硅基计划3.0 学习总结 伍 优先级队列排序初识

文章目录
- 一、优先级队列
- 1. 大根堆&小根堆
- 2. 创建堆
- 3. 堆的创建&删除
- 4. 堆的应用——堆排序
- 5. 堆的应用——TopK问题
- 二、 PriorityQueue类
- 1. 构造方法
- 2. 插入元素——offer方法
- 3. 传比较器
- 4. 扩容方法grow
- 5. 完善TopK问题
- 三、 排序
- 1. 插入排序
- 2. 希尔排序(插入排序Plus版)
- 3. 选择排序
- 4. 测试三种排序效率
- 5. 堆排序
一、优先级队列
这个队列说白了也就是一维数组,但是呢内部数据是具有优先性的,可以以一个关键字或者是数字为标准进行增删查改,比如我要求最小的几个数或者是最大的几个数等等
而这个优先级队列的底层使用到了堆,而堆就类似于我们之前讲过的完全二叉树
而我们的优先级队列因此就储存在我们的一维数组中了,因此我们根据内部数据排序分为了大根堆和小根堆
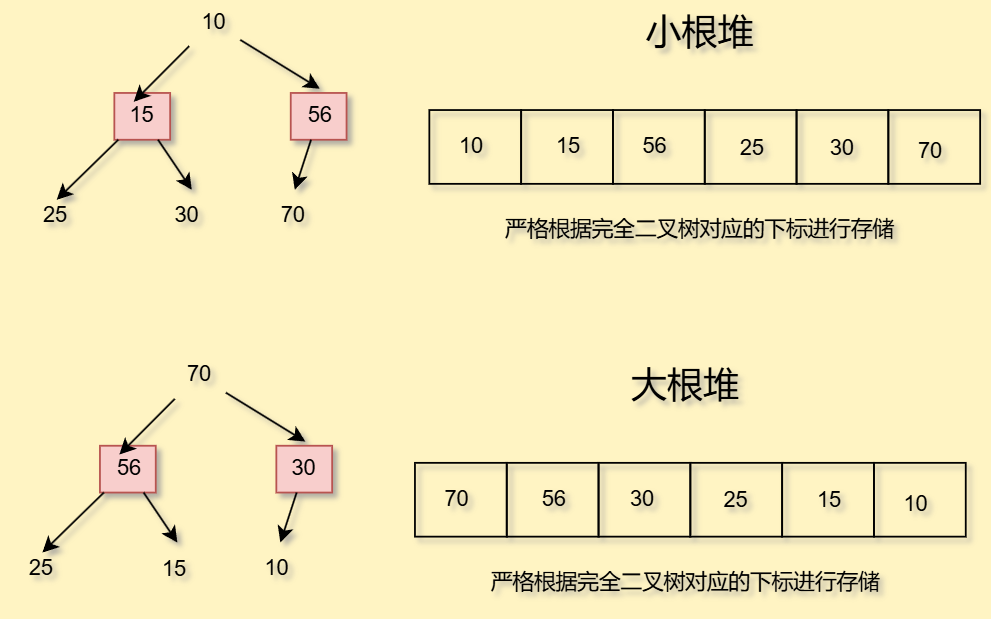
1. 大根堆&小根堆
对于左右孩子节点,大的在右边还是左边并无明确规定
- 大根堆:堆顶元素大于左右孩子节点值
- 小根堆:堆顶元素小于左右孩子节点值
2. 创建堆
我们先拿到一个数组,然后根据数组下标把对应的数字放在对应位置
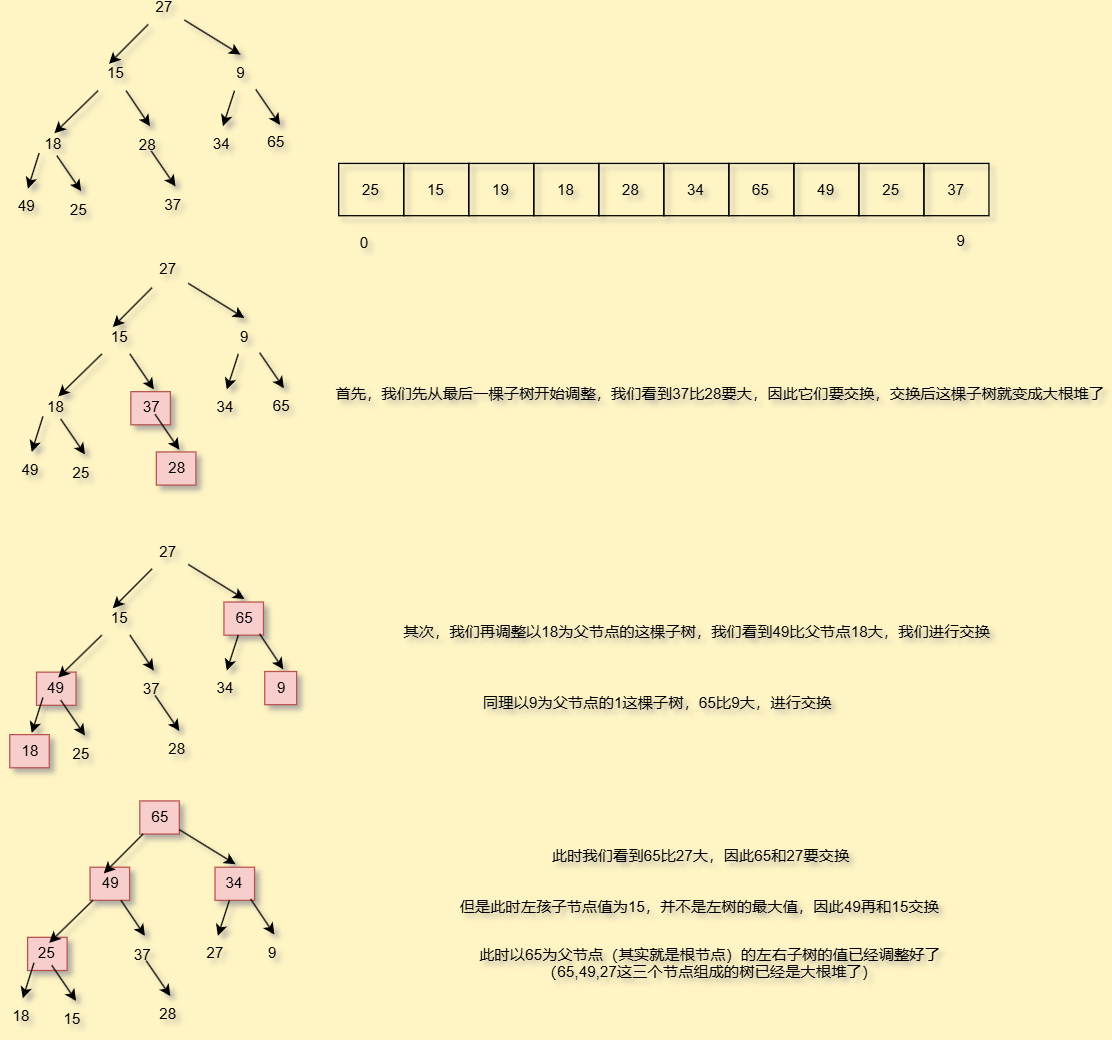
向下调整指的就是每次调整的时候从每棵子树的根节点开始向下面调整的
因此我们只需要知道每棵子树的根节点就好了
说白了就是每次调整的时候,以每一棵子树的根节点开始,往最下面的地方开始调
比如刚刚的图,如果我以65为此时的根节点,那我就要调整到25,如果我以49为此时的根节点,我还是要调整到25,为什么,你看

因此虽然当前子树是大根堆,但是你能保证当前子树的左右子树的子树是大根堆吗,不能保证
好,那我们怎么根据孩子节点求根节点呢,还记得我们之前的公式(i-1)/2吗,因此我们就可以先求数组长度,然后-1让其和数组最后一个下标重合,再带入公式,此时我们调整就是从最后一个节点的父节点开始调整了,然后循环往前走就好了
好,我们也把创建小根堆方法补充上
public class TestHeap {public int [] arrays;public int usedSize;public TestHeap() {arrays = new int[15];}//此时我们开始构造数据public void intArray(int [] array){for (int i = 0; i < array.length; i++) {arrays[i] = array[i];}usedSize = array.length;}//开始创建大根堆public void createHeap(){for(int parent = (usedSize-1-1)/2;parent>=0;parent--){//每棵子树都要被调整,父节点往前走,直到走到根节点//每次调整都是从当前的父节点开始往最后一个节点调整siftDown(parent,usedSize);}}//开始创建小根堆public void createHeaps(){for(int parent = (usedSize-1-1)/2;parent>=0;parent--){//每棵子树都要被调整,父节点往前走,直到走到根节点//每次调整都是从当前的父节点开始往最后一个节点调整upDown(parent,usedSize);}}//parent就是每次每次调整开始的父节点,usedSize就是每次调整的时候的终止节点private void siftDown(int parent, int usedSize) {int child = 2*parent+1;//此时我们要保证子节点在合法范围内//限定条件,要保证有右孩子,如果没有就不能++while(child < usedSize){if(arrays[child] < arrays[child+1] && child+1 < usedSize){child++;//如果做孩子不是最大值,那再去检查右孩子看看}//此时child是最大孩子的下标//但是你要考虑特殊情况//如果当前子树就一个左孩子呢,右孩子++的话不就越界了吗//条件加上后此时左孩子就是两个孩子节点的最大值//判断然后去看是否要交换if(arrays[child] > arrays[parent]){int temp = arrays[child];arrays[child] = arrays[parent];arrays[parent] = temp;//此时再去检查左右子树的子树是不是都是大根堆parent = child;child = 2*parent+1;}else{//如果本身就是大根堆,那就什么都不干,直接breakbreak;//如果你好奇为什么下面的不用去判断,因为我们是向下调整//我们每次调整都是从最下面一棵树开始向上走,下面的子树已经是大根堆了//那我们当前的树也就是大根堆}}}//我们尝试再写个小根堆private void upDown(int parent, int usedSize) {int child = 2*parent+1;while(child < usedSize){if(arrays[child] > arrays[child+1] && child+1 < usedSize){child++;}if(arrays[child] < arrays[parent]){int temp = arrays[child];arrays[child] = arrays[parent];arrays[parent] = temp;parent = child;child = 2*parent+1;}else{//如果本身就是大根堆,那就什么都不干,直接breakbreak;//如果你好奇为什么下面的不用去判断,因为我们是向下调整//我们每次调整都是从最下面一棵树开始向上走,下面的子树已经是大根堆了//那我们当前的树也就是大根堆}}}
}
好,我们来分析时间复杂度
如果你树的高度是h,第一层节点数为202^020个,第二次是212^121个…第h-1层是2^(h-2)个,(最后一层不用比较)
好,我们再分析每一层要调整的树的高度是多少,第一层调整除了根节点以外的层数,为h-1层,第二次是h-2层…第h-1层是1层
那我们根据时间复杂度定义,每一层有这么多节点,然后每一层的节点调整次数也不用,因此
20(h−1)+21(h−2)+......+2h−22^0(h-1)+2^1(h-2)+......+2^{h-2} 20(h−1)+21(h−2)+......+2h−2
我们进行求和,最后是2h−1−h−12^{h-1}-h-12h−1−h−1
又因为节点的个数是n=2h−1n=2^h-1n=2h−1推导出h=log(n+1)h=log(n+1)h=log(n+1),带入公式求得nlog(n+1)nlog(n+1)nlog(n+1),在n趋于无穷的时候可以忽略
因此最后时间复杂度就是O(n)
3. 堆的创建&删除
我们每次增删查改的时候,一定要保证再增删查改后的堆还是大根堆
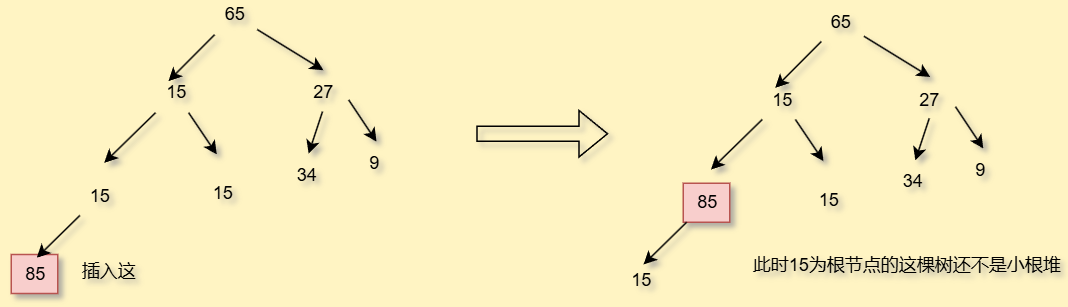
我们先来讲出插入堆,插入我们要插入到最后一个节点后面
我们之前讲过,堆就是数组,那数组满了是不是需要扩容呢,当你插入之后要看看当前的堆是不是大根堆/小根堆,如果不是要调整
插入的时候不需要比较你的另一个兄弟节点,因为我们说过大根堆和小根堆都没有明确规定左右孩子节点谁要大一点谁要小一点
插入的时候,就是向上调整了
向上调整与向下调整类似,虽然你当前的树是大根堆或者是小根堆了,但是你能保证比这更大一级的树是大根堆或者是小根堆吗,并不能,因此要继续向上调整,一直调整到子节点是0的时候或者是你的父节点是根节点的根节点(空)的时候就调完了
//插入节点public void offer(int val){if(isFull()){//满了就扩容arrays = Arrays.copyOf(arrays,arrays.length*2);}arrays[usedSize] = val;siftUp(usedSize);usedSize++;}//向上调整2.0版private void siftUp(int child){int parent = (child-1)/2;while(parent >= 0){if(arrays[child] > arrays[parent]){int temp = arrays[child];arrays[child] = arrays[parent];arrays[parent] = temp;child = parent;parent = (child-1)/2;}else{break;}}}private boolean isFull(){return usedSize == arrays.length;}
好,我们再来讲删除,好,假设现在有个堆已经是大根堆了,那我们删除完后因为要保持大根堆,因此我们可以采用删除堆顶元素方法
具体就是让最后一个元素和堆顶元素进行交换,再让usedSize减减,从而达到删除目的
此时我们仅仅只需要调整根节点所在的这棵树就好了,大大缩小了复杂度,自然就是向下调整
我们再把查看堆顶元素也实现下
public int poll(){if(isEmpty()){return -1;}//否则我们就进行交换int value = arrays[usedSize-1];int temp = arrays[0];arrays[0] = arrays[usedSize-1];arrays[usedSize-1] = arrays[0];usedSize--;//从根节点开始调整到最后一个节点的位置siftDown(0,usedSize);return value;}private boolean isEmpty(){return usedSize == 0;}public void display(){for(int i = 0;i<usedSize;i++){System.out.print(arrays[i]+" ");}System.out.println();}public int peek(){return arrays[0];}
4. 堆的应用——堆排序
如果要你从小到大排序,你是建大根堆还是小根堆呢?答案是大根堆,为什么?
