15day-人工智学习-机器学习-介绍和定义
一、机器学习的介绍和定义
1.1 机器学习的定义
机器学习本质上就是计算机从已有的数据里面找规律,然后利用这种规律去判断新的数据。
机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程。
机器学习的过程:
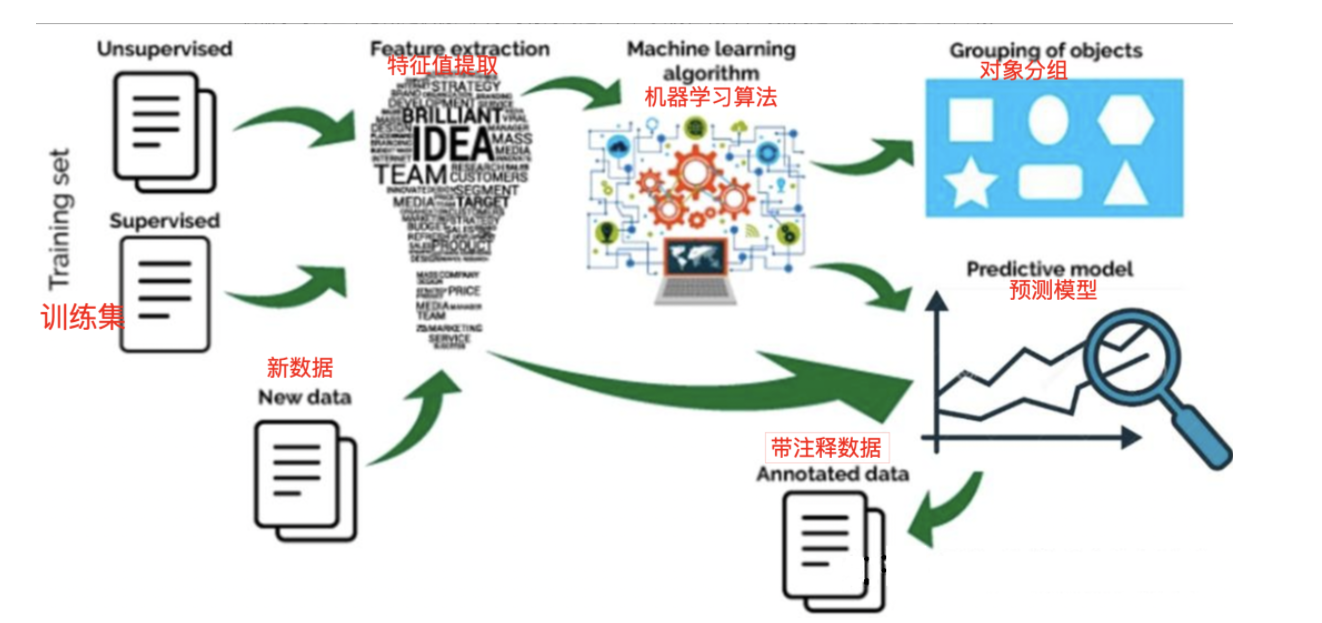
1.2 机器学习的分类
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
1.2.1 监督学习
从有标签的数据集(这个标签可以理解带答案的,比如扁嘴巴,长脖子,有毛就是鸭子这种,鸭子就是标签)里面训练模型找到这中关系(要长脖子,要有毛等),然后通过测试集去验证模型找到的关系准不准确,最后再去推理一些没有标签的数据。
监督学习主要用于分类和回归:
看是什么算法主要是看他们的标签(目标)集是标称型数据还是连续性数据。
标称型数据(Nominal Data)是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
标称数据的特点:
-
无序性:标称数据的各个类别之间没有固有的顺序关系。例如,“性别”可以分为“男”和“女”,但“男”和“女”之间不存在大小、高低等顺序关系。
-
非数值性:标称数据不能进行数学运算,因为它们没有数值含义。你不能对“颜色”或“品牌”这样的标称数据进行加减乘除。
-
多样性:标称数据可以有很多不同的类别,具体取决于研究的主题或数据收集的目的。
-
比如西瓜的颜色,纹理,敲击声响这些数据就属于标称型数据,适用于西瓜分类
连续型数据(Continuous Data)表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
连续型数据的特点包括:
-
可测量性:连续型数据通常来源于物理测量,如长度、重量、温度、时间等,这些量是可以精确测量的。
-
无限可分性:连续型数据的取值范围理论上是无限可分的,可以无限精确地细分。例如,你可以测量一个物体的长度为2.5米,也可以更精确地测量为2.53米,甚至2.5376米,等等。
-
数值运算:连续型数据可以进行数学运算,如加、减、乘、除以及求平均值、中位数、标准差等统计量。
在数据分析中,连续型数据的处理和分析方式非常丰富,常见的有:
-
描述性统计:计算均值、中位数、众数、标准差、四分位数等,以了解数据的中心趋势和分布情况。
-
概率分布:通过拟合概率分布模型,如正态分布、指数分布、伽玛分布等,来理解数据的随机特性。
-
图形表示:使用直方图、密度图、箱线图、散点图等来可视化数据的分布和潜在的模式。
-
回归分析:建立连续型变量之间的数学关系,预测一个或多个自变量如何影响因变量。
-
比如西瓜的甜度,大小,价格这些数据就属于连续型数据,可以用于做回归
1.2.2 半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
1.2.3 无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
1.2.4 强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是是通过不断试错进行学习的模式。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
二、sciklit-learn工具介绍
用于传统的机器学习的工具库,可以实现
需要注意的是,sklearn 主要聚焦于传统机器学习(非深度学习),对于神经网络、深度学习等任务,通常会使用 TensorFlow、PyTorch 等专门框架。但在传统机器学习领域,sklearn 是最常用的工具之一。
