学习笔记:原子操作与锁以及share_ptr的c++实现
原子操作
原子操作就是在一个线程进行这个操作时,别的线程只能看到这个操作实现前或实现后,别的线程不能访问也不能看到这个操作进行一半的样子,这个相对来说比较通俗,官方一点讲原子操作是指在多线程或并发环境中,一个操作不可被中断地完成,要么全部执行成功,要么完全不执行。这种操作能够避免竞态条件(Race Condition)和数据不一致问题。
在c/c++编程过程中实现原子操作我会介绍三种方法:
一是直接加互斥锁,互斥锁上锁后别的线程将不再可以访问上锁的部分,同时线程访问到上锁部分会进入休眠
二是上自旋锁,自旋锁与互斥锁不同的地方在于,自旋锁上锁的部分被访问到时线程不会休眠,而是进入不断地循环访问这一部分的状态,直到解锁
三是使用原子变量,这将是本文重点介绍的部分,原子变量的操作都是原子性的,所以不用上锁也能实现原子操作
单处理器单核实现原子操作
单处理器单核只需要保证操作指令不被打断即可,在硬件上已经实现了底层的自旋锁。
多处理器多核实现原子操作
多处理器多核需要避免其他核心访问内存,就要引入锁(下面也会介绍一下内存和缓存布局),锁上需要阻止其他核心访问的空间。
存储体系结构
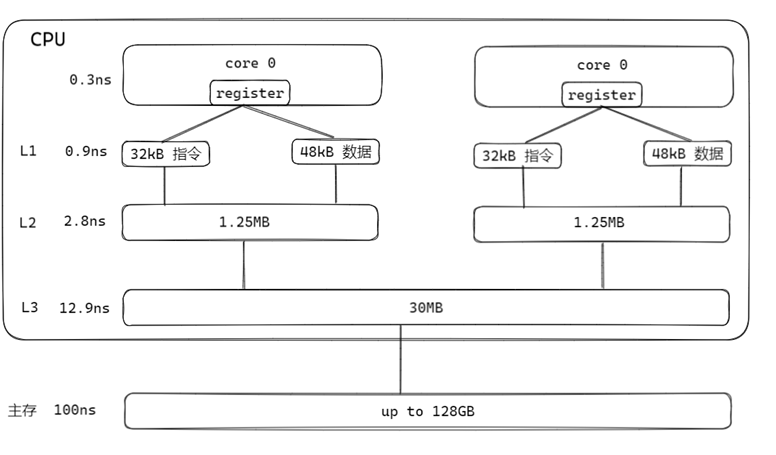
cpu缓存结构如上图,这个是一个多核处理器,L1,L2,L3是处理器的缓存部分,缓存部分的单位cache line如下图
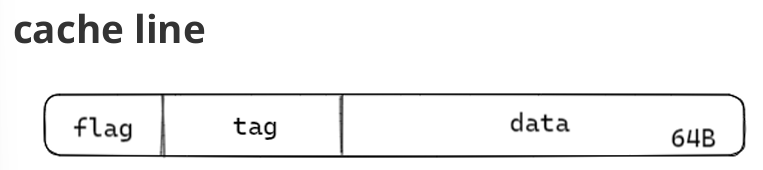
缓存存在的意义是什么呢,有些数据是频繁使用的,如果把这些数据放在缓存中的话,存取速度就会很快,很节约时间,如果什么数据都要从主存中存取的话很浪费时间,所以缓存又很有必要了,下面我们介绍一下读写数据的策略
写回策略
写:
如果在缓存空间有空闲空间的话,直接写入缓存中,并标记为脏,这里的脏意味着只存在在缓存中,没有保存到主存里;如果没有空闲的缓存块,利用LRU算法即最近最久未使用算法来选出要写入的缓存块,如果缓存块本来标记为脏,则把原来数据刷进主存,再将数据写入;如果原来不为脏,则直接写入,并标记为脏。
读:
如果缓存中有目标数据,则直接读出即可;如果没有,则从主存中找到目标数据,再使用LRU找到替换的缓存块,如果原来标记为脏,则先把原数据刷入主存,再把目标数据写入缓存,标记为非脏;如果原来为非脏,直接替换即可。
但是这里有问题了,写回策略会导致缓存中一个变量的值和主存中保存的不一致,所以我们就有了MESI一致性协议
MESI一致性协议
该协议把缓存块划分为四类
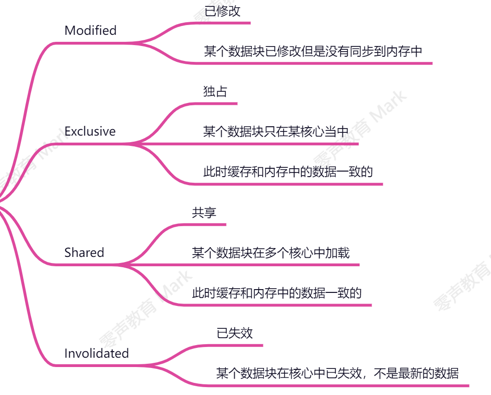
写后锁住ME状态,避免相关内存访问。这样就解决了缓存一致性问题。
