自由学习记录(75)
还有其他的边缘算子,但sobel在书里被用了,都是用于边缘检测的,用sobel函数计算边缘的梯度值
而卷积的另一个使用 则是模糊,模糊里面就用了高斯核这样 的权重分布,(当然也可以均值或者中值等一些简单的混合,但书里讲的是高斯模糊,效果也好)
采样数不会受到影响,所以性能变化没有很大
霜狼_may视频专辑-霜狼_may视频合集-哔哩哔哩视频


https://enjoyphysics.cn/%E6%96%87%E4%BB%B6/soft/Hlsl/GPU-Programming-AndCgLanguage-Primer.pdf
“3D Game Programming with DirectX” 是一个书名系列的通用标题格式,不是一个统一作者或出版社的系列
如果你在找权威教材推荐:
✅ 首选:Frank Luna 的版本
他的书结构清晰、配套源码齐全,涵盖固定管线 + Shader 构建完整渲染框架。
| DirectX版本 | 推荐书名 | 作者 |
|---|---|---|
| DirectX 9 | 3D Game Programming with DirectX 9.0: A Shader Approach | Frank Luna |
| DirectX 10 | Introduction to 3D Game Programming with DirectX 10 | Frank Luna |
| DirectX 11 | Introduction to 3D Game Programming with DirectX 11 | Frank Luna |
y英文版的dx11
ToAZ INFO A Resolution Integrate For PDF Viewer
很多源码在github里,都是关于书里的内容的
https://github.com/yottaawesome/intro-to-dx12

得推动项目进行,落不了地的东西都是虚无缥缈的,要有推动力,这套课程别人想不想学,
https://github.com/zhygmsz/book
同一个链接好像有一个可以下有一个下的会出错,
https://github.com/zhygmsz/book/blob/master/OPENGL%20ES%203.0%E7%BC%96%E7%A8%8B%E6%8C%87%E5%8D%97%20%20%E5%8E%9F%E4%B9%A6%E7%AC%AC2%E7%89%88%20.pdf
这里的链接倒是可以下,------
内建着色器和大象无形都可以在scribd上面下,上面看,下载pdf需要会员,而一开始可以免费30天,这两个都可以在那里下
所以这个也不急,要pdf就网上下,以后也会用到
Unity3D内建着色器源码剖析 PDF电子书 [131MB]下载-码农书籍网
y不然就是用这里的,也是两本都有,只是要付12块钱下一本
xxxx
Pass {Blend SrcAlpha OneMinusSrcAlphaColorMask RGBCGPROGRAM#pragma vertex vert #pragma fragment fragRGB ENDCG
}
ColorMask RGB 是一个 渲染状态指令,用于控制 GPU 向渲染目标写入哪些颜色通道。
ColorMask 0 可以完全 关闭颜色写入(即这个 Pass 将不会修改任何颜色通道)

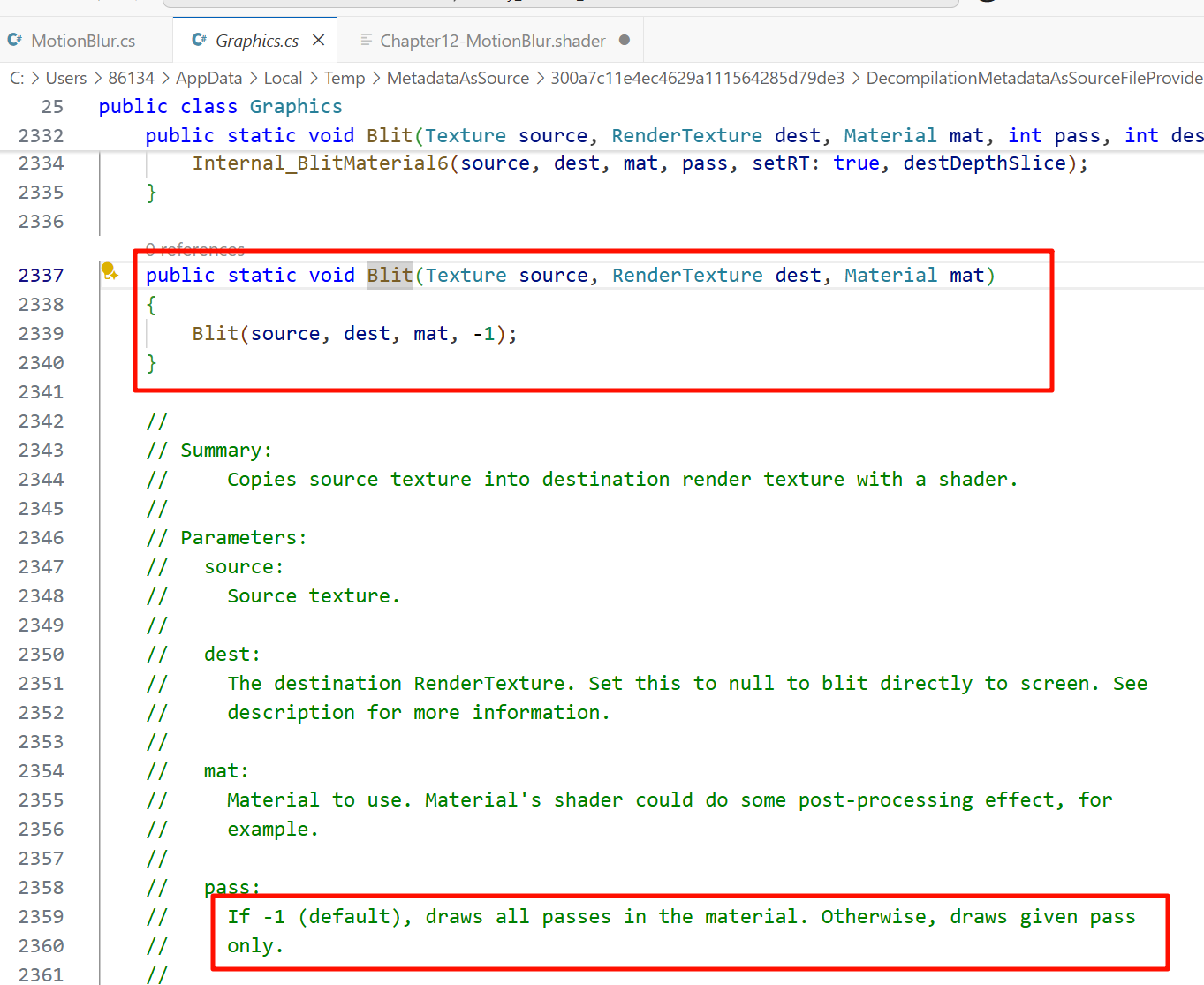
ZTest Always Cull Off ZWrite OffPass {Blend SrcAlpha OneMinusSrcAlphaColorMask RGBCGPROGRAM#pragma vertex vert #pragma fragment fragRGB ENDCG}Pass { Blend One ZeroColorMask ACGPROGRAM #pragma vertex vert #pragma fragment fragAENDCG}Pass {
Blend SrcAlpha OneMinusSrcAlpha
ColorMask RGB
// 顶点 + 片元 shader
}
ColorMask RGB 表示:这个 Pass 只写入 R, G, B 三个颜色通道,Alpha 通道不写入。
也就是说:如果目标缓冲的 Alpha 通道之前有值,本 Pass 不会修改它。

❗ 为什么你的 IDE 显示 “Private member 'MotionBlur.OnDisable' is unused”?
