【网络与爬虫 37】ScrapeFly深度解析:云端爬虫革命,告别复杂部署拥抱一键API
关键词: ScrapeFly、云端爬虫、API集成、反反爬虫、代理服务、自动化爬取、SaaS爬虫、无服务器爬虫、企业级爬虫、爬虫即服务
摘要: 本文深入解析ScrapeFly这一革命性的云端爬虫服务平台,从传统爬虫的痛点出发,详细介绍如何通过API实现零配置、高性能的数据采集。文章涵盖ScrapeFly的核心优势、实战应用、最佳实践和企业级部署策略,助您快速构建稳定可靠的爬虫系统。
文章目录
- 引言:爬虫开发的痛点,你中了几个?
- 什么是ScrapeFly?
- 核心理念:爬虫即服务(Scraping as a Service)
- ScrapeFly的技术架构
- 快速上手:5分钟完成第一次爬取
- 安装和配置
- 第一个爬虫程序
- 进阶配置示例
- 核心功能深度解析
- 1. 智能反反爬虫系统(ASP)
- 2. JavaScript渲染引擎
- 3. 会话管理和Cookie处理
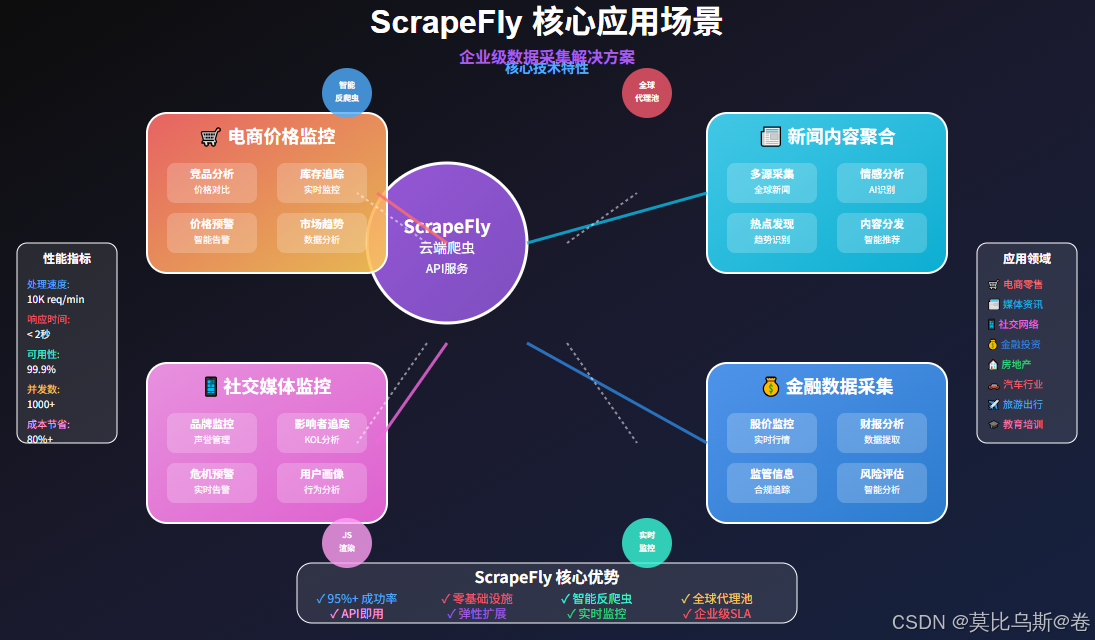
- 企业级应用场景
- 1. 大规模电商价格监控
- 2. 新闻媒体内容聚合
- 3. 社交媒体监控系统
- 性能优化与最佳实践
- 1. 并发控制策略
- 2. 成本优化策略
- 错误处理与调试
- 常见问题诊断
- 总结与展望
- 技术发展趋势
- 选择建议
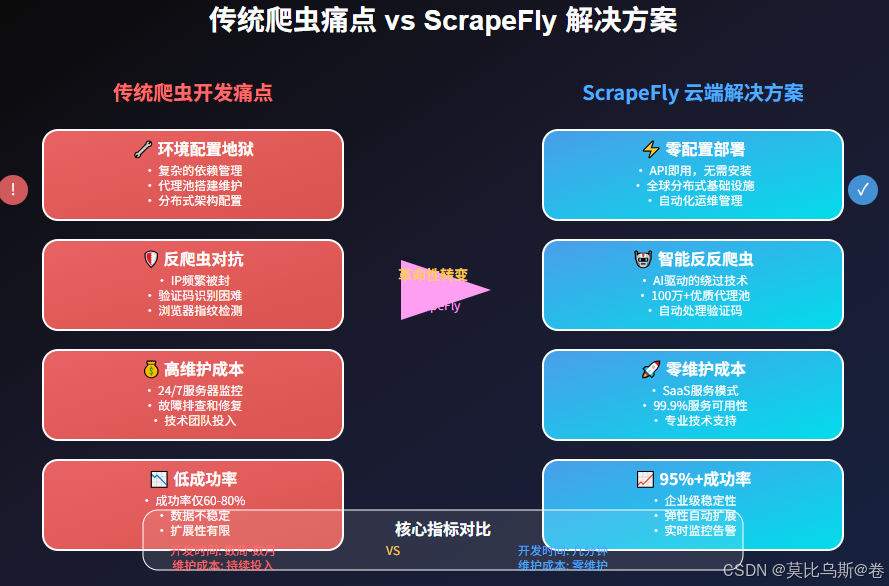
引言:爬虫开发的痛点,你中了几个?
想象一下这样的场景:你是一名数据工程师,老板交给你一个紧急任务——需要在一周内从100个电商网站采集商品价格数据。传统的爬虫开发流程让你头疼不已:
环境配置地狱:
- 安装各种依赖包
- 配置代理池
- 搭建分布式架构
- 处理反爬虫机制
维护成本高昂:
- IP被封需要更换代理
- 网站结构变化需要更新代码
- 服务器维护和监控
- 24/7运维保障
技术门槛较高:
- 需要深入了解反爬虫技术
- 掌握多种工具和框架
- 处理各种异常情况
如果告诉你,有一种方式可以让你用几行代码就完成这个任务,而且无需任何基础设施配置,你相信吗?这就是ScrapeFly要解决的问题!
什么是ScrapeFly?