你看嘛,大根堆它的堆顶元素一定是整棵树最大的元素,因此我们让堆顶元素和最后一个元素进行交换
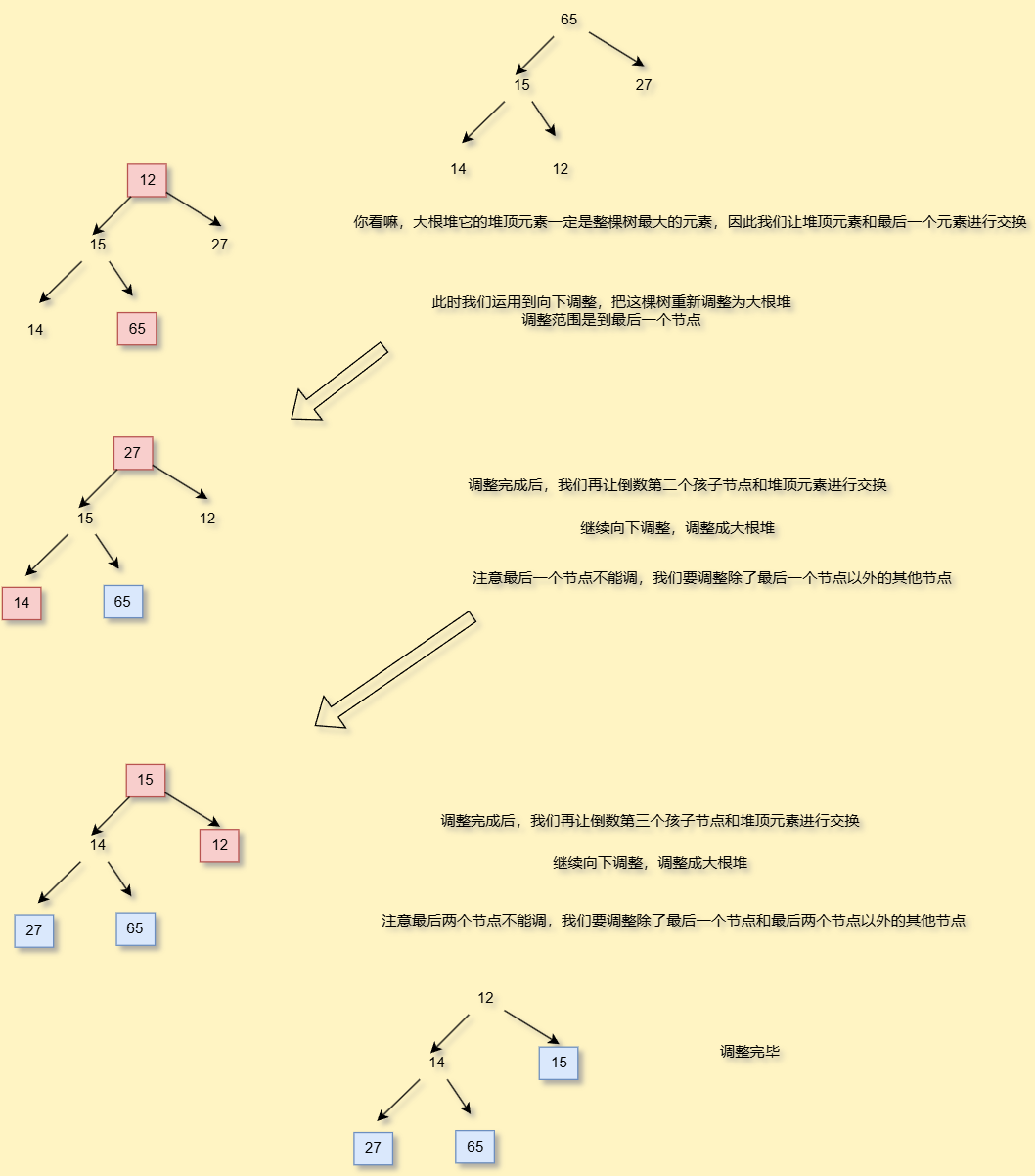
//排序,从小到大public void heapSort(){int end = usedSize-1;while(end > 0){int temp = arrays[0];arrays[0] = arrays[end];arrays[end] = temp;siftDown(0,end);end--;}}//排序,从大到小public void heapSorts(){createHeaps(); //使用小根堆构建方法int end = usedSize - 1;while (end > 0) {int temp = arrays[0];arrays[0] = arrays[end];arrays[end] = temp;upDown(0, end); //使用小根堆调整方法end--;}}
5. 堆的应用——TopK问题
这个问题就是给一组非常大的数据,让你求前几个最值
我们就举个例子吧
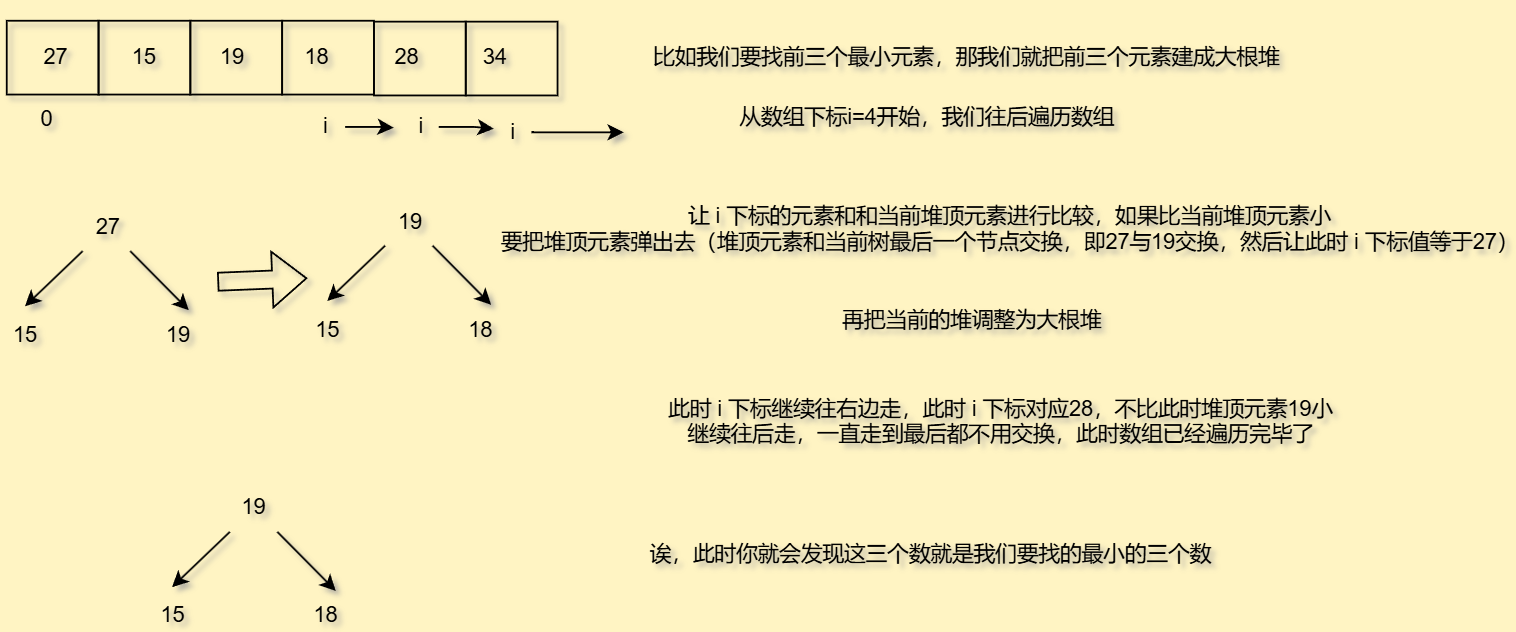
有了这种思想,我们的时间复杂度就大大降低了
时间复杂度是klogk+(n−k)logkklogk+(n-k)logkklogk+(n−k)logk,化简成nlogknlogknlogk,但是我们一般k即求前k最值的k一般很小,一次你最后化简成O(n)
而且此时堆顶元素就是我们要修的第k小或者是大的元素,amazing!
