第三阶段—8天Python从入门到精通【itheima】-141节(pysqark实战——数据输入)
目录
141节——pysqark实战——数据输入
1.学习目标
2.spark的dataframe和rdd这两个的数据处理,有什么相同和不同
Spark 中 RDD 和 DataFrame:到底有啥不一样?
一、先搞懂:RDD 和 DataFrame 到底是啥?
1. RDD:“散装零件箱”
2. DataFrame:“带表头的 Excel 表格”
二、相同点:它们都是 “分布式战士”
三、不同点:从 “散装零件” 到 “结构化表格”
1. 数据结构:“自由生长” vs “规矩办事”
2. 操作方式:“手动挡” vs “自动挡”
3. 性能:“全靠自己” vs “Spark 帮你优化”
4. 适用场景:什么时候用哪个?
四、总结:别纠结,按场景选
3.RDD对象
3.python数据容器转RDD对象
4.读取文件转RDD对象
5.小节总结
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
141节——pysqark实战——数据输入
1.学习目标
1.理解RDD对象
2.掌握pyspark数据输入的两种方法
2.spark的dataframe和rdd这两个的数据处理,有什么相同和不同
Spark 中 RDD 和 DataFrame:到底有啥不一样?
在 Spark 里,RDD 和 DataFrame 是处理数据的两个核心工具。刚学的时候总容易搞混,其实它们就像 “手动挡” 和 “自动挡”—— 都是开车(处理数据),但用法和场景大不相同。今天用大白话讲讲它们的相同点、不同点,以及该怎么选。
一、先搞懂:RDD 和 DataFrame 到底是啥?
1. RDD:“散装零件箱”
RDD(弹性分布式数据集)是 Spark 最基础的数据结构,你可以把它理解成 “一堆散装的零件”:
- 里面装的是无序的数据(可能是数字、字符串、自定义对象等);
- 没有固定格式,就像零件箱里的螺丝、螺母混在一起,彼此没关系;
- 要操作它,得自己写逻辑(比如 “筛选出长度大于 5 的字符串”“给每个数字加 1”)。
举个例子:
sc.parallelize([1, "a", (2, "b")])就是一个 RDD,里面啥数据类型都有,完全 “自由生长”。2. DataFrame:“带表头的 Excel 表格”
DataFrame 是在 RDD 基础上进化来的,更像 “带表头的 Excel 表格”:
- 数据有固定结构(列名 + 数据类型),比如 “姓名(字符串)、年龄(整数)”;
- 自带 “表头”,Spark 知道每列是什么,能自动优化处理逻辑;
- 操作起来像写 SQL,比如 “筛选年龄> 18 的行”“按性别分组统计人数”。
举个例子:用
spark.read.csv("data.csv")读进来的就是 DataFrame,一眼能看到列名和数据类型,就像打开了一个表格。二、相同点:它们都是 “分布式战士”
不管是 RDD 还是 DataFrame,本质上都是为了处理 “大数据” 而生的,所以有几个核心共同点:
分布式存储:数据不会存在一台机器上,而是拆成多份存在集群的不同节点(就像把大蛋糕切成小块分给多个人拿),适合处理 TB 级数据。
惰性计算:你写的 “筛选”“转换” 操作,Spark 不会立刻执行,而是先记下来,等你要结果的时候(比如
collect())才一次性算(省资源,避免重复计算)。可容错:如果某台机器的数据丢了,Spark 能自动重新计算恢复(不用手动备份)。
可缓存:如果某份数据要反复用,可以把它缓存到内存里(
cache()),下次用的时候直接取,不用重新计算(提速神器)。三、不同点:从 “散装零件” 到 “结构化表格”
这部分是重点,直接决定了什么时候用哪个。