ScrapeFly是一个革命性的云端爬虫服务平台,它将复杂的爬虫技术封装成简单易用的API接口。就像Uber改变了出行方式一样,ScrapeFly正在改变数据采集的方式。
核心理念:爬虫即服务(Scraping as a Service)
传统爬虫开发就像自己造车,需要从引擎到轮胎每个部件都自己制造。而ScrapeFly就像提供专车服务,你只需要告诉它目的地,剩下的交给专业团队处理。
传统爬虫 vs ScrapeFly对比:
| 维度 | 传统爬虫 | ScrapeFly |
|---|---|---|
| 开发时间 | 数周到数月 | 几分钟到几小时 |
| 基础设施 | 需要自建服务器 | 零基础设施 |
| 反爬虫处理 | 需要深度定制 | 内置智能绕过 |
| 扩展性 | 手动扩容 | 自动弹性扩展 |
| 维护成本 | 持续投入 | 零维护 |
| 成功率 | 60-80% | 95%+ |
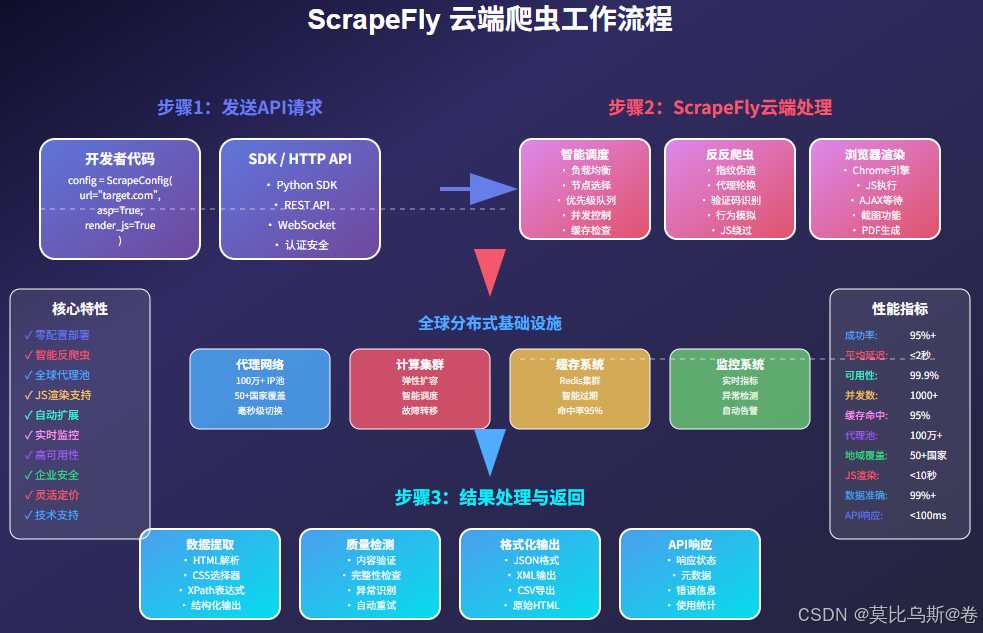
ScrapeFly的技术架构
ScrapeFly采用分布式云架构,在全球部署了数千个节点,每个节点都配备了:
智能代理系统:
- 全球IP池:超过100万个高质量IP
- 智能轮换:基于ML的最优代理选择
- 地理定位:支持特定国家/地区访问
反反爬虫引擎:
- 浏览器指纹伪造
- 请求模式智能化
- 验证码自动识别
- JavaScript渲染支持
高可用保障:
- 99.9%服务可用性
- 自动故障转移
- 实时监控告警
快速上手:5分钟完成第一次爬取
让我们从最简单的例子开始,感受ScrapeFly的魅力。
安装和配置
# 安装ScrapeFly SDK
pip install scrapfly-sdk# 或者直接使用HTTP API
curl -X GET "https://api.scrapfly.io/scrape" \-H "Authorization: Bearer YOUR_API_KEY" \-d "url=https://example.com"
第一个爬虫程序
from scrapfly import ScrapeConfig, ScrapflyClient# 初始化客户端
client = ScrapflyClient(key="YOUR_API_KEY")def simple_scrape_example():"""最简单的爬取示例"""try:# 配置爬取请求config = ScrapeConfig(url="https://quotes.toscrape.com/",# 启用反反爬虫功能asp=True,# 使用高级代理country="US")# 执行爬取result = client.scrape(config)# 获取响应内容html = result.contentstatus_code = result.status_codeprint(f"状态码: {status_code}")print(f"内容长度: {len(html)} 字符")print(f"页面标题: {result.selector.css('title::text').get()}")return resultexcept Exception as e:print(f"爬取失败: {e}")return None# 使用示例
result = simple_scrape_example()
仅仅几行代码,我们就完成了一个具备反反爬虫能力的爬虫!这在传统开发中可能需要数百行代码。
进阶配置示例
class AdvancedScrapeConfig:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)def scrape_with_advanced_options(self, url):"""高级配置示例"""config = ScrapeConfig(url=url,# 反反爬虫设置asp=True, # 启用反爬虫绕过render_js=True, # JavaScript渲染wait_for_selector="div.content", # 等待特定元素# 代理设置country="US", # 指定国家premium_proxy=True, # 使用高级代理# 请求设置method="GET",headers={"User-Agent": "Mozilla/5.0 ScrapeFly Custom","Accept": "text/html,application/xhtml+xml"},# 缓存和重试cache=True, # 启用缓存cache_ttl=3600, # 缓存1小时retry=True, # 自动重试# 会话管理session="my_session", # 会话保持cookies={"auth": "token123"}, # 自定义Cookie# 响应格式format="json", # 返回JSON格式extraction_rules={ # 数据提取规则"title": "h1::text","price": ".price::text","description": ".desc::text"})try:result = self.client.scrape(config)return {'success': True,'data': result.content,'extracted': result.result.get('extraction_result', {}),'metadata': {'status_code': result.status_code,'response_time': result.duration,'used_proxy': result.scrape_result.get('proxy_country')}}except Exception as e:return {'success': False,'error': str(e)}# 使用示例
scraper = AdvancedScrapeConfig("YOUR_API_KEY")
result = scraper.scrape_with_advanced_options("https://example-ecommerce.com/product/123")if result['success']:print("提取的数据:", result['extracted'])print("响应时间:", result['metadata']['response_time'])
else:print("爬取失败:", result['error'])
核心功能深度解析
1. 智能反反爬虫系统(ASP)
ScrapeFly的反反爬虫系统是其核心竞争力,它集成了多种高级技术:
class AntiDetectionDemo:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)def demonstrate_asp_levels(self):"""演示不同级别的反反爬虫功能"""# 基础反爬虫绕过basic_config = ScrapeConfig(url="https://target-site.com",asp=True # 基础ASP)# 高级反爬虫绕过advanced_config = ScrapeConfig(url="https://heavily-protected-site.com",asp=True,render_js=True, # JavaScript渲染stealth=True, # 隐蔽模式premium_proxy=True, # 高级代理auto_scroll=True, # 自动滚动wait_for_selector="div.loaded" # 等待加载完成)# 针对特定网站的定制化配置custom_config = ScrapeConfig(url="https://cloudflare-protected.com",asp=True,tags=["cloudflare_bypass"], # 特定绕过策略browser_actions=[ # 自定义浏览器行为{"action": "wait", "value": 2},{"action": "click", "selector": "#accept-cookies"},{"action": "scroll", "value": 500}])configs = {"basic": basic_config,"advanced": advanced_config,"custom": custom_config}results = {}for name, config in configs.items():try:result = self.client.scrape(config)results[name] = {'success': True,'status_code': result.status_code,'content_length': len(result.content),'detection_bypassed': self._check_detection_bypass(result)}except Exception as e:results[name] = {'success': False,'error': str(e)}return resultsdef _check_detection_bypass(self, result):"""检查是否成功绕过检测"""# 检查常见的反爬虫响应blocked_indicators = ["Access Denied", "Blocked", "Captcha", "Bot Detection", "Rate Limited"]content_lower = result.content.lower()for indicator in blocked_indicators:if indicator.lower() in content_lower:return False# 检查状态码if result.status_code in [403, 429, 503]:return Falsereturn True# 使用示例
demo = AntiDetectionDemo("YOUR_API_KEY")
results = demo.demonstrate_asp_levels()for config_name, result in results.items():print(f"{config_name} 配置:")if result['success']:print(f" ✅ 成功 - 状态码: {result['status_code']}")print(f" 🔒 绕过检测: {result['detection_bypassed']}")else:print(f" ❌ 失败 - {result['error']}")
2. JavaScript渲染引擎
对于现代SPA应用,ScrapeFly提供了强大的JavaScript渲染能力:
