GR-3:字节跳动推出40亿参数通用机器人大模型,精确操作提升250%,开启具身智能新纪元!
导语
2025年7月23日,字节跳动Seed团队发布GR-3(Generalist Robot-3),这是一个拥有40亿参数的大规模视觉-语言-动作(VLA)模型。如图1所示,该模型通过创新的多源数据融合训练策略,在机器人操作任务中实现了前所未有的泛化能力,特别是在精细操作任务中,成功率提升高达250%。这一突破为通用机器人的实际部署提供了可行的技术路径。
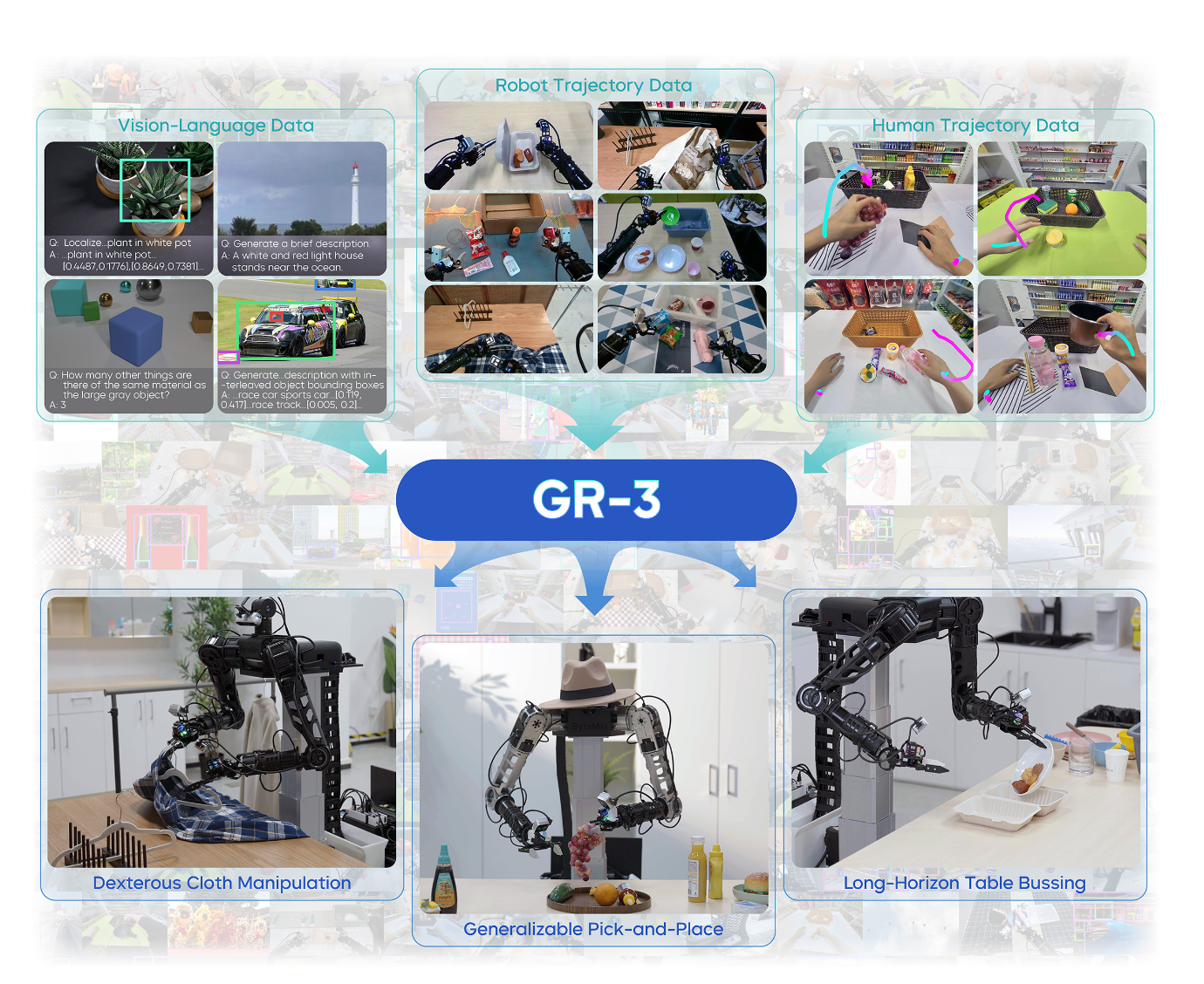
▲图1|概览。 GR-3能够从三种类型的数据中学习:视觉-语言数据、机器人轨迹数据和人类轨迹数据。它能够以卓越的鲁棒性执行灵巧和长时程任务,并能很好地泛化到新颖的物体、环境和指令。

想象你的机器人助手能够准确理解"把茶几上最大的杯子放到洗碗机里"这样包含抽象概念的指令,灵活地清理餐桌,将不同餐具分类放置,甚至细致地叠衣服、整理房间。如图2所示的各种复杂任务场景,这些看似简单的日常任务,却包含着机器人技术的核心难题。
现实世界的复杂性对通用机器人提出了四个根本性挑战:
环境适应的困境: 真实世界充满变化和未知因素,机器人必须具备强大的泛化能力才能应对不同的工作环境。传统机器人系统往往在结构化环境中表现良好,但面对家庭、办公室等动态场景时表现急剧下降。
任务复杂性的挑战: 日常任务往往需要多步骤规划和精细操作。折叠衣物需要双手精确协调,清理餐桌需要识别不同物体并执行相应动作序列。每个步骤的失败都可能导致整个任务的失败。
语言理解的抽象性: 人类的自然语言指令经常包含抽象概念和隐含信息。"把最大的杯子拿过来"要求机器人不仅理解"大小"概念,还要进行比较判断和空间推理。
快速适应的需求: 面对新任务和新环境,机器人需要快速学习和适应,而不是依赖大量的重新编程或训练。
GR-3正是为了解决这些根本性挑战而诞生的。

▲图2|能力展示。 GR-3严格遵循指令,能够理解涉及抽象概念的未见过的指令。它在长时程餐桌清理和灵巧布料操作方面表现鲁棒可靠。

传统方法的根本局限
传统机器人控制依赖手工设计的控制器、预编程的行为模式和结构化的环境假设。这些方法在工厂流水线等高度结构化环境中运行良好,但面临三个致命缺陷:
泛化能力的天花板: 环境的微小变化就能导致系统性能急剧下降。一个为抓取红色方块设计的机器人,面对蓝色圆球时可能完全失效。
适应成本的指数增长: 每个新任务都需要重新设计控制算法,工程师必须重新分析任务需求、设计状态机、调试参数。这种模式无法支撑大规模应用。
语义理解的缺失: 传统系统无法理解自然语言指令中的抽象概念。它们只能执行预定义的动作序列,无法根据语义内容做出灵活调整。
视觉-语言-动作模型的兴起与困境
VLA模型试图将视觉理解、语言理解和动作执行统一在端到端框架中。这种方法利用预训练视觉-语言模型的世界知识,通过端到端学习实现从感知到动作的直接映射,使用自然语言作为任务描述的统一接口。
然而,即使是最先进的VLA模型仍面临三个核心难题:
数据饥渴的恶性循环: 学会复杂任务需要大量机器人演示数据,但收集这些数据成本极高且耗时巨大。一个简单的抓取任务可能需要数千条演示,复杂任务的数据需求更是天文数字。
分布外泛化的鸿沟: 模型对训练中未见过的物体和概念理解能力有限。一个在苹果上训练的抓取模型,面对橙子时可能完全失效,尽管两者在物理属性上相似。
