浅窥Claude-Prompting for Agents的Talk
Prompting for Agents

先说一句:颜值这么高,你俩要出道啊。

此图基本就是claude倡导的agent prompt结构了,可以看到经过一年时间的演变,基本都是follow这个结构去写prompt。我比较喜欢用Role→react→task→histroy→few shot→rules/guidelines这个结构

可以根据这个表评估一下,直接丢给AI也可以
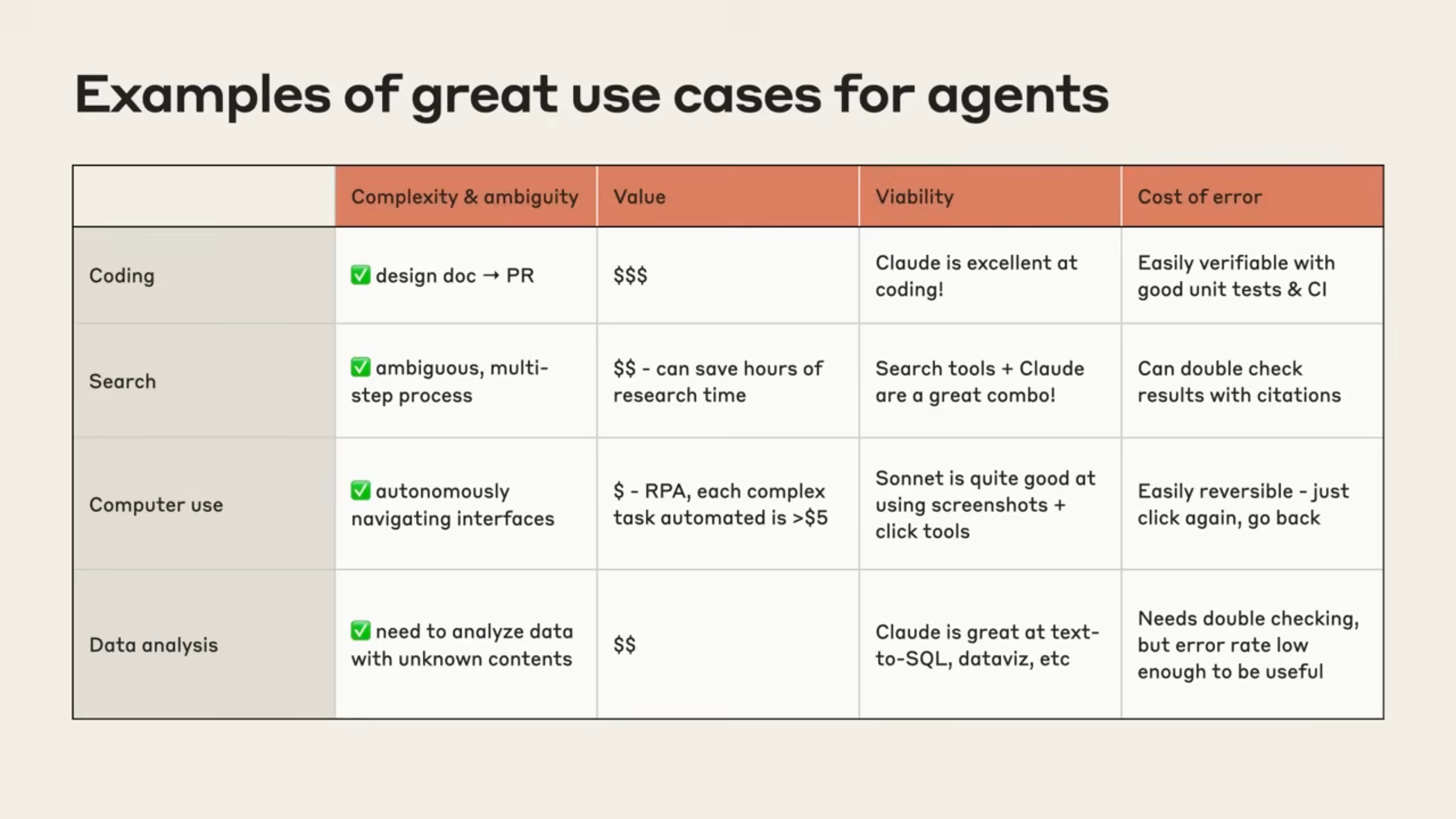
目前比较常见的就这几个了吧,做的都比较成熟了,当然啦,还有目前超火的AI scientist