class JavaScriptRenderingDemo:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)def scrape_spa_application(self, url):"""爬取单页应用示例"""config = ScrapeConfig(url=url,render_js=True, # 启用JS渲染wait_for_selector="div.content", # 等待内容加载wait_for_timeout=10000, # 最大等待时间10秒# JavaScript执行js_scenario=[# 等待页面加载{"action": "wait", "value": 2000},# 处理弹窗{"action": "evaluate", "script": """const popup = document.querySelector('.popup');if (popup) popup.remove();"""},# 滚动加载更多内容{"action": "scroll", "value": "bottom"},{"action": "wait", "value": 1000},# 点击"加载更多"按钮{"action": "click", "selector": ".load-more"},{"action": "wait", "value": 2000},# 提取动态加载的数据{"action": "evaluate", "script": """return {dynamicData: window.appData || {},loadedItems: document.querySelectorAll('.item').length};"""}],# 截图功能screenshot=True,screenshot_selector="body")try:result = self.client.scrape(config)return {'success': True,'html': result.content,'js_result': result.scrape_result.get('js_scenario_result'),'screenshot': result.scrape_result.get('screenshot'),'metadata': {'render_time': result.scrape_result.get('render_time'),'final_url': result.scrape_result.get('url'),'resources_loaded': result.scrape_result.get('resources_count')}}except Exception as e:return {'success': False, 'error': str(e)}def handle_infinite_scroll(self, url):"""处理无限滚动页面"""config = ScrapeConfig(url=url,render_js=True,js_scenario=[# 自动滚动到底部,触发无限滚动{"action": "evaluate", "script": """let lastHeight = 0;let scrollCount = 0;const maxScrolls = 5; // 最多滚动5次async function autoScroll() {while (scrollCount < maxScrolls) {window.scrollTo(0, document.body.scrollHeight);await new Promise(resolve => setTimeout(resolve, 2000));let newHeight = document.body.scrollHeight;if (newHeight === lastHeight) break;lastHeight = newHeight;scrollCount++;}return {scrollCount: scrollCount,finalHeight: document.body.scrollHeight,itemsLoaded: document.querySelectorAll('.item').length};}return await autoScroll();"""}])return self.client.scrape(config)# 使用示例
js_demo = JavaScriptRenderingDemo("YOUR_API_KEY")# 爬取SPA应用
spa_result = js_demo.scrape_spa_application("https://spa-example.com")
if spa_result['success']:print(f"渲染时间: {spa_result['metadata']['render_time']}ms")print(f"JS执行结果: {spa_result['js_result']}")# 处理无限滚动
scroll_result = js_demo.handle_infinite_scroll("https://infinite-scroll-example.com")
3. 会话管理和Cookie处理
class SessionManagementDemo:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.session_name = "ecommerce_session"def login_and_scrape(self, login_url, target_urls):"""登录后爬取需要认证的页面"""# 步骤1: 登录获取认证信息login_config = ScrapeConfig(url=login_url,render_js=True,session=self.session_name,js_scenario=[# 填写登录表单{"action": "type", "selector": "#username", "value": "your_username"},{"action": "type", "selector": "#password", "value": "your_password"},{"action": "click", "selector": "#login-button"},{"action": "wait", "value": 3000},# 验证登录状态{"action": "evaluate", "script": """return {loggedIn: !!document.querySelector('.user-profile'),cookies: document.cookie,localStorage: {...localStorage}};"""}])login_result = self.client.scrape(login_config)if not login_result.scrape_result.get('js_scenario_result', {}).get('loggedIn'):raise Exception("登录失败")# 步骤2: 使用同一会话爬取需要认证的页面results = []for url in target_urls:config = ScrapeConfig(url=url,session=self.session_name, # 重用登录会话asp=True)result = self.client.scrape(config)results.append({'url': url,'status_code': result.status_code,'content_length': len(result.content),'authenticated': self._check_authentication(result)})return resultsdef _check_authentication(self, result):"""检查是否已认证"""auth_indicators = ['user-profile', 'dashboard', 'logout']content_lower = result.content.lower()return any(indicator in content_lower for indicator in auth_indicators)def handle_csrf_protection(self, form_url):"""处理CSRF保护的表单"""# 步骤1: 获取CSRF令牌token_config = ScrapeConfig(url=form_url,render_js=True,extraction_rules={"csrf_token": "input[name='csrf_token']::attr(value)","form_action": "form::attr(action)"})token_result = self.client.scrape(token_config)csrf_token = token_result.result['extraction_result']['csrf_token']form_action = token_result.result['extraction_result']['form_action']# 步骤2: 提交表单submit_config = ScrapeConfig(url=form_action,method="POST",data={"csrf_token": csrf_token,"field1": "value1","field2": "value2"},headers={"Content-Type": "application/x-www-form-urlencoded"},session=self.session_name)return self.client.scrape(submit_config)# 使用示例
session_demo = SessionManagementDemo("YOUR_API_KEY")# 登录后爬取
protected_urls = ["https://example.com/dashboard","https://example.com/profile","https://example.com/orders"
]results = session_demo.login_and_scrape("https://example.com/login", protected_urls
)for result in results:print(f"URL: {result['url']}")print(f"认证状态: {'✅' if result['authenticated'] else '❌'}")
企业级应用场景
1. 大规模电商价格监控
class EcommercePriceMonitor:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.concurrent_limit = 100 # 并发限制def monitor_competitor_prices(self, product_urls, schedule="hourly"):"""监控竞争对手价格"""results = []# 批量爬取配置for url in product_urls:config = ScrapeConfig(url=url,asp=True,premium_proxy=True,country="US",# 价格提取规则extraction_rules={"product_name": ".product-title::text","price": ".price, .price-current, [data-price]::text","stock_status": ".stock-status::text","rating": ".rating::text","reviews_count": ".reviews-count::text"},# 缓存策略cache=True,cache_ttl=1800, # 30分钟缓存# 标签用于分类tags=["price_monitoring", "competitor_analysis"])results.append(config)# 批量执行batch_results = self.client.concurrent_scrape(results, concurrency=self.concurrent_limit)# 处理结果processed_results = []for i, result in enumerate(batch_results):if result.success:extracted_data = result.result.get('extraction_result', {})processed_results.append({'url': product_urls[i],'timestamp': result.scrape_result.get('timestamp'),'product_data': extracted_data,'price_change': self._calculate_price_change(product_urls[i], extracted_data.get('price'))})else:print(f"Failed