嵌入式第十八课!!数据结构篇入门及单向链表
在前几章对C语言的学习中,我们学到了:
- 基本的C语法和简单算法
- 面向过程的编程思想
而在数据结构这一篇章,我们将要学习:
- 常用的数据存储结构
- 算法
- 面向对象的编程思想
数据结构
在正式开始学习之前,我们先来了解一下什么是数据结构:
什么是数据结构?
所谓数据结构,就是用来组织和存储数据的,而存储 , 即存储变量、数组(在数据结构里称为顺序表)等;程序 = 数据结构 + 算法,了解数据的存放佐以数据的算法,就构成了程序。
数据与数据之间的关系
1)逻辑结构 :数据元素与元素之间的关系
- 集合:元素与元素之间平等独立的集合关系
- 线性结构:数据元素与元素之间存在一对一的关系(顺序表、链表、队列、栈)
- 树形结构:数据元素与元素之间存在一对多的关系(二叉树)
- 图形结构:数据元素与元素之间存在多对多的关系 (网状结构)
2)物理结构 :数据元素在计算机内存中的存储方式
顺序结构:
在内存中选用一段连续的内存空间(线性结构)进行存储
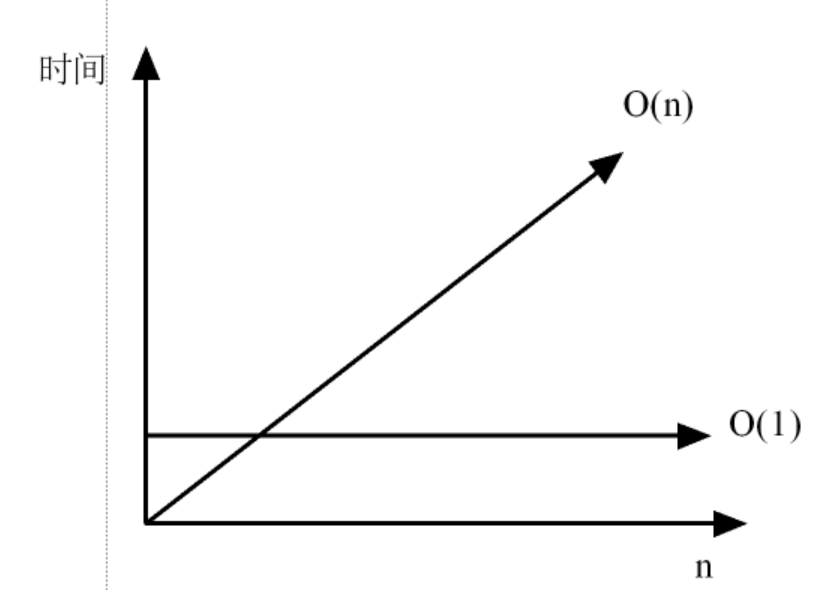
- 数据访问方便(O(1))
- 插入和删除数据时需要移动大量数据
- 需要预内存分配
- 可能造成大量的内存碎片
内存碎片:
- 内内存碎片:如结构体struct里空出的空间;
- 外内存碎片:申请大连续空间(malloc)剩余的空间;
顺序结构的存储如图所示:
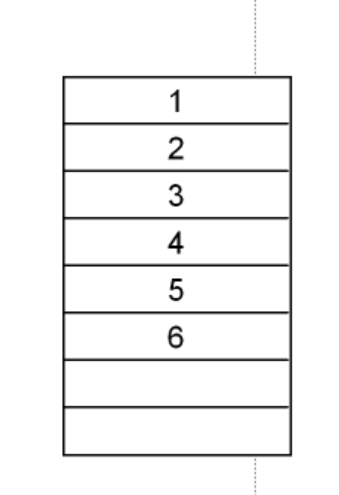
像数组一样,依次进入存储空间,如果要插入数据或删除数据都要把该数据前后的数据修改一下。
链式结构:
可以在内存中选用一段非连续的内存空间进行存储
- 数据访问时必须要从头遍历(O(n))
- 插入和删除元素方便
- 不需要预内存分配,是一种动态存储的方式
- 可以充分使用内存空间
链式结构的存储方式如图所示:
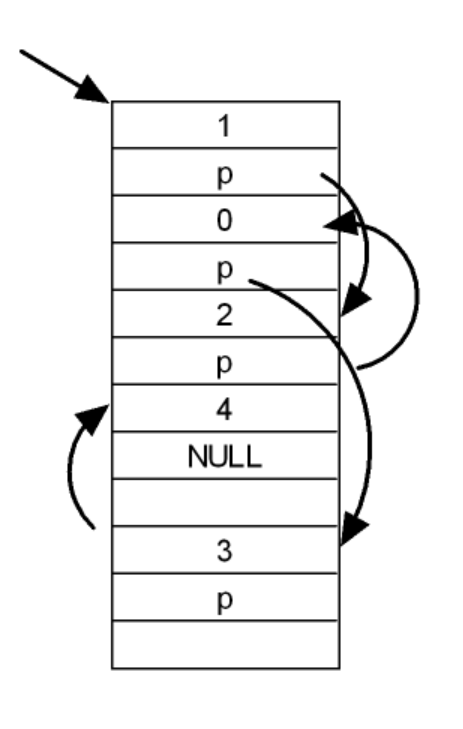
链式结构存储是通过元素后的指针指向下一元素进行链接的,当最后一个元素后的指针是一个空指针时就表示停止。
顺序结构和链式结构的时间复杂度如图所示:
索引结构:
将要存储的数据的关键字和存储位置之间构建一个索引表,也就是给下面的哈希函数建立一个表。
散列结构(哈希结构):
将数据的存储位置与数据元素之间的关键字建立起对应的关系(哈数函数),根据该关系进行数据存储和快速查找
哈希结构存储方式如下图:
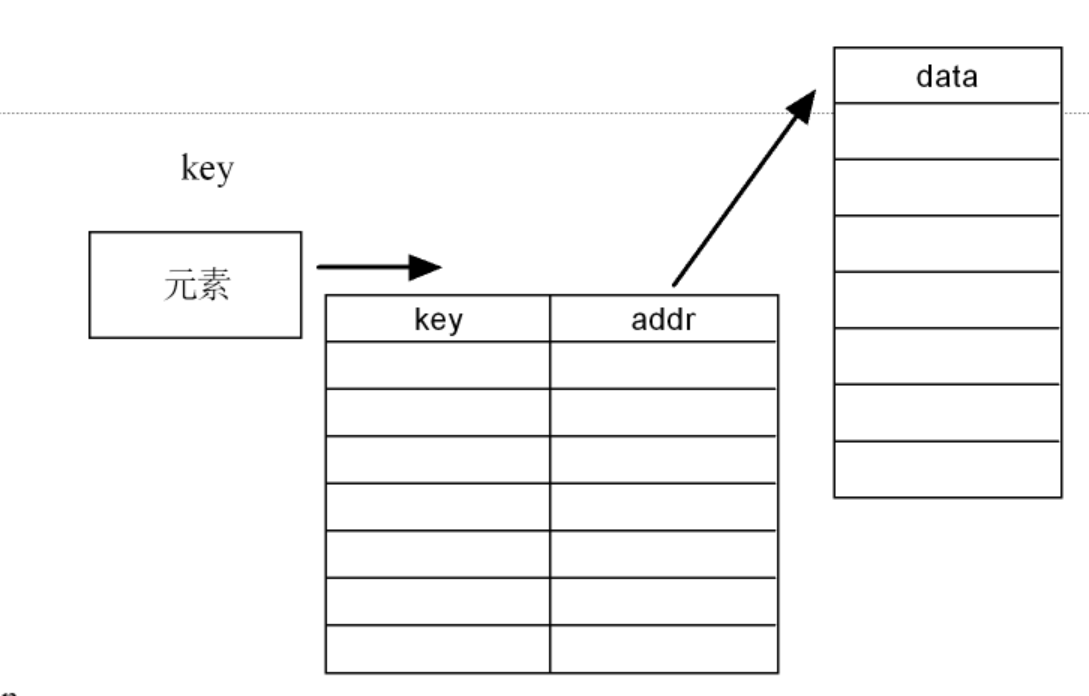
中间关键字key 和addr的表就是索引结构
基本功能
数据结构的基本功能就是:
- 快捷使用指针
- 结构体(封装)
- 实现动态内存分配
数据结构的内容
数据结构包含一下内容(带*的为重点)
1. 链式表
单向链表*
双向链表*
循环链表
内核链表
2. 栈*
3. 队列*
4. 二叉树
5. 哈希表
6.常用算法*
单向链表
单向链表的组成