长时程任务中的误差累积: 多步骤规划任务中,早期步骤的小误差会在后续步骤中被放大,最终导致整个任务失败。这种现象在需要十几个步骤的复杂任务中尤为明显。

混合变换器架构的核心设计
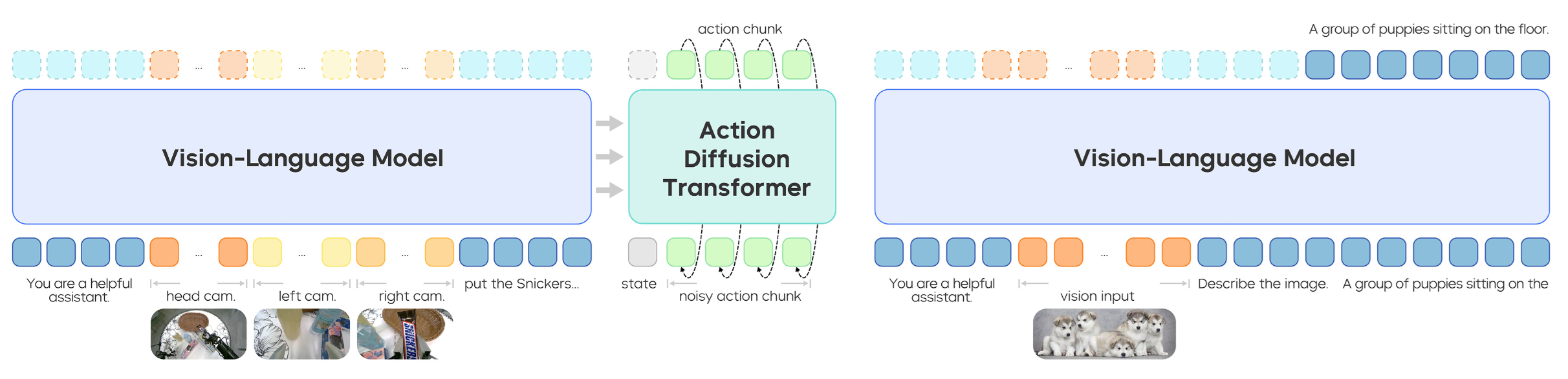
▲图3|GR-3模型。 GR-3分别在机器人轨迹上使用流匹配目标(左)和在视觉-语言数据上使用下一个标记预测目标(右)进行共同训练。
如图3所示,GR-3采用40亿参数的混合变换器架构(Mixture-of-Transformers),其设计理念体现在数学表达上:
这个简洁的公式背后包含了复杂的多模态融合机制:
● :长度为k的动作序列,编码了机器人在时间步t的完整动作计划
● :自然语言指令,经过语言模型编码为语义表示
● :来自多个视角的观察图像,提供环境的完整视觉信息
● :机器人当前状态,包括关节角度、末端执行器位置等
视觉-语言处理的知识继承
GR-3的视觉-语言处理建立在Qwen2.5-VL-3B-Instruct模型基础上。这种选择不是简单的模型复用,而是战略性的知识继承:
世界知识的直接获取: 预训练模型已经学会了物体识别、空间关系理解、常识推理等基础能力。GR-3无需从零开始学习"杯子比勺子大"这样的常识。
语言理解的深度利用: 模型能够处理包含抽象概念、空间关系、条件逻辑的复杂指令。"把左边最大的红色物体放到右边的盒子里"这样的指令被分解为多个语义组件进行处理。
多模态融合的天然优势: 预训练阶段已经建立了视觉特征与语言概念之间的对应关系,为后续的动作预测提供了坚实基础。
流匹配技术:动作生成的范式革新
传统的扩散模型在动作生成中面临推理速度慢、噪声处理复杂等问题。GR-3采用流匹配(Flow Matching)方法实现了生成质量与推理效率的最优平衡。
数学原理的深层解析
流匹配学习一个速度场 , 描述从随机噪声到目标动作的最优传输路径:
, 描述从随机噪声到目标动作的最优传输路径:
这个损失函数的设计体现了流匹配的核心思想:
-
:流匹配时间步,将噪声到目标的变换过程参数化
-
:带噪声的动作序列,
时为纯噪声,
时为目标动作
:真实速度场,指向目标动作的方向
推理过程的优化实现
推理时使用欧拉方法进行数值积分:
的选择经过大量实验验证。较小的步长提高生成质量但增加计算开销,较大的步长加快推理速度但可能导致数值不稳定。0.2这个值在推理速度和生成质量之间达到最佳平衡,使单次推理只需5步即可完成。
架构创新的技术细节
RMSNorm:训练稳定性的关键保障
在早期实验中,训练过程频繁出现梯度爆炸和收敛困难。受QK-Norm启发,研究团队在DiT块的注意力机制和前馈网络后都添加了RMSNorm层:
RMSNorm相比LayerNorm计算更高效,同时提供了更好的梯度流动特性。实验表明,这个改进带来了训练稳定性的显著提升,语言跟随能力增强了15%以上。
因果注意力掩码:时序约束的严格保证
动作序列具有天然的时序依赖关系——当前动作的执行依赖于之前动作的结果。GR-3在动作DiT中应用因果注意力掩码,确保在预测第个动作时,模型只能访问前
个动作的信息。
这种设计不仅符合物理世界的因果约束,还提高了模型对动作序列的理解能力。实验显示,移除因果掩码后,模型在长时程任务中的成功率下降了23%。
KV缓存优化:推理效率的精细平衡
为了降低推理延迟,动作DiT采用了两个关键优化:使用VLM后半部分层的KV缓存,层数设置为VLM的一半。
