计算机基础速通--数据结构·线性表应用
如有问题大概率是我的理解比较片面,欢迎评论区或者私信指正。
考察线性表,核心围绕其存储结构特性、核心操作实现、场景应用选型三大维度,重点检验对基础概念的理解、代码实现能力及问题分析能力,通常会结合算法设计、复杂度分析和实际场景进行考察。
一、基础概念与特性辨析
-
核心定义与逻辑结构
-
问题:“什么是线性表?它与非线性结构(如树、图)的本质区别是什么?” (考察点:线性表 “一对一” 的逻辑关系,区别于树的 “一对多” 和图的 “多对多”)
-
-
两种存储结构的核心差异
-
问题:“顺序表和链表在存储方式、访问效率、插入删除操作上有何本质区别?” (考察点:顺序表的连续空间与随机存取、链表的离散空间与指针依赖;插入删除时 “移动元素” 与 “修改指针” 的效率差异)
-
-
总结
-
顺序表 vs 链表的本质区别
-
顺序表:连续内存、随机访问快(O(1)),增删需移动元素(O(n)),扩容成本高。
-
链表:离散内存、增删快(O(1)),查找需遍历(O(n)),无扩容问题但存储密度低。
“数组和链表分别适合什么场景?为什么数据库索引常用B+树(基于数组)而非链表?”
答:数组适合读多写少(如索引),链表适合频繁增删(如操作历史记录)。 -
二、核心操作的代码实现(边界处理)
(一)顺序表操作
插入与删除
问题1:“编写函数,在顺序表的第 i 个位置插入元素 x,需处理越界、表满等异常。” (关键点:从后往前移动元素(避免覆盖),表长 + 1;时间复杂度分析)
public class SeqList {private int[] data; // 存储元素的数组private int maxSize; // 顺序表最大容量private int length; // 当前元素个数// 初始化顺序表public SeqList(int capacity) {this.maxSize = capacity;this.data = new int[maxSize];this.length = 0;}/*** 在顺序表第i个位置插入元素x* @param i 插入位置(位序从1开始)* @param x 插入元素值* @return 操作是否成功*/
public boolean insert(int i, int x) {// 1. 检查位序有效性if (i < 1 || i > length + 1) {System.err.println("插入位置越界!有效范围:[1, " + (length + 1) + "]");return false;}// 2. 检查表满异常if (length >= maxSize) {System.err.println("顺序表已满!最大容量:" + maxSize);return false;}// 3. 元素后移操作(从后向前移动)for (int j = length-1; j >= i-1; j--) {data[j+1] = data[j]; // 将元素向后移动一位}// 4. 插入新元素data[i - 1] = x; // 数组下标 = 位序 - 1length++; // 更新表长return true;}
}问题2:“删除顺序表中值为 x 的所有元素,要求时间复杂度、空间复杂度
。” (思路:用 k 记录有效元素个数,遍历数组时将非 x 元素前移至 k 位置,最后更新表长)
public class OrderedList {private int[] data; // 存储元素的数组private int length; // 当前元素个数private int capacity; // 列表容量// 初始化顺序表public OrderedList(int capacity) {this.capacity = capacity;this.data = new int[capacity];this.length = 0;}/*** 删除所有值为x的元素(时间复杂度O(n),空间复杂度O(1))* @param x 要删除的目标值* @return 删除的元素数量*/public int removeAll(int x) {int k = 0; // 有效元素指针int count = 0; // 删除计数// 双指针遍历for (int i = 0; i < length; i++) {if (data[i] != x) {// 保留非x元素data[k] = data[i];k++;} else {// 统计删除元素count++;}}// 更新表长length = k;return count;}// 辅助方法:添加元素(测试用)public void add(int value) {if (length < capacity) {data[length] = value;length++;}}// 辅助方法:打印当前列表(测试用)public void print() {System.out.print("[");for (int i = 0; i < length; i++) {System.out.print(data[i]);if (i < length - 1) System.out.print(", ");}System.out.println("]");}