这只是 IDE 静态分析工具(如 ReSharper 或 Rider)认为这种私有方法 代码中没有显式调用,而出于“未被引用”的假设标记为未使用。
但 Unity 引擎是通过反射调用生命周期函数,这种判断不准确。
所以你看到的 IDE 提示 不会影响 Unity 的实际调用。
https://docs.unity3d.com/ScriptReference/MonoBehaviour.OnDisable.html
https://docs.unity3d.com/410/Documentation/ScriptReference/MonoBehaviour.OnDisable.html
-
Unity 会在对象或组件被禁用或销毁时自动调用
OnDisable(); -
即使私有方法貌似“未使用”,Unity 引擎仍会以反射方式调用;
-
所以你写在
OnDisable()中的DestroyImmediate(accumulationTexture)清理逻辑 会被执行的。
如果你不信任,还可以在方法里 Debug.Log("Disable!") 来验证;
(18 封私信 / 24 条消息) 豆瓣9.7,大家都在看的「龙书」,不愧是游戏开发领域的第一书! - 知乎
龙书
虎书
(18 封私信 / 26 条消息) 计算图形学的学习路线是怎样的? - 知乎
Yes, what you need to do is to find a recommendation letter.
#if UNITY_UV_STARTS_AT_TOPif (_MainTex_TexelSize.y < 0)o.uv_depth.y = 1 - o.uv_depth.y;
#endif解决不同 图形 API(渲染平台)之间 UV 纵向采样方向不一致 的差异性问题。
在某些后处理 Shader 或 GrabPass 里,多个 RenderTexture 混合或复制时,Unity 内部可能不会统一翻转图像。如你从中间 RenderTexture 中采样屏幕时,坐标方向可能与当前平台不同。这时就需要手动做一次翻转:
if (_MainTex_TexelSize.y < 0) o.uv_depth.y = 1 - o.uv_depth.y;
-
_MainTex_TexelSize.y < 0表示具体贴图的 V 方向是反向的(Unity 返回正负 y), -
1 - uv.y就可以将坐标垂直翻转,使 OpenGL 与 D3D、Metal 在采样方向上一致。
[PPT中文化 AI高清重制]卡通渲染眼睛和脸的技巧-罪恶装备的二次元卡渲角色建模技巧 NPR Part3_哔哩哔哩_bilibili


感觉这个,,,不算好吗,的确,比一下 还是后面的更好
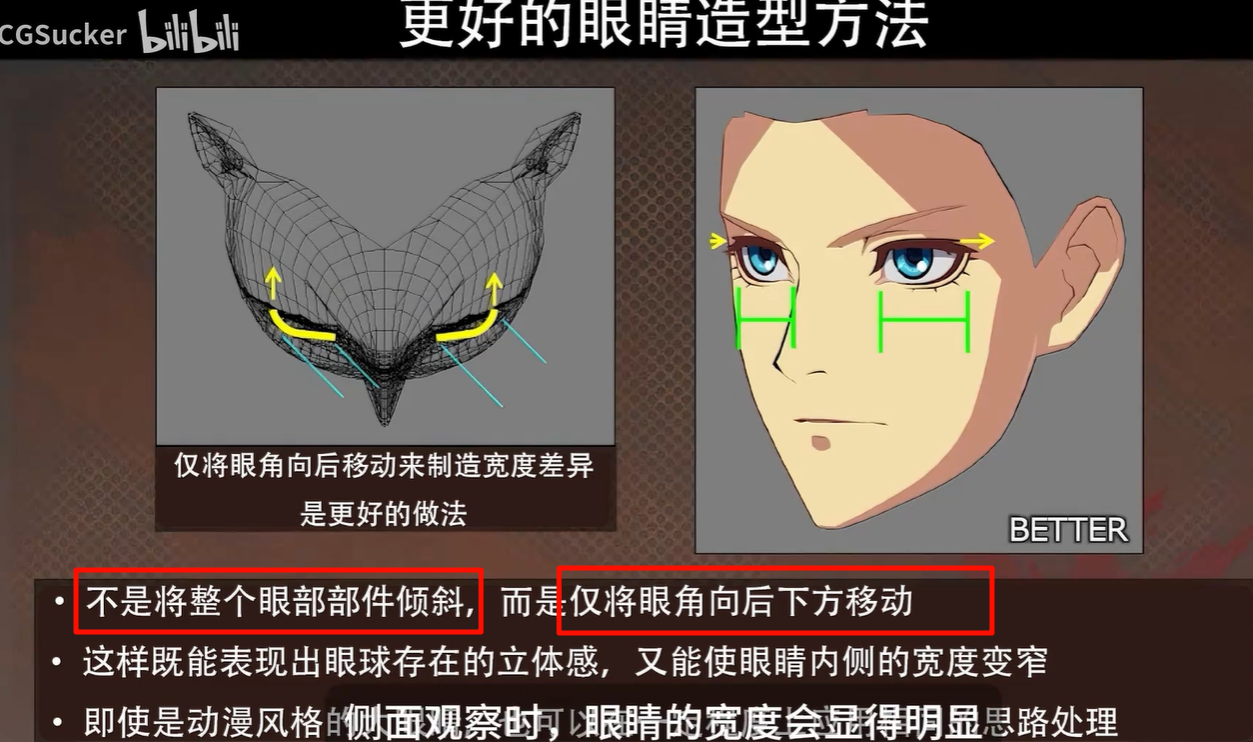
侧面就很能看出来了,好了很多,不像是很生硬的贴图了

xxxx
