 映射的 span//Span* span = Page_Cache::Get()->Get_Span_Map(ret,start);Span* span = (Span*)(Page_Cache::Get()->Get_Span_Map(ret, start));span->usecount--;Next_Ptr(start) = span->_FreeList;span->_FreeList = start;// 都回来了,在还if (span->usecount == 0){_CC[index].Erase(span);span->_FreeList = nullptr;span->_next = nullptr;span->_prev = nullptr;_CC[index]._mtu.unlock();Page_Cache::Get()->_mut.lock();Page_Cache::Get()->Merge_Span(span);Page_Cache::Get()->_mut.unlock();_CC[index]._mtu.lock();}start = tail;}_CC[index]._mtu.unlock(); }首先加 central_cache 的桶锁,把这批范围的内存块全部依次放入到 central_cache 对应的 span 当中,根据这批范围的内存块的地址得到页号并查表得到对应的 span,并让 span 的 _usecount--,如果等于 0 则表示该 span 的小块对象全部都回来了则直接从 central_cache 某个槽位弹出并还到 span_cache 中,并加 span_cache 的全局锁,这里 Merge_Span(span),刚刚的函数说过,这里就不再多说了,自此释放逻辑结束。
五 高并发优化
前面的建立映射可以用 unordered_map/map 进行映射,但可能会有问题,因为虽然只有在 central_cache 归还一个批量的小块内存块的时候进行查找了并加了桶锁,但 span_cache 添加新的 span 映射的时候:
map:增加节点的时候可能会造成红黑树的调整逻辑导致查找的时候数据混乱。
unordered_map:增加节点的时候可能会引起哈希表的扩容导致查找的时候原数据被释放导致未定义。
虽然查找的时候是有锁进行保护,但增加的时候是不受 central_cache 的桶锁限制,首 span_cache 的全局锁限制,所以并发导致的增加和查找会有线程安全问题,除非增加或者查找的时候同时进行加锁,但会导致效率降低,下面来看看基数树采用的结构。
基数树:
按照 bit 位提前开好空间,保证涵盖所有的页号。
单层基数树:
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = Barrel_Index_Nsize::Up_Size(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};BITS:根据他的大小,实例化 array_ 数组的大小,具体是按 2^BITS 次方来保证涵盖所有的页号,比如一页是 8 KB,总共需要的页号就是 2^32 / 2^13 = 2^19,数组大小总共 2^19 。
而单层基数树,只有一个数组,传入页号直接索引下标取 void* 即可,插入就转换为直接设置赋值即可,因为空间已经提前开好了。
双层基数树:
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocatorpublic:void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);assert(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}};
双层里的第一层则不是存放的实际要返回的指针,而是指向实际要返回的指针数组里某个指针的索引。
比如和单层基数树一样按 8 KB 为一页。
ROOT_LENGTH :该字段决定第一层基数树的大小,也就是 2^ROOT_BITS 次方大小为 32。
LEAF_LENGTH :该字段决定第二层基数树的大小,也就是 2^LEAF_BITS 次方大小为 2^14。
set:i1:把 k 右移 LEAF_BITS 取到头部 5 bit 位,得到第一层基数树的某个下标,i2:得到中间 14 bit 位得到第一层基数树的某个下标指向的另一个指针数组的下标,即最终要返回的值,然后设置为传入的 v 指针。
get:和上面类似,如果有直接返回,否则直接返回空。
单层和双层紧紧针对 32 位平台,如果 64 位平台紧紧是 2 层是不够的,比如还是按 8 KB 为一页,剩余 2^64 - 13 = 2^51,假设第一层还是用了 5 个 bit 位,第二层用 49 个 bit 位明显是开不出来这么大的空间的,就算对半开整体还是 2^24 * 2^25 次方。所以这里要扩展成 3 层 甚至 4/5 层基数树。