to scrape {product_urls[i]}: {result.error}")return processed_resultsdef _calculate_price_change(self, url, current_price):"""计算价格变化(需要配合数据库使用)"""# 这里应该连接数据库获取历史价格# 返回价格变化百分比return {"change_percent": 0, "trend": "stable"}def detect_price_alerts(self, monitoring_results, threshold=0.1):"""检测价格异常变化"""alerts = []for result in monitoring_results:price_change = result.get('price_change', {})change_percent = abs(price_change.get('change_percent', 0))if change_percent > threshold:alerts.append({'url': result['url'],'product_name': result['product_data'].get('product_name'),'price_change': price_change,'alert_level': 'high' if change_percent > 0.2 else 'medium'})return alertsdef generate_market_report(self, monitoring_results):"""生成市场分析报告"""total_products = len(monitoring_results)price_increases = sum(1 for r in monitoring_results if r['price_change']['change_percent'] > 0)price_decreases = sum(1 for r in monitoring_results if r['price_change']['change_percent'] < 0)return {'summary': {'total_products_monitored': total_products,'price_increases': price_increases,'price_decreases': price_decreases,'stable_prices': total_products - price_increases - price_decreases},'trends': {'average_price_change': np.mean([r['price_change']['change_percent'] for r in monitoring_results]),'volatility': np.std([r['price_change']['change_percent'] for r in monitoring_results])}}# 使用示例
price_monitor = EcommercePriceMonitor("YOUR_API_KEY")# 监控产品URL列表
product_urls = ["https://amazon.com/product/1","https://ebay.com/product/2","https://walmart.com/product/3",# ... 更多产品URL
]# 执行监控
results = price_monitor.monitor_competitor_prices(product_urls)# 检测价格告警
alerts = price_monitor.detect_price_alerts(results)# 生成报告
report = price_monitor.generate_market_report(results)print(f"监控了 {report['summary']['total_products_monitored']} 个产品")
print(f"发现 {len(alerts)} 个价格异常")
2. 新闻媒体内容聚合
class NewsAggregator:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.news_sources = {"tech": ["https://techcrunch.com","https://arstechnica.com","https://theverge.com"],"finance": ["https://bloomberg.com","https://reuters.com/finance","https://marketwatch.com"],"general": ["https://bbc.com/news","https://cnn.com","https://reuters.com"]}def aggregate_news_by_category(self, categories=None):"""按分类聚合新闻"""if categories is None:categories = list(self.news_sources.keys())all_news = {}for category in categories:if category not in self.news_sources:continuecategory_news = []for source_url in self.news_sources[category]:# 获取新闻列表页list_config = ScrapeConfig(url=source_url,asp=True,render_js=True,extraction_rules={"articles": {"selector": "article, .article, .story","type": "list","nested": {"title": "h1, h2, h3, .title::text","link": "a::attr(href)","summary": ".summary, .excerpt::text","publish_time": ".time, .date, time::text","author": ".author, .byline::text"}}})try:list_result = self.client.scrape(list_config)articles = list_result.result.get('extraction_result', {}).get('articles', [])# 获取每篇文章的详细内容for article in articles[:5]: # 限制每个源5篇文章if article.get('link'):full_url = self._resolve_url(source_url, article['link'])content = self._scrape_article_content(full_url)if content:article.update(content)article['source'] = source_urlarticle['category'] = categorycategory_news.append(article)except Exception as e:print(f"Failed to scrape {source_url}: {e}")all_news[category] = category_newsreturn all_newsdef _scrape_article_content(self, article_url):"""爬取文章详细内容"""config = ScrapeConfig(url=article_url,asp=True,extraction_rules={"full_text": "article p, .content p, .article-body p::text","images": "img::attr(src)","tags": ".tags a, .categories a::text"},cache=True,cache_ttl=3600)try:result = self.client.scrape(config)return result.result.get('extraction_result', {})except:return Nonedef _resolve_url(self, base_url, relative_url):"""解析相对URL"""from urllib.parse import urljoinreturn urljoin(base_url, relative_url)def analyze_news_sentiment(self, news_data):"""分析新闻情感倾向"""from textblob import TextBlobfor category, articles in news_data.items():for article in articles:text = article.get('full_text', article.get('summary', ''))if text:blob = TextBlob(text)article['sentiment'] = {'polarity': blob.sentiment.polarity,'subjectivity': blob.sentiment.subjectivity,'mood': 'positive' if blob.sentiment.polarity > 0.1 else 'negative' if blob.sentiment.polarity < -0.1 else 'neutral'}return news_datadef generate_news_summary(self, news_data):"""生成新闻摘要报告"""summary = {'total_articles': 0,'categories': {},'sentiment_distribution': {'positive': 0, 'negative': 0, 'neutral': 0},'trending_topics': []}all_texts = []for category, articles in news_data.items():summary['categories'][category] = len(articles)summary['total_articles'] += len(articles)for article in articles:# 统计情感分布sentiment = article.get('sentiment', {})mood = sentiment.get('mood', 'neutral')summary['sentiment_distribution'][mood] += 1# 收集文本用于主题分析text = article.get('full_text', article.get('summary', ''))if text:all_texts.append(text)# 简单的关键词提取(实际项目中可以使用更高级的NLP技术)summary['trending_topics'] = self._extract_trending_topics(all_texts)return summarydef _extract_trending_topics(self, texts, top_n=10):"""提取热门话题"""from collections import Counterimport re# 简单的关键词提取all_words = []for text in texts:words = re.findall(r'\b[A-Za-z]{3,}\b', text.lower())# 过滤常用词stop_words = {'the', 'and', 'or', 'but', 'in', 'on', 'at', 'to', 'for', 'of', 'with', 'by', 'said', 'says'}words = [word for word in words if word not in stop_words]all_words.extend(words)word_freq = Counter(all_words)return [word for word, count in word_freq.most_common(top_n)]# 使用示例