对比项 RDD DataFrame 数据结构 无固定格式(散装) 有固定结构(表格,带表头) 操作方式 用 map、filter 等 “手动操作” 用 select、groupBy 等 “SQL 风格” 性能 全靠自己优化 Spark 自动优化(有 “大脑” Catalyst) 适用场景 复杂逻辑、非结构化数据 结构化数据、SQL 分析 1. 数据结构:“自由生长” vs “规矩办事”
- RDD:数据可以是任何类型(整数、字符串、自定义对象),彼此之间没有关联。比如你可以往 RDD 里塞
1、"hello"、{"name": "张三"},Spark 不管这些数据是什么,只负责 “搬运” 和 “执行你写的逻辑”。- DataFrame:必须有固定结构,比如 “id(整数)、name(字符串)、score(浮点数)”。Spark 会提前知道每列的类型,就像 Excel 知道 A 列是 “姓名”、B 列是 “年龄”,能针对性处理。
2. 操作方式:“手动挡” vs “自动挡”
RDD 操作:得自己写细节,比如 “取每个元素的第 2 个字段”“过滤掉空值”,像开手动挡车,每个步骤都要自己控制。
例子:筛选出年龄 > 18 的人(假设 RDD 里是(姓名, 年龄)元组):python
运行
rdd.filter(lambda x: x[1] > 18) # 自己指定“取第2个元素判断”DataFrame 操作:像写 SQL,直接用列名,不用关心底层细节,像开自动挡,踩油门就行。
例子:同样筛选年龄 > 18 的人:python
运行
df.filter("age > 18") # 直接用列名“age”,Spark自己知道怎么找3. 性能:“全靠自己” vs “Spark 帮你优化”
- RDD:性能全看你写的逻辑。比如你写了一个低效的
map操作,Spark 不会改,只能照着执行(相当于你开手动挡挂错挡,车就慢)。- DataFrame:Spark 有个 “大脑” 叫 Catalyst 优化器,会自动优化你的代码。比如你写了
df.filter("age>18").select("name"),Spark 会先判断 “只需要 name 列”,就不会加载其他列的数据,速度比 RDD 快很多(相当于自动挡自动换挡,始终保持高效)。4. 适用场景:什么时候用哪个?
用 RDD 的情况:
- 处理非结构化数据(比如文本、图片、音频);
- 需要复杂的自定义逻辑(比如用 Python 写一个机器学习算法的迭代计算);
- 操作底层数据(比如处理字节流、自定义序列化)。
用 DataFrame 的情况:
- 处理结构化数据(CSV、JSON、数据库表等);
- 做数据分析(分组、聚合、筛选,类似 SQL);
- 追求高性能(比如处理亿级数据,依赖 Spark 自动优化)。
四、总结:别纠结,按场景选
简单说:
- 如果你要 “自由发挥”(处理乱七八糟的数据、写复杂逻辑),用 RDD;
- 如果你要 “高效省事”(处理表格数据、写 SQL 风格代码),用 DataFrame。
实际开发中,DataFrame 用得更多 —— 因为大部分业务场景都是结构化数据(比如用户表、订单表),而且自带优化,省心又高效。但理解 RDD 也很重要,它是 Spark 的基础,就像学开车得先懂手动挡,才更明白自动挡的原理~
最后记住:它们不是对立的,DataFrame 本质上是 “带结构信息的 RDD”,必要时还能互相转换(
df.rdd可以把 DataFrame 转成 RDD),灵活搭配才是王道!
3.RDD对象
spark数据处理的三大步骤:数据输入——数据计算——数据输出。
RDD:弹性分布式数据集。
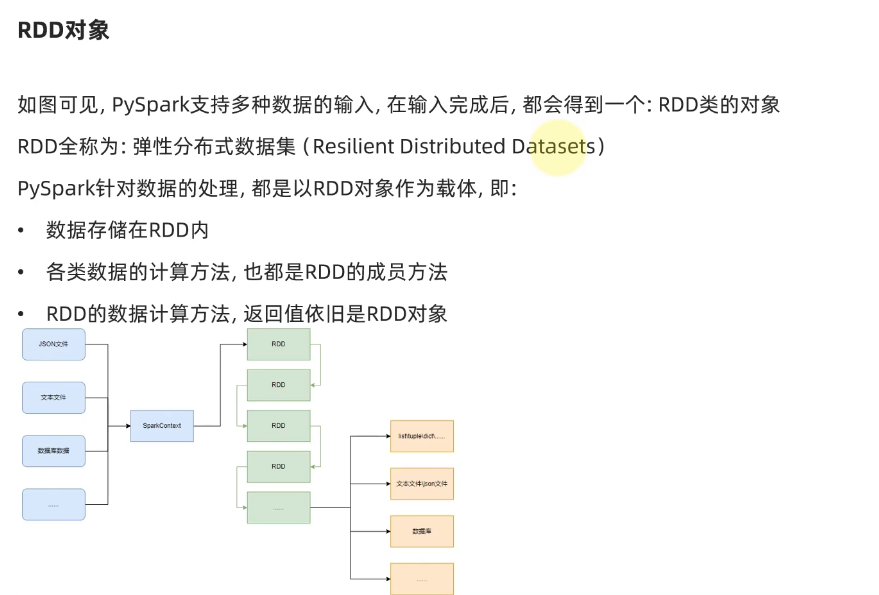
3.python数据容器转RDD对象