链表:对象(存储数据的对象)、属性(变量)、行为(函数)
单向链表是由链表对象与各个结点组成的:

结点:
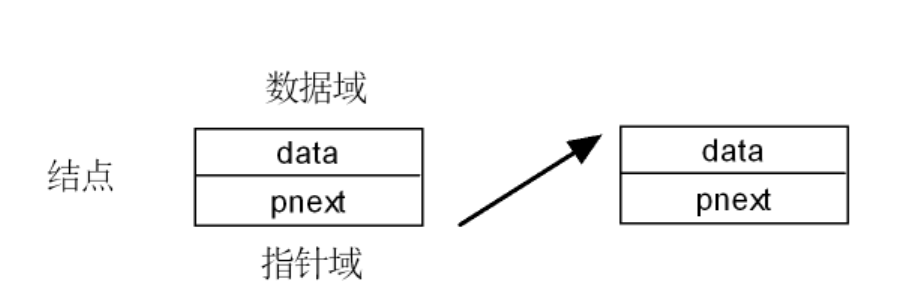
单向链表的结点是由上方的数据域data和下方的指针域pnext(指向下一个结点)组成的。
链表对象
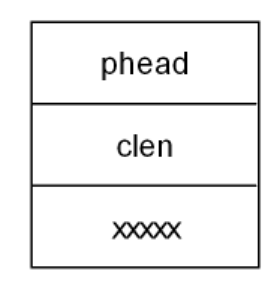
链表对象是由phead(保存头结点地址,指向下一节点),clen(节点个数),以及其他属性组成的。
单向链表代码
1. 创建链表对象
首先我们要先在声明 link . h 里封装结构体:
#ifndef __LINK_H__
#define __LINK_H__/*链表存储的数据的数据类型*/
typedef int Data_type_t;/*链表的结点类型*/
typedef struct node
{Data_type_t data;struct node *pnext;
}Node_t;/*链表对象类型*/
typedef struct link
{Node_t *phead;int clen;
}Link_t;
#endif然后我们在函数文件里创建函数:
#include "link.h"
#include <stdlib.h>
#include <stdio.h>/*创建单向链表*/
Link_t *create_link()
{Link_t *plink = malloc(sizeof(Link_t));if (NULL == plink){printf("malloc error!\n");return NULL;}plink->phead = NULL;plink->clen = 0;return plink;
}
在堆区开辟空间创建链表对象,如果没有申请到空间,即打印出错;如果申请成功,将链表对象指向结点的指针初始化为空指针,节点个数设置为0;
在主函数调用函数:
#include <stdio.h>
#include "link.h"int main(int argc, const char *argv[])
{Link_t *plink = create_link();if (NULL == plink){return -1;}return 0;
}2. 插入数据(头插、尾插)
头插
头插即是从链表对象后开始插入数据:
/*向单向链表的头部插入数据*/
int insert_link_head(Link_t *plink, Data_type_t data)
{//申请结点Node_t *pnode = malloc(sizeof(Node_t));if (NULL == pnode){printf("malloc error!");return -1;}//初始化结点pnode->data = data;pnode->pnext = NULL;//头插2步插入结点pnode->pnext = plink->phead;plink->phead = pnode;plink->clen++;return 0;