二、 PriorityQueue类
这个是Java官方提供的优先级队列的类,它的创建格式是
public static void main(String[] args) {PriorityQueue <Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(11);priorityQueue.offer(44);priorityQueue.offer(66);System.out.println(priorityQueue);}
我们可以知道打印的结果小根堆,说明了创建PriorityQueue类时,默认就是按照小根堆存放的
-
如果你
offer的几个数据不能够比较大小,比如对象之类的,那它就会抛出类型转换异常
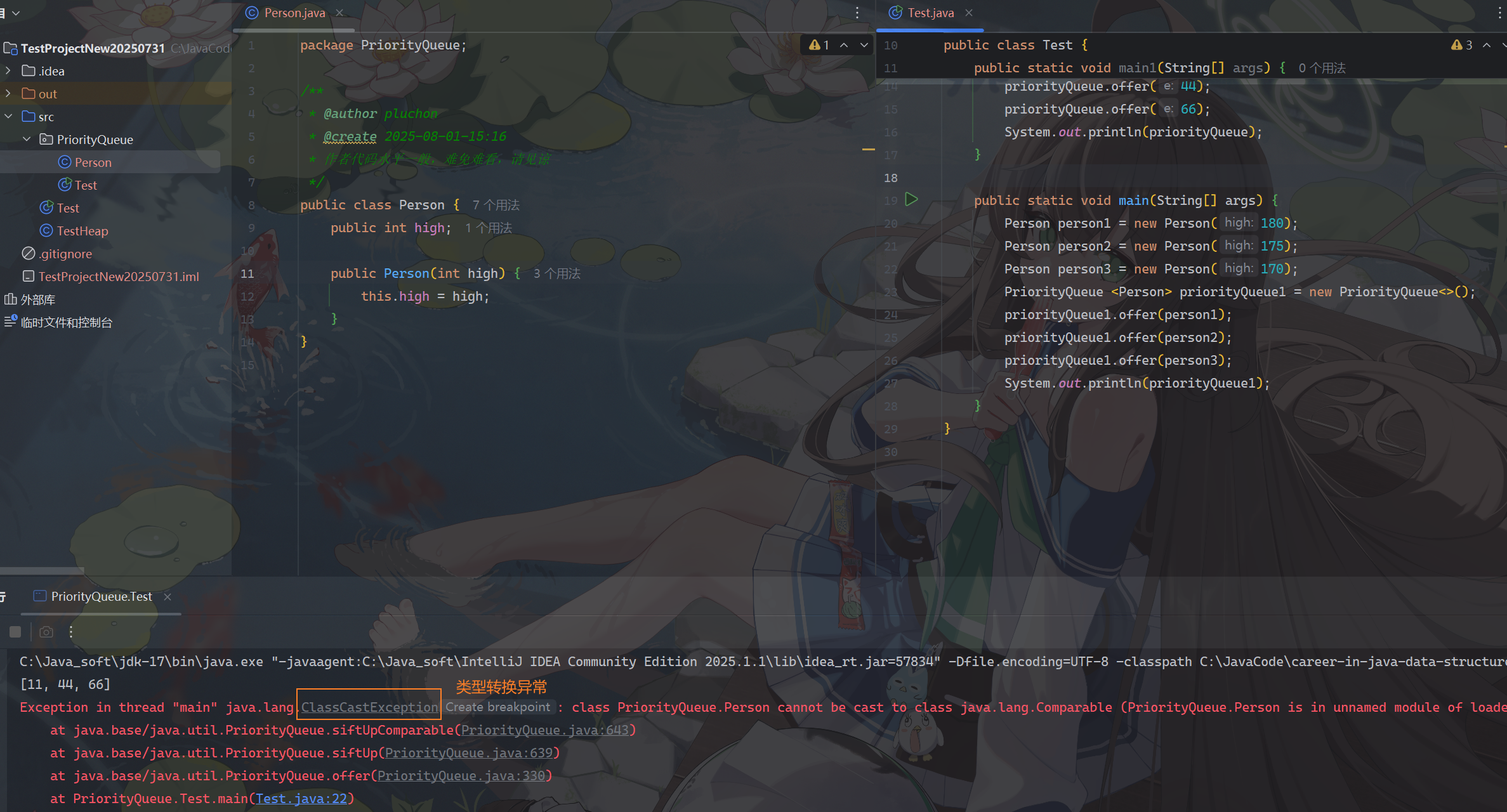
那怎么办呢,很简单,我们让Person类实现Comparable接口就好了,重写comparTo方法
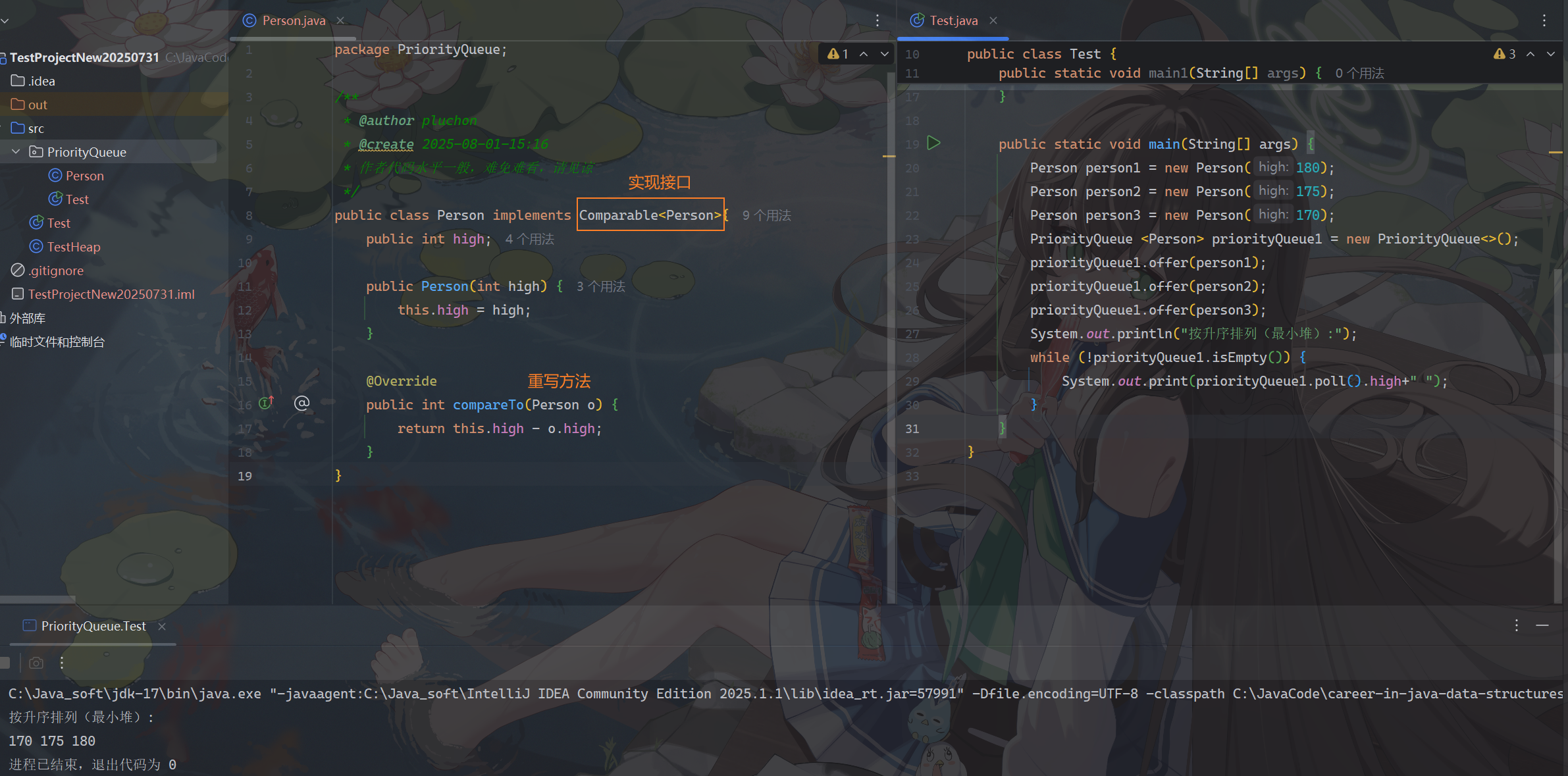
-
不可以插入空对象null,否则会抛出异常
-
插入与删除的时间复杂度都是lognlognlogn
1. 构造方法
要想了解一个类,首先就是要先了解它的构造方法
你打开会发现有几个老熟人,DEFAULT_INITIAL_CAPACITY默认大小,Object [] queue队列,size的有效个数表示等等
private final Comparator<? super E> comparator;,这个比较起我们还未初始化,因此此时是null
我们来看第一个构造方法,它是不带参的构造方法
public PriorityQueue() {this(DEFAULT_INITIAL_CAPACITY, null);}
我们可以看到其内部又调用了带两个参数的构造方法,后面那个null就是我们刚刚的比较器
接着看第二个构造方法
public PriorityQueue(int initialCapacity) {this(initialCapacity, null);}
这个就是指定容量大小,也就是说我们在传参时候可以指定这个优先级队列数组的大小,比较器默认还是null的
我们在看第三个构造方法
public PriorityQueue(int initialCapacity,Comparator<? super E> comparator) {// Note: This restriction of at least one is not actually needed,// but continues for 1.5 compatibilityif (initialCapacity < 1)throw new IllegalArgumentException();this.queue = new Object[initialCapacity];this.comparator = comparator;}
我们刚刚两个构造方法就是调用了这个构造方法,我们只能指定数组大小,并不能指定比较器
我们再看下一个构造方法,是一个比较器的构造方法
public PriorityQueue(Comparator<? super E> comparator) {this(DEFAULT_INITIAL_CAPACITY, comparator);}
还有其他构造方法,就不一样叙述了
2. 插入元素——offer方法
