C++编译过程与GDB调试段错误和死锁问题

在 C++ 开发过程中,了解编译流程和掌握调试技巧是提升开发效率的关键。本文将详细解析 C++ 的编译流程,介绍 g++ 编译命令的使用,并深入讲解 GDB 调试工具的常用技巧,包括段错误和死锁的调试方法。
C++ 编译流程
C++ 代码从源代码到可执行文件需要经历四个主要阶段:预处理、编译、汇编和链接。每个阶段都有其特定的功能和可能出现的错误。
我们以一个最简单的示例代码做演示
预处理阶段
预处理是编译的第一步,主要处理以#开头的预处理指令。使用g++ -E main.cpp > main.e命令可以生成预处理后的文件 main.e。
预处理阶段的主要工作包括:
- 宏定义替换:将所有#define定义的宏进行文本替换,例如#define MAX 100会将代码中所有 MAX 替换为 100
- 处理头文件包含:将#include指令指定的头文件内容递归插入到当前文件中
- 处理条件编译:如#if、#ifdef、#elif、#else、#endif等,根据条件保留或删除部分代码
- 删除注释:将代码中的注释替换为空格
- 添加行号和文件名标识:便于后续编译阶段生成错误信息
main.cpp:
#define MAX 100#if 1int main()
{int a = MAX;return 0;
}#endifmain.e:
# 0 "main.cpp"
# 0 "<built-in>"
# 0 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 0 "<command-line>" 2
# 1 "main.cpp"int main()
{int a = 100;return 0;
}
预处理阶段可能出现的错误:
- 宏定义语法错误,如缺少括号、引号不匹配
- 头文件找不到(fatal error: xxx.h: No such file or directory)
- 嵌套包含导致的文件路径错误(#pragma once 或 #ifndef HEADFILE_H解决)
编译阶段
编译阶段将预处理后的代码(.i 或.e 文件)转换为汇编代码(.s 文件),使用g++ -S main.cpp命令可生成汇编文件 main.s。
编译过程主要包括:
- 词法分析:将源代码分解为单词(token),如关键字、标识符、常量等
- 语法分析:根据语法规则将单词组成语法树,检查语法错误
- 语义分析:检查语法树的语义是否正确,如类型匹配、变量未定义等
- 中间代码生成:将语法树转换为中间代码(如三地址码)
- 代码优化:对中间代码进行优化,提高执行效率
- 目标代码生成:将优化后的中间代码转换为汇编指令
main.s:
.arch armv8-a.file "main.cpp".text.align 2.global main.type main, %function
main:
.LFB0:.cfi_startprocsub sp, sp, #16.cfi_def_cfa_offset 16mov w0, 100str w0, [sp, 12]mov w0, 0add sp, sp, 16.cfi_def_cfa_offset 0ret.cfi_endproc