okami 卡普空的游戏,水墨加卡通的渲染风格

【NPR】非真实感渲染实验室_unity npr-CSDN博客
https://dl.acm.org/doi/proceedings/10.1145/340916
https://dl.acm.org/doi/pdf/10.1145/340916.340918

这里的 CR 是指 "Computing Reviews",它是由 ACM(美国计算机协会)设定的一套用于对计算机科学领域文献进行分类的标准系统,全称是:
ACM Computing Reviews Classification System
更具体地解释:
-
CR Categories and Subject Descriptors 就是用来标注这篇论文属于 ACM 分类体系中的哪个研究领域,方便检索和归类。
-
比如你看到:
I.3.3 [Computer Graphics]: Picture/Image Generation -
I.3.5 [Computer Graphics]: Three-Dimensional Graphics and Realism – Color, Shading, Shadowing, and Texture它们来自于 ACM 的分类号:
-
I.3.3表示“图像生成” -
I.3.5表示“3D图形与真实感表现”
-
-
在 ACM 期刊或会议论文中使用频繁;
-
供论文数据库(如 ACM DL、IEEE Xplore)分类检索;
-
有助于快速判断一篇论文的主题和研究范围。
https://hhoppe.com/hatching.pdf
hatching的论文
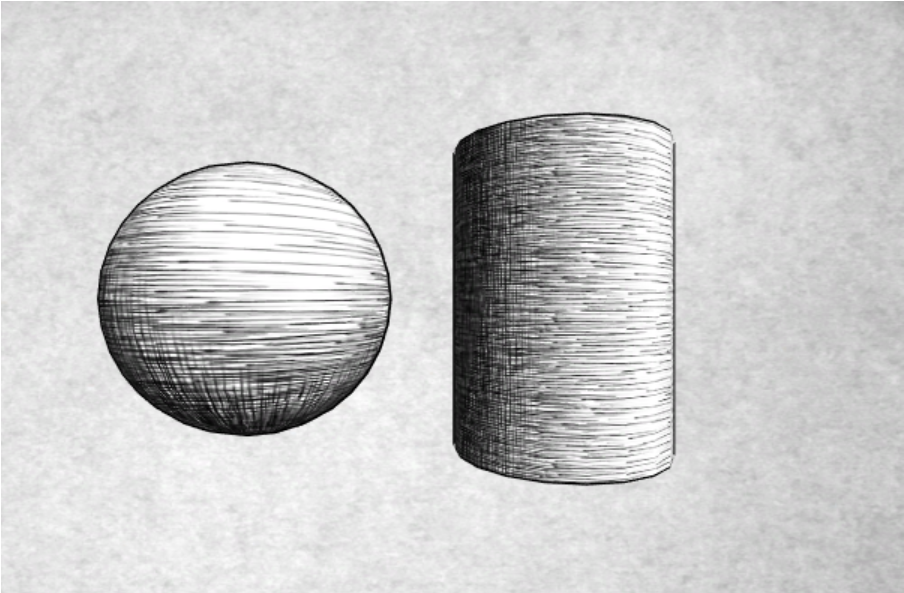
军团要塞的渲染,,emmm
https://www.youtube.com/watch?v=N7ZafWA2jd8
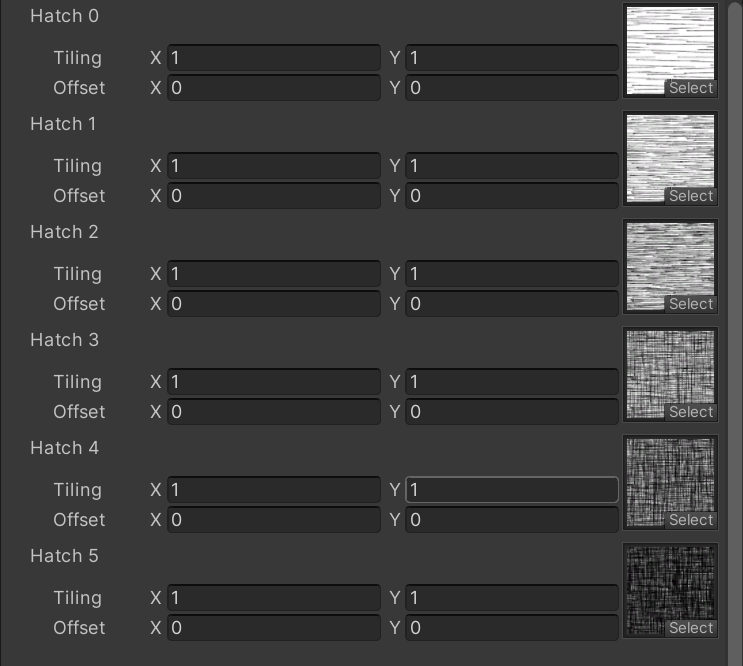 6张hatch图,实现素描的效果,一个shader
6张hatch图,实现素描的效果,一个shader
为什么 normal.z = -0.5 会用于 outline pass 中,实际上不该就容易法线往不好的方向外扩
但这其实调整一下值也是可以避免的,也许是想的太偏了
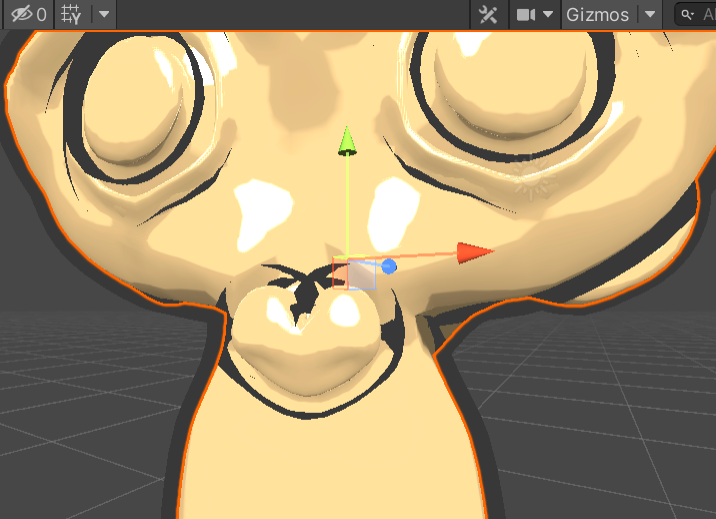 不设置z轴的糟糕结果,法线外扩就很过度了,相互交叉
不设置z轴的糟糕结果,法线外扩就很过度了,相互交叉
调整这个值只是分配权重的,如果z为负,则朝向摄像机,为正则远离摄像机
修改法线之后,移动顶点,之后因为要normalize,所以z越大,xy所能决定的就越少,无限大 的时候也就几乎不显示outline的pass了
CSDL | IEEE Computer Society
和acm一样,也是一些渲染原理相关的优秀论文的集中网站