public boolean offer(E e) {if (e == null)throw new NullPointerException();modCount++;int i = size;if (i >= queue.length)grow(i + 1);siftUp(i, e);size = i + 1;return true;}
我们点开siftUp方法
private void siftUp(int k, E x) {if (comparator != null)siftUpUsingComparator(k, x, queue, comparator);elsesiftUpComparable(k, x, queue);}
可以看到当我们比较器是null时候调用了siftUpUsingComparator(k, x, queue, comparator);方法
private static <T> void siftUpUsingComparator(int k, T x, Object[] es, Comparator<? super T> cmp) {while (k > 0) {int parent = (k - 1) >>> 1;Object e = es[parent];if (cmp.compare(x, (T) e) >= 0)break;es[k] = e;k = parent;}es[k] = x;}
你会发现这个和我们写的小根堆的方法非常类似,>>>1指的是除以2的意思
但是这也就说明了源码是默认小根堆的,那我如果想去实现大根堆怎么搞呢,总不能去修改源码吧
因此我们就要自己去重写compareTo方法,我们之前已经写过了,我们直接拿过来
public class Person implements Comparable<Person>{public int high;public Person(int high) {this.high = high;}@Overridepublic int compareTo(Person o) {return o.high - this.high;}
}public static void main(String[] args) {Person person1 = new Person(180);Person person2 = new Person(175);Person person3 = new Person(170);PriorityQueue <Person> priorityQueue1 = new PriorityQueue<>();priorityQueue1.offer(person1);priorityQueue1.offer(person2);priorityQueue1.offer(person3);System.out.println("按升序排列(最大堆):");while (!priorityQueue1.isEmpty()) {System.out.print(priorityQueue1.poll().high+" ");}}
3. 传比较器
我们刚刚看到构造方法可以传入自己的比较器,那我们就自己写一个比较器
public class MaxComparator implements Comparator<Integer> {@Overridepublic int compare(Integer o1,Integer o2) {return o2.compareTo(o1);//o2-o1//return o1.compareTo(o2);//o1-o2}