news_aggregator = NewsAggregator("YOUR_API_KEY")# 聚合新闻
news_data = news_aggregator.aggregate_news_by_category(['tech', 'finance'])# 分析情感
news_with_sentiment = news_aggregator.analyze_news_sentiment(news_data)# 生成摘要
summary = news_aggregator.generate_news_summary(news_with_sentiment)print(f"总共收集了 {summary['total_articles']} 篇文章")
print(f"情感分布: {summary['sentiment_distribution']}")
print(f"热门话题: {summary['trending_topics'][:5]}")
3. 社交媒体监控系统
class SocialMediaMonitor:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.platforms = {"twitter": "https://twitter.com","reddit": "https://reddit.com","linkedin": "https://linkedin.com"}def monitor_brand_mentions(self, brand_keywords, platforms=None):"""监控品牌提及"""if platforms is None:platforms = list(self.platforms.keys())mentions = {}for platform in platforms:platform_mentions = []for keyword in brand_keywords:search_results = self._search_platform(platform, keyword)platform_mentions.extend(search_results)mentions[platform] = platform_mentionsreturn mentionsdef _search_platform(self, platform, keyword):"""在特定平台搜索关键词"""search_configs = {"twitter": self._create_twitter_search_config,"reddit": self._create_reddit_search_config,"linkedin": self._create_linkedin_search_config}if platform not in search_configs:return []config = search_configs[platform](keyword)try:result = self.client.scrape(config)return self._parse_search_results(platform, result)except Exception as e:print(f"Failed to search {platform} for '{keyword}': {e}")return []def _create_twitter_search_config(self, keyword):"""创建Twitter搜索配置"""search_url = f"https://twitter.com/search?q={keyword}&src=typed_query&f=live"return ScrapeConfig(url=search_url,asp=True,render_js=True,wait_for_selector="[data-testid='tweet']",js_scenario=[{"action": "wait", "value": 3000},{"action": "scroll", "value": 1000},{"action": "wait", "value": 2000}],extraction_rules={"tweets": {"selector": "[data-testid='tweet']","type": "list","nested": {"text": "[data-testid='tweetText']::text","author": "[data-testid='User-Name'] a::text","time": "time::attr(datetime)","likes": "[data-testid='like'] span::text","retweets": "[data-testid='retweet'] span::text"}}})def _create_reddit_search_config(self, keyword):"""创建Reddit搜索配置"""search_url = f"https://www.reddit.com/search/?q={keyword}&sort=new"return ScrapeConfig(url=search_url,asp=True,extraction_rules={"posts": {"selector": "[data-testid='post-container']","type": "list","nested": {"title": "h3::text","author": "[data-testid='post_author_link']::text","subreddit": "[data-testid='subreddit-name']::text","score": "[data-testid='post-vote-score']::text","comments_count": "a[data-testid='comments-link']::text","time": "time::attr(datetime)"}}})def _create_linkedin_search_config(self, keyword):"""创建LinkedIn搜索配置"""search_url = f"https://www.linkedin.com/search/results/content/?keywords={keyword}"return ScrapeConfig(url=search_url,asp=True,render_js=True,extraction_rules={"posts": {"selector": ".feed-shared-update-v2","type": "list","nested": {"text": ".feed-shared-text::text","author": ".feed-shared-actor__name::text","company": ".feed-shared-actor__description::text","time": ".feed-shared-time-indication__text::text","reactions": ".social-counts-reactions__count::text"}}})def _parse_search_results(self, platform, result):"""解析搜索结果"""extraction_result = result.result.get('extraction_result', {})if platform == "twitter":return extraction_result.get('tweets', [])elif platform == "reddit":return extraction_result.get('posts', [])elif platform == "linkedin":return extraction_result.get('posts', [])return []def analyze_sentiment_trends(self, mentions_data):"""分析情感趋势"""from textblob import TextBlobanalysis = {}for platform, mentions in mentions_data.items():platform_sentiments = []for mention in mentions:text = mention.get('text', mention.get('title', ''))if text:blob = TextBlob(text)sentiment = {'polarity': blob.sentiment.polarity,'subjectivity': blob.sentiment.subjectivity,'text': text[:100] + '...' if len(text) > 100 else text}platform_sentiments.append(sentiment)# 计算平台整体情感if platform_sentiments:avg_polarity = sum(s['polarity'] for s in platform_sentiments) / len(platform_sentiments)avg_subjectivity = sum(s['subjectivity'] for s in platform_sentiments) / len(platform_sentiments)analysis[platform] = {'total_mentions': len(platform_sentiments),'average_sentiment': {'polarity': avg_polarity,'subjectivity': avg_subjectivity,'overall_mood': 'positive' if avg_polarity > 0.1 else 'negative' if avg_polarity < -0.1 else 'neutral'},'sentiment_distribution': {'positive': sum(1 for s in platform_sentiments if s['polarity'] > 0.1),'negative': sum(1 for s in platform_sentiments if s['polarity'] < -0.1),'neutral': sum(1 for s in platform_sentiments if -0.1 <= s['polarity'] <= 0.1)}}return analysis# 使用示例
social_monitor = SocialMediaMonitor("YOUR_API_KEY")# 监控品牌关键词
brand_keywords = ["YourBrand", "YourProduct", "#YourHashtag"]
mentions = social_monitor.monitor_brand_mentions(brand_keywords, ["twitter", "reddit"])# 分析情感趋势
