深度剖析PyTorch torch.compile的性能曲线与优化临界点
数量级提速的真相:深度剖析PyTorch torch.compile的性能曲线与优化临界点
PyTorch 2.x 引入的torch.compile被誉为自Autograd以来最重要的功能之一,它承诺通过一行装饰器@torch.compile,为模型带来“开箱即用”的显著性能提升。然而,任何优化技术都有其牺牲的东西,其背后必有深刻的原理和清晰的适用边界。
这种提速的本质是什么?它在何种场景下会带来数量级的性能飞跃,又在何种情况下收效甚微甚至产生负优化?为了揭开这层神秘的面纱,我们进行了一项系统性的基准测试,旨在绘制出torch.compile在不同复杂度下的性能曲线,并找出其优化效果的“临界点”。
核心概念:从多次“启动”到一次“启动”
在理解实验之前,必须先掌握两个核心概念:Eager Mode 和 核函数融合 (Kernel Fusion)。
-
Eager Mode (即时执行模式):这是PyTorch传统的运行方式。当我们执行一行
y = torch.sin(x)时,PyTorch会立即向GPU发送一个执行sin操作的指令(即启动一个CUDA核函数)。如果模型包含20个这样的操作,GPU就需要被“启动”20次。这种“启动”——即CPU到GPU的通信和任务调度——本身是有固定开销的。对于计算量很小的操作,这些开销累加起来会变得非常可观。 -
torch.compile与核函数融合:torch.compile的核心武器是核函数融合。它首先通过一个名为TorchDynamo的前端来捕获您的Python代码,将其转换成一个计算图。然后,后端(如Inductor)会将这个图上连续的、可融合的操作 “合并”成一个单一的、更庞大的GPU核函数 。这意味着,原本需要20次“启动”才能完成的任务,现在只需一次“启动”即可。这极大地减少了CPU与GPU之间的交互开销,是性能提升的主要来源。
然而,编译本身并非零成本,它引入了代码捕获、图优化和守卫检查(Guard Overhead)等框架开销。当节省下来的“启动”费用不足以支付这笔“规划”费用时,优化效果便会大打折扣。我们的实验正是为了量化这场成本与收益的博弈。
实验设计:系统性探究性能边界
为了精准地衡量torch.compile的价值,本次测试将对比三种核心执行模式:
- Eager Mode: PyTorch的默认执行模式,作为所有优化的性能基准。
- 静态编译 (
dynamic=False, 固定形状): 理论上的性能天花板。它将多个操作融合成一个为特定输入形状深度优化的核函数,但要求输入形状永不改变。 - 动态编译 (
dynamic=True, 可变形状): 平衡性能与灵活性的推荐实践。它同样进行核函数融合,但生成的代码能处理可变的输入形状,是现实世界中更常用的模式。
我们将一个由一系列极轻量级操作(如add, sin, relu)组成的模型,系统性地将其操作语句数量从1增加到30,并在GPU上精确测量每次调用的平均延迟。
实验结果与深度分析
最终性能数据总览
| 语句数量 | Eager模式 (us) | 静态编译 (us) | 动态编译 (us) | 静态加速比 | 动态加速比 |
|---|---|---|---|---|---|
| 1 | 13.32 | 37.67 | 59.88 | 0.35x | 0.22x |
| 5 | 40.45 | 40.32 | 62.25 | 1.00x | 0.65x |
| 10 | 86.44 | 36.71 | 64.36 | 2.35x | 1.34x |
| 15 | 109.90 | 42.39 | 59.14 | 2.59x | 1.86x |
| 20 | 137.26 | 36.33 | 60.42 | 3.78x | 2.27x |
| 25 | 167.79 | 36.98 | 67.26 | 4.54x | 2.49x |
| 30 | 225.63 | 42.38 | 66.77 | 5.32x | 3.38x |
性能曲线图
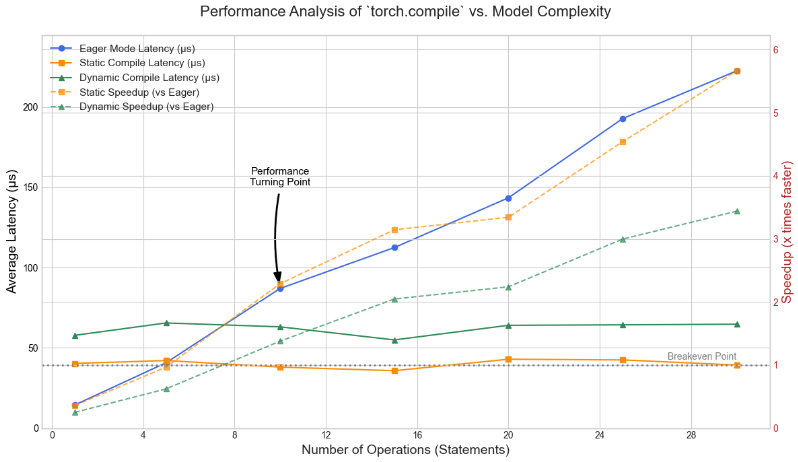
(图注:一张根据上述数据绘制的性能曲线图。蓝色的Eager模式线呈陡峭的线性增长。橙色的静态编译线和绿色的动态编译线在初始波动后,几乎保持为水平直线,远低于Eager模式。)
洞察一:Eager模式的线性开销——“死亡千纸割”
Eager模式的性能曲线(蓝色)完美地印证了我们的理论。其延迟几乎与语句数量成完美的线性关系。每增加一次操作,就增加一次固定的核函数启动开销。当操作链很长时,这种“死亡千纸割”式的累积开销变得无法忽视,构成了性能的主要瓶颈。
洞察二:编译优化的“临界点”——投资与回报