}public static void main(String[] args) {MaxComparator maxComparator = new MaxComparator();PriorityQueue <Integer> priorityQueue1 = new PriorityQueue<>(maxComparator);priorityQueue1.offer(11);priorityQueue1.offer(15);priorityQueue1.offer(18);while (!priorityQueue1.isEmpty()) {System.out.print(priorityQueue1.poll()+" ");}}
因此此时的构造方法调用的就是有比较器的siftUpComparable方法了
4. 扩容方法grow
我们可以去看源码
private void grow(int minCapacity) {int oldCapacity = queue.length;// Double size if small; else grow by 50%int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity < 64 ? oldCapacity + 2 : oldCapacity >> 1/* preferred growth */);queue = Arrays.copyOf(queue, newCapacity);}
我们可以看到如果小于64容量,我们就二倍扩容,否则就是1.5倍扩容
但是如果容量超过了整型最大值减去8这个容量时,就以MAX_ARRAY_SIZE进行扩容
5. 完善TopK问题
还记得我们上节课遗留的TopK问题吗,我们就可以用这个传比较器的思想去完成
这里给出题目题目链接
class Solution {public int[] smallestK(int[] array, int k) {int [] ret = new int[k];if(array == null || k <= 0){//验证合法性return ret;}//传入比较器MaxComparator maxComparator = new MaxComparator();//建立优先级队列PriorityQueue <Integer> priorityQueue = new PriorityQueue<>(maxComparator);//把前K个建成大根堆for(int i = 0;i < k;i++){priorityQueue.offer(array[i]);}//遍历剩下N-K个元素for(int i = k;i<array.length;i++){//查看堆顶元素int peekValue = priorityQueue.peek();if(peekValue > array[i]){//说明堆顶元素不是最小的前K个数priorityQueue.poll();//把比原先堆顶元素更小的数放进去priorityQueue.offer(array[i]);}}//把结果放进数组内for(int i = 0;i < k;i++){ret[i] = priorityQueue.poll();}return ret;}
}public class MaxComparator implements Comparator<Integer> {@Overridepublic int compare(Integer o1,Integer o2) {return o2.compareTo(o1);//o2-o1//return o1.compareTo(o2);//o1-o2}
