机器学习-KNN
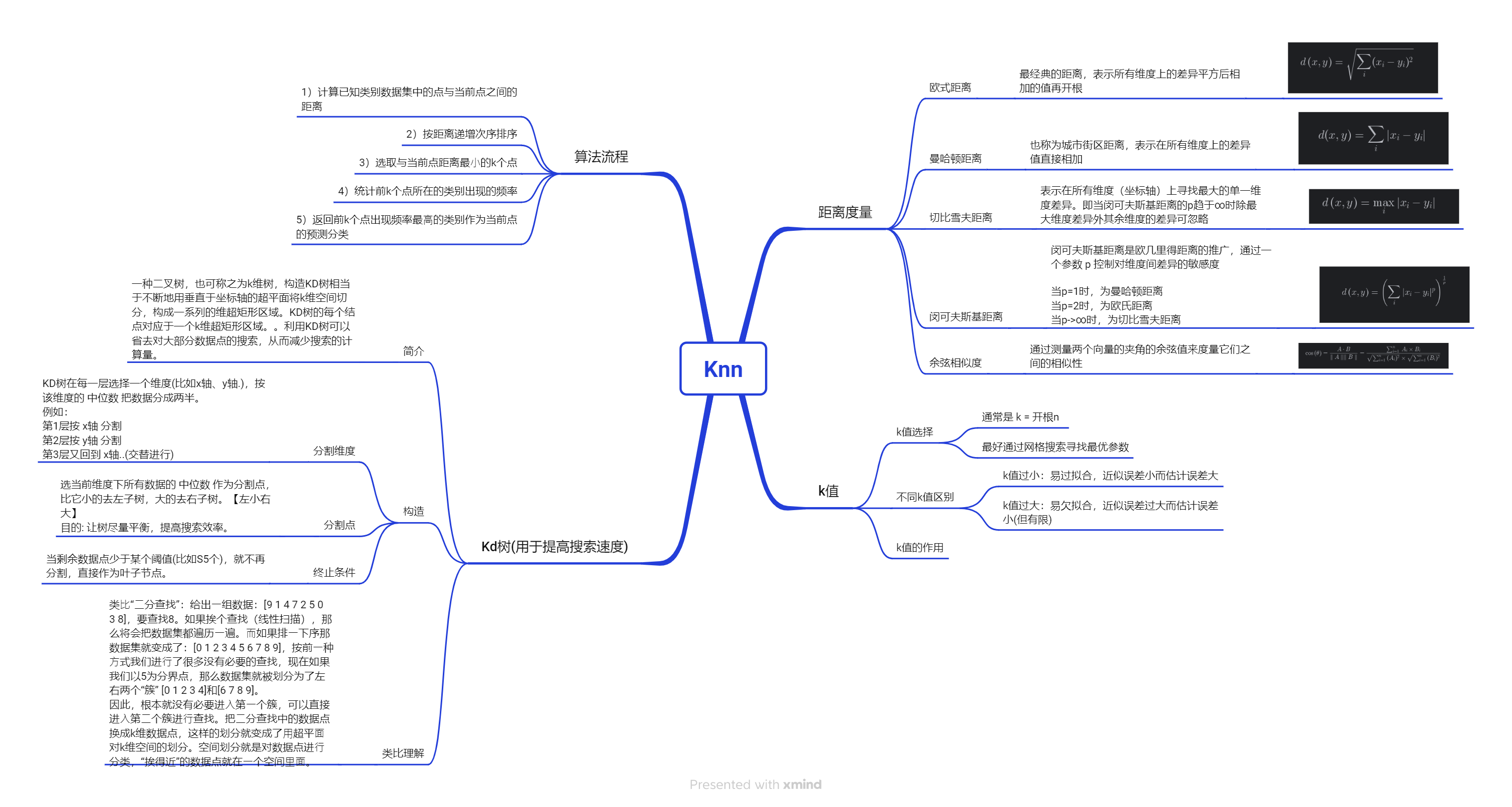
一、相关知识点
二、利用KNN完成香蕉和苹果的识别
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import cv2
import os
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifierdef preprocess(img):# image_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度化# # 加入sobel算子用于提取边缘信息# # # 高斯滤波,去除噪声防止干扰边缘提取# gaussian = cv2.GaussianBlur(image_gray, (5, 5), sigmaX=2) # sigmax为2是因为只有两种颜色# # 垂直梯度处理,(滤波)# image_ver = cv2.filter2D(gaussian, -1, kernel_ver)# # # 水平梯度处理,(滤波)# # image_hor = cv2.filter2D(gaussian, -1, kernel_hor)# image_ver = cv2.resize(image_ver, target_size)# flattened_edge = image_ver.flatten()# # -----至此获取到了图像的边缘信息-----img = cv2.resize(img, target_size)img_flat = img.flatten() # 展平,否则knn无法读取# -----以上是图像的原本信息-----# combined_features = np.concatenate([flattened_edge, img_flat])# -----拼接,在不损失颜色信息的前提下同时加入边缘信息----return img_flat# # sobel算子,用于提取边缘
# # 垂直梯度算子
# kernel_ver = np.array([[-1, 0, -1],
# [-2, 0, 2],
# [-1, 0, 1]])
# # 水平梯度算子
# kernel_hor = np.array([[-1, -2, -1],
# [0, 0, 0],
# [1, 2, 1]])# 读取图片并预处理
images = []
target_size = (100, 100)
for file_name in os.listdir('../data/fruit/img'):img = cv2.imread(f'../data/fruit/img/{file_name}')img_flat = preprocess(img)images.append(img_flat)
print(len(images))
# 2. 转成 NumPy 数组 (n_samples, n_features)
X = np.array(images, dtype=np.float32)
# 3.标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 4.读取标签
labels = []
for file_name in os.listdir('../data/fruit/label'):with open(f'../data/fruit/label/{file_name}', 'r', encoding='utf-8') as f:first_char = f.read(1)labels.append(first_char)
print(len(labels))y = labels# -----------------训练# 分出训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=42
)# 训练
for i in range(3, 15):estimator = KNeighborsClassifier(n_neighbors=i, weights='distance')estimator.fit(X_train, y_train) # fit的X参数必须输入二维的# 评估y_pred = estimator.predict(X_test)# 准确率accuracy = estimator.score(X_test, y_test)print(accuracy)# 对比找出分类错误的样本misclassified_indices = np.where(y_pred != y_test)[0]print(misclassified_indices)#
estimator = KNeighborsClassifier(n_neighbors=5)
estimator.fit(X_train, y_train) # fit的X参数必须输入二维的
sample = cv2.imread('F:\py_MachineLearning\MachineLearning\MachineLearning\img.png')
sample=preprocess(sample)
sample = sample.reshape(1, -1)
sample_pred = estimator.predict(sample)print("测试:",sample_pred)