内存序
内存序简单理解就是我们的代码顺序在被编译之后执行顺序可能不是我们写的代码的顺序,编译器会优化执行顺序来加快程序运行,这里我们要介绍几个内存序的模型:
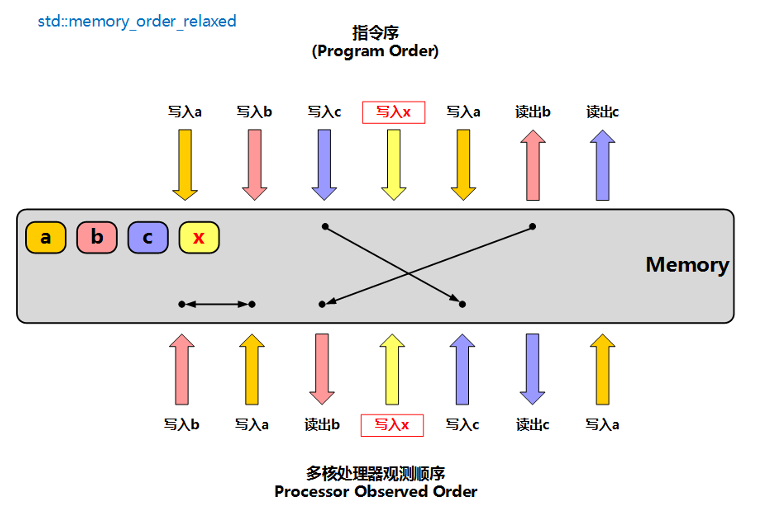
memory_order_relaxed
松散内存序,只用来保证对原子对象的操作是原子的,在不需要保证顺序时使用,这个内存序只保证原子,不保证序列,运行速度最快
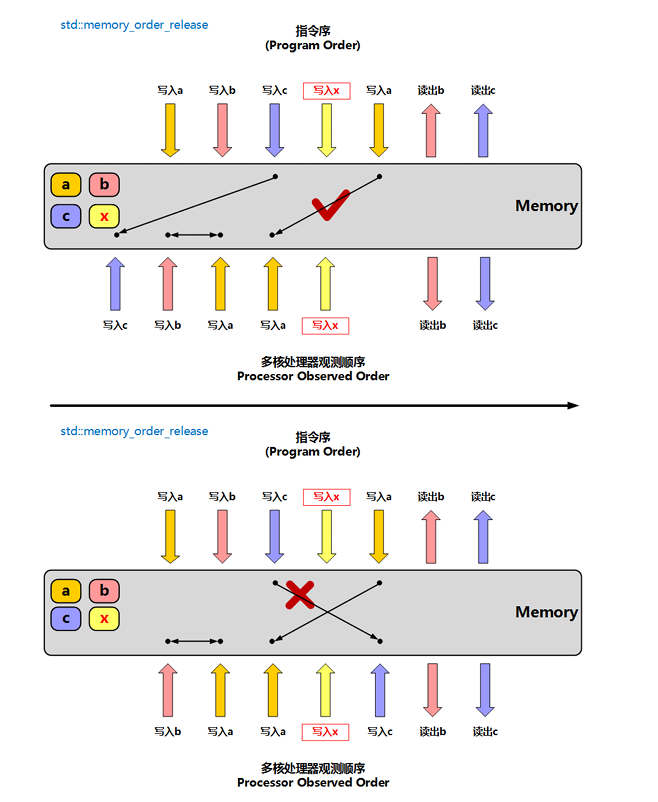
memory_order_release
释放操作,在写入某原子对象时, 当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见;通常与 memory_order_acquire 或 memory_order_consume 配对使用;
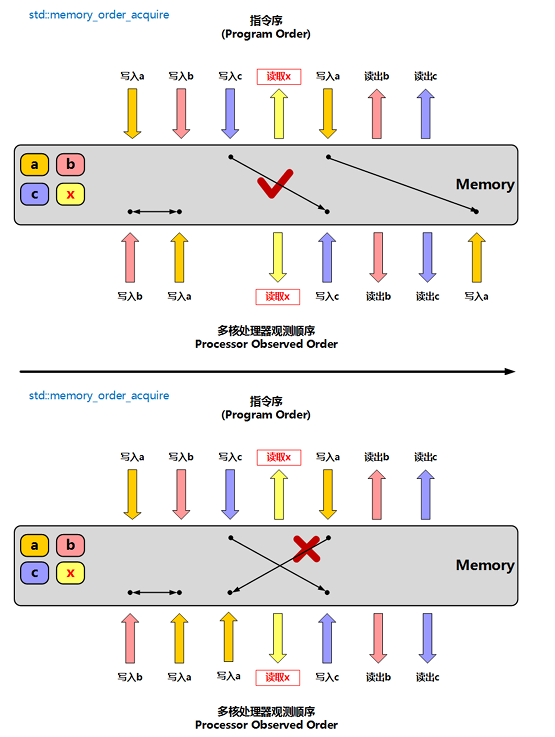
memory_order_acquire
获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面 去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见;
memory_order_consume
同 memory_order_acquire 类 似,区别是它仅对依赖于该原子变量操作涉及的对象,比如这个 操作发生在原子变量 a 上,而 s = a + b;那 s 依赖于 a,但 b 不 依赖于 a;当然这里也有循环依赖的问题,例如:t = s + 1,因 为 s 依赖于 a,那 t 其实也是依赖于 a 的;在大多数平台上,这 只会影响编译器的优化;不建议使用;
memory_order_acq_rel
获得释放操作,一个读‐修改‐写操作 同时具有获得语义和释放语义,即它前后的任何读写操作都不允 许重排,并且其他线程在对同一个原子对象释放之前的所有内存 写入都在当前线程可见,当前线程的所有内存写入都在对同一个 原子对象进行获取的其他线程可见;
memory_order_seq_cst
顺序一致性语义,对于读操作相当 于获得,对于写操作相当于释放,对于读‐修改‐写操作相当于获 得释放,是所有原子操作的默认内存序,并且会对所有使用此模 型的原子操作建立一个全局顺序,保证了多个原子变量的操作在 所有线程里观察到的操作顺序相同,当然它是最慢的同步模型。用人话来说就是代码怎么写就怎么运行,不进行任何优化。
c/c++实现shared_ptr
学习了原子性,原子操作,和内存序,那么下面让我们进入实战环节完成一个shared_ptr,首先我们直到这是一个智能指针,内部有一个control block,会进行引用计数,当计数归零时释放指针