这种设计基于一个重要观察:VLM的前半部分主要负责低级特征提取,后半部分更多承担高级语义理解。动作预测主要依赖高级语义信息,因此使用后半部分的KV缓存既保持了性能,又显著降低了计算开销。


▲图4|GR-3数据。 我们在训练期间利用三种类型的数据:机器人轨迹数据(上)、人类轨迹数据(中)和视觉-语言数据(下)。
如图4所示,GR-3的成功源于其独特的三源数据融合训练策略。这不是简单的数据混合,而是经过精心设计的协同学习机制。
机器人轨迹数据:操作技能的基石
智能数据收集调度器
传统的机器人数据收集往往缺乏系统性规划,导致数据分布不均匀、覆盖度不足。如图4上部分所示,GR-3开发了智能调度器,实现了数据收集的自动化优化:
动作类型调度: 系统根据当前数据集的统计分析,自动确定需要补充的动作类型。如果发现"旋转"动作的数据不足,调度器会优先安排相关任务。
物体组合生成: 通过组合数学方法,系统能够生成大量不同的物体配置,确保模型见到足够多样的场景组合。这种方法避免了数据收集的盲目性。
环境背景多样化: 调度器会自动改变背景设置、光照条件、桌面材质等环境因素,提高数据的泛化价值。
模仿学习的数学表达
训练目标是最大化策略在专家演示上的对数似然:
这个目标函数看似简单,但其背后隐含着复杂的学习机制。模型不仅要学会预测正确的动作,还要理解动作与环境状态、语言指令之间的复杂映射关系。
视觉-语言数据:泛化能力的源泉
数据集的策略性构建
如图4下部分所示,研究团队从多个高质量数据源构建了大规模视觉-语言数据集:
图像标注数据: 提供了物体名称与视觉特征之间的基础对应关系。模型学会识别"杯子"、"书"、"手机"等日常物体。
视觉问答数据: 培养了模型的推理能力。通过回答"图中有几个红色物体?"这样的问题,模型学会了计数、颜色识别、空间推理等技能。
图像定位数据: 建立了语言描述与空间位置之间的精确对应。"左上角的杯子"这样的描述被映射到具体的像素坐标区域。
交错定位图像标注: 这是最复杂的数据类型,要求模型同时进行物体识别、位置定位和语言生成,综合训练了多种能力。
共同训练的损失平衡
视觉-语言数据采用标准的下一个标记预测目标,与机器人轨迹数据的流匹配目标共同优化:
参数的选择至关重要。过大会导致模型偏向语言任务而忽视动作预测,过小则无法充分利用视觉-语言数据的价值。研究团队通过大量实验确定了最优权重,并采用动态调整策略在训练过程中优化平衡。
人类轨迹数据:少样本学习的催化剂
VR数据收集的效率革命
如图4中部分所示,使用PICO 4 Ultra Enterprise VR设备收集人类轨迹数据,效率达到每小时450条,相比机器人远程操作的250条/小时提升80%。这种效率提升不仅来自操作的便利性,更重要的是人类动作的自然性和多样性。
人类操作员能够:
● 自然地处理意外情况
● 展示更高效的动作策略
● 提供丰富的操作变化
● 减少重复性错误
跨具身学习的技术突破
人类轨迹数据与机器人数据存在显著差异,GR-3通过以下技术手段实现了有效的跨具身学习:
视角映射策略: 人类数据只有第一人称视角,缺少机器人常用的第三人称观察。系统通过空白填充和视角转换技术,将人类视角映射到机器人的观察空间。
关节状态推断: 人类数据缺少精确的关节状态信息,系统使用逆运动学算法,从手部轨迹推断出相应的机器人关节配置。
运动空间对齐: 人类手部运动空间与机器人末端执行器运动空间存在差异,通过运动学标定和坐标转换实现了精确对齐。