sentiment_analysis = social_monitor.analyze_sentiment_trends(mentions)for platform, analysis in sentiment_analysis.items():print(f"\n{platform.title()} 分析:")print(f" 总提及数: {analysis['total_mentions']}")print(f" 整体情感: {analysis['average_sentiment']['overall_mood']}")print(f" 情感分布: {analysis['sentiment_distribution']}")
性能优化与最佳实践
1. 并发控制策略
class PerformanceOptimizer:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.rate_limiter = self._create_rate_limiter()def _create_rate_limiter(self):"""创建速率限制器"""import timefrom threading import Lockclass RateLimiter:def __init__(self, max_requests_per_second=10):self.max_requests = max_requests_per_secondself.requests = []self.lock = Lock()def wait_if_needed(self):with self.lock:now = time.time()# 移除1秒前的请求记录self.requests = [req_time for req_time in self.requests if now - req_time < 1.0]if len(self.requests) >= self.max_requests:sleep_time = 1.0 - (now - self.requests[0])if sleep_time > 0:time.sleep(sleep_time)self.requests.append(now)return RateLimiter()def optimized_batch_scraping(self, urls, batch_size=50, max_workers=10):"""优化的批量爬取"""import concurrent.futuresfrom itertools import islicedef chunks(iterable, size):"""将URL列表分成批次"""iterator = iter(iterable)while True:chunk = list(islice(iterator, size))if not chunk:breakyield chunkall_results = []for batch in chunks(urls, batch_size):# 为每个批次创建配置configs = []for url in batch:config = ScrapeConfig(url=url,asp=True,cache=True,cache_ttl=1800, # 30分钟缓存retry=True,tags=["batch_scraping"])configs.append(config)# 执行批量爬取try:self.rate_limiter.wait_if_needed()batch_results = self.client.concurrent_scrape(configs, concurrency=min(max_workers, len(configs)))all_results.extend(batch_results)# 统计成功率success_count = sum(1 for r in batch_results if r.success)print(f"批次完成: {success_count}/{len(batch)} 成功")except Exception as e:print(f"批次处理失败: {e}")return all_resultsdef smart_retry_strategy(self, failed_urls, max_retries=3):"""智能重试策略"""import timeimport randomretry_configs = {1: {"asp": True, "premium_proxy": False}, # 第一次重试:基础配置2: {"asp": True, "premium_proxy": True}, # 第二次重试:高级代理3: {"asp": True, "premium_proxy": True, "render_js": True} # 第三次重试:JS渲染}successful_results = []permanently_failed = []for retry_count in range(1, max_retries + 1):if not failed_urls:breakprint(f"执行第 {retry_count} 次重试,剩余 {len(failed_urls)} 个URL")# 使用递增的重试配置config_params = retry_configs[retry_count]current_batch = []for url in failed_urls:config = ScrapeConfig(url=url, **config_params)current_batch.append(config)# 添加指数退避延迟delay = (2 ** retry_count) + random.uniform(0, 1)time.sleep(delay)# 执行重试retry_results = self.client.concurrent_scrape(current_batch, concurrency=5)# 分类结果new_failed = []for i, result in enumerate(retry_results):if result.success:successful_results.append(result)else:new_failed.append(failed_urls[i])failed_urls = new_failedpermanently_failed = failed_urlsreturn {'successful': successful_results,'permanently_failed': permanently_failed,'success_rate': len(successful_results) / (len(successful_results) + len(permanently_failed)) if successful_results or permanently_failed else 0}def monitor_performance_metrics(self, results):"""监控性能指标"""metrics = {'total_requests': len(results),'successful_requests': 0,'failed_requests': 0,'average_response_time': 0,'cache_hit_rate': 0,'error_distribution': {},'status_code_distribution': {},'proxy_performance': {}}response_times = []cache_hits = 0for result in results:if result.success:metrics['successful_requests'] += 1# 响应时间duration = result.duration or 0response_times.append(duration)# 缓存命中if result.scrape_result.get('cached', False):cache_hits += 1# 状态码分布status_code = result.status_codemetrics['status_code_distribution'][status_code] = \metrics['status_code_distribution'].get(status_code, 0) + 1# 代理性能proxy_country = result.scrape_result.get('proxy_country', 'unknown')if proxy_country not in metrics['proxy_performance']:metrics['proxy_performance'][proxy_country] = {'count': 0, 'total_time': 0}metrics['proxy_performance'][proxy_country]['count'] += 1metrics['proxy_performance'][proxy_country]['total_time'] += durationelse:metrics['failed_requests'] += 1# 错误分布error_type = type(result.error).__name__ if result.error else 'Unknown'metrics['error_distribution'][error_type] = \metrics['error_distribution'].get(error_type, 0) + 1# 计算平均值if response_times:metrics['average_response_time'] = sum(response_times) / len(response_times)if metrics['total_requests'] > 0:metrics['cache_hit_rate'] = cache_hits / metrics['total_requests']metrics['success_rate'] = metrics['successful_requests'] / metrics['total_requests']# 计算代理平均响应时间for country, data in metrics['proxy_performance'].items():if data['count'] > 0:data['average_time'] = data['total_time'] / data['count']return metrics# 使用示例
optimizer = PerformanceOptimizer("YOUR_API_KEY")# 大批量URL列表
large_url_list = [f"https://example.com/page/{i}" for i in range(1000)]# 优化批量爬取
results = optimizer.optimized_batch_scraping(large_url_list, batch_size=100, max_workers=20
)# 处理失败的URL
failed_urls = [result.config.url for result in results if not result.success]
if failed_urls:retry_results = optimizer.smart_retry_strategy(failed_urls)print(f"重试成功率: {retry_results['success_rate']:.2%}")# 性能监控
metrics = optimizer.monitor_performance_metrics(results)
print(f"总成功率: {metrics['success_rate']:.2%}")