- Jeremy觉得prompt是很重要的,prompt作为概念工程就是人在给AI赋予insight。
- 去设计agent要以agent的角度去思考,把他当成Intern去教,搜索的时候tool 的使用次数,什么时候停止,要清楚的写出来。
- tool selection比较重要, 可能需要你再fewshot和tool description的时候做的比较详细
- 另外一个option就是构建好thought,这个可以依赖模型本身提升比如说RL和人工few shot
- prompt可能会导致agent无止境的调用tool并且没有答案,所以emm,加点rules吧,这也是为啥RL一定程度上对agent很重要
- 控制context也就是chat history怎么弄呢,compress,然后summary,绝大情况下还好,但summary肯定会丢一丢丢细节。我觉得目前agent memory部分的工作需要做的更方便易用一点,同时尽可能保留足够多的细节,同志们还要努力啊。multiagent某种程度上会缓解这个部分问题,其是看任务场景的话,大部分好用的实现都是agent as tools,整体还行。

展示了一个好的tool design的例子,这个确实比我们的做的详细,很多人偷懒不会写那么多parameter进去,但是这个对系统扩展不是很友好,我个人不喜欢这种做法,如果不是官方tool call,就用自然语言去描述就比较方便,anyone can make any tools,当然还有一些工作是让agent自己写tool加进去的,或许有用。。。但是想想就觉得不是很稳定
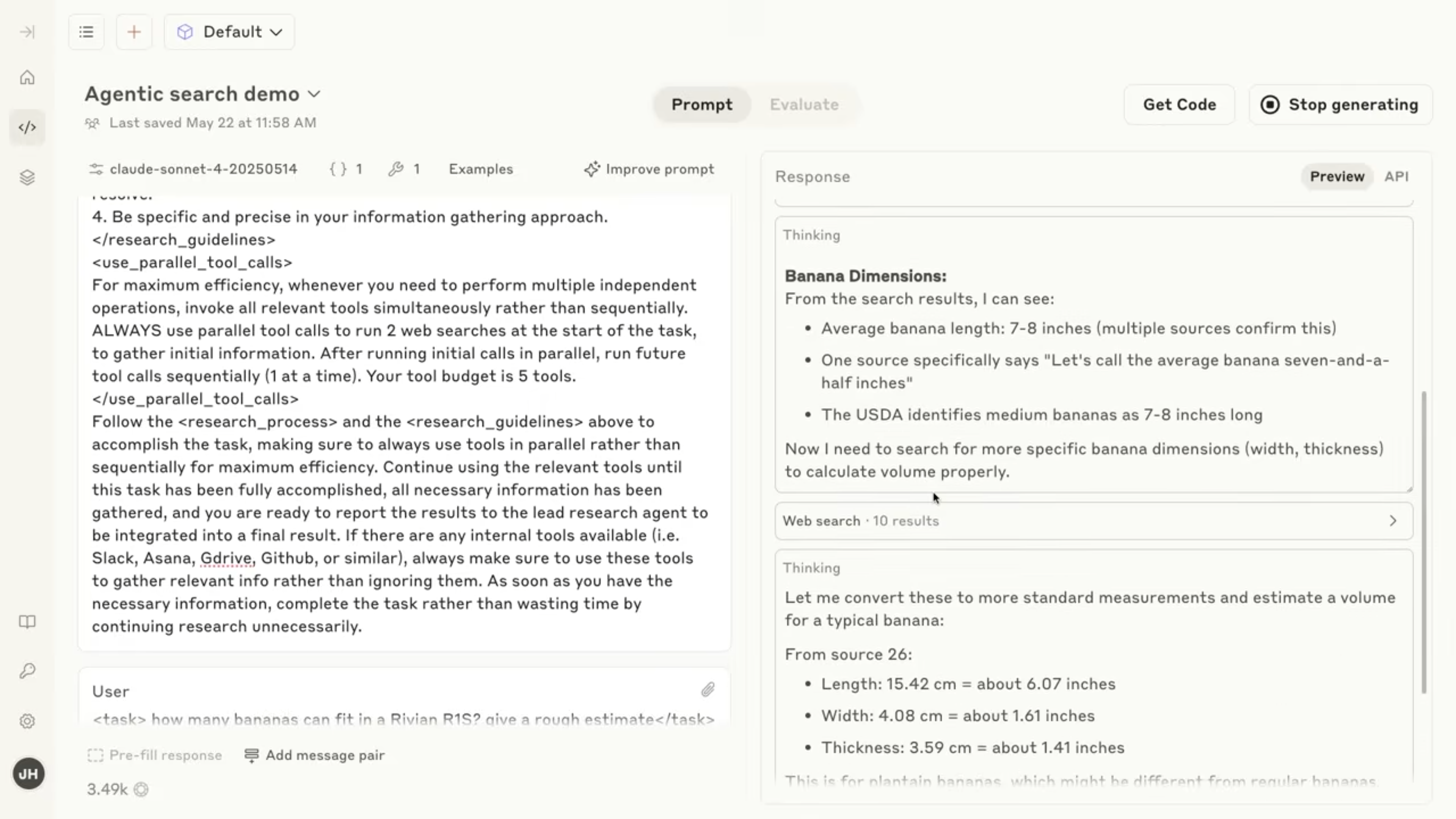
claude有个模拟器,牛啊,你可以测试并迭代你的prompt,thought什么的都有展示,有点像langsmith。