}查找与扩容
问题1:“在有序顺序表中实现折半查找,返回元素位置;若不存在,返回插入位置。” (考察点:二分法的边界控制(low <= high)、循环结束时 low 的含义)
/*** 在有序顺序表中执行折半查找* * @param arr 有序顺序表(升序排列)* @param target 目标元素值* @return 元素位置(从1开始计数),若不存在则返回应插入位置*/
public static int binarySearch(int[] arr, int target) {// 边界检查:空表直接返回插入位置1if (arr == null || arr.length == 0) {return 1;}int low = 0;int high = arr.length - 1;// 关键点1:循环条件必须包含等号(单个元素)while (low <= high) {// 关键点2:防止整数溢出的中间值计算int mid = low + ((high - low) >> 1);if (arr[mid] == target) {// 找到目标值,返回位序(索引+1)return mid + 1;} else if (arr[mid] < target) {// 目标在右半区low = mid + 1;} else {// 目标在左半区high = mid - 1;}}// 关键点3:循环结束时low指向第一个大于target的元素位置return low + 1;
}问题2:“顺序表动态扩容的原理是什么?为什么扩容时通常选择扩大为原容量的 1.5 倍?” (考察点:避免频繁扩容导致的时间开销, amortized 复杂度优化,懒加载策略)
public class ArrayList<E> {/*** 默认初始化空间*/private static final int DEFAULT_CAPACITY = 10;/*** 空元素*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/*** ArrayList 元素数组缓存区*/transient Object[] elementData;private int size;//实际容量// 添加元素触发扩容public boolean add(E e) {// 步骤1:计算最小所需容量int minCapacity = size + 1;// 步骤2:处理首次添加的特殊情况if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}// 步骤3:检查并执行扩容if (minCapacity - elementData.length > 0) {// 3.1 记录当前容量int oldCapacity = elementData.length;// 3.2 计算新容量(1.5倍扩容)int newCapacity = oldCapacity + (oldCapacity >> 1);// 3.3 处理1.5倍不足的情况if (newCapacity - minCapacity < 0) {newCapacity = minCapacity;}// 3.4 创建新数组并复制数据elementData = Arrays.copyOf(elementData, newCapacity);}// 步骤4:安全添加元素elementData[size++] = e;return true;}
(二)链表操作
单链表基础操作
问题1:“带头结点的单链表中,实现第 i 个位置插入元素;若 i=1,操作和其他位置有何不同?” (关键点:头结点的作用 —— 统一插入逻辑,无需特殊处理 i=1;指针修改顺序:先连新结点,再断原链)
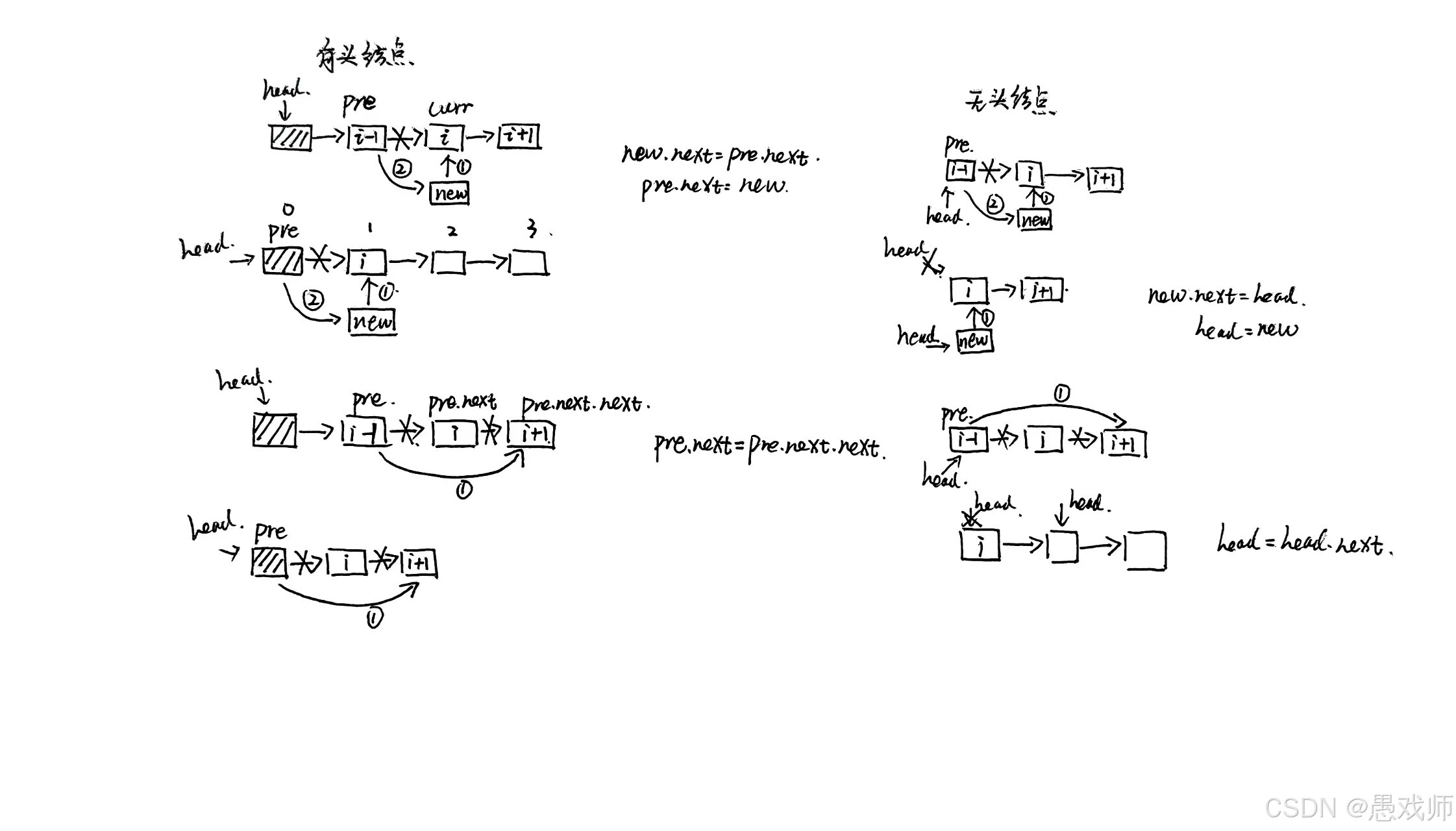
