嵌入式 - 数据结构:数据结构基础与链表
目录
一、数据结构核心概念
1. 数据结构的本质
2. 代码质量的衡量标准
二、数据结构的分类体系
1. 逻辑结构
2. 存储结构
3. 常见数据结构
三、链表深度解析
1. 链表与顺序表的对比
2. 链表的分类及特点
3. 单向链表的实现
(1)节点定义
(2)空链表创建
(3)头插法
(4)链表遍历
(5)节点删除
四、工程管理工具 Makefile
1. Makefile 的作用
2. 基本使用流程
3. 语法规则
五、实战练习
1、 封装一个函数返回链表中第一个指定元素节点的地址
2、封装一个函数将链表中指定元素的值更新为新值
3、尾插法实现
一、数据结构核心概念
1. 数据结构的本质
程序的本质可以概括为 "程序 = 数据结构 + 算法",这一公式揭示了数据结构在程序设计中的核心地位。数据结构主要描述两方面内容:一是数据的存储和组织方式,二是操作这些数据对象的方法。
2. 代码质量的衡量标准
评价一段代码的优劣,通常从时间复杂度和空间复杂度两个维度考量:
-
时间复杂度:描述数据量增长与程序运行时间增长之间的比例关系,称为时间渐进复杂度函数。常见的时间复杂度从低到高排序如下:
- O (1):运行时间恒定,不受数据量影响,如数组随机访问
- O (logn):初期增长较快,数据量达到一定规模后趋于平缓,如二分查找
- O (n):运行时间与数据量呈线性增长,如线性查找
- O (nlogn):常见于高效排序算法,如快速排序、归并排序
- O (n²)、O (n³):多项式级复杂度,多见于嵌套循环
- O (2ⁿ):指数级复杂度,如递归实现的斐波那契数列
-
空间复杂度:反映数据量增长与程序占用空间增长的比例关系。在实际开发中,往往需要在时间复杂度和空间复杂度之间做权衡,即所谓的 "以空间换时间" 或 "以时间换空间"。
二、数据结构的分类体系
1. 逻辑结构
逻辑结构描述数据元素之间的逻辑关系,主要分为:
- 线性结构:元素之间为一对一关系,如各种表结构
- 非线性结构:包括一对多关系的树结构和多对多关系的图结构
2. 存储结构
存储结构关注数据在计算机中的物理存储方式,主要有四种:
- 顺序存储:数据元素连续存放,如数组
- 链式存储:通过指针链接分散的存储单元,如链表
- 散列存储:利用哈希函数映射到存储空间,如哈希表
- 索引存储:通过索引表快速定位数据位置
3. 常见数据结构
实际开发中常用的数据结构包括:
- 顺序表
- 链式表
- 顺序栈
- 链式栈
- 顺序队列
- 链式队列
- 二叉树
- 邻接表
- 邻接矩阵
三、链表深度解析
1. 链表与顺序表的对比
顺序表(数组)和链表作为两种基本的线性结构,各有特点:
| 特性 | 顺序表 | 链表 |
|---|---|---|
| 存储空间 | 连续 | 不连续 |
| 空间利用 | 需连续大空间,利用率低 | 可利用零散小空间 |
| 访问效率 | 随机访问方便(O (1)) | 需顺序访问(O (n)) |
| 元素数量 | 有限制(受初始化大小影响) | 理论上无上限 |
| 插入删除 | 效率低(需移动元素) | 效率高(仅需修改指针) |
顺序表的优势在于随机访问的高效性,而链表则在动态插入和删除操作上表现更优至。
2. 链表的分类及特点
- 单向链表:节点仅包含指向下一节点的指针,访问方向单一

- 双向链表:节点同时包含前驱和后继指针,可双向遍历

- 循环链表:首尾节点相连,可从任一节点遍历整个链表

- 内核链表:Linux 内核采用的通用链表结构,将指针嵌入数据结构而非作为外部包装
3. 单向链表的实现
(1)节点定义
单向链表节点通常包含数据域和指针域两部分:
/* 链表存放数据的类型 */
typedef int datatype;/* 链表节点类型 */
typedef struct node {datatype data; // 存放数据的空间struct node *pnext; // 存放下一个节点的地址
} linknode;//struct node 是结构体名称 是类型
//linknode 等价于上方 是类型(link-链 node-节点)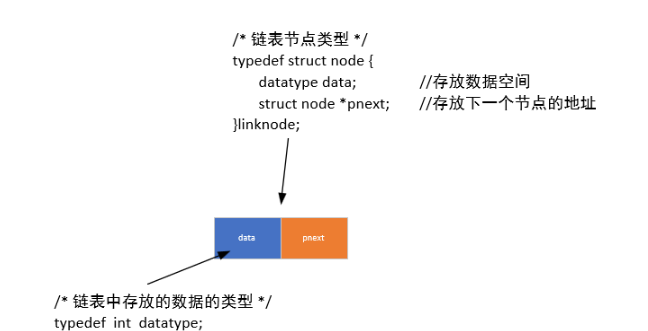
这种结构设计使得每个节点既可以存储数据,又能指向链表中的下一个节点。
(2)空链表创建
创建空链表时,需注意指针域的初始化:
- 创建一个空的链表节点
- data不需要赋值(最好赋值),空白节点不存放数据,主要为了保证链表操作的便利性