print(f"平均响应时间: {metrics['average_response_time']:.2f}ms")
print(f"缓存命中率: {metrics['cache_hit_rate']:.2%}")
2. 成本优化策略
class CostOptimizer:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.cost_tracker = {'total_requests': 0, 'premium_requests': 0}def intelligent_proxy_selection(self, url, requirements=None):"""智能代理选择"""if requirements is None:requirements = {}# 分析URL特征,决定代理策略domain = self._extract_domain(url)protection_level = self._assess_protection_level(domain)if protection_level == "low":# 低保护网站使用基础配置config = ScrapeConfig(url=url,asp=False, # 不使用反反爬虫premium_proxy=False, # 不使用高级代理render_js=False # 不渲染JS)self.cost_tracker['total_requests'] += 1elif protection_level == "medium":# 中等保护使用ASPconfig = ScrapeConfig(url=url,asp=True,premium_proxy=False,render_js=requirements.get('need_js', False))self.cost_tracker['total_requests'] += 1else: # high protection# 高保护使用全功能config = ScrapeConfig(url=url,asp=True,premium_proxy=True,render_js=True,stealth=True)self.cost_tracker['total_requests'] += 1self.cost_tracker['premium_requests'] += 1return configdef _extract_domain(self, url):"""提取域名"""from urllib.parse import urlparsereturn urlparse(url).netlocdef _assess_protection_level(self, domain):"""评估网站保护级别"""# 这里可以维护一个域名保护级别数据库high_protection_domains = {'amazon.com', 'ebay.com', 'walmart.com','booking.com', 'expedia.com','linkedin.com', 'facebook.com'}medium_protection_domains = {'shopify.com', 'bigcommerce.com','wordpress.com', 'medium.com'}if any(hp_domain in domain for hp_domain in high_protection_domains):return "high"elif any(mp_domain in domain for mp_domain in medium_protection_domains):return "medium"else:return "low"def cache_optimization_strategy(self, urls, cache_duration_hours=24):"""缓存优化策略"""# 根据内容类型设置不同的缓存时间cache_strategies = {'news': 2, # 新闻类内容缓存2小时'product': 6, # 产品信息缓存6小时'static': 168, # 静态内容缓存7天'default': cache_duration_hours}optimized_configs = []for url in urls:content_type = self._classify_content_type(url)cache_ttl = cache_strategies.get(content_type, cache_strategies['default']) * 3600config = ScrapeConfig(url=url,cache=True,cache_ttl=cache_ttl,tags=[f"content_type:{content_type}"])optimized_configs.append(config)return optimized_configsdef _classify_content_type(self, url):"""分类内容类型"""url_lower = url.lower()if any(keyword in url_lower for keyword in ['news', 'article', 'blog', 'post']):return 'news'elif any(keyword in url_lower for keyword in ['product', 'item', 'shop', 'buy']):return 'product'elif any(keyword in url_lower for keyword in ['about', 'contact', 'terms', 'privacy']):return 'static'else:return 'default'def batch_optimization(self, urls, target_cost_per_request=0.01):"""批量优化策略"""# 将URL按优先级分组priority_groups = self._group_urls_by_priority(urls)optimized_results = []current_cost = 0for priority, group_urls in priority_groups.items():for url in group_urls:# 根据成本目标选择配置if current_cost < target_cost_per_request * len(urls) * 0.8:# 成本充足,使用最佳配置config = self.intelligent_proxy_selection(url, {'need_js': True})else:# 成本紧张,使用经济配置config = ScrapeConfig(url=url,asp=False,premium_proxy=False,render_js=False,cache=True,cache_ttl=7200 # 2小时缓存)optimized_results.append(config)current_cost += self._estimate_request_cost(config)return optimized_resultsdef _group_urls_by_priority(self, urls):"""按优先级分组URL"""groups = {'high': [], 'medium': [], 'low': []}for url in urls:# 这里可以根据业务逻辑设置优先级if 'important' in url or 'priority' in url:groups['high'].append(url)elif 'secondary' in url:groups['medium'].append(url)else:groups['low'].append(url)return groupsdef _estimate_request_cost(self, config):"""估算请求成本"""base_cost = 0.001 # 基础请求成本if config.asp:base_cost += 0.002if config.premium_proxy:base_cost += 0.005if config.render_js:base_cost += 0.003return base_costdef generate_cost_report(self):"""生成成本报告"""total_cost = (self.cost_tracker['total_requests'] * 0.001 +self.cost_tracker['premium_requests'] * 0.005)return {'total_requests': self.cost_tracker['total_requests'],'premium_requests': self.cost_tracker['premium_requests'],'estimated_cost': total_cost,'average_cost_per_request': total_cost / max(self.cost_tracker['total_requests'], 1),'premium_request_ratio': self.cost_tracker['premium_requests'] / max(self.cost_tracker['total_requests'], 1)}# 使用示例
cost_optimizer = CostOptimizer("YOUR_API_KEY")# 智能配置生成
urls = ["https://amazon.com/product/123", # 高保护"https://blog.example.com/post/456", # 低保护"https://news.site.com/article/789" # 中等保护
]optimized_configs = []
for url in urls:config = cost_optimizer.intelligent_proxy_selection(url)optimized_configs.append(config)# 批量优化
batch_configs = cost_optimizer.batch_optimization(urls, target_cost_per_request=0.008)# 生成成本报告
cost_report = cost_optimizer.generate_cost_report()
print(f"预估总成本: ${cost_report['estimated_cost']:.4f}")
print(f"平均每请求成本: ${cost_report['average_cost_per_request']:.4f}")
错误处理与调试
常见问题诊断