要求:
1.不考虑删除器和空间配置器
2.不考虑弱引用
3.考虑引用计数的线程安全
4.提出测试案例
数据成员细节
private:T *ptr_;std::atomic<std::size_t>* ref_count_;ref_count_设计为原子变量,这样使用时满足了原子性同时后续可以以考虑内存序的问题。
所需接口
那么先让我们来思考完成一个shared_ptr需要哪些接口呢
构造函数
shared_ptr() : ptr_(nullptr) , ref_count_(nullptr) {}explicit shared_ptr(T*& ptr) : ptr_(ptr) , ref_count_(ptr ? new std::atomic<std::size_t>* (1) : nullptr) {}这是最基本的构造一个空指针
析构函数
~shared_ptr(){release();}
private:void release() {if(ptr_ && ref_count_->fetch_sub(1,std::memory_order_acq_rel) == 1) {delete ptr_;delete ref_count_;}}析构函数依赖一个release接口,实现当ref_count_归零时释放指针,正常调用将ref_count_减一即可
这里要注意ref_count_调用fetch_sub是,返回的是运算前的值,所以这里需要==1,同时这里的内存序选择的是memory_order_acq_rel,因为--操作需要注意是否到0,所以不能是随意顺序的--,--完后写入ref_count_所以需要release,同时这个函数有个返回值的动作,从内存中读取数据,需要acquire,所以内存序选择memory_order_acq_rel。
拷贝构造函数
shared_ptr(const shared_ptr<T>& other) : ptr_(other.ptr_),ref_count_(other.ref_count_) {if(ref_count_) {ref_count_->fetch_add(1,std::memory_order_relaxed);}} 用初始化列表赋值后,只需要检验 _ref_count_是否存在,存在++即可,这里的内存序是memory_order_relaxed,因为++操作没有顾虑,直接加就行。
拷贝赋值运算符