class LinkedListWithHead {private Node head; // 头指针始终指向头结点(哨兵结点)public LinkedListWithHead() {head = new Node(-1); // 创建头结点(哨兵结点),数据域通常无效}// 在位置 i 插入元素public boolean insert(int i, int data) {if (i < 1) return false; // 位置无效检查Node pre = head; // 从头结点开始// 寻找第 i-1 个结点(插入位置的前驱)for (int pos = 0; pos < i - 1; pos++) {if (pre.next == null) break; // 提前到达链表末尾pre = pre.next;}if (pre == null) return false; // 前驱结点无效Node newNode = new Node(data); // 创建新结点newNode.next = pre.next; // 新结点指向原位置结点pre.next = newNode; // 前驱指向新结点return true;}// 删除位置 i 的元素public boolean delete(int i) {if (i < 1 || head.next == null) return false; // 位置无效或链表为空Node pre = head; // 从头结点开始// 寻找第 i-1 个结点(删除位置的前驱)for (int pos = 0; pos < i - 1; pos++) {if (pre.next == null) break; // 提前到达链表末尾pre = pre.next;}if (pre.next == null) return false; // 要删除的结点不存在pre.next = pre.next.next; // 跳过要删除的结点return true;}// 查找元素public int find(int data) {int position = 1;Node current = head.next; // 从第一个实际结点开始while (current != null) {if (current.data == data) {return position; // 找到元素,返回位置}current = current.next;position++;}return -1; // 未找到}// 获取链表字符串表示public String getListString() {StringBuilder sb = new StringBuilder("Head → ");Node current = head.next; // 跳过头结点while (current != null) {sb.append(current.data);if (current.next != null) sb.append(" → ");current = current.next;}sb.append(" → NULL");return sb.toString();}
}class LinkedListWithoutHead {private Node head; // 直接指向第一个实际结点(可能为null)public LinkedListWithoutHead() {head = null; // 初始化为空链表}// 在位置 i 插入元素public boolean insert(int i, int data) {if (i < 1) return false; // 位置无效检查// 特殊处理 i=1 的情况if (i == 1) {Node newNode = new Node(data);newNode.next = head; // 新结点指向原头结点head = newNode; // 更新头指针return true;}Node pre = head; // 从第一个结点开始// 寻找第 i-1 个结点for (int pos = 1; pos < i - 1; pos++) {if (pre == null) break; // 提前结束pre = pre.next;}if (pre == null) return false; // 前驱结点无效Node newNode = new Node(data);newNode.next = pre.next; // 新结点指向原位置结点pre.next = newNode; // 前驱指向新结点return true;}// 删除位置 i 的元素public boolean delete(int i) {if (i < 1 || head == null) return false; // 位置无效或链表为空// 特殊处理 i=1 的情况if (i == 1) {head = head.next; // 头指针指向第二个结点return true;}Node pre = head; // 从第一个结点开始// 寻找第 i-1 