.LFE0:.size main, .-main.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0".section .note.GNU-stack,"",@progbits
编译阶段常见错误:
- 语法错误:如缺少分号、括号不匹配
- 类型错误:如不同类型变量赋值
- 未声明的变量或函数使用
汇编阶段
汇编阶段将汇编代码(.s 文件)转换为机器码(二进制指令),生成目标文件(.o 或.obj 文件)。使用g++ -c main.cpp命令可生成目标文件 main.o。
汇编过程相对简单,主要是将每条汇编指令对应到特定 CPU 的机器码,不进行复杂的语法检查,只检查汇编指令的有效性。
链接阶段
链接阶段将多个目标文件(.o)和所需的库文件组合在一起,生成可执行文件。
链接主要完成:
- 符号解析:将目标文件中引用的外部符号(如函数、全局变量)与定义这些符号的目标文件关联起来
- 重定位:调整目标文件中符号的地址,使其在最终的可执行文件中具有正确的内存地址
链接阶段常见错误:
- 未定义引用(undefined reference):引用了未实现的函数或变量
- 多重定义(multiple definition):同一个符号在多个目标文件中被定义
- 库文件找不到:指定的库文件不存在或路径错误
GDB 调试
GDB(GNU Debugger)是一款功能强大的命令行调试工具,支持断点设置、变量查看、程序单步执行等功能。使用g++ -g main.cpp -o main命令编译程序时,-g选项会在可执行文件中加入调试信息,使 GDB 能够进行调试。
常用 GDB 命令
1. bt:查看当前线程的调用栈(backtrace),显示函数调用关系和参数
2. list <行号>|< 函数名 >:查看指定行号或函数的源代码
(gdb) list 10 # 查看第10行附近的代码(gdb) list main # 查看main函数的代码3. break:设置断点
(gdb) break 20 # 在第20行设置断点(gdb) break func_name # 在函数func_name处设置断点(gdb) break file.cpp:30 # 在file.cpp的第30行设置断点4. info break:查看所有断点信息,包括断点编号、位置、状态等
5. run:开始执行程序,若有断点则在断点处暂停
6. print:打印变量或表达式的值
(gdb) print x # 打印变量x的值(gdb) print a + b # 打印表达式a + b的值(gdb) print array[0] # 打印数组第一个元素7. next:执行下一行代码,不进入函数调用(单步执行)
8. step:执行下一行代码,若有函数调用则进入函数内部(单步跟踪)
9. continue:继续执行程序,直到遇到下一个断点或程序结束
GDB调试段错误(Core Dump)
段错误(Segmentation Fault)通常是由于程序访问了非法内存地址导致的。通过 Core Dump 文件可以记录程序崩溃时的内存状态,便于事后调试。