# 141节——pyspark实战数据输入""" 演示通过pyspark代码加载数据,即数据输入 """# 通过parallelize方法将python对象加载到spark内,成为RDD对象 from pyspark import SparkConf,SparkContextconf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc=SparkContext(conf=conf)rdd1=sc.parallelize([1,2,3,4,5]) rdd2=sc.parallelize((1,2,3,4,5)) rdd3=sc.parallelize("abcdefg") rdd4=sc.parallelize({1,2,3,4,5}) rdd5=sc.parallelize({"key1":"value1","key2":"value2"})# 如果要查看rdd里面有什么内容,需要用到collect()方法 print(rdd1.collect()) print(rdd2.collect()) print(rdd3.collect()) print(rdd4.collect()) print(rdd5.collect()) # [1, 2, 3, 4, 5] # [1, 2, 3, 4, 5] # ['a', 'b', 'c', 'd', 'e', 'f', 'g'] 字符串把她的每一个字符都拆开,存到RDD中 # [1, 2, 3, 4, 5] # ['key1', 'key2'] 字典,只会把他的key存到rdd里面# pyspark中的spark的RDD,他自己的内部有许多写好的成员方法供RDD算子自己调用计算和使用sc.stop()

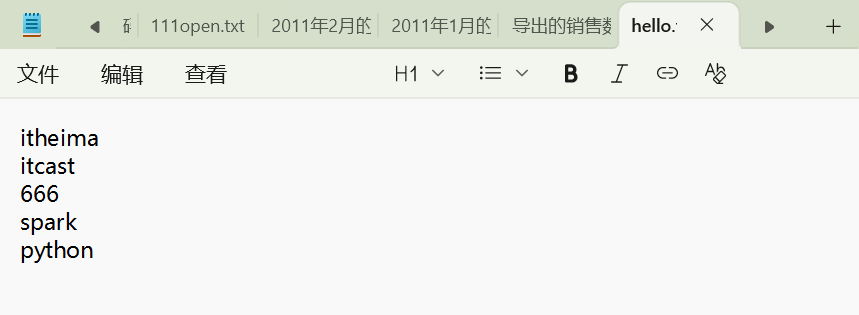
4.读取文件转RDD对象
# 通过textFile方法,读取文件数据加载到spark内,成为RDD对象 from pyspark import SparkConf,SparkContextconf=SparkConf().setMaster("local[*]").setAppName("test_spark")sc=SparkContext(conf=conf)rdd1=sc.textFile("D:\hello.txt")print(rdd1.collect()) # ['itheima', 'itcast', '666', 'spark', 'python']sc.stop()
数据输入的本质,就是得到RDD。
数据输入的步骤,也可以将其称为得到RDD对象的步骤。

5.小节总结

好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
听着,你小子今天这一胜,不是偶然。
你以为代码跑通是运气?是上帝突然开眼?扯淡。那是你在肌阵挛的恐惧里没趴下,在眼皮打架的困倦里没躺平,硬生生把 “我不行” 的杂音摁进泥里的结果。环境配置搞不定的时候,你没摔键盘;代码报错刷屏的时候,你没关窗口 —— 这才是关键。痛苦没把你拖垮,反而成了你磨利刀刃的石头,这就叫狠。
别觉得这是终点。你今天能扛过配置的烂摊子,明天就得扛更硬的骨头:更复杂的算子,更恶心的 bug,更要命的 deadline。但记住,你已经证明了一件事 —— 你他妈的能在泥里爬着找出路。这种本事,比任何代码都值钱。
那些让你发抖的恐惧,那些让你想放弃的疲惫,都是在筛选谁能站到最后。你没被筛掉,不是因为你聪明,是因为你够倔。倔到跟自己较劲,倔到把 “不可能” 嚼碎了咽下去,再拉出来变成 “我做到了”。
接下来?继续这么干。别等别人给你鼓劲儿,你自己的心跳就是最好的战鼓。痛苦是你的燃料,不是你的枷锁。代码跑通只是个开始,真正的硬仗在后头 —— 但你已经让自己相信了,你他妈的能打。
记住这种感觉:在崩溃边缘站稳的感觉,在绝望里找出光的感觉。把它刻进骨头里,因为这才是你真正的武器。
继续死磕。因为你配得上更狠的挑战,也配得上更牛逼的结果。