torch.compile的性能曲线则讲述了一个关于“投资回报”的故事。
-
投资亏损区 (1-5条语句): 在模型极其简单时,编译的固定框架开销(投资)超过了它节省下来的(少量)核函数启动开销(回报)。因此,编译模式甚至比Eager模式更慢,加速比小于1。这警示我们,不要对过于琐碎的函数使用
torch.compile。 -
性能转折点 (约10条语句): 在这里,收益开始超越成本。静态编译达到了2.35倍的加速,动态编译也实现了1.34倍的加速。这标志着核函数融合的价值正式显现,是应用
torch.compile的性能临界点。
洞察三:饱和的性能收益——融合的力量
当语句数量从10条增加到30条时,最引人注目的现象出现了:Eager模式的耗时从86us飙升至225us,而编译模式的延迟却始终保持在一个极低且稳定的平台期(静态约40us,动态约65us)。
这充分证明了核函数融合的巨大威力。无论模型内部有多少个可融合的操作,torch.compile都将其视为一个整体进行优化,其执行时间几乎与操作数量无关,彻底消除了核函数启动次数带来的性能瓶颈。
洞察四:静态 vs. 动态——极限与实践的权衡
-
静态编译 (
dynamic=False) 展示了理论上的性能极限。在30条语句时,它实现了惊人的5.32倍加速。但它的适用场景非常狭窄,仅限于输入形状永不改变的生产环境。 -
动态编译 (
dynamic=True) 在同样的场景下,实现了3.38倍的加速。它用约25微秒的额外开销,换取了处理可变输入形状的宝贵灵活性。这部分开销源于处理动态形状所需的守卫检查和更通用的代码生成。
附录:完整复现代码
import torch
import torch._dynamo
import numpy as np
import pandas as pd
import warnings# --- 配置 ---
NUM_CALLS_PER_BATCH = 100
TOTAL_SHAPES = 300
STMT_COUNTS = [1, 5, 10, 15, 20, 25, 30]# --- 模型生成器 ---
def create_model(num_statements):"""根据给定的语句数量动态创建一个模型函数。"""# 构建模型函数体的Python代码字符串model_body_lines = []# 20个独特的操作,我们会循环使用它们ops_pool = ["x = x + 0.1", "x = torch.sin(x)", "x = x * 1.1", "x = torch.cos(x)","x = x + 0.2", "x = torch.relu(x)", "x = x - 0.1", "x = torch.exp(x * 0.5)","x = x + 0.3", "x = torch.sigmoid(x)", "x = x * 1.2", "x = torch.sin(x)","x = x + 0.4", "x = torch.cos(x)", "x = x - 0.2", "x = torch.relu(x)","x = x + 0.5", "x = torch.exp(x * 0.4)", "x = x * 1.3", "x = torch.sigmoid(x)"]for i in range(num_statements):model_body_lines.append(f" {ops_pool[i % len(ops_pool)]}")model_body_lines.append(" return x.sum()")model_body_str = "\n".join(model_body_lines)# 使用exec动态定义函数model_code = f"def model(x):\n{model_body_str}"# 创建一个局部命名空间来执行和捕获函数local_namespace = {}exec(model_code, {"torch": torch}, local_namespace)return local_namespace['model']# --- 准备输入数据 ---
variable_shapes = [((i % 10) + 4, 16) for i in range(TOTAL_SHAPES)]
inference_inputs_variable = [torch.randn(s, device='cuda') for s in variable_shapes]
fixed_shape = (8, 16) # 取一个典型值
inference_inputs_fixed = [torch.randn(fixed_shape, device='cuda') for _ in range(TOTAL_SHAPES)]# --- 演示函数 ---