段错误实例代码(segmenterr.cpp):
#include <iostream>int main()
{int* a = 0;*a = 10;return 0;
}//g++ -g -o segmenterr segmenterr.cpp(1)开启 Core Dump:
默认情况下,系统可能限制 Core 文件的生成,使用ulimit -a命令可以查看系统资源限制。其中core file size表示 Core 文件的大小限制。
ulimit -c unlimited # 设置Core文件大小不受限制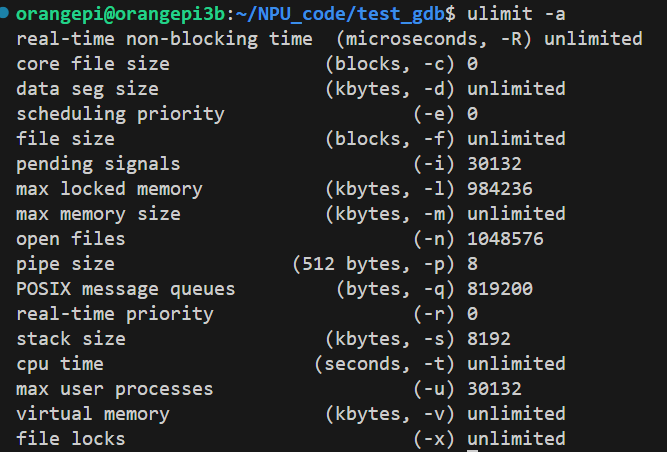
(2)生成 Core 文件:
当程序发生段错误时,会自动生成名为core或core.PID的文件,ubuntu系统下,默认生成在执行文件同目录下,可以通过修改/etc/sysctl.conf配置core文件生成路径:
修改/etc/sysctl.conf,再最后插入kernel.core_pattern=<路径>,例如:
kernel.core_pattern=/home/orangepi/core_dump/core-%e-%p-%t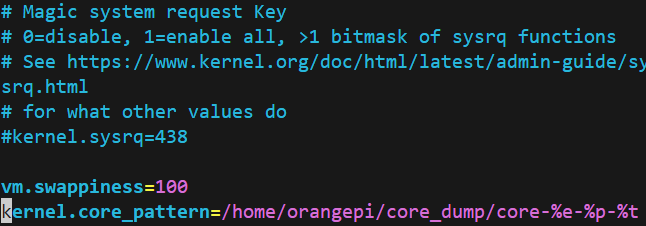
core_dump_core-%e-%p-%t时期望生成core文件的文件名模板,其中:
%e: 执行文件名称
%p: <pid>
%t: dump的时间
创建对应文件夹(我这里是core_dump文件夹)
mkdir /home/orangepi/core_dump执行:
sudo sysctl -p /etc/sysctl.conf使用cat查看配置路径是否生效:
cat /proc/sys/kernel/core_pattern
(3)使用 GDB 调试 Core 文件:
先执行程序,时段错误发生并产生core

执行
gdb <可执行文件> <core文件路径>
我的是:
gdb ./segmenterr /home/orangepi/core_dump/core-segmenterr-9214-1754215410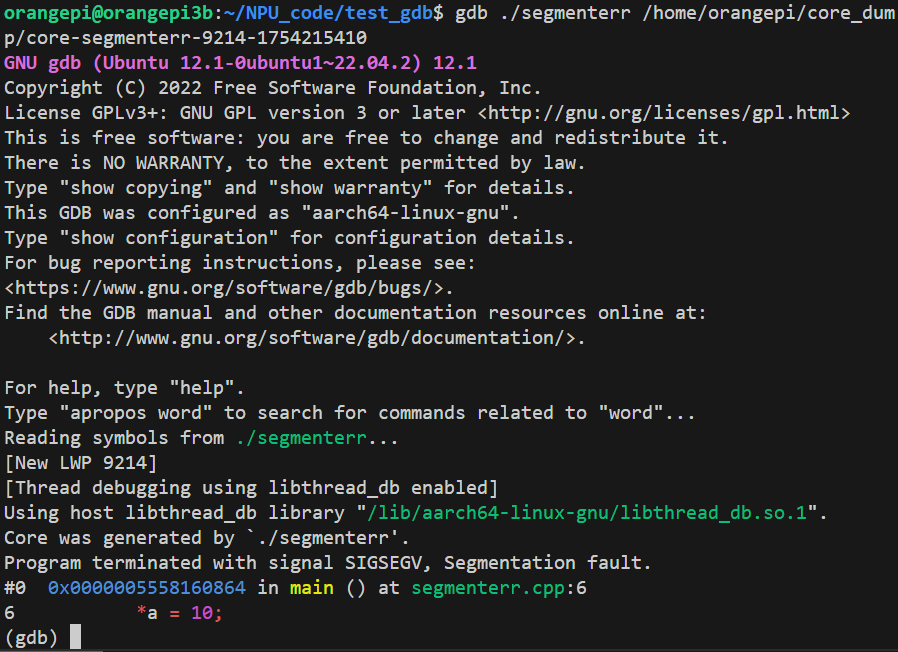
(gdb) bt # 查看崩溃时的调用栈,定位错误位置
死锁调试
死锁是多线程程序中常见的问题,当两个或多个线程互相等待对方释放资源时就会发生死锁。
死锁示例代码
#include <pthread.h>
#include <iostream>using namespace std;pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t mutex2 = PTHREAD_MUTEX_INITIALIZER;void *thread1(void *arg) {pthread_mutex_lock(&mutex1);cout << "Thread 1 locked mutex1" << endl;// 模拟一些工作sleep(1);pthread_mutex_lock(&mutex2); // 等待mutex2cout << "Thread 1 locked mutex2" << endl;pthread_mutex_unlock(&mutex2);pthread_mutex_unlock(&mutex1);return NULL;