}
三、 排序
排序它的核心思想就是我们对一个新的值插入到已经排列好的序列中去
我们先来讲什么是稳定和不稳定

- 内部排序:内存中排序
- 外部排序:不在内存中排序,但是和内部排序紧密联系,交换数据
1. 插入排序
顾名思义就是插入数字后进行排序,且看我图解

好,那么如何去比较数字呢,很简单,我们定义一个中间变量tmp,每次把i下标的数字放入中间变量tmp中,然后让j下标数字和tmp去比,如果比i下标的数字小,说明此时j下标和i下标时间是从小到大的顺序,符合要求
如果j下标数字比i下标大,那就要把下标j位置的数字放在j+1,为什么不是放在i下标呢
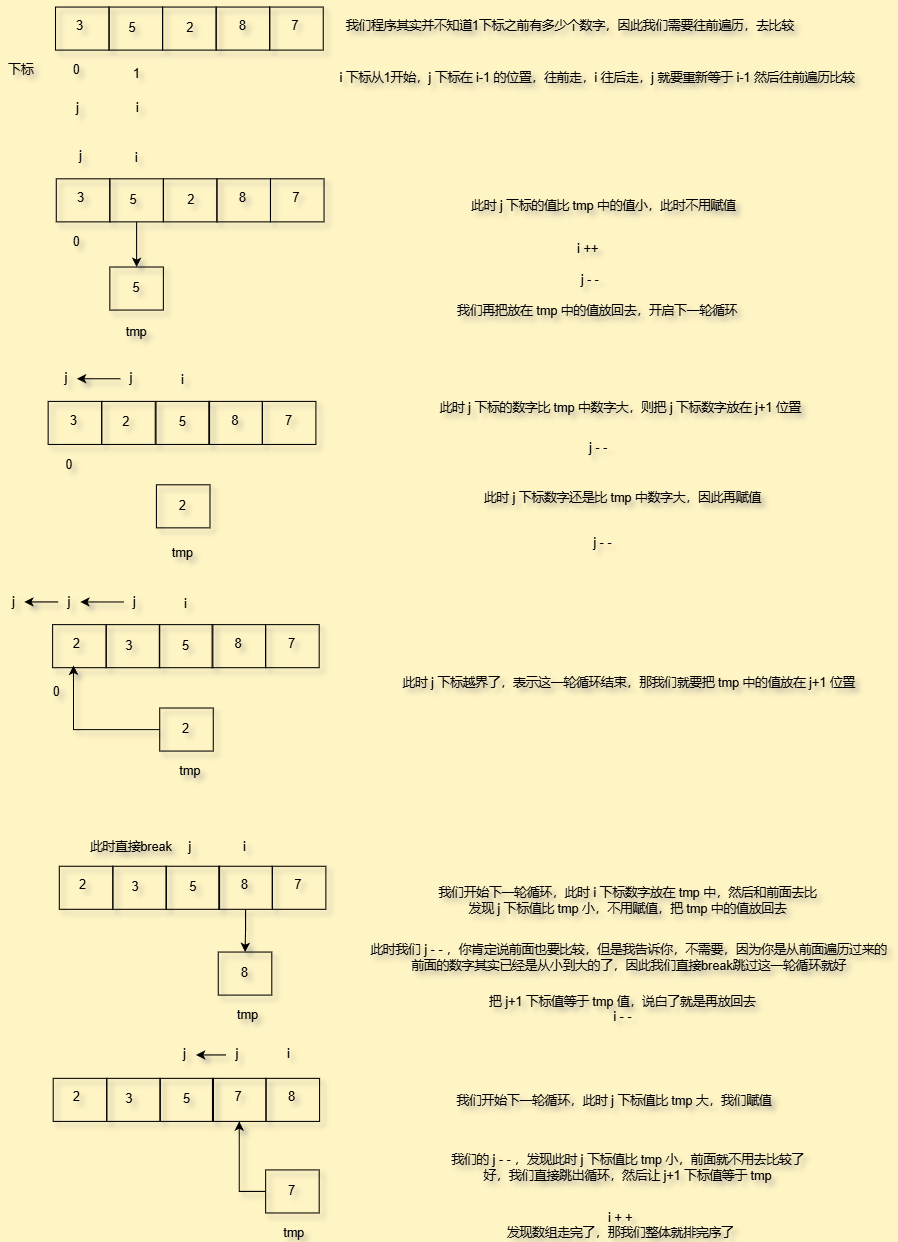
好,你问为什么我们不把值放在i下标位置,这会导致排序错误,请看演示
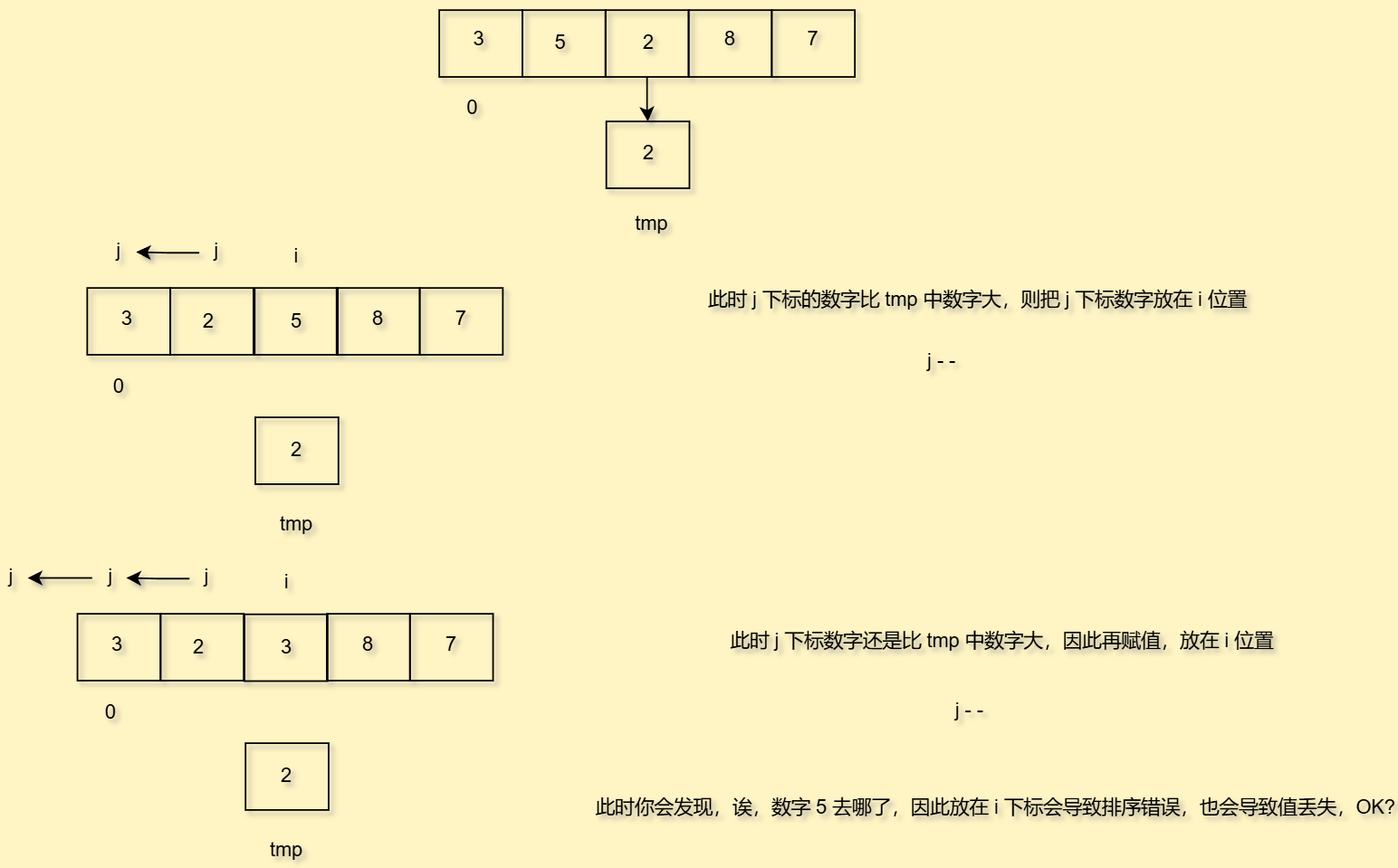
那好,我们来完善代码吧
//直接插入排序public void insertSort(int [] array){for(int i = 1; i < array.length;i++){int tmp = array[i];int j = i-1;for(; j >= 0;j--) {if (array[j] > tmp) {//小于就赋值array[j + 1] = array[j];} else {array[j + 1] = tmp;break;}}//记得要把tmp值放在数组开头,也就是j+1位置array[j+1] = tmp;}}
我们来分析时间复杂度,最坏的情况我们就是要把全部是从大到小的数据排列成从小到大的数据,每次排序排比当前下标所在位置少一个的元素(刚刚演示过)
是一个等差数列,我们求和结果是∑n2\sum n^2∑n2,因此时间复杂度就是O(n2n^2n2)
空间复杂度就是O(1),因为没有申请额外空间
我们重点来分析稳定性方面
我们的交换条件是array[j]>tmp,因此如果数字相同,并不会产生交换,从而保持了稳定
比如2(红) 5 2,此时虽然值一样,但是我们的交换条件不满足,因此还是会保持原来位置
但是,这种稳定性是我们人为可以打破的,如果把交换条件改成array[j]>=tmp,那就会交换位置,导致位置变化,比如2(红) 5 2–>2 5 2(红)
因此,如果一个排序本身是稳定的,那它一定可以转变成不稳定排序
反之,如果这个排序本身就不稳定,那它就不可能稳定了
2. 希尔排序(插入排序Plus版)
我们的希尔排序又叫缩小增量排序,它的核心就是分组,然后让每一组进行插入排序
排序后每一组内部都是有序的了,然后我们再次分组,比上次分组少,然后再排序,再分组,直到分为一组,然后排序,这下整体就是有序的了
你问为什么它比插入排序更牛,其实是因为你每一组数据都比较少,然后你排完序再分组的时候,由于上一次排序让部分数字有序了,因此你这一次分组虽然每组数字比上次多
但是每组数字都是比上一次有序了,实际上这一次排序比上一次排序工作量更小,因此也就造就了数据越有序,排序就越高效
好,在希尔排序中,我们把每次分的组总数叫做gap,关于这个组怎么分呢,其实现在科学界并无确切定论
有跳跃式分组:即当前数字和后面不想领数字为一组,这样就有一个好处,就是可以让大的数字往后边走,小的数字往前面来
还有我们可以对半分,即每次分组除以2,或者是对三分,除以3都可以,我们就以对半分为例
这个逻辑还是跟之前直接插入排序类似

好,为什么我们每次让j要往前走j-gap步呢?