个结点for (int pos = 1; pos < i - 1; pos++) {if (pre.next == null) break; // 提前结束pre = pre.next;}if (pre.next == null) return false; // 要删除的结点不存在pre.next = pre.next.next; // 跳过要删除的结点return true;}// 查找元素public int find(int data) {int position = 1;Node current = head; // 从第一个实际结点开始while (current != null) {if (current.data == data) return position;current = current.next;position++;}return -1; // 未找到}// 获取链表字符串表示public String getListString() {if (head == null) return "NULL"; // 空链表StringBuilder sb = new StringBuilder();Node current = head;while (current != null) {sb.append(current.data);if (current.next != null) sb.append(" → ");current = current.next;}sb.append(" → NULL");return sb.toString();}
}单链表有无头节点操作细节总结:
查找:
Node current = head.next; // 从第一个实际结点开始
Node current = head; // 从第一个实际结点开始删除:
if (i < 1 || head.next == null) return false; // 位置无效或链表为空
if (i < 1 || head == null) return false; // 位置无效或链表为空 Node pre = head; // 从头结点开始// 寻找第 i-1 个结点(插入位置的前驱)for (int pos = 0; pos < i - 1; pos++) {if (pre.next == null) break; // 提前到达链表末尾pre = pre.next;}if (pre == null) return false; // 前驱结点无效Node pre = head; // 从第一个结点开始// 寻找第 i-1 个结点for (int pos = 1; pos < i - 1; pos++) {if (pre == null) break; // 提前结束pre = pre.next;}if (pre == null) return false; // 前驱结点无效 pre.next = pre.next.next; // 跳过要删除的结点// 特殊处理 i=1 的情况if (i == 1) {head = head.next; // 头指针指向第二个结点return true;}pre.next = pre.next.next; // 跳过要删除的结点插入:
if (i < 1) return false; // 位置无效检查Node pre = head; // 从头结点开始// 寻找第 i-1 个结点(插入位置的前驱)for (int pos = 0; pos < i - 1; pos++) {if (pre.next == null) break; // 提前到达链表末尾pre = pre.next;}if (pre == null) return false; // 前驱结点无效if (i < 1) return false; // 位置无效检查Node pre = head; // 从第一个结点开始// 寻找第 i-1 个结点for (int pos = 1; pos < i - 1; pos++) {if (pre == null) break; // 提前结束pre = pre.next;}if (pre == null) return false; // 前驱结点无效 newNode.next = pre.next; // 新结点指向原位置结点pre.next = newNode; // 前驱指向新结点// 特殊处理 i=1 的情况if (i == 1) {Node newNode = new Node(data);newNode.next = head; // 新结点指向原头结点head = newNode; // 更新头指针return true;}newNode.next = pre.next; // 新结点指向原位置结点pre.next = newNode; // 前驱指向新结点问题2:“删除单链表中值为 x 的所有结点,如何避免内存泄漏?” (思路:用前驱指针 pre 遍历,找到目标结点后,pre->next 指向其后继,释放当前结点)