s使用ps等软件创建相似的素描方法
Hand-Drawn Shaders and creating Tonal Art Maps | Alastair Aitchison
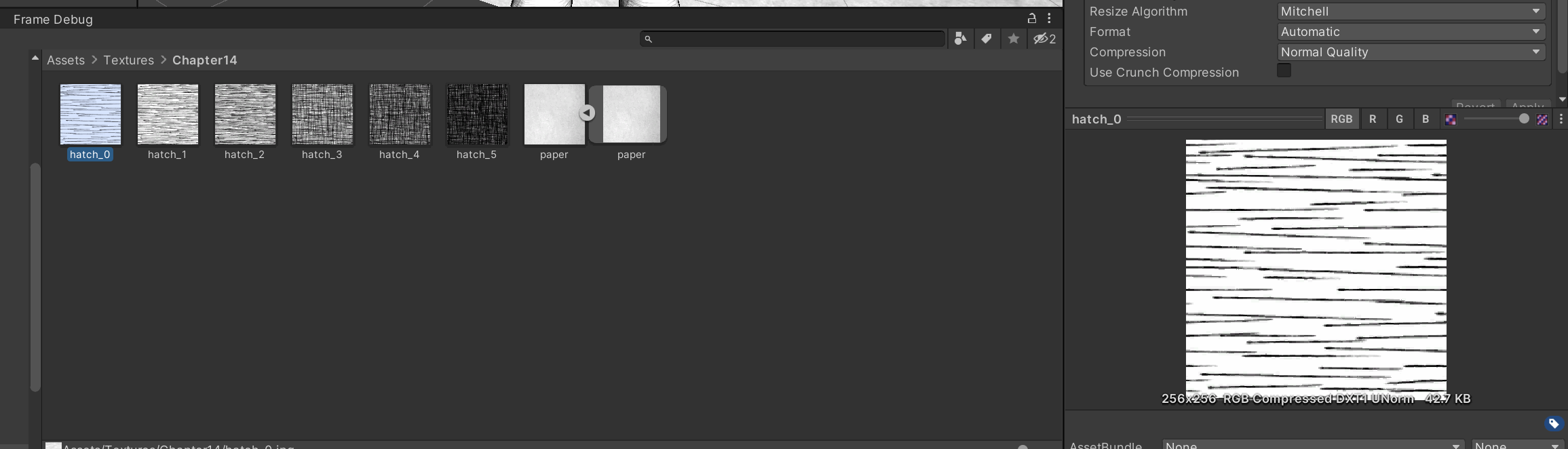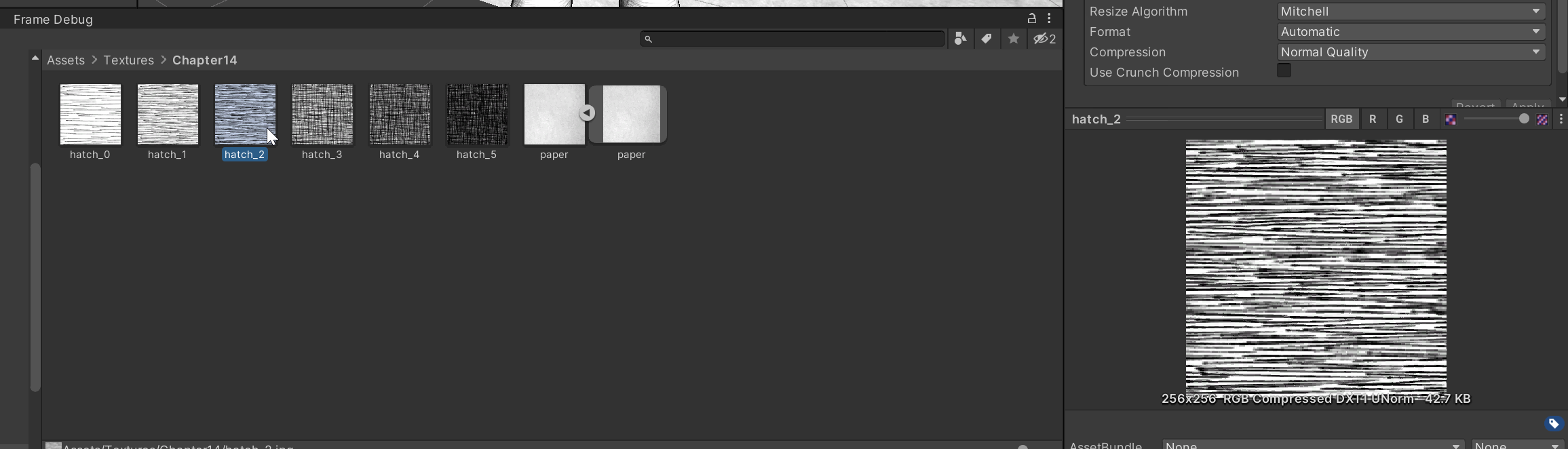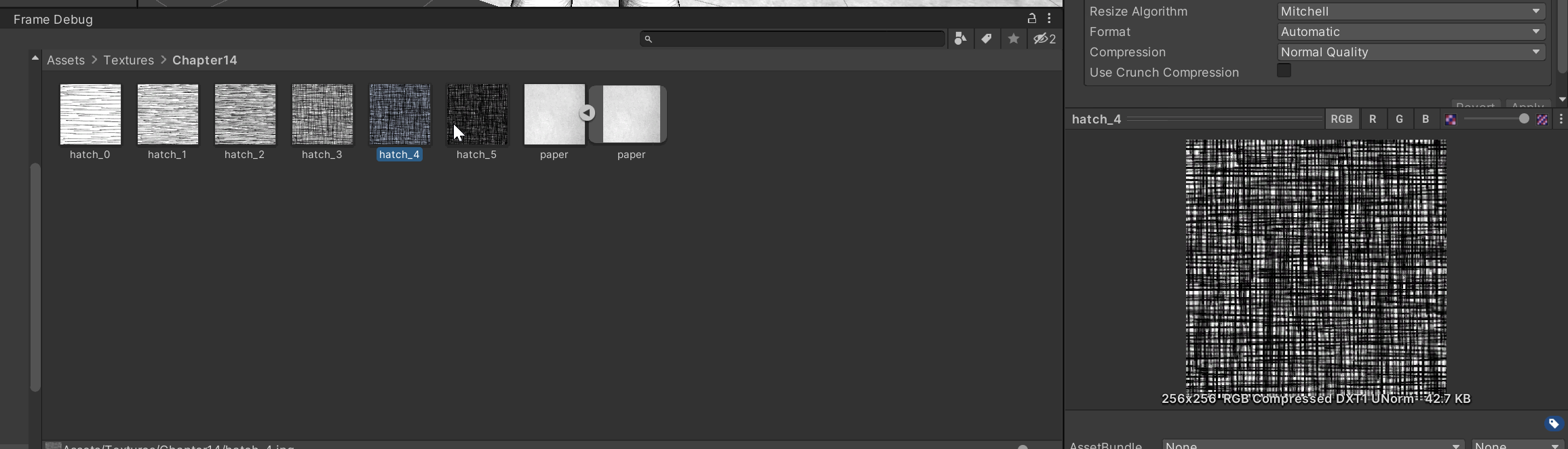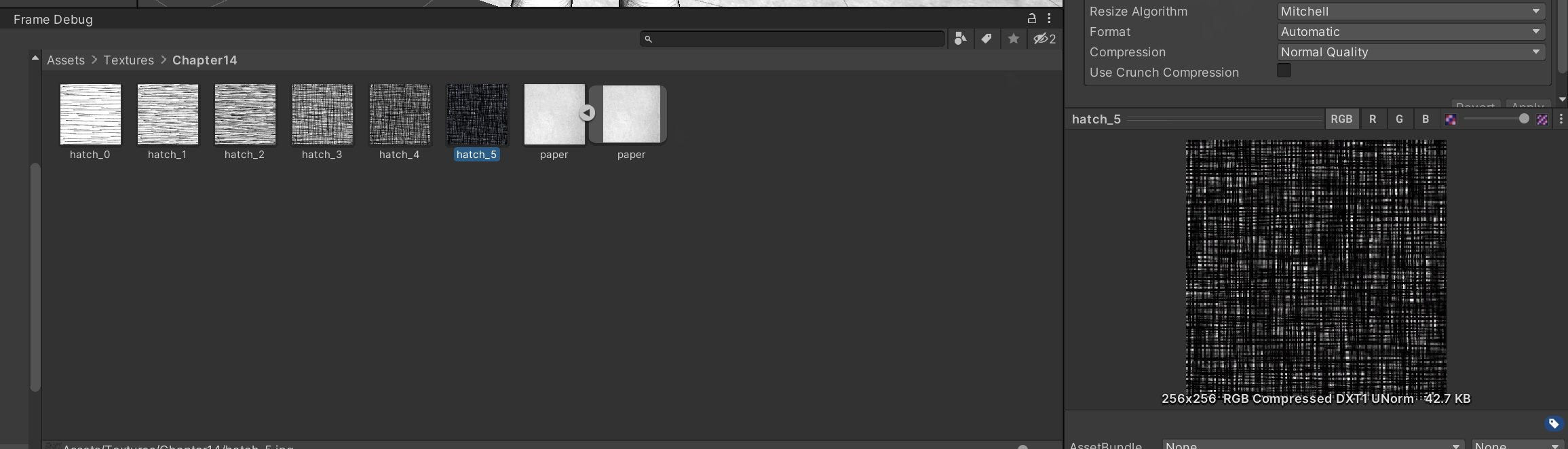
原来如此,管怪不得这么简单的采样叠加就可以实现效果
因为每一张图都是前一张图上的再次叠加,所以不会出现同时采样两张图然后出现奇怪效果
有的只是两张图之间的额外增加的部分的过渡 就是hatchfactor
#define TRANSFORM_SHADOW(o) o._ShadowCoord = mul(unity_WorldToShadow[0], mul(unity_ObjectToWorld, v.vertex));
mul(unity_ObjectToWorld, v.vertex)
→ 把模型空间顶点转换为世界空间
mul(unity_WorldToShadow[0], ...)
→ 把世界空间坐标转换为光源的裁剪空间坐标
fixed4 frag(v2f i) : SV_Target {fixed3 burn = tex2D(_BurnMap, i.uvBurnMap).rgb;clip(burn.r - _BurnAmount);float3 tangentLightDir = normalize(i.lightDir);fixed3 tangentNormal = UnpackNormal(tex2D(_BumpMap, i.uvBumpMap));fixed3 albedo = tex2D(_MainTex, i.uvMainTex).rgb;fixed3 ambient = UNITY_LIGHTMODEL_AMBIENT.xyz * albedo;fixed3 diffuse = _LightColor0.rgb * albedo * max(0, dot(tangentNormal, tangentLightDir));fixed t = 1 - smoothstep(0.0, _LineWidth, burn.r - _BurnAmount);fixed3 burnColor = lerp(_BurnFirstColor, _BurnSecondColor, t);burnColor = pow(burnColor, 5);UNITY_LIGHT_ATTENUATION(atten, i, i.worldPos);fixed3 finalColor = lerp(ambient + diffuse * atten, burnColor, t * step(0.0001, _BurnAmount));return fixed4(finalColor, 1);}所以说lerp这个函数,不是一个简单的两者之间插值