}void *thread2(void *arg) {pthread_mutex_lock(&mutex2);cout << "Thread 2 locked mutex2" << endl;// 模拟一些工作sleep(1);pthread_mutex_lock(&mutex1); // 等待mutex1cout << "Thread 2 locked mutex1" << endl;pthread_mutex_unlock(&mutex1);pthread_mutex_unlock(&mutex2);return NULL;
}int main() {pthread_t t1, t2;pthread_create(&t1, NULL, thread1, NULL);pthread_create(&t2, NULL, thread2, NULL);pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_mutex_destroy(&mutex1);pthread_mutex_destroy(&mutex2);return 0;
}GDB 调试死锁方法
1.编译带调试信息的程序:
g++ -g -o lockerr lockerr.cpp -lpthread2.运行程序并使用 GDB 附加进程:

gdb attach <pid> # 附加到进程
gdb attach 99063. 查看线程信息:
(gdb) info threads # 显示所有线程(gdb) thread 2 # 切换到线程2(gdb) bt # 查看线程2的调用栈(gdb) thread 3 # 切换到线程3(gdb) bt # 查看线程3的调用栈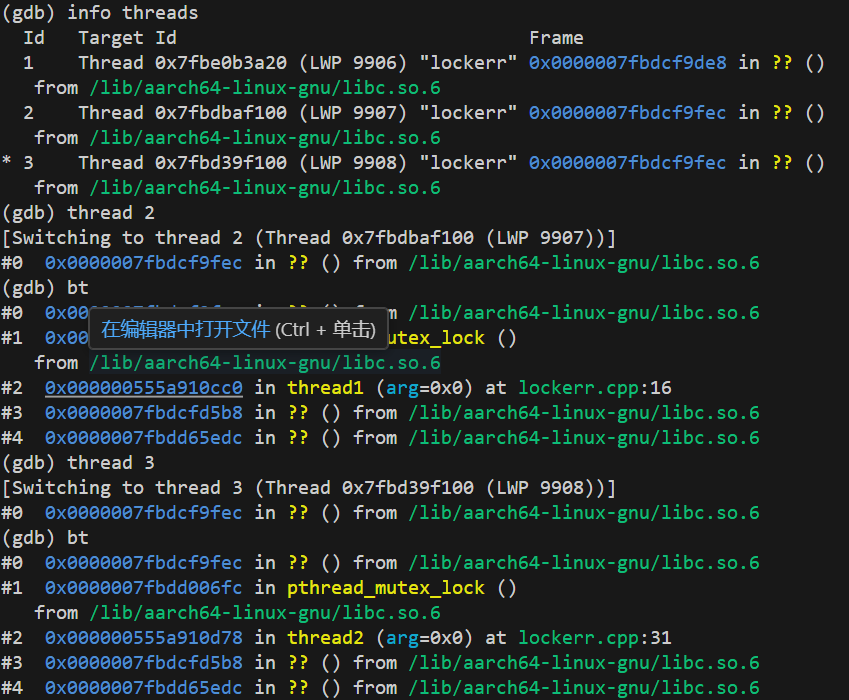
在 GDB 中可以使用info threads查看所有线程的状态,结合bt命令查看线程的调用栈,分析线程正在等待的锁资源,从而定位死锁原因。
(gdb) thread apply all bt # 查看所有线程的调用栈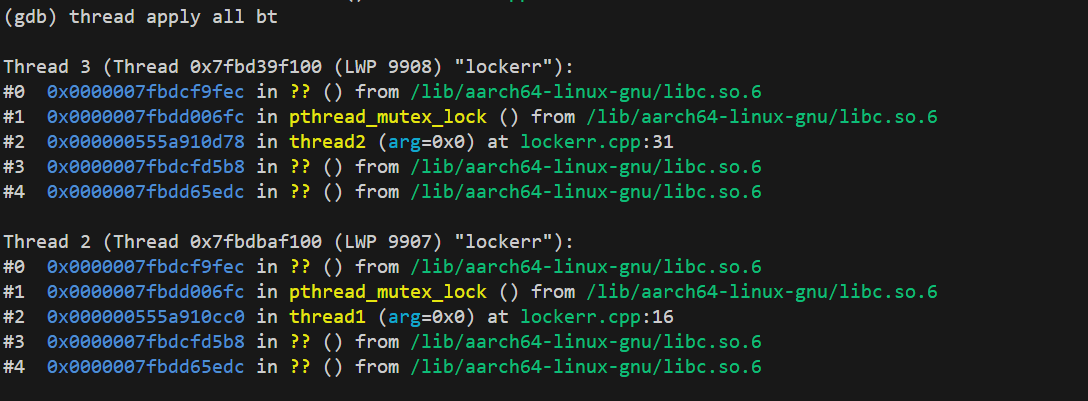
#1 pthread_mutex_lock
#2 thread2 (arg=0x0) at lockerr.cpp:31
说明 线程 3(对应thread2函数)在lockerr.cpp的第 31 行调用pthread_mutex_lock,尝试获取某个互斥锁,但陷入阻塞。
#1 pthread_mutex_lock
#2 thread1 (arg=0x0) at lockerr.cpp:16
说明 线程 2(对应thread1函数)在lockerr.cpp的第 16 行调用pthread_mutex_lock,尝试获取某个互斥锁,也陷入阻塞。
通过以上方法,可以清晰地看到两个线程阻塞位置,从而确认死锁的发生位置和原因。