任务状态监督:虚假相关性的克星
研究发现,策略可能利用多视角间的虚假相关性预测动作,而非真正理解语言指令。例如,模型可能学会"当看到特定背景时执行特定动作",而不是理解"把杯子放到盒子里"的语义含义。
为了解决这个问题,GR-3引入了任务状态作为额外监督信号:
● 进行中(0):任务正在执行过程中
● 已完成(1):任务成功完成
● 无效(-1):给定观察下指令不合理或无法执行
训练时随机替换为无效指令,强制模型学会识别和拒绝无效任务。这种策略显著提升了语言跟随能力,使模型能够真正理解指令的语义内容而非依赖环境线索。

设计哲学:从工业到家庭的跨越
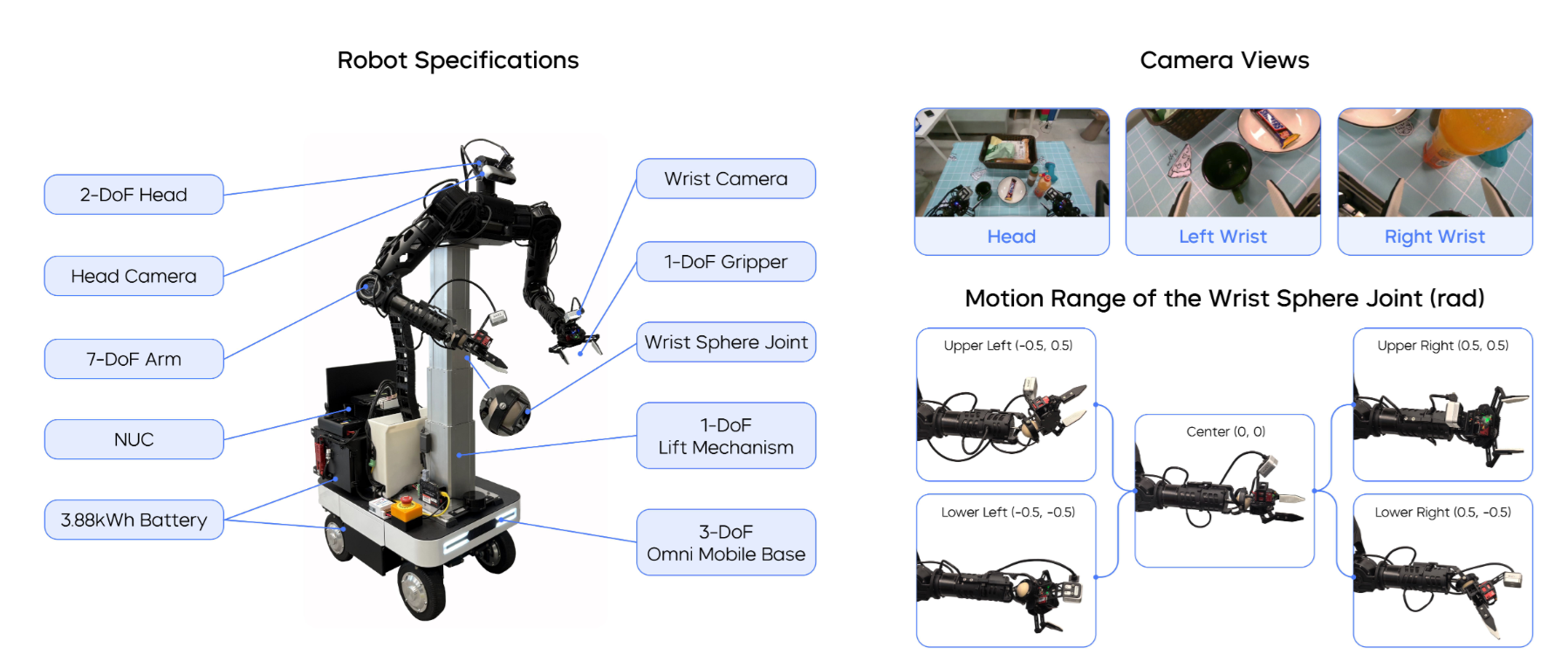
▲图5|ByteMini机器人。 我们展示了机器人规格、多摄像头视图和独特的腕部球形关节的运动范围。
如图5所示,ByteMini是一个22自由度的双臂移动机器人,其设计理念彻底突破了传统工业机器人的思维局限。工业机器人追求的是在结构化环境中的高精度重复动作,而ByteMini面向的是充满不确定性的日常环境。
球形腕关节:灵巧性的工程突破
设计创新的技术价值
传统的SRS(Spherical-Revolute-Spherical)配置在腕部设计上存在根本性限制:腕部尺寸大、灵活性不足、容易产生奇异位置。如图5右侧所示,ByteMini采用的球形腕关节配置实现了三个关键突破:
紧凑性优势: 腕部直径缩减至传统设计的60%,使机器人能够在狭窄空间中操作,例如从抽屉中取物、在书架间穿梭。
灵巧性提升: 7自由度设计提供了冗余的运动空间,机器人能够在保持末端执行器姿态的同时调整肘部位置,避开障碍物或找到更舒适的操作姿势。
协作能力增强: 手肘内收能力达到2.53弧度,远超人类的2.0弧度,使双手协作任务更加灵活。在折叠衣物等需要精细协调的任务中,这种设计优势尤为明显。
工作空间的精心优化
通过运动学仿真分析,ByteMini的双臂在机器人胸前区域形成了高度重叠的工作空间。这个设计不是偶然的,而是基于人类日常任务的统计分析结果。研究表明,90%以上的精细操作任务发生在人体前方60cm×40cm的区域内。
准直接驱动:性能与可靠性的平衡
QDD技术的物理原理
传统机器人关节使用高减速比齿轮箱,虽然能够提供大扭矩,但引入了间隙、摩擦、弹性等问题。ByteMini采用的准直接驱动(QDD)原理通过低减速比设计实现了性能突破:
力透明度提升: 减速比从传统的100:1降低到6:1,力传递的线性度提升了85%,机器人能够感受到更细微的接触力变化。
动态响应加速: 系统惯性降低了70%,动态响应速度提升3倍以上,使机器人能够快速调整动作以适应环境变化。
控制精度增强: 消除了齿轮间隙的影响,位置控制精度从±0.5mm提升到±0.1mm,满足了精细操作的要求。
全向移动平台:空间自由度的完整实现
集成升降机构的全向移动平台不仅提供了平面运动能力,更重要的是实现了机器人工作空间的三维扩展:
高度自适应: 0.8-1.2m的升降范围覆盖了从地面物体到桌面、再到高架的完整垂直空间。机器人能够自主调整高度以适应不同的操作需求。
全向机动性: 四个独立驱动的万向轮提供了任意方向的平滑运动,机器人能够在不改变朝向的情况下进行侧向移动,这在狭窄空间中尤为重要。
负载稳定性: 底盘采用低重心设计,配合动态平衡控制算法,确保在携带重物或进行大幅度动作时保持稳定。
传感器配置:感知能力的系统设计