}首先,申请空间存放节点,后对结点进行初始化;我们要先让待插入的结点指向当前链表对象指向的结点;后再让链表对象指向当前待插入的结点。不然如果先让链表对象指向待插入的结点,后一位结点的位置将会丢失,不能再进行链接:
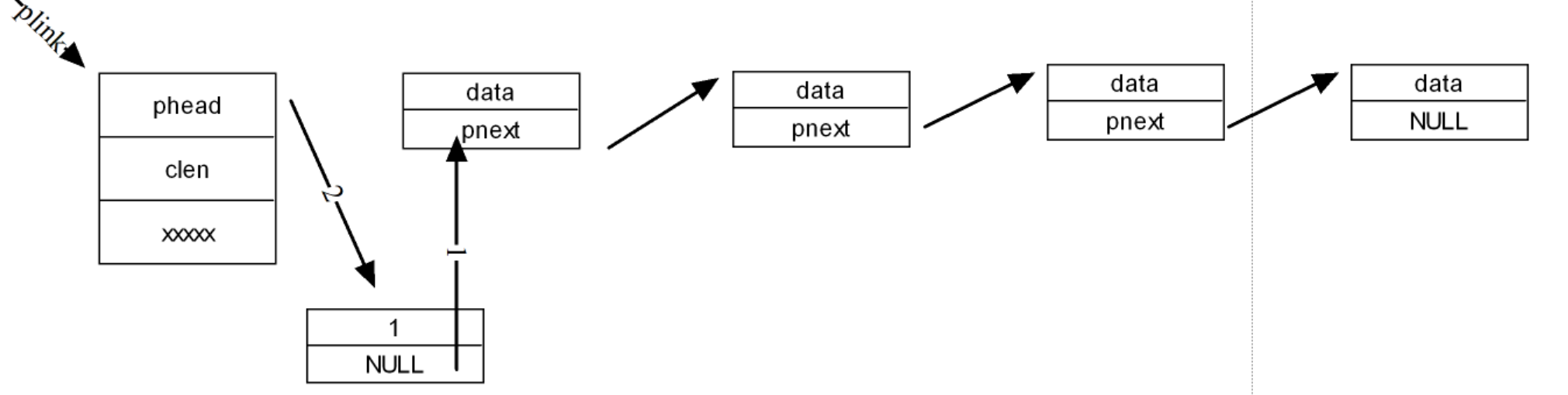
尾插
尾插即是从链表末尾开始插入数据:
int insert_link_back(Link_t *plink , Data_type_t data)
{Node_t *pnode = malloc(sizeof(Node_t));if(NULL == pnode){printf("malloc error!");return -1;}pnode -> data = data;pnode -> pnext =NULL;if(plink -> phead == NULL){plink -> phead = pnode;pnode -> pnext = NULL;plink -> clen++;return 0;}else{Node_t *ptmp = plink -> phead;while(ptmp -> pnext != NULL){ptmp = ptmp-> pnext;}ptmp -> pnext = pnode;plink ->clen++;return 0;}
尾插的一些逻辑算法和头插一致,但不同的是,先判断是否是一个空链表:如果是一个空链表,那就直接改变链表对象的指向与结点的指向即可;如果不是一个空指针,要先遍历一遍结点,找到末尾的结点,修改它的指针域指向待插入结点。
3. 删除数据(头删、尾删)
头删
头删即是从链表对象指向的结点开始销毁空间:
int delete_link(Link_t *plink)
{Node_t*ptmp = plink -> phead;plink -> phead = ptmp -> pnext;if(plink -> phead == NULL){return 0;}else{free(ptmp);plink -> clen--;ptmp = NULL;return 1;}
}先设定一个指针来指向第一个结点,此时设定链表对象指向下一个结点;如果此时是一个空链表,即不再运行、如果非空链表,就解放当前指针ptmp指向的第一个结点的空间,同时让节点个数-1,别忘了此时ptmp是野指针,将ptmp设为空指针。
尾删
尾删即是从链表的最后一个结点开始删除:
int delete_linkback(Link_t *plink)
{if (plink -> phead == NULL){free(plink);return -1;}Node_t*ptmp = plink -> phead;if (ptmp -> pnext == NULL){delete_link(plink);return 0;}else{while(ptmp -> pnext -> pnext != NULL){ptmp = ptmp -> pnext;}free(ptmp -> pnext);plink -> clen--;ptmp -> pnext = NULL;return 1;}