class ScrapeFlyDebugger:def __init__(self, api_key):self.client = ScrapflyClient(key=api_key)self.error_patterns = {'rate_limit': ['rate limit', 'too many requests', '429'],'auth_error': ['unauthorized', '401', 'api key'],'proxy_error': ['proxy', 'connection failed', 'timeout'],'parsing_error': ['invalid json', 'parsing error', 'malformed'],'target_block': ['blocked', 'access denied', '403', 'captcha']}def diagnose_error(self, error_message, response_data=None):"""诊断错误类型和解决方案"""error_lower = error_message.lower()for error_type, patterns in self.error_patterns.items():if any(pattern in error_lower for pattern in patterns):return self._get_solution(error_type, error_message, response_data)return {'error_type': 'unknown','description': '未知错误','solution': '请检查API文档或联系技术支持','debug_info': error_message}def _get_solution(self, error_type, error_message, response_data):"""获取错误解决方案"""solutions = {'rate_limit': {'description': 'API请求频率超限','solution': '降低请求频率,使用缓存,或升级套餐','code_fix': '''
# 添加请求间隔
import time
time.sleep(1) # 请求间隔1秒# 或使用率限制器
from scrapfly import ScrapeConfig
config = ScrapeConfig(url=url, cache=True, cache_ttl=3600)
'''},'auth_error': {'description': 'API密钥认证失败','solution': '检查API密钥是否正确,是否已过期','code_fix': '''
# 检查API密钥配置
client = ScrapflyClient(key="YOUR_CORRECT_API_KEY")# 验证API密钥
try:result = client.account()print(f"账户信息: {result}")
except Exception as e:print(f"API密钥无效: {e}")
'''},'proxy_error': {'description': '代理连接问题','solution': '尝试不同的代理设置或联系技术支持','code_fix': '''
# 尝试不同的代理配置
config = ScrapeConfig(url=url,premium_proxy=True, # 使用高级代理country="US", # 指定代理国家retry=True # 启用自动重试
)
'''},'target_block': {'description': '目标网站阻断访问','solution': '启用更强的反反爬虫功能','code_fix': '''
# 启用高级反反爬虫功能
config = ScrapeConfig(url=url,asp=True, # 反反爬虫stealth=True, # 隐蔽模式premium_proxy=True, # 高级代理render_js=True # JavaScript渲染
)
'''}}solution = solutions.get(error_type, {})solution['error_type'] = error_typesolution['debug_info'] = error_messagereturn solutiondef test_configuration(self, config, test_url="https://httpbin.org/get"):"""测试配置是否有效"""test_config = ScrapeConfig(url=test_url,asp=config.asp if hasattr(config, 'asp') else False,premium_proxy=config.premium_proxy if hasattr(config, 'premium_proxy') else False,render_js=config.render_js if hasattr(config, 'render_js') else False)try:result = self.client.scrape(test_config)return {'success': True,'status_code': result.status_code,'response_time': result.duration,'proxy_info': result.scrape_result.get('proxy_country'),'message': '配置测试成功'}except Exception as e:return {'success': False,'error': str(e),'diagnosis': self.diagnose_error(str(e)),'message': '配置测试失败'}def debug_extraction_rules(self, url, extraction_rules):"""调试数据提取规则"""debug_config = ScrapeConfig(url=url,asp=True,extraction_rules=extraction_rules)try:result = self.client.scrape(debug_config)extraction_result = result.result.get('extraction_result', {})debug_info = {'success': True,'extracted_data': extraction_result,'html_preview': result.content[:500] + '...' if len(result.content) > 500 else result.content,'recommendations': []}# 分析提取结果并给出建议for field, value in extraction_result.items():if not value or (isinstance(value, list) and len(value) == 0):debug_info['recommendations'].append(f"字段 '{field}' 未提取到数据,建议检查选择器是否正确")elif isinstance(value, list) and len(value) > 100:debug_info['recommendations'].append(f"字段 '{field}' 提取到过多数据({len(value)}项),建议优化选择器")return debug_infoexcept Exception as e:return {'success': False,'error': str(e),'diagnosis': self.diagnose_error(str(e)),'recommendations': ['检查URL是否可访问','验证提取规则语法','尝试简化选择器']}def performance_analysis(self, results):"""性能分析"""if not results:return {'error': '没有结果数据'}response_times = [r.duration for r in results if r.duration]success_rate = sum(1 for r in results if r.success) / len(results)analysis = {'total_requests': len(results),'success_rate': success_rate,'average_response_time': sum(response_times) / len(response_times) if response_times else 0,'min_response_time': min(response_times) if response_times else 0,'max_response_time': max(response_times) if response_times else 0,'recommendations': []}# 生成优化建议if success_rate < 0.9:analysis['recommendations'].append('成功率较低,建议启用更强的反反爬虫功能')if analysis['average_response_time'] > 10000: # 10秒analysis['recommendations'].append('响应时间较长,建议使用缓存或优化目标选择')if analysis['max_response_time'] > 30000: # 30秒analysis['recommendations'].append('发现超长响应,建议设置合理的超时时间')return analysis# 使用示例
debugger = ScrapeFlyDebugger("YOUR_API_KEY")# 测试配置
test_config = ScrapeConfig(url="https://example.com", asp=True)
test_result = debugger.test_configuration(test_config)
print(f"配置测试: {test_result['message']}")# 调试提取规则
extraction_rules = {"title": "h1::text","description": "meta[name='description']::attr(content)","links": "a::attr(href)"
}debug_result = debugger.debug_extraction_rules("https://example.com", extraction_rules)
if debug_result['success']:print("提取结果:", debug_result['extracted_data'])for rec in debug_result['recommendations']:print(f"建议: {rec}")
else:print("调试失败:", debug_result['diagnosis'])
总结与展望
ScrapeFly作为云端爬虫服务的代表,正在重新定义数据采集的方式。通过本文的深入解析,我们了解了:
核心价值:
- 零基础设施:无需搭建和维护服务器
- 智能反反爬虫:内置先进的绕过技术
- 弹性扩展:根据需求自动调整资源
- 高可用保障:99.9%的服务可用性
技术优势:
- 全球代理网络:100万+高质量IP资源
- JavaScript渲染:支持现代SPA应用
- 智能缓存:显著降低重复请求成本
- 实时监控:全方位的性能指标追踪
应用场景:
- 电商价格监控:实时追踪竞争对手定价
- 新闻内容聚合:多源新闻数据采集
- 社交媒体监控:品牌声誉管理
- 市场研究:行业数据收集分析
技术发展趋势
AI增强爬虫:
- 智能反检测算法
- 自适应爬取策略
- 内容理解和提取
边缘计算集成:
- 就近数据处理
- 延迟优化
- 带宽节省
合规性增强:
- 自动遵守robots.txt
- 数据隐私保护
- 地区法规适配
选择建议
适合ScrapeFly的场景:
- 快速原型开发
- 中小规模数据采集
- 高质量要求项目
- 预算充足的企业应用
需要考虑的因素:
- 长期成本控制
- 数据安全要求
- 定制化需求
- 团队技术能力
ScrapeFly代表了爬虫技术的未来方向——将复杂的技术封装成简单易用的服务,让开发者专注于业务逻辑而非基础设施。随着云原生技术的发展,这种"爬虫即服务"的模式将成为主流,为数据驱动的决策提供更强大的支持。
在选择爬虫解决方案时,应该根据项目需求、技术能力和预算约束来权衡。ScrapeFly提供了一个优秀的选择,特别适合那些需要快速上线、高成功率和低维护成本的项目。
相关资源
- ScrapeFly官方文档
- Python SDK详细指南
- API参考手册
- 最佳实践案例