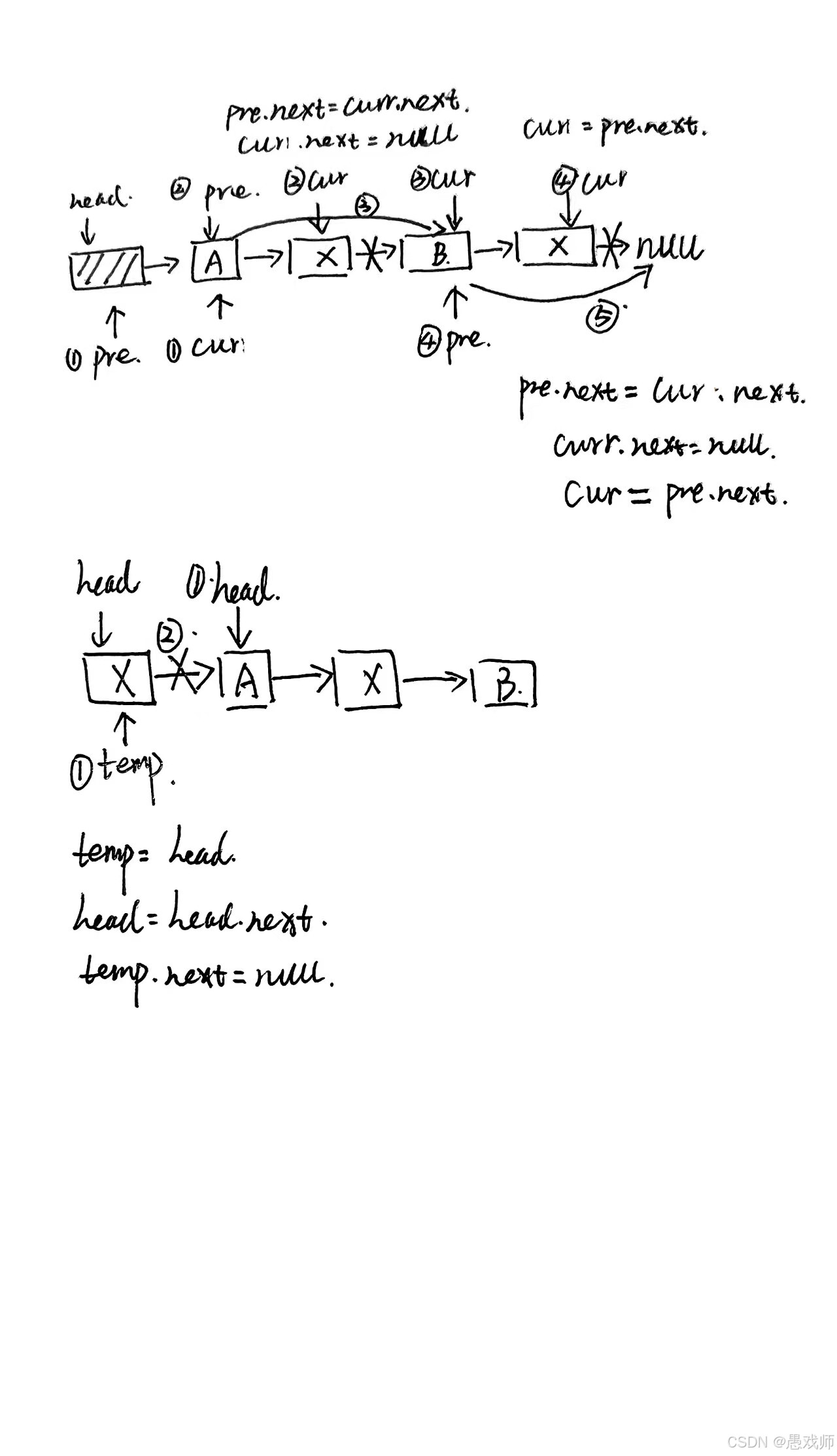
// 带头结点链表中删除所有值为 x 的结点
public void deleteAll(int x) {Node pre = head; // 前驱指针指向头结点Node cur = head.next; // 当前指针指向第一个实际结点while (cur != null) {if (cur.data == x) {// 找到目标结点pre.next = cur.next; // 前驱指针跳过当前结点// 释放内存(在Java中置为null帮助GC,在C++中需要delete)cur.next = null; // 断开引用cur = pre.next; // 移动当前指针到下一个结点} else {// 非目标结点,双指针一起移动pre = cur;cur = cur.next;}}
}// 无头结点链表中删除所有值为 x 的结点
public void deleteAll(int x) {// 特殊情况:删除开头连续的目标结点while (head != null && head.data == x) {Node temp = head;head = head.next;temp.next = null; // 断开引用}if (head == null) return; // 链表为空Node pre = head;Node cur = head.next;while (cur != null) {if (cur.data == x) {pre.next = cur.next; // 前驱指针跳过当前结点cur.next = null; // 断开引用cur = pre.next; // 移动当前指针} else {pre = cur;cur = cur.next;}}
}内存泄漏分析及避免方法
| 操作 | 内存泄漏风险 | 正确做法 |
|---|---|---|
| 未断开引用 | 被删除结点仍被其他对象引用 | 将被删除结点的 next 置为 null |
| 未释放内存 | 已删除结点仍占用内存空间 | 在C++中使用 delete,在Java中依赖GC |
| 指针处理错误 | 链表断裂,无法访问后续结点 | 使用双指针技术确保链表连续性 |
| 头指针处理不当 | 删除头结点后未更新头指针 | 单独处理链表开头连续的目标结点 |
双链表与循环链表
问题1:“双链表中,在 p 所指结点后插入 s 结点,需修改哪些指针?” (步骤:s->next = p->next;p->next->prior = s;s->prior = p;p->next = s)
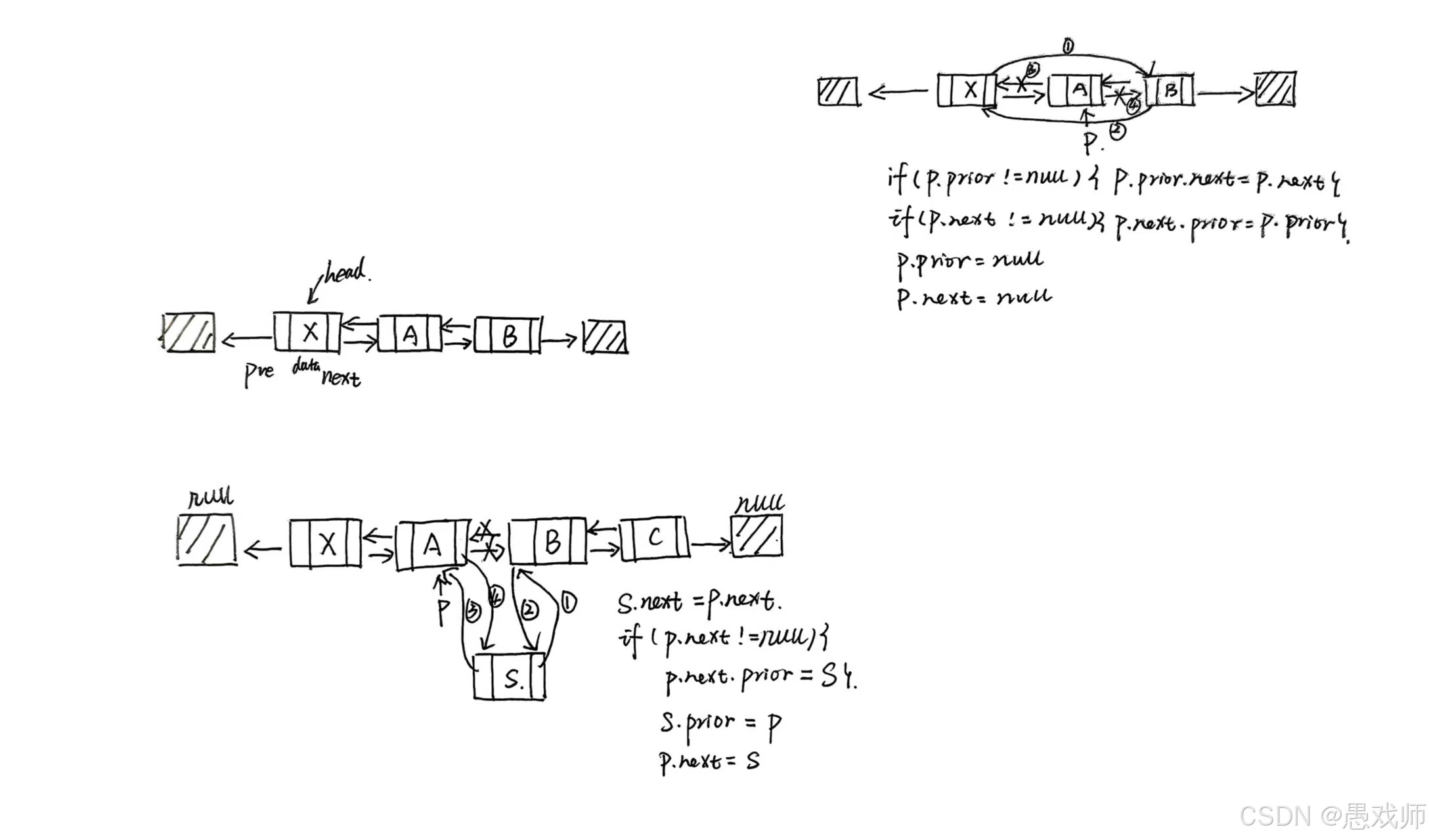
public class DLinkedList<T> {// ... 省略其他代码/*** 在节点 p 后插入新节点* @param p 目标节点(不能为 null)* @param data 新节点的数据* @return 插入成功返回 true,失败返回 false*/public boolean insertAfter(DNode<T> p, T data) {if (p == null) return false; // p 无效DNode<T> s = new DNode<>(data); // 创建新节点 s// 核心步骤:s.next = p.next; // 1. s 的 next 指向 p 的原后继if (p.next != null) {p.next.prior = s; // 2. 如果 p 有后继,其 prior 指向 s(文档:p->next->prior=s)}s.prior = p; // 3. s 的 prior 指向 pp.next = s; // 4. p 的 next 指向 sreturn true;}
}public class DLinkedList<T> {// ... 省略其他代码/*** 删除节点 p* @param p 要删除的节点(不能为 null 或头结点)* @return 删除成功返回 true,失败返回 false*/public boolean deleteNode(DNode<T> p) {if (p == null || p == head) return false; // 禁止删除头结点或无效节点// 核心步骤:if (p.prior != null) {p.prior.next = p.next; // 1. 前驱节点的 next 指向 p 的后继}if (p.next != null) {p.next.prior = p.prior; // 2. 后继节点的 prior 指向 p 的前驱}// 清理引用,避免内存泄漏p.prior = null;p.next = null;return true;}
