OCC任务新SOTA!华科提出SDGOCC:语义深度双引导的3D占用预测框架(CVPR 2025)
引入
对周围环境的精确三维感知是自动驾驶系统和机器人技术的基石,可确保高效的规划和安全的控制。近年来,工业界和学术界已经极大推动了3D目标检测任务的发展。但3D目标检测依赖于严格的3D边界框,因此很难识别任意形状或未知的目标。
在此背景下,3D语义占用预测任务提供了一种更加全面的环境建模方式,并且同时估计场景体素的几何结构和语义类别,为每个3D体素分配标签,并提供更完整的感知,对任意形状和动态遮挡表现出更强的鲁棒性。
此外,利用激光雷达和摄像头数据的互补优势进行多模态融合,对于各种3D感知任务至关重要。然而由于模态之间的差异性,多模态的3D占用预测任务仍然具有很大的挑战性。现有的方法通常采用基于LSS的视角转换方式来构建BEV特征,但所得到的稀疏BEV特征仅有50%的网格接收到了有效特征(如图1(a))所示。

图1|不同构建方式的BEV特征可视化
信息,但同时处理点云和图像的融合方法会带来繁重的计算负担,从而增加实时应用的压力。
基于上述提到的相关问题,并且为了引入多模态信息互补的优势。本文提出了一个多模态3D语义占用预测框架SDGOCC,旨在通过融合BEV视角的LiDAR信息来实现更高的准确率和具有竞争力的推理速度。实验结果表明,本文提出的方法在Occ3D-nuscenes和SurroundOcc-nuScenes数据集上实现了SOTA的性能。
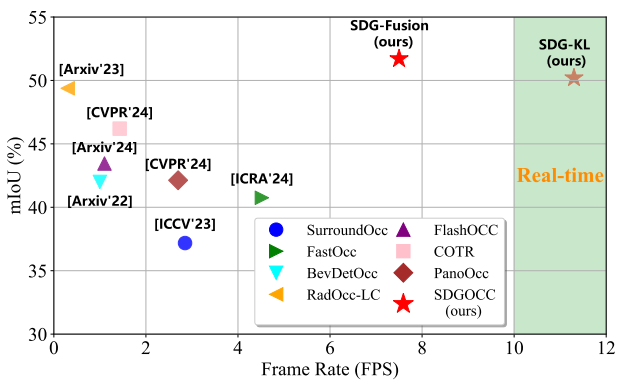
图2|不同算法模型在Occ3D-nuScenes数据集上的比较结果
本文的主要贡献如下:
● 本文引入了一种多模态3D语义占用预测框架,称为SDGOCC,旨在通过从BEV 视角融合LiDAR信息来实现更高的准确度和具有竞争力的推理速度。
● 本文提出了一种新颖的视图变换方法,利用点云的几何和语义信息来指导二维到三维视图的变换。显著提高了深度估计的准确性,并提高了语义占用的速度和准确性。
● 本文提出了一个融合占用驱动的主动蒸馏模块,该模块集成了多模态特征,并根据 LiDAR识别的区域选择性地将多模态知识迁移到图像特征中。