- pnext必须赋值为NULL,表示该节点为最后一个节点
- 将节点地址返回
/* 创建一个空链表 */
linknode *create_empty_linklist(void)
{linknode *ptmpnode = NULL;ptmpnode = malloc(sizeof(linknode));if (NULL == ptmpnode){perror("fail to malloc");return NULL;}ptmpnode->pnext = NULL; // 空链表的指针必须指向NULLreturn ptmpnode;
}/* 创建新节点函数* 参数:data - 节点存储的数据* 返回值:成功返回节点指针,失败返回NULL */
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node)); // 动态分配内存空间if (newNode == NULL) { // 内存分配失败检查printf("内存分配失败!\n");return NULL;}newNode->data = data; // 设置节点数据newNode->next = NULL; // 初始化指针域为NULLreturn newNode; // 返回新节点地址
}
空链表的头节点不存放有效数据,主要用于简化链表操作,其指针域必须设置为 NULL至。
(3)头插法
头插法是在链表头部插入新节点的操作,步骤如下:
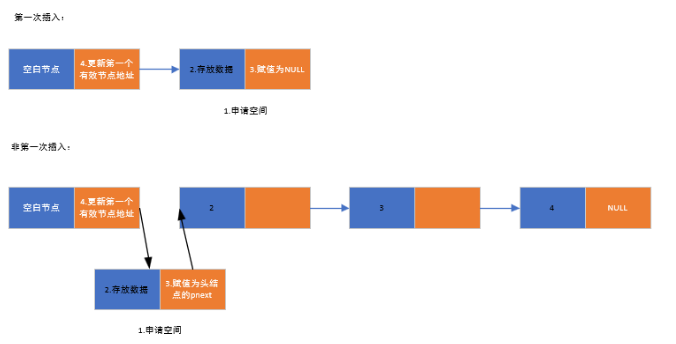
- 为新节点分配内存空间
- 将数据存入新节点的数据域
- 将新节点的指针域指向头节点原来的后继节点
- 更新头节点的指针域指向新节点
/* 插入一个节点(头插法) */
int insert_head_linklist(linknode *phead, datatype tmpdata)
{linknode *ptmpnode = NULL;// 申请空间ptmpnode = malloc(sizeof(linknode)); if (NULL == ptmpnode){perror("fail to malloc");return -1;}// 存放数据ptmpnode->data = tmpdata;// 存放下一个节点地址ptmpnode->pnext = phead->pnext;// 更新头节点的pnextphead->pnext = ptmpnode;return 0;
}
头插法的时间复杂度为 O (1),适合需要频繁在头部插入数据的场景至。
(4)链表遍历
遍历链表需从头节点开始,依次访问每个节点:
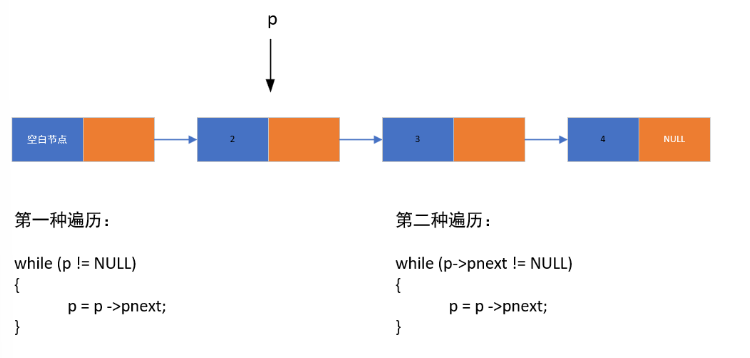
方法一:多用于遍历链表中所有节点元素
方法二:多用于找到链表最后一个节点
/*遍历链表节点元素*/
void show_linklist(linknode *phead)
{linknode *ptmpnode = NULL;ptmpnode = phead->pnext;//第一种遍历方法:全部成员都可访问while(ptmpnode != NULL){printf("%d ",ptmpnode->data);ptmpnode = ptmpnode->pnext;}// 多用于找到链表最后一个节点// while(ptmpnode->pnext != NULL)// {// printf("%d ",ptmpnode->data);// ptmpnode = ptmpnode->pnext;// }printf("\n");return;
}
遍历操作的时间复杂度为 O (n),需访问链表中的每个节点。实际开发中,可根据需求修改遍历函数,如添加数据过滤、统计等功能。
(5)节点删除
删除指定元素的节点需要两个指针协作:
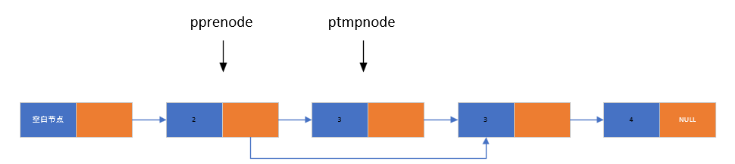
- 定义两个指针ptmpnode用来遍历链表查找要删除的节点元素,pprenode永远只想
- ptmpnode的前一个节点
- 当ptmpnode找到要删除的节点元素,让pprenode->pnext赋值为ptmpnode->pnext
- 将要删除的节点元素释放
- 让ptmpnode判断下一个节点元素是否要删除,直到该指针指向NULL为止
/* 删除指定的链表节点元素 */
int delete_linklist(linknode *phead, datatype tmpdata)