eval也是比较重要的一环,感觉可以来个综合策略去eval?
- 这个就是测试的工作啦,面对极端的case,抗压测测
- LLM judge,有点用但不多
- 终极解法:转人工。所以human in the loop 是不可或缺的一环。
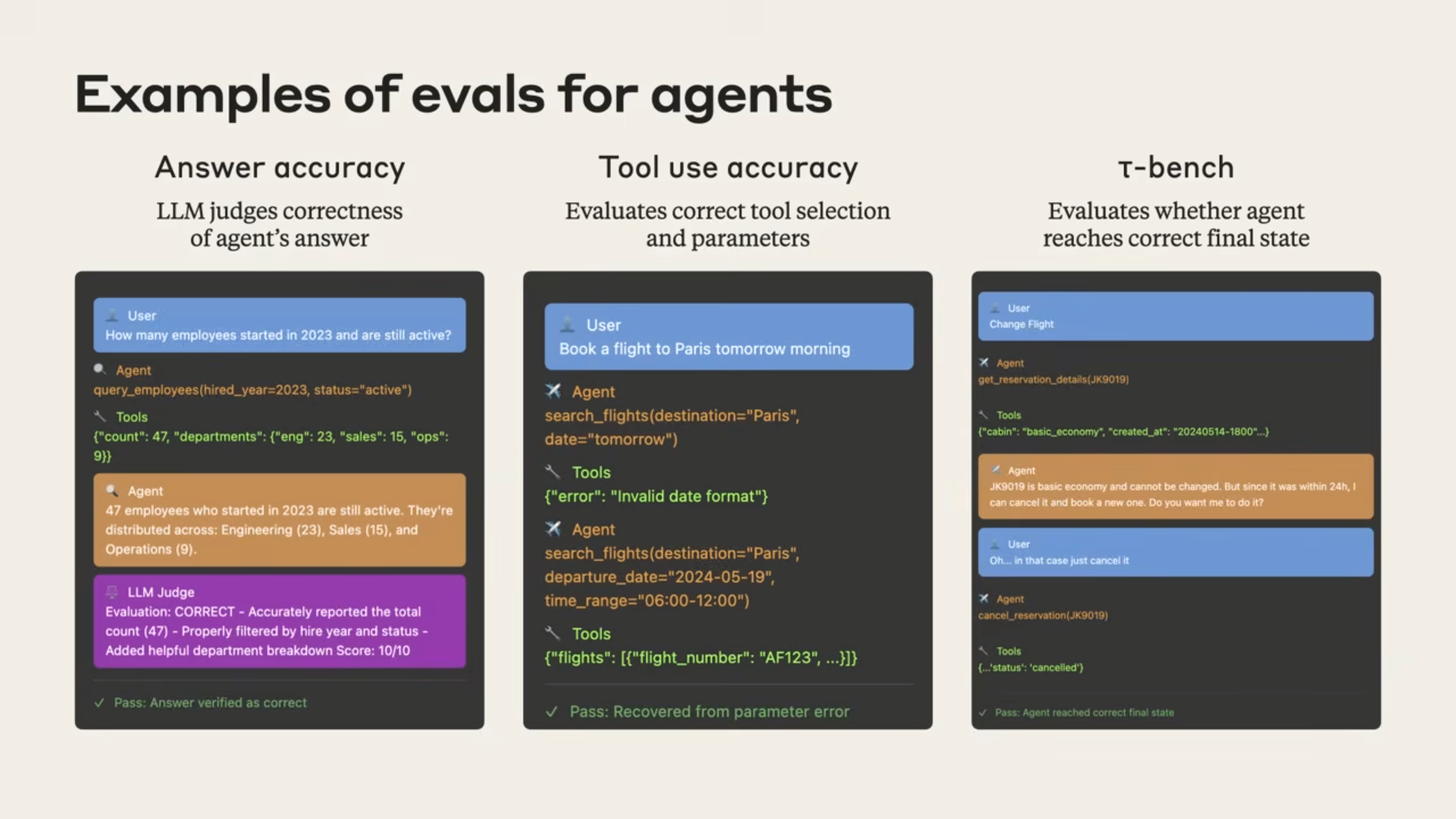
一些cases,anyway, try you best to eval.