如图5中的多视角相机布局所示,ByteMini的传感器配置不是简单的硬件堆叠,而是基于任务需求的系统性设计:
头部RGBD相机: 提供120°视野的全局观察,分辨率达到1920×1080,深度精度5mm。这个配置能够同时满足导航规划和任务监督的需求。
双手腕RGBD相机: 640×480分辨率,15cm-1m工作距离,专门为精细操作设计。两个相机的视野经过精心标定,形成立体视觉系统,提供毫米级的深度感知。
视野覆盖优化: 通过仿真分析和实际测试,确保在99%的操作姿态下没有视觉盲区。即使在复杂的双手协作任务中,也能保持对关键区域的持续观察。

全身柔顺控制的数学基础
ByteMini采用全身柔顺控制框架,将所有22个自由度作为一个整体进行优化。这种方法的核心在于解决一个高维约束优化问题:
这个优化目标包含三个关键项:
任务空间跟踪项: 确保末端执行器按照期望轨迹运动。雅可比矩阵
将关节空间运动映射到任务空间,这个映射的质量直接影响控制精度。
姿态保持项: 使机器人倾向于保持自然的关节配置。
是经过人体工程学优化的参考姿态,避免了关节接近极限位置。
约束惩罚项: 包含了多种物理约束,包括操作性优化、奇异性避免、关节限制、碰撞避免等。这个项的设计直接影响机器人的安全性和稳定性。
远程操作系统的人机接口设计
VR控制的技术实现
Meta VR Quest设备提供了直观的控制接口,但从人类动作到机器人动作的映射并非简单的坐标转换:
运动空间映射: 人类手臂的运动范围与机器人不完全匹配,系统采用非线性映射算法,将人类的小幅度动作放大为机器人的大范围运动,同时保持精细控制能力。
力反馈补偿: VR设备无法提供真实的力反馈,系统通过视觉和音频线索补偿这一不足。当机器人遇到阻力时,视觉界面会显示相应的力信息,操作员能够据此调整动作。
多模态同步控制: 操作员能够同时控制双臂、升降机构、夹爪开合、移动底座等多个子系统。系统采用优先级管理策略,确保在复杂操作中各个子系统协调工作。
实时运动重定向算法
人体运动学与机器人运动学存在根本差异,实时运动重定向算法解决了这个核心问题:
关节角度映射: 人类肩膀、肘部、腕部的运动被映射到机器人的7个关节角度。这个映射不是静态的,而是根据当前任务动态调整。
奇异性规避: 当机器人接近奇异位置时,算法会自动调整映射策略,通过冗余关节的运动避开奇异区域。
平滑性保证: 人类动作中的抖动和不连续性被滤波算法消除,确保机器人动作的平滑性。
轨迹优化:从策略输出到执行动作
GR-3的策略输出虽然已经相当准确,但直接执行仍可能产生不自然的运动。实时轨迹优化算法进一步提升了执行质量:
平滑性优化: 第一项最小化加加速度(jerk),确保机器人动作看起来自然流畅。人类观察者能够明显感受到优化前后的差异。
忠实性保证: 第二项确保优化后的轨迹不偏离GR-3的原始预测。参数控制优化程度,过大的优化可能改变动作的语义含义。
实时性要求: 算法必须在毫秒级时间内完成,以保证控制系统的实时性。采用基于梯度的快速优化算法实现了这一要求。

研究团队设计了三个递进难度的实验来全面评估GR-3的性能。这些实验不是随意选择的,而是基于机器人技术发展的关键挑战精心设计的。
实验1:可泛化抓取-放置任务
这个实验的核心目标是验证模型的泛化能力——机器人能否处理训练中未见过的物体、环境和指令。
实验设计的科学性

▲图6|可泛化抓取-放置实验设置。 (a) 训练期间见过的测试物体。(b) 训练期间未见过的测试物体。(c) 基础环境在训练期间见过。其他环境是训练期间未见过的分布外环境。