}public class DLinkedList<T> {// ... 省略其他代码// 后向遍历(从头结点后的第一个节点开始)public void traverseForward() {DNode<T> p = head.next; // 跳过头结点while (p != null) {System.out.print(p.data + " "); // 处理节点(如打印)p = p.next; // 移动到后继}System.out.println();}// 前向遍历(需先定位到尾节点,然后从尾到头)public void traverseBackward() {// 先找到尾节点(需遍历整个链表)DNode<T> tail = head.next;while (tail != null && tail.next != null) {tail = tail.next;}// 从尾节点开始前向遍历(跳过头结点)DNode<T> p = tail;while (p != null && p != head) { System.out.print(p.data + " ");p = p.prior; // 移动到前驱}System.out.println();}
}问题2:“循环单链表相比单链表有何优势?如何判断循环链表为空或满?” (考察点:首尾相连,适合环形场景(如约瑟夫问题);判空:头结点 next 指向自身;判满:需额外标志或牺牲一个节点)
// 定义链表结点类,存储数据和下一个结点指针
class LNode<T> {T data; // 结点数据LNode<T> next; // 指向下一个结点的指针public LNode(T data) {this.data = data;this.next = null; // 初始化时next为null,在链表中会被设置}
}// 定义循环单链表类
public class CircularLinkedList<T> {private LNode<T> head; // 头结点(不存储数据,用于标记链表起始)private int size; // 当前链表大小(额外标志,用于判满)private int maxSize; // 链表最大容量(设置判满条件)// 初始化链表:创建头结点,并使其next指向自身(形成环)public CircularLinkedList(int maxSize) {this.head = new LNode<>(null); // 头结点data为nullthis.head.next = this.head; // 关键:next指向自身,表示空表this.size = 0;this.maxSize = maxSize; // 设置最大容量(用于判满)}// 判断链表是否为空:头结点的next指向自身public boolean isEmpty() {return head.next == head;}// 判断链表是否为满:基于size变量(额外标志)public boolean isFull() {return size >= maxSize; // size达到maxSize时为满}// 添加结点到链表尾部(示例操作,展示环形遍历)public void append(T data) {if (isFull()) {throw new IllegalStateException("LinkedList is full. Cannot append.");}LNode<T> newNode = new LNode<>(data);if (isEmpty()) {// 空表:新结点next指向头结点,头结点next指向新结点newNode.next = head;head.next = newNode;} else {// 非空表:找到尾结点(尾结点的next指向头结点),插入新结点LNode<T> current = head.next;while (current.next != head) { // 遍历到尾结点current = current.next;}current.next = newNode; // 尾结点指向新结点newNode.next = head; // 新结点指向头结点,维持环状}size++; // 更新大小}// 示例:打印链表(展示环形访问)public void