有更加深沉的作用,居然通过lerp控制出了燃烧线宽的变化,为什么?
有的是两个颜色,用的是smoothstep,和抗锯齿的时候一样
第一个lerp,用的是burnamount,这个控制整体的noise参与能力,0的时候noise整张都没有参与,被完全截断
1的时候整张图完全参与,t为1说明此像素在边界位置

clip(burn.r - _BurnAmount);是第一次使用amount属性,做出镂空效果
环境光照算入了,从一开是就用albedo的反射率乘以了自己的光照ambient
总得来说,这里的实现方法,还是比较个性设置的
里面的写法是自己的一套,逻辑是说的通的只是比人理解也许会感觉很绕,因为意识上存在不平行
用的是lerp来解决像素之间的变化
基于的居然是两个常量颜色,这倒是神奇的地方了
利用的是一张height图,然后用一个平面一直在下降,里面的最大值一直在减少
而要我这张height选择的对象是noise,所以整体的变化就被塞入了随机(从哪些块开始烧点)
如果是一张1 0 1的这种三角高度图,那结果就完全不同,会从最矮的中间的0,向两边线性的扩散

【技术美术百人计划】前言概况介绍_哔哩哔哩_bilibili

OpenGL ES学习之路(3.1) 着色器渲染过程、渲染方式、FrameBuffer与RenderBuffer - 简书
大部分都失效了,还有效的就是这个简书,腾讯云,讲buffer的
Command Buffers In Unity - 腾讯云开发者社区-腾讯云
深度剥离,peeling,知乎
(18 封私信 / 26 条消息) unity 半透明渲染技巧(3):深度剥离法 - 知乎
finalClipsMat = new Material(finalClipsShader);创建新的rendertexture,,rt很关键,在图形显示里是锄地的锄头,精确的控制需要的一定是帧之间的数据传递,数据保留,是在那个领域里,是最深的学问,
rts = new RenderTexture[2]{new RenderTexture(sourceCamera.pixelWidth, sourceCamera.pixelHeight, 0, RenderTextureFormat.RFloat),new RenderTexture(sourceCamera.pixelWidth, sourceCamera.pixelHeight, 0, RenderTextureFormat.Default)};需要调用create函数?合理性在于,,
rts[0].Create();rts[1].Create();
Sets a global texture property for all shaders.