● 本文的方法在Occ3D-nuScenes数据集上通过实时处理实现了SOTA性能,并在更具挑战性的SurroundOcc-nuScenes验证数据集上表现出了相当的性能,证明了方法的有效性。

本文提出的SDGOCC算法模型的整体结构如图3所示。主要由四个关键模块组成,分别是图像编码器模块、SDG视角转换模块、主动蒸馏模块以及占用预测头模块。
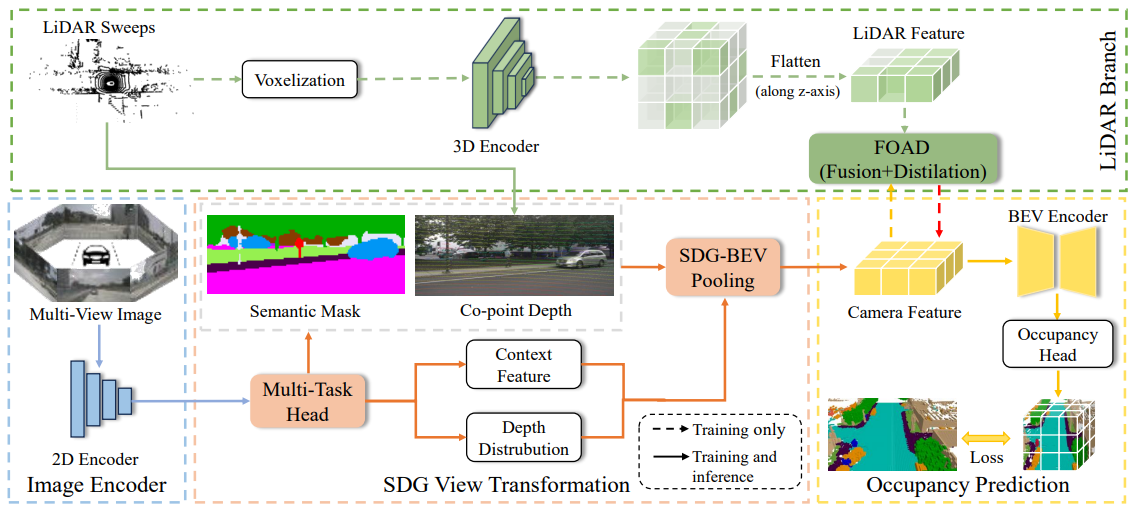
图3|SDGOCC算法模型的整体网络结构图
图像编码器模块
图像编码器模块的作用在于捕捉多视角的图像特征,为后续由2D到3D的视角转换模块提供基础。
SDG视角转换模块
本文提出了一种新颖的视角转换模块,通过利用来自激光雷达点云稀疏深度信息作为先验,并在同一语义类别内进行扩散,从而实现更高性能的视觉转换,如图4所示。
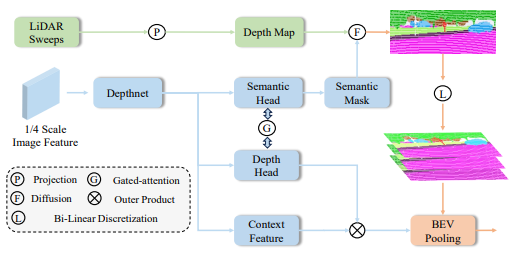
图4|SDG视角转换模块网络结构
具体而言,本文提取多视角图像的特征并且利用多任务头生成语义分割掩码,同时提取图像上下文特征和深度分布权重,其中深度预测头和语义分割头通过门控注意力补充跨任务的信息。
本文考虑到图像和点云之间的稀疏性差异,将图像语义分割掩码和LiDAR提供的稀疏投影深度图相结合,以扩散同一语义类别掩码内的深度值,从而生成半密集的扩展深度图,如下所示:
由于二维像素到三维点的投影存在偏差,本文对扩展深度图应用双向线性增量离散化,以获得离散的虚拟点,从而提高深度估计的精度。最后,通过外积计算图像纹理特征和深度分布权重,为每个虚拟点提取特征,并通过BEV池化生成相机的BEV特征。
主动蒸馏模块
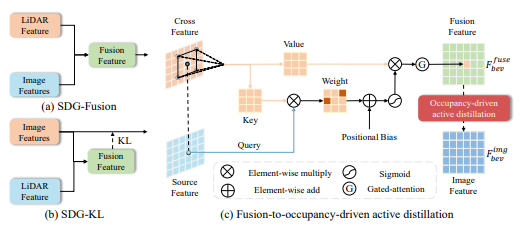
图5|主动蒸馏模块的流程图
将图像特征作为源特征,通过线性层投影获得查询特征。将LiDAR点云特征作为交叉特征进行投影,以获得键值和值特征。查询点的局部邻域特征通过以下公式计算:
对于特征图中的每个像素,本文都会计算局部邻域特征。然后通过门控注意力机制从邻域特征中获得融合特征:
此外,为了确保实时性,本文也提出了一种占用率驱动的主动蒸馏方法。LiDAR点云特征作为源特征,图像特征作为交叉特征,从而得到以LiDAR为主导的融合特征。
通过将将空间划分为两个区域:活动区域以及非活动区域,如下所示。
此外,为了防止模型过分强调AR区域的知识提炼,本文根据AR和IR区域的相对大小应用自适应缩放,如下所示
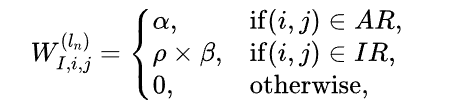
来自于教师和学生的BEV特征蒸馏损失为,最终利用蒸馏损失和分类损失之和来训练网络。

本文研究在Occ3D-nuScenes和SurroundOcc数据集上进行了实验分析来验证所提算法的有效性。图6展示了提出的算法模型与其他栅格占用预测算法模型在Occ3D-nuScenes数据集上的实验结果对比。
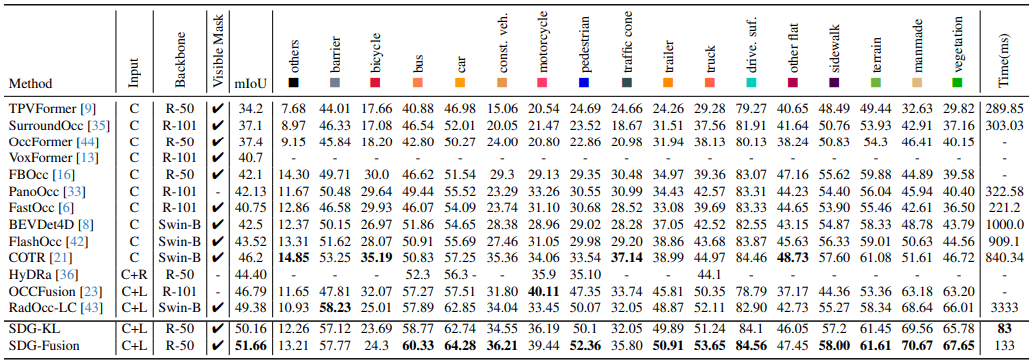
图6|在Occ3D-nuScenes数据集上的实验结果汇总
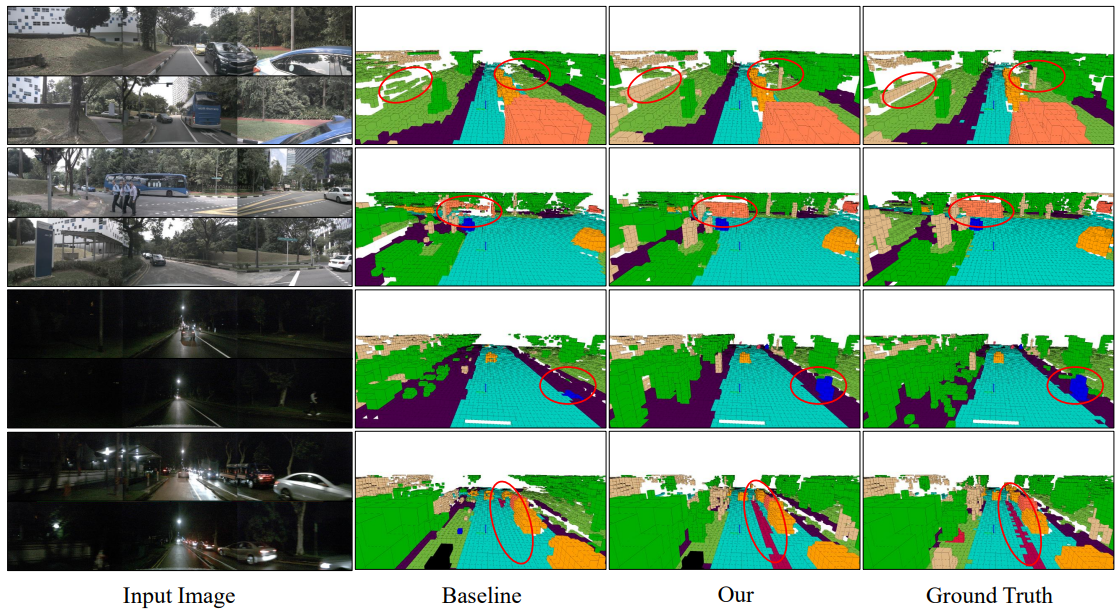
图7|本文提出算法模型的感知结果可视化
展示了提出的算法模型与其他栅格占用预测算法模型在SurroundOcc数据集上的实验结果对比。通过结果可以看出,本文提出的算法模型实现了最佳的感知性能。
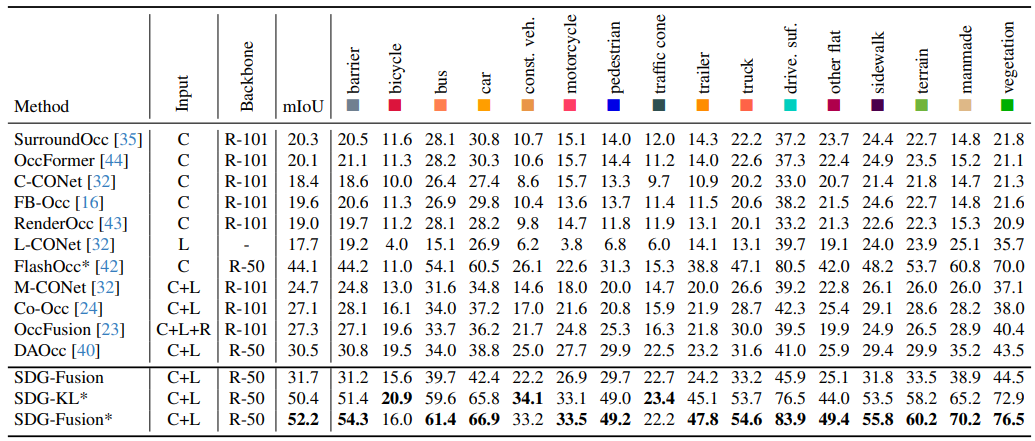
图8|在SurroundOcc数据集上的实验结果汇总
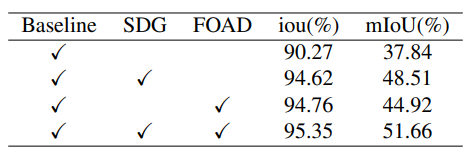
图9|消融实验结果汇总
通过实验结果可以看出,提出的所有模块均对模型的感知性能进行了贡献,进而证明了所提模块的有效性。

本文提出了一种多模态三维语义占用预测框架SDGOCC,旨在通过融合BEV视角的 LiDAR信息,实现更高的准确率和具有竞争力的推理速度。本文提出的方法在Occ3D-nuScenes数据集上实现了实时处理的最高性能,并在更具挑战性的SurroundOcc-nuScenes数据集上取得了相当的性能,证明了其有效性。