}这种删除数据的方法要找到尾部结点的前一个结点,故使用ptmp寻找它指向结点的下一结点的指向是否指向空指针;如果不是,则继续遍历、如果是,则解放当前指针指向结点的下一结点;同时要记得判断空链表与链表只有一个节点的情况;
4. 查找数据
查找数据时要遍历所有结点的数据域,然后输出找到的地址:
Node_t *find_tdata(Link_t *plink , Data_type_t n)
{Node_t *ptmp = plink->phead;while(ptmp != NULL){if(n == ptmp -> data){return ptmp;}ptmp = ptmp -> pnext;}return ptmp;}这个只需要先让指针指向第一个结点,后一一遍历比较即可。
5. 修改数据
修改数据可以直接调用查找数据的函数,然后直接改变其结点的数据域即可:
Node_t *find_tdata(Link_t *plink , Data_type_t n)
{Node_t *ptmp = plink->phead;while(ptmp != NULL){if(n == ptmp -> data){return ptmp;}ptmp = ptmp -> pnext;}return ptmp;}
int change_linkdata(Link_t *plink , Data_type_t oldata , Data_type_t newdata)
{Node_t*ptmp = find_tdata(plink , oldata);if(ptmp == NULL){return 0;}else{ptmp -> data = newdata;return 1;}
}6. 销毁链表
销毁链表不能直接使用free函数调用指向链表的指针plink,这样会导致剩余的结点的位置全部丢失,导致剩下很多结点的存储空间未被销毁。所以要先使用删除数据,销毁所有结点空间,后再进行销毁链表对象空间:
Link_t *destroy_link(Link_t *plink)
{int n;if(plink -> phead == NULL){free(plink);plink = NULL;return plink;}else{while(plink -> phead != NULL){n = delete_link(plink);if(n == 0){plink = NULL;return plink;}}}
}调用删除数据函数进行循环,直到链表变为空链表为止,后进行销毁;
以上就是和大家分享的内容!!!!单向链表的理解需要指针扎实的基础和结构体的应用,感谢你的阅读!!!!如有遗漏和错误,欢迎评论区进行批评和指正!!