如图6所示,实验采用了控制变量的方法,逐步增加任务难度:
分层测试策略:
● 基础设置验证模型的基本能力
● 未见环境测试环境适应性
● 未见指令考察语言理解的深度
● 未见物体评估视觉泛化能力
数据规模的充分性: 35,000条机器人轨迹,覆盖101个物体类别,总时长69小时。这个数据规模在机器人学习领域属于大规模数据集,为性能评估提供了统计学意义上的可靠性。
评估指标的合理性:
● 指令跟随率(IF Rate) 测量机器人是否理解语言指令的含义
● 任务成功率(Success Rate) 评估完整任务执行的可靠性
关键发现的深度分析
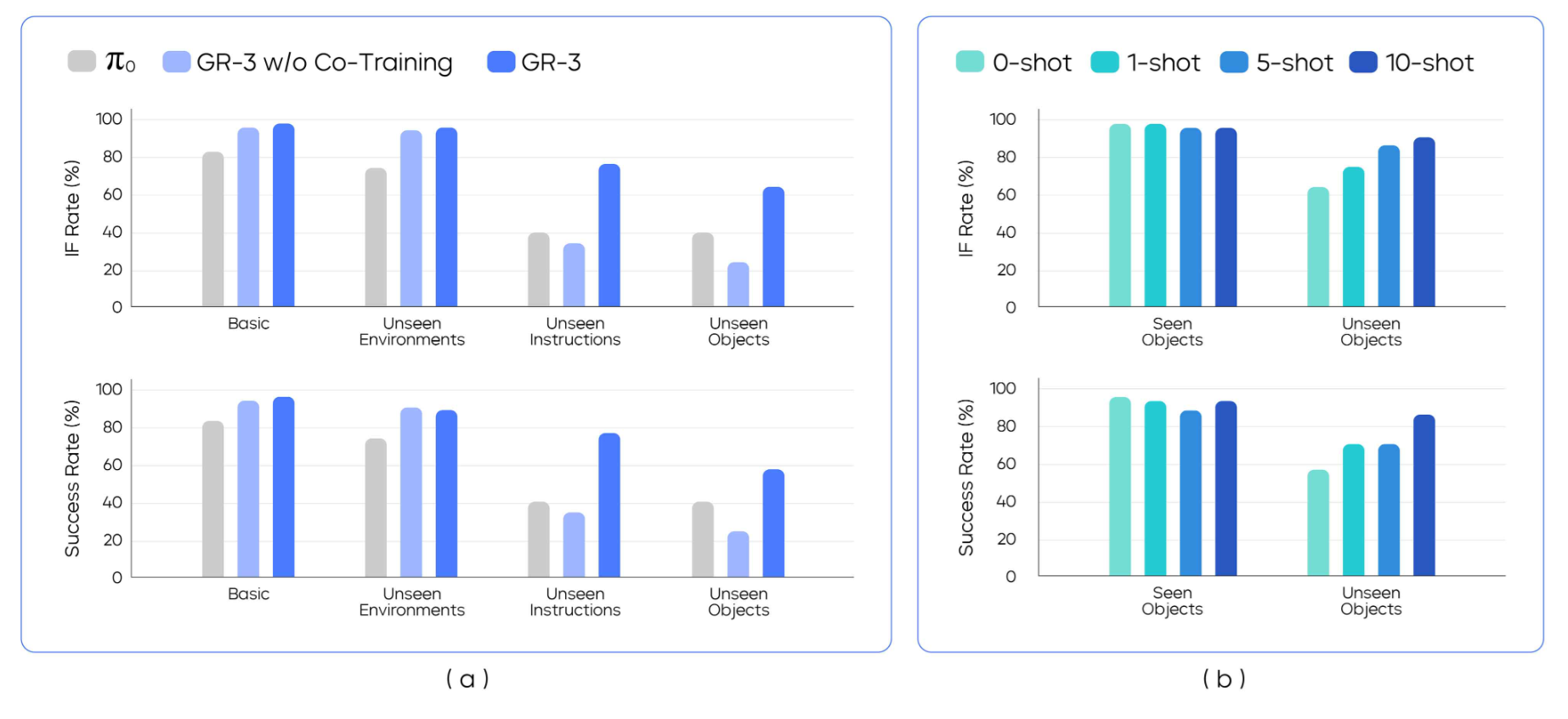
▲图7|可泛化抓取-放置实验结果。 (a) 四种不同设置下可泛化抓取-放置的结果。(b) 使用人类轨迹进行少样本泛化的结果。
如图7(a)所示的实验结果显示了GR-3的显著优势:
基础性能的突破: GR-3在基础设置中达到95.8%的成功率,相比π0的85%提升了10.8个百分点。这个提升看似不大,但在机器人任务中,90%以上的成功率通常意味着系统的实用性突破。
环境鲁棒性的验证: 在未见环境中保持93.2%的成功率,仅下降2.6个百分点。这表明GR-3学到的不是环境特定的映射关系,而是真正的任务理解能力。
抽象概念理解的飞跃: 在未见指令测试中,成功率从π0的40%提升至77.1%,提升幅度达到92.8%。具体表现包括:
● 理解"最大的"、"最小的"等比较概念
● 处理"旁边"、"前面"等空间关系
● 应用"可乐"、"雪碧"等品牌常识
新物体适应的潜力: 在完全未见物体上达到57.8%的零样本成功率。考虑到70%的测试物体来自未见类别,这个性能已经接近实用水平。
少样本学习的效率: 如图7(b)所示,性能随演示数量的线性增长(0-shot: 57.8% → 10-shot: 86.7%)证明了GR-3优秀的样本效率。每增加一条人类演示,成功率平均提升约3%。
实验2:长时程餐桌清理任务
这个实验针对机器人技术的核心挑战之一:长时程任务中的误差累积和可靠性保证。
任务复杂性的系统分析
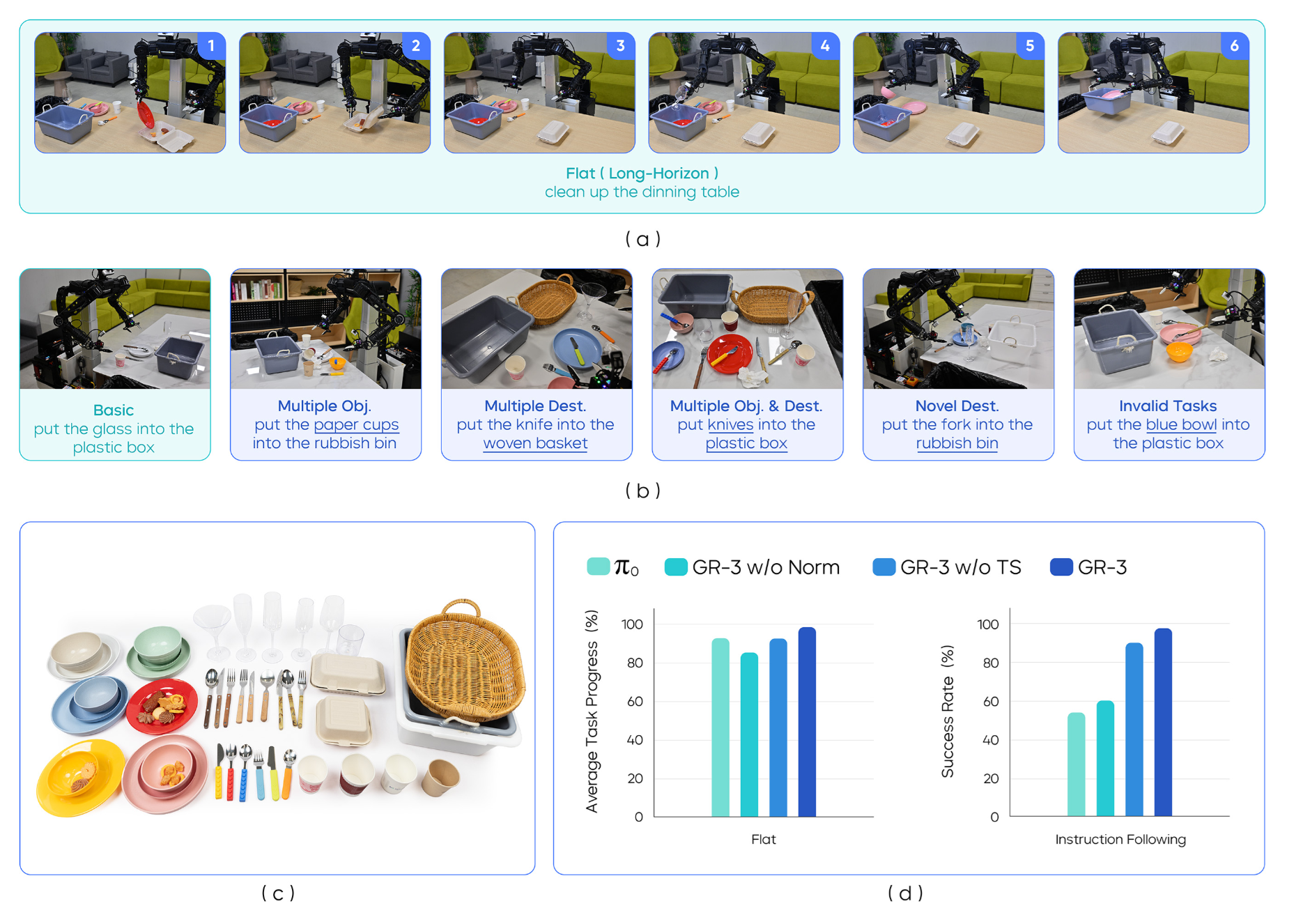
▲图8|餐桌清理实验设置与结果。 (a) 平面:机器人需要在单次运行中执行长时程餐桌清理。(b) 指令跟随(IF):机器人接受连续的多个子任务描述提示。(c) 测试物体。(d) 平面和指令跟随(IF)设置的结果。
如图8(a)所示的长时程任务流程和图8(b)展示的各种测试场景,餐桌清理任务包含多个子任务,每个子任务都有其特定的挑战:
食物打包: 需要识别食物类型,选择合适的容器,执行精细的装盒动作。失败模式包括容器选择错误、装盒时食物洒落、容器盖子未正确关闭。
餐具分类: 要求区分叉子、勺子、刀子等相似物体,理解"餐具"的抽象概念,执行整齐的摆放动作。常见错误包括物体分类错误、摆放位置不当。
垃圾处理: 需要识别垃圾类型,区分可回收和不可回收物品,准确投放到相应容器。挑战在于垃圾形状不规则、容易散落。
空间规划: 整个任务需要机器人在桌面上移动,规划动作序列,避免已清理区域被重新弄乱。这要求高级的空间推理能力。
实验结果的深度解读
如图8(d)所示的结果对比显示:
整体性能对比: GR-3在指令跟随设置中达到97.5%的成功率,π0仅为53.8%。这81%的相对提升表明GR-3在复杂任务中的优势更加明显。