{linknode *pprenode = NULL; // 前驱节点指针linknode *ptmpnode = NULL; // 当前节点指针pprenode = phead;ptmpnode = phead->pnext;while (ptmpnode != NULL){if (ptmpnode->data == tmpdata){pprenode->pnext = ptmpnode->pnext; // 跳过当前节点free(ptmpnode); // 释放内存ptmpnode = pprenode->pnext; // 继续检查下一个节点}else {// 未找到目标,两个指针同时后移ptmpnode = ptmpnode->pnext;pprenode = pprenode->pnext;}}return 0;
}
删除操作需注意避免内存泄漏,必须释放被删除节点的内存空间至。
四、工程管理工具 Makefile
1. Makefile 的作用
Makefile 是一款强大的工程管理工具,主要用于:
- 管理代码的编译流程
- 根据预设规则选择需要编译的代码
- 通过依赖关系和时间戳判断是否需要重新编译
使用 Makefile 可以显著提高大型项目的编译效率,避免每次都重新编译所有文件。
2. 基本使用流程
- 在工程目录下创建名为 Makefile 或 makefile 的文件
- 编写编译规则,定义目标文件、依赖文件和编译命令
- 在终端执行
make命令调用 Makefile 进行编译 - 编译成功后运行生成的可执行程序
3. 语法规则
Makefile 的核心语法规则为:
目标文件: 依赖文件列表生成目标的命令(必须以Tab开头)
例如,编译一个包含 main.c 和 linklist.c 的项目,Makefile 可写为:
app: main.o linklist.ogcc main.o linklist.o -o app
main.o: main.cgcc -c main.c -o main.o
linklist.o: linklist.cgcc -c linklist.c -o linklist.o
clean:rm -f *.o app
五、实战练习
1、 封装一个函数返回链表中第一个指定元素节点的地址
linknode *find_linklist(linknode *phead,datatype tmpdata)
{linknode *pprenode = NULL;linknode *ptmpnode = NULL; pprenode = phead;ptmpnode = phead->pnext;while(tmpdata != ptmpnode->data){ptmpnode = ptmpnode->pnext;pprenode = pprenode->pnext;}ptmpnode = pprenode->pnext;return ptmpnode;}2、封装一个函数将链表中指定元素的值更新为新值
/*更新指定元素的值*/
int update_linklist(linknode *phead,datatype olddata,datatype newdata)
{linknode *ptmpnode = NULL;ptmpnode = phead->pnext;while (ptmpnode != NULL){if(ptmpnode->data == olddata){ptmpnode->data = newdata; }ptmpnode = ptmpnode->pnext;}return 0;
}3、尾插法实现
/*尾插法:插入一个节点*/
int insert_tail_linklist(linknode *phead,datatype tmpdata)
{linknode *ptmpnode = NULL;linknode *ptail = phead;ptmpnode = malloc(sizeof(linknode));if(NULL == ptmpnode){perror("fall to malloc");return -1;}//遍历方法2:找到链表最后一个节点while(ptail->pnext != NULL){ptail = ptail->pnext;}//将尾节点的pnext指向当前节点ptail->pnext = ptmpnode;//更新数据和下一个节点地址ptmpnode->data = tmpdata;ptmpnode->pnext = NULL;return 0;}