shared_ptr<T>& operator=(const shared_ptr<T>& other){if(this != other) {release();ptr_ = other.ptr_;ref_count_ = other.ref_count_;if(ref_count_) {ref_count_->fetch_add(1,std::memory_order_relaxed);}}return *this;}注意考虑自赋值,拷贝赋值主要实现的是引用传入的指针,释放原本的指针,所以先release,然后赋值进来即可,最后把指针return出去
移动构造函数
shared_ptr<T>(shared_ptr<T>&& other) noexcept : ptr_(other.ptr_),ref_count_(other.ref_count_) {other.ptr_ = nullptr;other.ref_count_ = nullptr;}移动构造则是全面接管传图的指针,要将对方置为NULL才可 ,noexprct是指该模块不会产生错误,让编译器编译的执行结构运行更快。
移动赋值运算符
shared_ptr<T>& operator=(shared_ptr<T>&& other) noexcept {if(this != other) {release();ptr_ = other.ptr_;ref_count_ = other.ref_count_;other.ptr_ = nullptr;other.ref_count_ = nullptr;}return *this;}和拷贝赋值一样,不过要将对方置为NULL,这种情况下,就不需要考虑引用计数增加的情况
解引用,箭头运算符
//*p1T& operator*() const{return *ptr_;}//p1->T* operator->() const{return ptr_;}
需要解引用就解完给,需要指针就直接给。
这里要解释const,有个口诀左定值右定向,即目前使用的const将不能改变指针指向,在左边出现的话将不能改变指针指向的值但可以改变指向
引用计数,原始指针,重置指针
std::size_t use_count() const{return ref_count_ ? ref_count_->load(std::memory_order_acquire) : 0;}T* get() const{return ptr_;}void reset(T* p = nullptr){release();ptr_ = p;ref_count_ = ptr_ ? new std::atomic<std::size_t>* (1) : 0;}要值给值,这里使用acquire是取出值,要原指针就返回指针,重置的话先release,再判断是否有ref_count_,有则置1,无则置0。
更多资料在:https://github.com/0voice查询