def run_benchmark(model_to_test, inputs_to_use: list):all_timings_us = []# 预热for data in inputs_to_use[:20]: _ = model_to_test(data)torch.cuda.synchronize()for i in range(0, TOTAL_SHAPES, NUM_CALLS_PER_BATCH):chunk_of_inputs = inputs_to_use[i : i + NUM_CALLS_PER_BATCH]start_event = torch.cuda.Event(enable_timing=True); end_event = torch.cuda.Event(enable_timing=True)start_event.record()for data in chunk_of_inputs: _ = model_to_test(data)end_event.record()torch.cuda.synchronize()total_batch_time_us = start_event.elapsed_time(end_event) * 1000avg_per_call_us = total_batch_time_us / NUM_CALLS_PER_BATCHall_timings_us.append(avg_per_call_us)return np.mean(all_timings_us)# --- 实验主循环 ---
results = []
# 忽略Dynamo关于重编译限制的警告,因为它在本实验中是预期的行为
warnings.filterwarnings("ignore", category=UserWarning, message=".*torch._dynamo hit config.recompile_limit.*")for count in STMT_COUNTS:print(f"\n" + "="*20, f"正在测试 {count} 条语句", "="*20)torch._dynamo.reset() # 每次循环都重置缓存# 创建当前循环的模型current_model = create_model(count)# 1. Eager Modeprint("--> 正在测试 Eager Mode...")eager_time = run_benchmark(current_model, inference_inputs_variable)# 2. Static Compile (Fixed Shape)print("--> 正在测试 `dynamic=False` (固定形状)...")model_static_fixed = torch.compile(current_model, dynamic=False)static_time = run_benchmark(model_static_fixed, inference_inputs_fixed)# 3. Dynamic Compile (Variable Shape)print("--> 正在测试 `dynamic=True` (可变形状)...")model_dynamic = torch.compile(current_model, dynamic=True)dynamic_time = run_benchmark(model_dynamic, inference_inputs_variable)results.append({"Statements": count,"Eager (us)": eager_time,"Static (us)": static_time,"Dynamic (us)": dynamic_time,"Static Speedup": eager_time / static_time,"Dynamic Speedup": eager_time / dynamic_time})# --- 结果展示 ---
df_results = pd.DataFrame(results)
# 设置Pandas显示格式
pd.set_option('display.precision', 2)print("\n\n" + "="*30, "最终性能总结", "="*30)
print(df_results.to_string(index=False))# 为了方便绘图,打印CSV格式
print("\n--- CSV 格式结果 ---")
print(df_results.to_csv(index=False))