printList() {if (isEmpty()) {System.out.println("LinkedList is empty.");return;}LNode<T> current = head.next;System.out.print("Circular List: ");do {System.out.print(current.data + " -> ");current = current.next;} while (current != head); // 循环直到回到头结点System.out.println("(head)"); // 表示环闭合}// 主方法:测试判空、判满和环形场景public static void main(String[] args) {// 初始化链表,设置最大容量为3(用于判满)CircularLinkedList<Integer> list = new CircularLinkedList<>(3);// 测试判空System.out.println("Is empty? " + list.isEmpty()); // 输出: true// 添加结点list.append(1);list.append(2);list.append(3);list.printList(); // 输出: Circular List: 1 -> 2 -> 3 -> (head)// 测试判满System.out.println("Is full? " + list.isFull()); // 输出: true// 尝试添加更多结点(会抛异常)try {list.append(4); // 抛出 IllegalStateException} catch (IllegalStateException e) {System.out.println("Error: " + e.getMessage());}}
}背景:约瑟夫环问题(Josephus problem)是一个著名的理论和计算机科学问题:n个人围成一圈,从第一个人开始报数,每数到k的人被淘汰出局,然后从下一个人重新开始报数,如此循环,直到最后剩下一个人为止。这个幸存者在初始圆环中的位置即为约瑟夫问题的解。
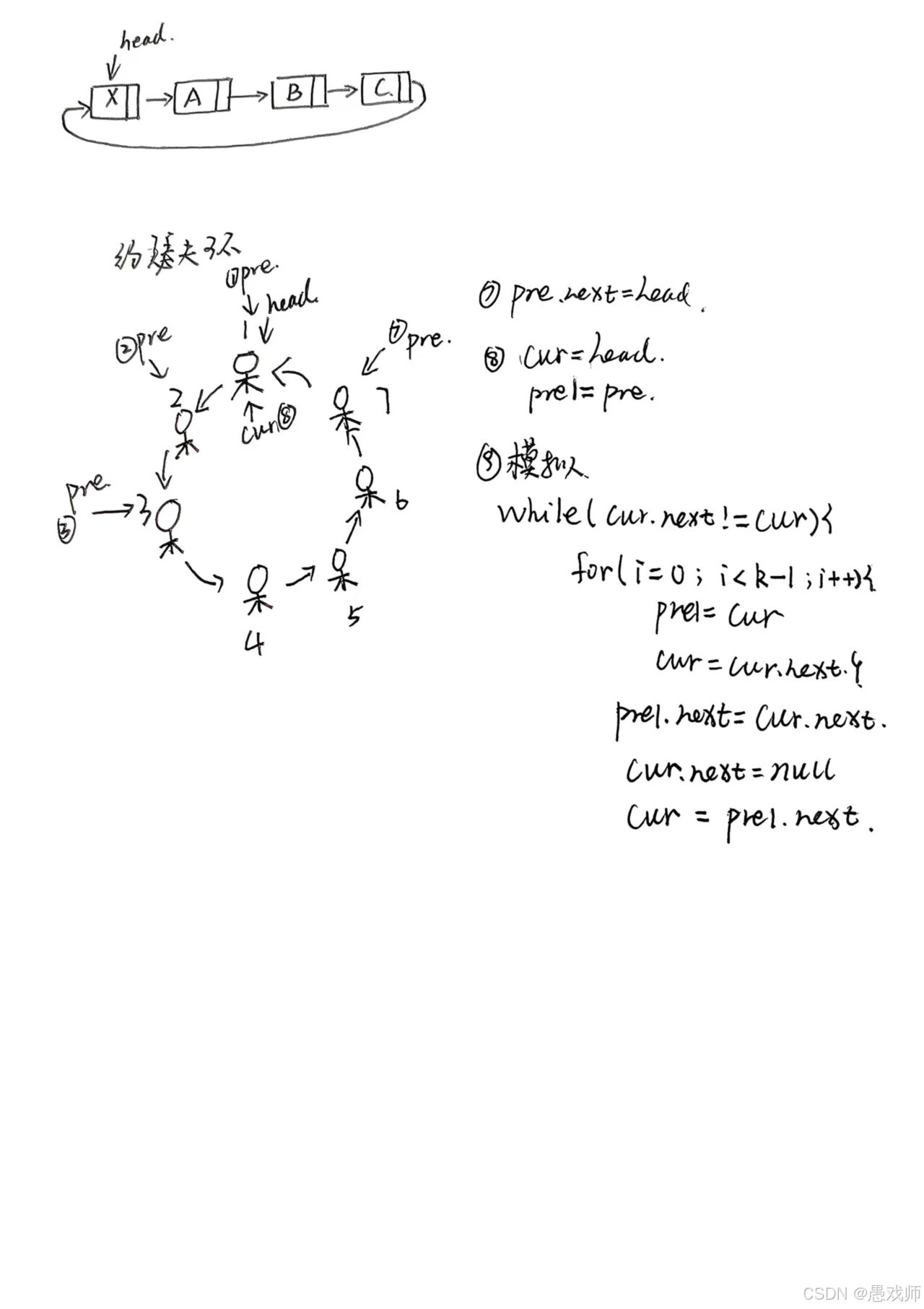
class Node {int data;Node next;public Node(int data) {this.data = data;this.next = null;}
}public class JosephusProblem {public static int josephus(int n, int k) {if (n <= 0 || k <= 0) {throw new IllegalArgumentException("n and k must be positive integers");}// 创建循环链表Node head = new Node(1);Node prev = head;for (int i = 2; i <= n; i++) {prev.next = new Node(i);prev = prev.next;}prev.next = head; // 形成环Node current = head;Node previous = prev; // 前驱节点// 当链表中不止一个节点时while (current.next != current) {// 报数:移动k-1步(从1开始计数)for (int i = 0; i < k - 1; i++) {previous = current;current = current.next;}// 移除当前节点previous.next = current.next;current = previous.next; // 从下一个节点重新开始}return current.data; // 最后剩下的节点}public static void main(String[] args) {int n = 7; // 总人数int k = 3; // 报数到k的人出列int survivor = josephus(n, k);System.out.println("最后剩下的人的编号是: " + survivor);}
}链表的特殊操作
问题1:“反转单链表(就地逆置),要求空间复杂度。” (思路:用 prev、curr、next 三个指针迭代反转,避免递归栈开销)
206. 反转链表 - 力扣(LeetCode)
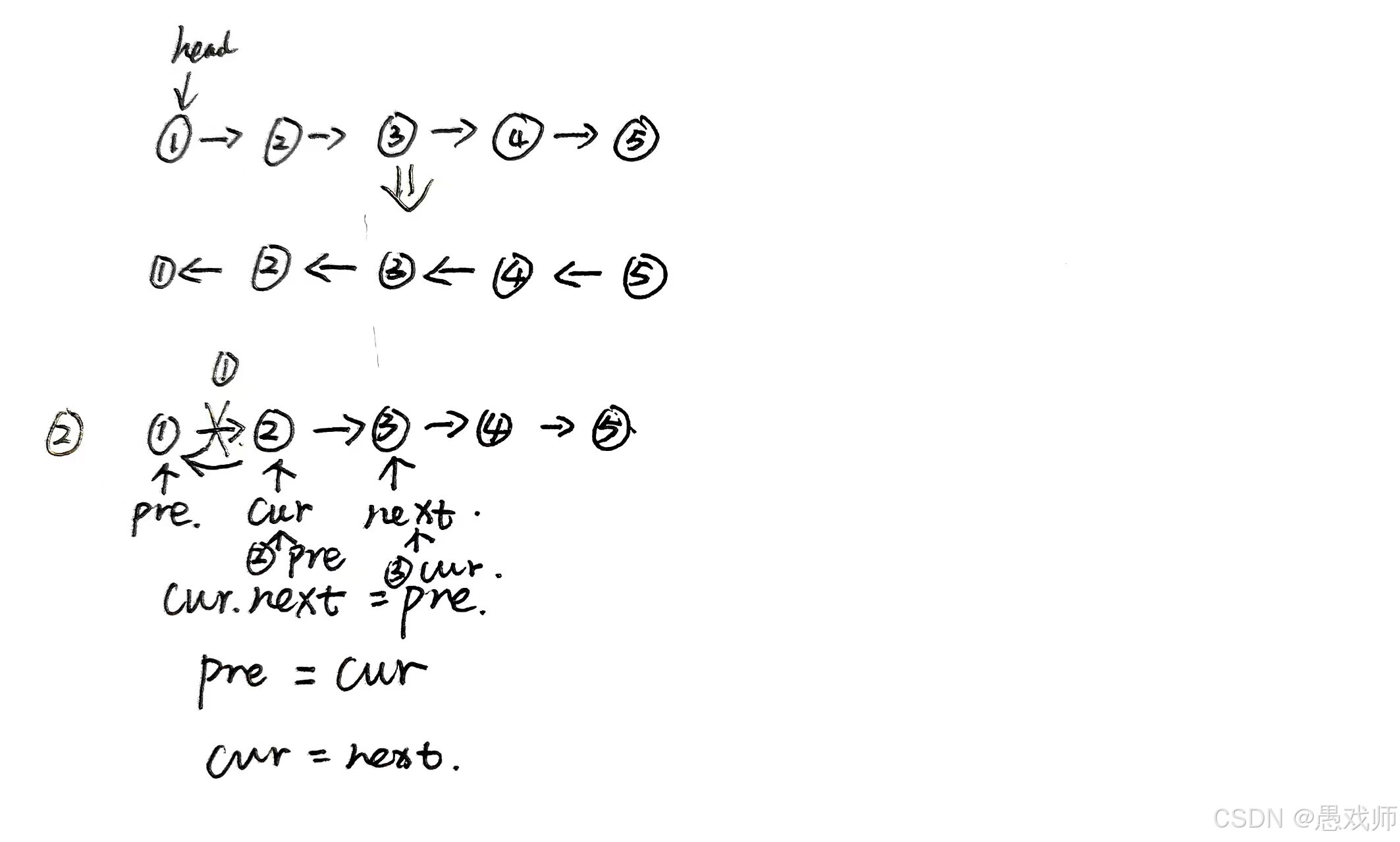