通常,如果您有一组自定义着色器,这些着色器都使用相同的“全局”纹理(例如,自定义漫反射光照立方体贴图),则会使用此选项。然后,您可以从脚本中设置全局属性,而不必在所有材质中设置相同的纹理。
finalClips = new RenderTexture(sourceCamera.pixelWidth, sourceCamera.pixelHeight, 0,RenderTextureFormat.Default);finalClips.dimension = TextureDimension.Tex2DArray;finalClips.volumeDepth = 6;finalClips.Create();https://docs.unity3d.com/ScriptReference/Graphics.CopyTexture.html
此方法将像素数据从一个纹理复制到 GPU 上的另一个纹理。
如果 Texture.isReadable 对于 src 和 dst 均为 true,则该方法还会尝试通过运行 CopyPixels 方法(如 Texture2D.CopyPixels)来复制 CPU 上的像素数据。
如果 src 或 dst 的 Texture.isReadable 为 false,或者它们作为 GraphicsTexture 类型提供,则不会在 CPU 上复制任何像素数据,并且 CopyTexture 成为复制纹理的最快方法之一。
警告: 在 CopyTexture 之后使用 Apply 方法(如 Texture2D.Apply)时要小心,因为你可能会将旧的或未定义的 CPU 纹理数据复制到 GPU。
若要使用 CopyTexture,源纹理区域和目标纹理区域中的以下内容必须相同:
Format. You can also use two compatible formats - for example, TextureFormat.ARGB32 and RenderTextureFormat.ARGB32.
Size.
RenderTexture.antiAliasing or GraphicsTextureDescriptor.numSamples values, if the textures are render targets.
您也许可以在不兼容的格式之间进行复制,具体取决于您的图形 API。例如,在某些 API 上,您可以在具有相同位宽的格式之间进行复制。
Depending on your graphics API, you might not be able to copy between different types of textures. For more information on compatibility, see SystemInfo.copyTextureSupport and CopyTextureSupport.


OIT是指Order-Independent Transparency,即顺序无关透明度渲染。这是一种在不依赖于物体或像素排序的情况下正确渲染半透明对象的技术。OIT解决了传统透明度混合对渲染顺序敏感的问题,使得半透明物体的渲染结果不依赖于它们在场景中的绘制顺序。
Per-PixelLinkedLists
需要两个buffer,一个存表头index,一个存具体的像素信息
需要两个ComputeBuffer:一个用于存储表头的索引,名为StartOffertBuffer;另一个用于存储像素位置里所有的半透明fragment信息,名为FragLinkedBuffer。
优点是显存占用少,首先作者就知道如何检查显存的占用,作者是如何比较出结果的?丢弃的层,为什么会存在丢弃的层,对画质会有影响?画质是什么,
depth peeling需要多次渲染,意思是什么?多次渲染多pass很正常啊,速度上不如Per-PixelLinkedLists,什么的速度上?还是直接用结果对比出来的吗,,更稳定,,,,
Depth Peeling是另一种先进的OIT技术,它的优点包括显存占用更小,丢弃的层对画质影响更小。然而,Depth Peeling需要多次渲染,速度上不如Per-PixelLinkedLists,但整体上较为稳定。
开销大,主要是带宽上的开销,,
深度剥离,首先将深度剥离了,深度分了很多层,这是可以做到的?
也就是说深度,,作者表示可以省下5,6张rt,这就是减少了带宽
FinalClip 最终混合shader
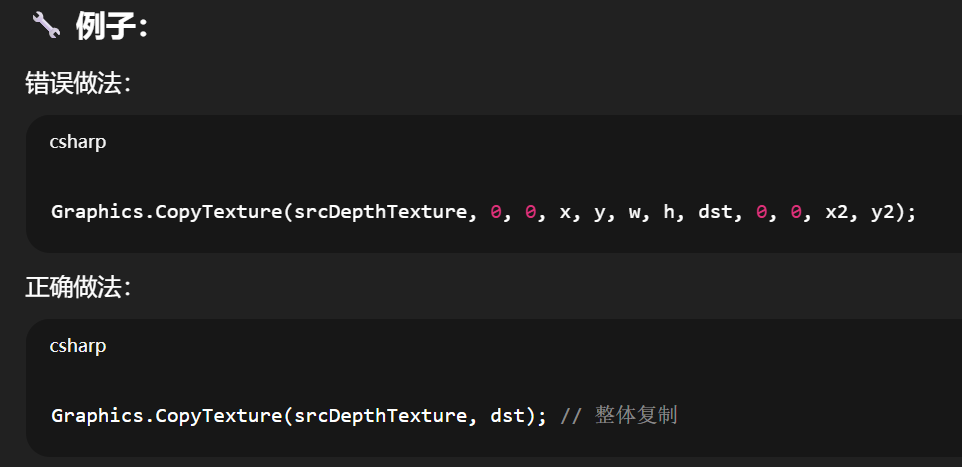
If
srcis a depth-only render target, you must copy the whole texture, not part of it. A depth-only render texture has its color buffer set to a color format ofNoneand its depth buffer set to a valid RenderTexture.depthStencilFormat. A depth graphics texture has its format set to a valid GraphicsFormat with a depth component.使用 QualitySettings.globalTextureMipmapLimit、Texture2D.mipmapLimitGroup 和 Texture2D.ignoreMipmapLimit 时,纹理可以具有各种 mipmap 限制设置。
这意味着你可能无法从一个 mipmap 级别复制到另一个 mipmap 级别,因为例如,源纹理限制为一半分辨率,目标纹理限制为四分之一分辨率。
请注意,当 src 和 dst 设置为图形纹理时,这不适用,因为图形纹理的 mipmap 计数已受到限制,并且仅表示当前上传的 mipmap 级别。