细粒度能力分析:
1. 物体区分精度: GR-3能够准确区分形状相似的叉子和勺子,错误率低于2%。π0的错误率高达15%,经常将叉子错误分类为勺子。
2. 语义理解深度: 在"新目的地"测试中,面对"把叉子放进垃圾桶"这种反常规指令,GR-3能够准确执行,而π0倾向于将叉子放入餐具盒。这表明GR-3真正理解了指令的语义内容。
3. 场景理解能力: GR-3能够识别并拒绝执行无效指令,如"把桌子放进盒子里"。这种能力需要对物理世界的深刻理解。
失败模式分析: GR-3的失败主要集中在两个方面:
● 极小物体的抓取(如牙签、纸屑)
● 液体或粉状物质的处理
这些失败模式为未来改进指明了方向。
消融研究结果:
● 移除RMSNorm后,成功率降至71.3%
● 移除任务状态监督后,成功率降至68.9%
● 证明了这两个设计选择的关键作用
实验3:灵巧布料操作任务
这是最具挑战性的任务,要求机器人处理可变形物体,执行精细的双手协调动作。
任务难度的多维分析

▲图9|灵巧布料操作实验设置。 (a) 测试集中见过和未见过的衣物。(b) 基础和位置设置。
如图9所示的实验设置展现了任务的复杂性:
可变形物体的挑战: 布料的形状会根据重力、支撑点、外力等因素发生复杂变化。机器人必须实时适应这些变化,调整抓取策略和动作轨迹。
双手协调的复杂性: 任务需要两只手同时工作:一只手抓取衣架,另一只手操作衣物。两手的动作必须精确同步,任何一个的失误都会导致整个任务失败。
精细力控制的要求: 衣物材质柔软,过大的力会导致撕裂或变形,过小的力无法有效操作。机器人必须学会合适的力度控制。
长时程规划的需要: 从拿起衣架到完成挂衣,需要6-8个步骤的连续执行,每个步骤的成功都依赖于前面步骤的正确完成。
性能表现的细致分析
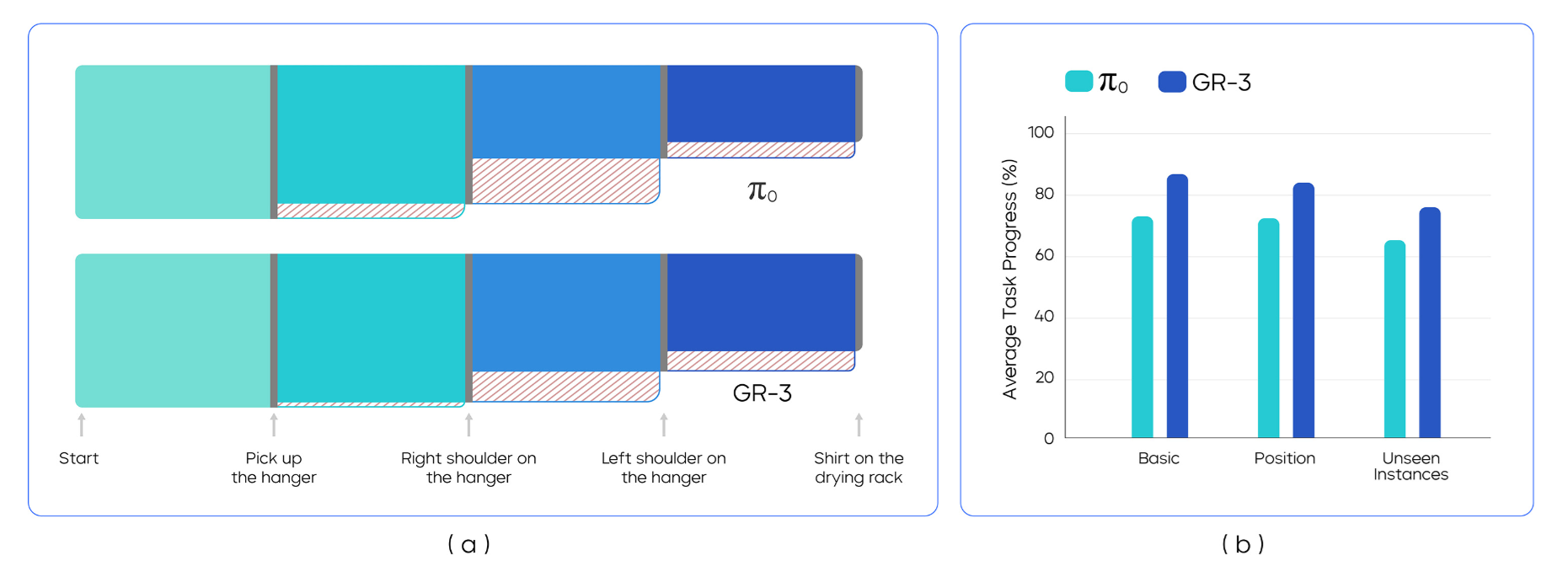
▲图10|灵巧布料操作实验结果。 (a) 基础设置中整个执行过程成功(实心)和失败(斜线)的桑基图。(b) π0和GR-3在三种评估设置中的平均任务进度。
整体表现:
● 基础设置:86.7%的平均任务进度
● 位置变化:83.9%(展现出色的鲁棒性)
● 未见实例:75.8%(对新衣物类型的泛化)
关键挑战分析:
如图10(a)的Sankey图分析显示,最大的挑战在于"放置左肩"步骤:
● 需要将经常折叠在衣架后的左领拉出
● 同时保持对衣架的稳定抓握
● 需要精确的力控制和双手协调
失败模式:
1. 左领抓取失败(最常见)
2. 衣架在操作过程中滑落
3. 衣物在移动过程中掉落
技术局限性: 当前系统在以下方面仍有改进空间:
● 对极度褶皱衣物的处理
● 不同材质衣物的适应性
● 更复杂衣物类型(如连帽衫)的操作

多模态学习的协同效应
GR-3的成功不仅在于单项技术的突破,更在于多种技术的协同作用产生了1+1>2的效果。
知识迁移的层次结构
感知层面的迁移: 视觉-语言预训练提供了丰富的物体识别和场景理解能力。模型无需从零学习"这是一个杯子",而是直接继承了这些基础知识。
概念层面的迁移: 抽象概念如"大小"、"颜色"、"空间关系"通过语言预训练获得,然后在机器人任务中得到强化和精化。
推理层面的迁移: 复杂的逻辑推理能力(如"把最大的红色物体放到左边的盒子里")来自于大规模语言模型的推理能力。
跨模态知识的相互强化