class Solution {public ListNode reverseList(ListNode head) {ListNode cur=head;ListNode pre=null;ListNode next=null;while(cur!=null){next=cur.next;cur.next=pre;pre=cur;cur=next;}return pre;}
}问题2:“判断单链表是否有环?若有环,如何找到环的入口?” (快慢指针法:快指针每次 2 步,慢指针 1 步,相遇则有环;再从表头和相遇点同步走,交点即为入口)
141. 环形链表 - 力扣(LeetCode)
//双指针法
public class Solution {public boolean hasCycle(ListNode head) {ListNode slow=head;ListNode fast=head;while(fast!=null && fast.next!=null){slow=slow.next;fast=fast.next.next;if(slow==fast)return true;}return false;}
}142. 环形链表 II - 力扣(LeetCode)
ListNode detectCycle(ListNode head) {if (head == null) return null;// 步骤1:判断是否有环并记录相遇点ListNode slow = head;ListNode fast = head;boolean hasCycle = false;while (fast != null && fast.next != null) {slow = slow.next;fast = fast.next.next;if (slow == fast) {hasCycle = true;break;}}// 无环则返回nullif (!hasCycle) return null;// 步骤2:重置慢指针到链表头slow = head;// 步骤3:同步移动直至相遇while (slow != fast) {slow = slow.next;fast = fast.next; // 快指针改为每次1步}return slow; // 相遇点即环入口
}三、场景应用与选型
1.存储结构选型
问题:“当需要频繁按序号访问元素时,选顺序表还是链表?当需要频繁在中间位置插入删除时,选哪种?为什么?” (考察点:顺序表随机存取O(1)适合高频访问;链表插入删除O(1)已知前驱)适合高频修改)
实际场景设计
问题:“设计一个通讯录系统,支持添加、删除、查询联系人,应采用顺序表还是链表?说明理由。” (考察点:通讯录数据量动态变化(适合链表)、查询频率(若按姓名查询,两种结构差异不大;若按索引,顺序表更优))
2. 手写算法实现
考察目的:考察编码能力和边界处理。
删除链表中重复元素(有序链表)83. 删除排序链表中的重复元素 - 力扣(LeetCode)
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode deleteDuplicates(ListNode head) {ListNode cur=head;while(cur!=null && cur.next!=null){if(cur.val==cur.next.val){cur.next=cur.next.next;}else{cur=cur.next;}}return head;}
}关键点:双指针遍历。
3. 复杂问题与优化
考察目的:考察算法设计思维和优化能力。
(1) 合并两个有序链表(LeetCode 21)21. 合并两个有序链表 - 力扣(LeetCode)
思路:虚拟头节点简化边界处理。
class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {//虚拟头节点ListNode head=new ListNode(-1);ListNode cur=head;while(list1!=null && list2!=null){if(list1.val<=list2.val){cur.next=list1;list1=list1.next;}else{cur.next=list2;list2=list2.next;}cur=cur.next;}cur.next=(list1==null)?list2:list1;return head.next;}
}
4. 场景应用题
考察目的:将线性表应用于实际问题。
Q:设计一个支持高效插入、删除和随机访问的数据结构(LeetCode 380)。
A:使用 哈希表 + 动态数组:
数组存储元素,支持O(1)随机访问。
哈希表存储元素到数组下标的映射,支持O(1)插入/删除。