,看不懂啊,,上下文缺少太严重了,一堆莫名其妙的凑在一起直接脑子白了
如果你要拷贝一个只包含深度(没有颜色)的渲染纹理(比如用于阴影贴图),你不能只拷贝其中一部分,而必须一次性整体拷贝整张纹理。
原因是:深度纹理并不像颜色纹理那样支持区域复制(可能牵涉硬件级别的限制和驱动兼容性)。
关于 mipmap 限制造成无法复制的问题
先解释几个关键词:
-
QualitySettings.globalTextureMipmapLimit:系统级 mip 限制(越高越模糊) -
Texture2D.mipmapLimitGroup:可按组限制 mip 级别 -
Texture2D.ignoreMipmapLimit:忽略上述限制
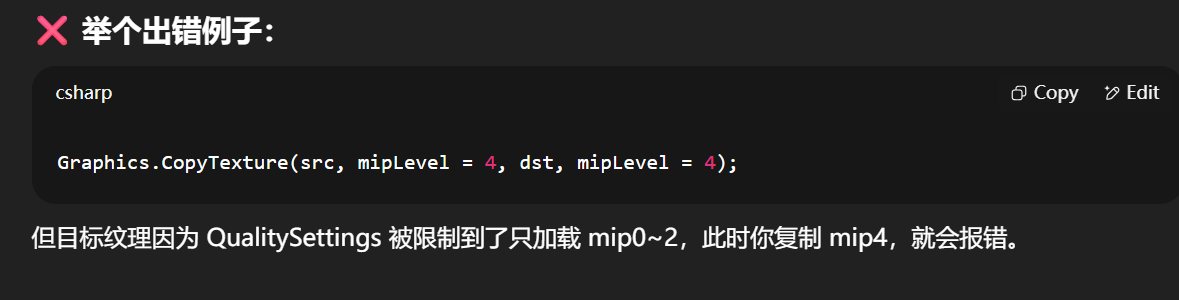
你不能从一个 mipmap 层级复制到另一个 mipmap 层级,如果目标纹理的 mipmap 层级被限制了,而源纹理没有被限制,或者限制程度不一致。
因为此时两者支持的 mipmap 数量不一致,可能源纹理有 5 层 mipmap,目标纹理被系统限制为只有 3 层,就会出错。
RenderTexture 本质是“GPU 上的目标画布”
你写 shader → 得有人接收 shader 输出 → RT 就是那个“接收结果”的画布。
-
📦 当作材质输出目标(比如 camera 渲染进去)
-
🎞 用作图像后处理的中间帧(比如模糊、描边、颜色 grading)
-
🧠 甚至临时做缓存图/lookup表(高度图、深度图、mask等)
| 功能场景 | RenderTexture 的精髓作用 |
|---|---|
| 后处理效果链 | 自定义 camera 渲染到 RT,再自己处理 + 显示 |
| 离屏渲染(offscreen) | 把多个物体渲染到一个 RT,实现小地图、卡牌、物品图标生成 |
| 动态 shadow/depth map | 自建 RT 接收阴影,自己控制 shadow sampling |
| 多 Pass 缓存数据 | 把一帧数据缓存下来,下一帧继续用(流体模拟、模糊叠加) |
| GBuffer模拟 | 自制延迟渲染:color、normal、depth 各输出到独立 RT |
| Graphics.CopyTexture | 用于跨帧、跨通道复制图像或深度,RT 是唯一合法中间体 |
进入 “多个 RT 协作 + CommandBuffer”
如:
-
使用 CommandBuffer 画指定层的物体到某张 RT
-
多个 RT 同时处理数据(比如合成颜色 + 深度 + 脏区)
SRP 框架下的 RT 构造逻辑(如 URP/HDRP)
-
熟悉
RenderTargetIdentifier、ScriptableRenderPass中如何声明 RT -
SRP 下创建 RT 是通过
RenderTextureDescriptor,你可以设置 MSAA、DepthFormat、Mipmap 等
操作意识
-
为什么 RT 必须要设置 format/depth/stencil,它和普通 Texture2D 有什么不同?
-
为什么 Graphics.CopyTexture 不能区域复制 depth-only RT?
-
如何用一张 RT 实现后处理滤镜链条?
-
URP 的
_CameraColorTexture/_CameraDepthTexture是哪一步生成的? -
一个 frame 中有多少 RT 是临时生成并释放的?(这就是优化点)
如何用 RT 保存上帧图像?(做 trailing、流体残影)
在 SRP 中用 RT,为什么要用 Descriptor 而不是 new RenderTexture?
如何用 CommandBuffer 实现“只渲染某个图层到 RT”?
void Update() {var rt = new RenderTexture(...);Graphics.Blit(..., rt);rt.Release();
}
这会让 Unity 每帧都:申请 GPU 显存填充纹理描述符提交渲染命令等 GPU 同步回收资源(甚至不是立即回收)结果:性能直接爆炸RenderTexture 的创建/释放如果不控制,会导致频繁的 CPU→GPU 同步和内存波动,直接影响帧率与流畅度,尤其是在每帧都分配/销毁 RT 时,问题尤为严重。
RenderTexture 的创建在 C# 中,但它实际是 GPU 资源
正确的做法是tr的池用,在c#脚本内创建又销毁,会打断渲染的流程,会造成内存的碎片化
你应该在 RT 使用时:
| 场景 | 方式 |
|---|---|
| 每帧都要使用的 RT | 提前创建一次,重复使用(缓存下来) |
| 分辨率可能变化 | 在分辨率变化时手动销毁并重新创建 |
| 多个 Pass 共享 RT | 建立一个 RT 池,用 key 复用(分辨率+format) |
| 用完之后 | 不要立即 Release,用 rt.DiscardContents() 清空,但保留对象 |

RT 的高级用法之所以重要,不只是你能输出什么图像,而是你是否能掌控它的生命周期、内存占用与渲染节奏。
那也就是说,drawcall可能没有想象的那么需要分开,和cpu
rt的使用,池用,,创建之后传给gpu,通知可以使用者一张rt了,这样的函数
void Update() {var rt = new RenderTexture(...);Graphics.Blit(src, rt);rt.Release();
}代码的实际运行流程(每帧)
[CPU] new RenderTexture() ─────┐
▼
[CPU→GPU] 分配显存 + 建纹理缓冲 ←─(阻塞可能)
▼
[GPU] Blit 渲染 full-screen quad → rt
▼
[CPU] rt.Release()(请求释放)
▼
[Unity 引擎] 进入延迟释放队列(下一帧或合适时机才真正 free)
new RenderTexture(...)