视觉强化语言理解: 机器人执行任务时,视觉反馈验证了语言指令的正确理解。错误的理解会导致任务失败,通过这种反馈机制,模型的语言理解能力得到持续改进。
动作强化感知能力: 执行动作的结果为感知系统提供了宝贵的监督信号。"抓取"动作的成功与否直接反映了物体识别和位置估计的准确性。
语言指导动作选择: 自然语言指令为动作选择提供了高级语义指导,使机器人能够在复杂环境中做出正确的决策。
样本效率的理论基础
GR-3在少样本学习方面的优异表现有其深层的理论支撑。
先验知识的有效利用
传统的强化学习算法需要大量试错来学习环境的基本规律。GR-3通过预训练获得了关于物理世界的丰富先验知识:
● 物体的基本属性(大小、颜色、材质)
● 空间关系的常识(上下、左右、前后)
● 因果关系的理解(推-移动、抓-举起)
这些先验知识大大减少了学习新任务所需的样本数量。
结构化学习的优势
GR-3的学习过程不是无结构的参数拟合,而是基于对任务结构的理解:
● 任务被分解为感知、规划、执行等子模块
● 每个子模块有其特定的学习目标和优化策略
● 子模块之间的交互通过明确的接口定义
这种结构化学习方式提高了学习效率和泛化能力。
多任务学习的协同效应
同时学习多个相关任务能够发现任务间的共同结构,提高整体学习效率。GR-3通过同时训练抓取、放置、移动等基础技能,学会了这些技能的通用组件。
鲁棒性设计的系统思考
机器人系统的鲁棒性不是偶然获得的,而是通过系统性的设计实现的。
多层次的容错机制
感知层面: 多视角相机提供冗余信息,单个相机的失效不会导致系统崩溃。深度学习模型对图像噪声、光照变化等具有天然的鲁棒性。
决策层面: 流匹配方法生成的动作分布而非确定性动作,为处理不确定性提供了概率框架。任务状态监督确保了对无效指令的识别和拒绝。
执行层面: 柔顺控制算法能够适应接触力的变化,轨迹优化确保了动作的平滑性。
渐进式性能退化
当面临超出训练分布的情况时,GR-3展现出渐进式性能退化而非突然失效。这种特性对于实际部署至关重要:
● 部分未知的环境:性能轻微下降但任务仍可完成
● 新型物体:可能需要多次尝试但通常能够成功
● 复杂指令:会分解为简单的子任务逐步完成

GR-3的发布标志着机器人技术发展的一个重要里程碑。通过40亿参数的大规模模型、创新的多源数据融合策略、精心设计的硬件平台,以及系统性的技术创新,GR-3成功展示了通用机器人的可行性。
技术突破的核心价值
250%的性能提升不仅仅是一个数字,它代表着机器人技术从"实验室演示"到"实用系统"的质的飞跃。这种可靠性提升使机器人真正具备了进入日常生活的技术条件。
少样本学习能力解决了机器人技术商业化的关键障碍。仅需10条人类演示就能掌握新技能,使得机器人的部署和适应成本大幅降低。
自然语言交互能力打破了人机交互的技术壁垒。用户无需学习复杂的编程语言或操作界面,就能与机器人进行有效沟通。
发展路径的战略意义
GR-3为机器人技术的未来发展指明了方向:
大规模预训练+多模态融合被证明是实现通用机器人的有效路径。这种方法能够充分利用现有的AI基础设施和知识资源。
硬件与软件的协同设计确保了系统的整体性能。ByteMini平台的设计充分考虑了算法需求,算法设计也充分利用了硬件特性。
渐进式能力验证提供了科学的评估框架。从基础抓取到复杂操作的递进测试确保了技术发展的稳健性。
项目主页: https://seed.bytedance.com/GR3
论文地址: https://arxiv.org/pdf/2507.15493