你想,我们希尔排序本质上就是对对一组内进行排序,如果j--,那是不是会导致不同的组进行排序,就比如8(红色那组) 6(蓝色那组) 9(红色那组),如果我们i等于9,j等于8,这样只是在红色那一组内排序,符合希尔排序要求
但是如果我们i等于9,j等于8,会导致我们在蓝色和红色组内排序,不符合希尔排序要求
当我们两组再排完序之
我们再把所有数字看成一个整体再进行排序,由于上一次排序部分数字是有序的,因此我们这一次排序就比上次高效的多
我们让初识gap等于数组长度,即每个元素看成一组,然后每次除以2分组,直到分为一组
说白了就是几组数字交替排序
//希尔排序
public void shellSort(int [] array){int gap = array.length;while(gap > 1){gap /= 2;shell(array,gap);}
}//每一轮希尔排序
private void shell(int[] array, int gap) {//每一次排序都从中间位置往后走for(int i = gap;i <array.length;i++){int tmp = array[i];int j = i - gap;for(;j >= 0;j-=gap){if(array [j] > tmp){//关键一步array[j+gap] = array[j];}else{break;}}array[j+gap] = tmp;}
}
由于希尔排序对gap分组极其敏感,目前又尚无定论,因此时间复杂度并不能确定,但是目前测算比较准确的是在n1.3n1.5n^1.3 ~ n^1.5n1.3 n1.5之间
因此我们和直接插入排序的时间复杂度比较O(n2n^2n2),因此这就是为什么说希尔排序是直接插入排序的高效版本,但是希尔排序是不稳定排序,本质原因在于分组跳跃式交换机制
3. 选择排序
本质上就是数字的交换,且看我图解
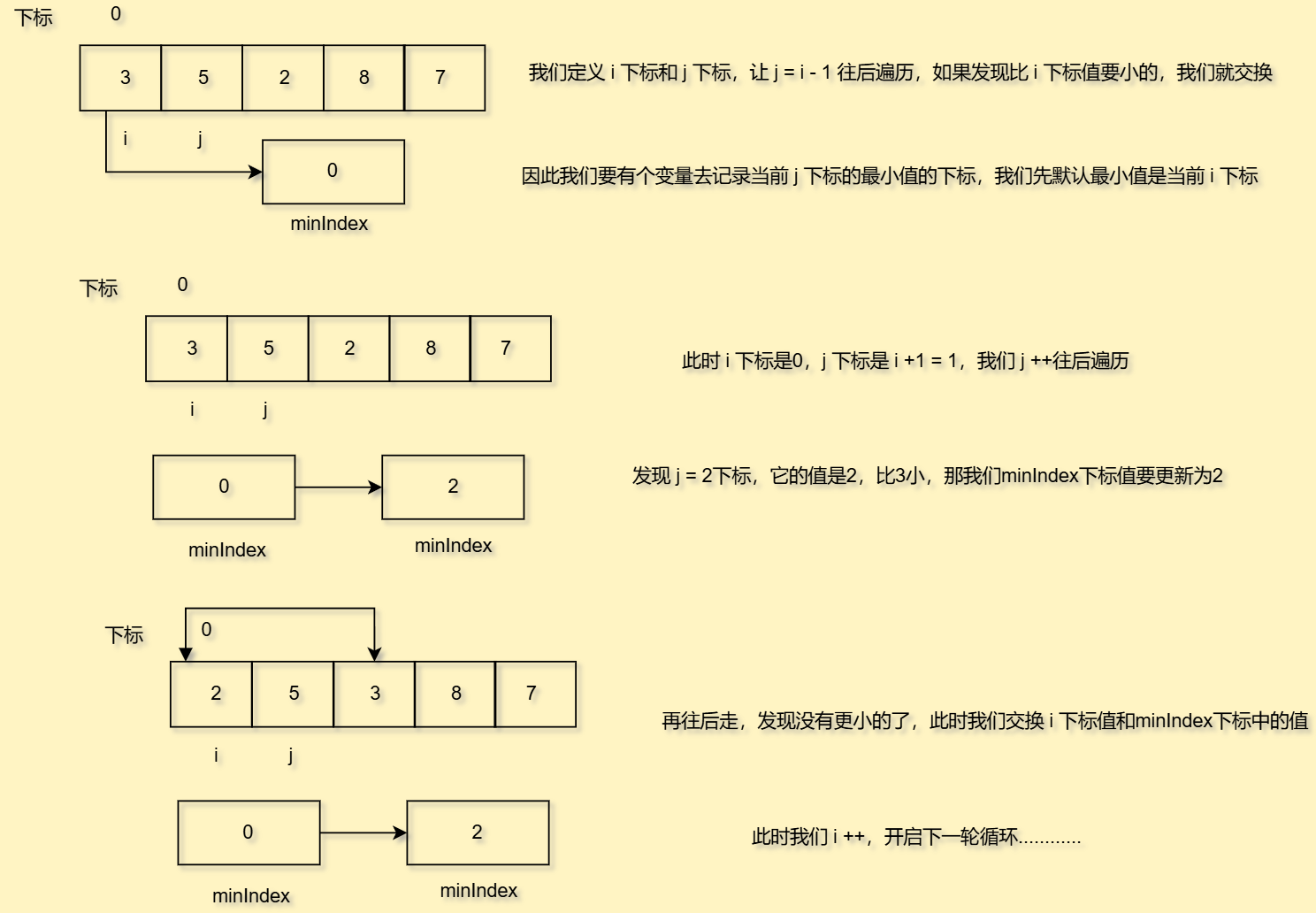
//选择排序public void selectSort(int [] array){for(int i = 0;i<array.length;i++){int minIndex = i;for (int j = i+1; j < array.length; j++) {if(array[j] < array[minIndex]){//更新最小值下标minIndex = j;}}//如果遍历一圈下来最小值下标就是i本身,就没必要交换了if(i == minIndex){break;}//说明此时minIndex中的下标值就是最小值int tmp = array[i];array[i] = array[minIndex];array[minIndex] = tmp;}}
好,我们来分析时间复杂度,由于每次都要排序比当前下标少一个的次数,因此还是等差数列,求和好时间复杂度还是O(n2n^2n2)
由于没有申请额外空间,空间复杂度就是O(1)
而且它不稳定,我们每一轮排序都有跳跃式交换数字
int tmp = array[i];
array[i] = array[minIndex];
array[minIndex] = tmp;
4. 测试三种排序效率
public static void main(String[] args) {//测试,倒序数组int [] array = new int[200000];for(int i = array.length-1;i >= 0 ;i--){array[i] = i;}//测试,正序数组int [] arrays = new int[200000];for(int i = 0;i < arrays.length;i++){arrays[i] = i;}//测试,随机数组Random random = new Random();int [] arrayss = new int[50000];for (int i = 0; i < arrayss.length; i++) {arrayss[i] = random.nextInt(150);}//测试插入排序testInsertSort(array);testInsertSort(arrays);testInsertSort(arrayss);//测试希尔排序testShellSort(array);testShellSort(arrays);testShellSort(arrayss);//测试选择排序testSelectSort(array);testSelectSort(arrays);testSelectSort(arrayss);}public static void testInsertSort(int [] array){MySort mySort = new MySort();array = Arrays.copyOf(array,array.length);Long startTime = System.currentTimeMillis();mySort.insertSort(array);Long endTime = System.currentTimeMillis();System.out.println("直接插入排序时间差是:"+(endTime-startTime));}public static void testShellSort(int [] array){MySort mySort = new MySort();array = Arrays.copyOf(array,array.length);Long startTime = System.currentTimeMillis();mySort.insertSort(array);Long endTime = System.currentTimeMillis();System.out.println("希尔排序排序时间差是:"+(endTime-startTime));}public static void testSelectSort(int [] array){MySort mySort = new MySort();array = Arrays.copyOf(array,array.length);Long startTime = System.currentTimeMillis();mySort.insertSort(array);Long endTime = System.currentTimeMillis();System.out.println("选择排序时间差是:"+(endTime-startTime));}
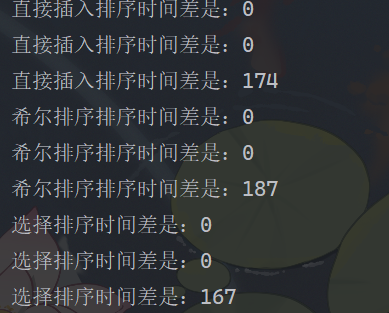
但是记住,时间只是辅助验证,即使时间复杂度不一样,但是时间也是存在相同情况
就比如我的选择排序和直接插入排序时间复杂度是一样的,但是时间差却不同
因此时间复杂度≠时间差时间复杂度≠时间差时间复杂度=时间差
5. 堆排序
已经在优先级队列中写过了,这里就不再赘述,时间复杂度是O(nlogn),而且不稳定,没有额外申请空间则空间复杂度是O(1)