-
C# 层分配一个
RenderTexture对象(托管对象) -
Unity 引擎底层触发 GPU 资源分配命令:
-
调用底层 Graphics API(如 D3D11、Vulkan、Metal)
-
分配显存:开辟一个符合你设置的纹理缓冲区(color/depth/stencil)
-
通常为显卡上的 VRAM 中分配
-
❗这是一个GPU-端资源创建操作,相对昂贵
同时由于 Unity 引擎维护了一个资源生命周期队列,这一步还会 触发资源注册+等待 GPU 命令完成(CPU → GPU 同步)
Graphics.Blit(src, rt)
-
将
src纹理用一个全屏四边形(fullscreen quad)绘制到rt上 -
实际过程:
-
设置
rt为当前RenderTarget -
创建一个内部 command buffer
-
提交绘制命令
-
GPU 开始执行着色器,输出结果到
rt
-
这一阶段 比较快(如果 RT 已缓存好),但因为你刚刚才创建了
rt,GPU 可能仍在“准备”资源 → 有轻微 pipeline stall。
rt.Release()
-
显式释放 GPU 资源(而不是 C# 的
null) -
Unity 会立即将这个
RenderTexture从显存中注销,释放 GPU 缓冲区
❗虽然你显式调用了
.Release(),但并不意味着 GPU 立刻就能回收资源,因为它可能还在 pipeline 中被引用
Unity 只能标记资源待释放,并在合适的时机真正释放(延迟释放)
最影响“延迟”
列出的这几个流程中,如果我们要挑出最影响“延迟”(即卡顿、掉帧、stutter、输入响应变慢等)**的那一块,答案是:
[CPU→GPU] 分配显存 + 建纹理缓冲 ←─(阻塞可能)
📍 为什么这是瓶颈核心?
因为这一阶段涉及的是:
-
Unity C# 层发起资源分配请求
-
Unity 引擎转为底层图形 API 调用(如 D3D12/Vulkan)
-
GPU 需要同步完成显存分配、布局、绑定等操作
-
如果上一个 frame 的渲染还没完成,CPU 可能会阻塞等待 GPU 空闲(pipeline stall)
最直接的后果是:
| 问题 | 表现 |
|---|---|
| GPU 还在前一帧写旧 RT,CPU 却要求新建 RT | CPU 等待 GPU → 主线程卡顿 |
| 显存碎片导致分配慢 | 随机掉帧或不稳定 spike |
| 每帧反复新建新释放 | 带来大量 context 切换和垃圾资源链表处理 |
具体数据支持:
在 Unity Profiler / Frame Debugger / RenderDoc 中你可以看到如下表现:
-
“WaitForRenderThread” 占用增加
-
“RenderTexture.Create()” 阶段耗时上升
-
Profiler 报出 GC spikes / Memory spikes
-
RenderDoc 标红:
glTextureStorage/ID3D11Device::CreateTexture2D时间拉长
对比其他步骤影响程度:
| 步骤 | 延迟影响程度 | 原因说明 |
|---|---|---|
new RenderTexture()(C# 层) | ⚠️ 中低 | 分配托管对象本身不慢,但它触发下一步 |
分配显存 + 建纹理缓冲 | ✅ ✅ 高 | GPU 创建资源最花时间,且需同步 |
Graphics.Blit() | 🟡 中 | GPU 执行 draw call,快,但若资源还未 ready 会 stall |
rt.Release() | 🔘 低 | 标记(仅标记,待后续一次性处理)释放, |
延迟释放队列 | 🟡 中 | 会在某一帧集中释放,产生 GC/GPU spike,但不是每帧 |
所以优化 RenderTexture 的延迟瓶颈,第一要务是:
避免每帧分配 GPU-side RenderTexture(避免动态构建显存资源)
建议你在 Profiler 中重点观察这几个模块:
-
RenderTexture.Create
-
Gfx.WaitForPresentOnGfxThread
-
GC.Alloc
-
GfxDevice.RenderThreadEvents
关于rt.Release()是cpu-->gpu,影响却不大的原因
创建和释放的根本区别在于:
| 行为 | GPU 必须立即执行? | 有无资源争抢? | 会阻塞 CPU? | 表现影响 |
|---|---|---|---|---|
new RenderTexture()(或 .Create()) | ✅ 必须立刻准备可渲染资源 | ✅ 有,需分配显存、建立绑定表 | ✅ 可能阻塞(pipeline stall) | 💥 高延迟风险 |
rt.Release() | ❌ 不立即销毁资源,标记进入延迟释放队列 | ❌ 没有立即资源争用 | ❌ 通常不阻塞 | ✅ 几乎无延迟影响 |
-
你调用
rt.Release()(CPU 标记) -
Unity 内部将其加入一个“待销毁 GPU 资源队列”
-
实际销毁动作由 引擎在后续帧或合适的空闲时间点批量执行(如
GfxDeviceWorker异步线程) -
如果 GPU 当前还在使用这个 RT,Unity 会自动延迟到使用结束后再销毁
意思是说cpu和gpu之间不是像只能同时执行一个,不是说cpu发命令给GPU之后,自己就必须等GPU渲染完才能继续传命令?不存在如果c#里中途叉一条会影响GPU的函数就导致cpu做的事情全部要停下?
默认行为(大多数情况):
-
C# → Unity 渲染线程(Gfx thread) → 生成命令 → 放入 command queue
-
GPU 异步从队列中取命令去执行(比如绘制、采样、贴图绑定)
这意味着:
你在 C# 脚本中写的逻辑、甚至连续多个Graphics.Blit()、CommandBuffer.DrawMesh()等渲染命令,是排队而不是阻塞。
CPU 发完就继续执行自己的逻辑,不会等 GPU 渲染完才继续干活。
那什么时候会强制同步(pipeline stall)?
这就是你关心的重点了!
并不是所有 GPU 指令都是异步的,有些 API 会引起 CPU-GPU 同步阻塞,这些是导致“全部停下”的根本。
常见导致同步的操作:
| 操作 | 为什么同步 |
|---|---|
new Texture2D(...) + Apply() | 必须立即上传像素数据给 GPU |
RenderTexture.Create() | 分配显存、需要 GPU 构造资源描述符 |
Graphics.CopyTexture(...)(跨设备) | 部分平台必须等待 GPU 写完资源才能读 |
AsyncGPUReadback.Request() + 等待结果 | 需要 GPU 读回结果 → 强制 stall CPU 等待 |
访问 RenderTexture.active 并读像素(ReadPixels) | 必须 GPU 渲染完后再拷贝回 CPU → 阻塞 |
| 使用 profiler 的 GPU timing | 为了测 GPU 时间,必须等待 GPU 执行完所有命令 |
📌 这些操作会 打破默认的异步性,会导致 CPU 主线程等待 GPU → 掉帧或卡顿。
纯渲染命令(不会 stall)
Graphics.Blit(rt1, rt2);
Graphics.Blit(rt2, screen);-
两条命令进入 command queue
-
GPU 后台慢慢画
-
CPU 发完继续做别的事情
✅ 完全异步、高效
中途强行访问像素数据
Graphics.Blit(rt1, rt2);
Texture2D tex = new Texture2D(w, h);
RenderTexture.active = rt2;
tex.ReadPixels(...); // 🚨 stall:必须等 rt2 渲染完才能读!中途 CPU 发了一个需要等待 GPU 的命令,就可能导致所有 CPU 工作全部停下”,这确实会发生,但只在你明确调用了会触发同步的 API 时。