-
Scikit-learn官网:scikit-learn: machine learning in Python — scikit-learn 1.7.1 documentation
-
Scikit-learn中文文档:sklearn
下载
进入到自己设置好的环境。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
我们前期的学习会通过使用这个工具包进行过度,
sklearn 的核心特点包括:
- 涵盖了多种经典机器学习算法,如线性回归、逻辑回归、决策树、随机森林、支持向量机(SVM)、K - 近邻(KNN)、聚类算法等
- 提供数据预处理工具(如标准化、归一化、特征选择)
- 包含模型评估方法(如交叉验证、准确率、召回率等指标)
- 设计风格简洁统一,API 易用,适合快速原型开发和教学
三、数据集
我们从上面得知,我们要实现机器学习一系列步骤和功能的前提就是得要有数据给模型。
在我们学习的时候这些数据不用自己找了,sklearn工具包里面内置了一些数据。

from sklearn.datasets import load_iris
iris = load_iris()#鸢尾花数据iris是一个类,然后里面有这些属性
# data 特征集
# feature_names 特征描述
# target 目标集
# target_names 目标描述
# DESCR 数据集的描述
# filename 下后到本地保存后的文件名
可以自己尝试熟悉一下数据集。
也可以加载本地的数据也行,通过sklearn联网下载也是可以的。
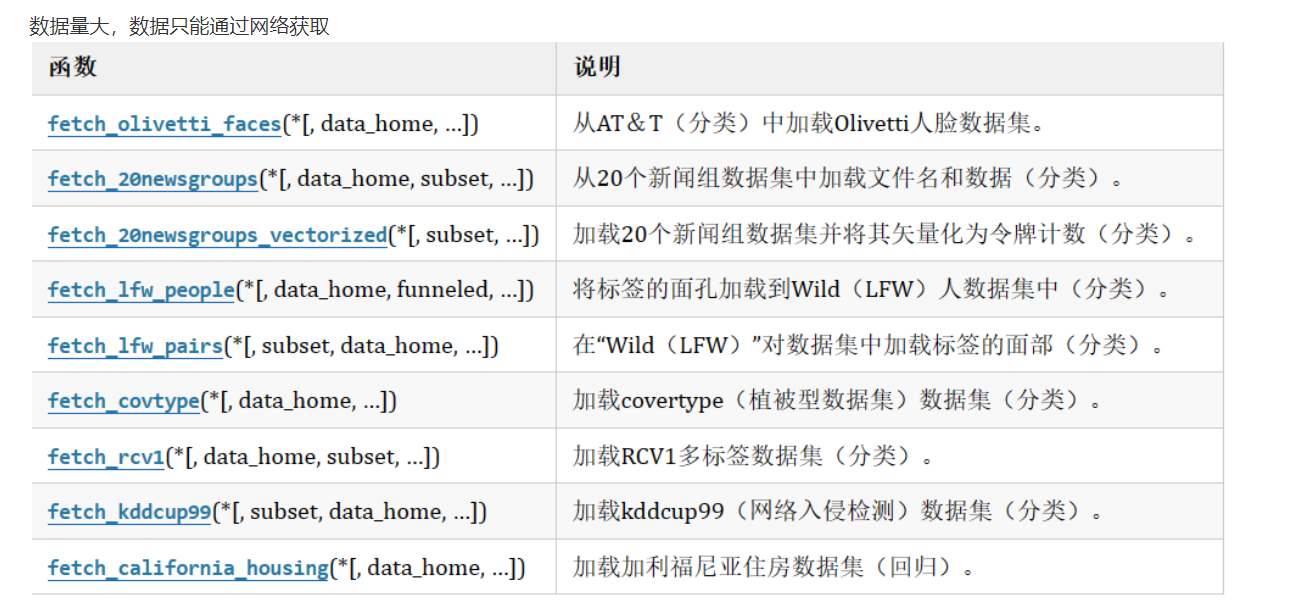
from sklearn.datasets import fetch_20newsgroups #这是一个20分类的数据
news = fetch_20newsgroups(data_home=None,subset='all')(1)data_home可以自定义指定,默认下载到C盘,subset为train就是下载训练集,为test就是下载测试集,为all自然就是都下载。
(2)下载时,有可能回为网络问题而出问题,要“小心”的解决网络问题,不可言…..
(3)第一次下载会保存的硬盘中,如果第二次下载,因为硬盘中已经保存有了,所以不会再次下载就直接加载成功了。
3.1 数据集的划分
我们现在准备了数据,然后将数据集分为训练集和测试集,训练集就来训练模型,让模型知道规律,测试集就来验证这个规律找到的准不准。
我们也不需要自己手动去分了,sklearn提供了一个api,我们只需要传入一些参数就好
train_test_split
参数是*数据集,test_size(有默认值)
test_size=0.4就是测试集占百分之40,训练集占百分之60,你也可以直接填几条,test_size也可以是train_size道理一样的,返回值自然是训练集a和测试集b。
from sklearn.model_selection import train_test_split
data1 = [1, 2, 3, 4, 5]
data2 = ["1a", "2a","3a", "4a", "5a"]
a, b = train_test_split(data1, test_size=0.4)
print(a, b) #[4, 1, 5] [2, 3]a, b = train_test_split(data2, test_size=0.4)
print(a, b) #['4a', '1a', '5a'] ['2a', '3a']这只是一个数据集的划分,那么两个又是怎么实现的
这里我们要了解到api是怎么划分的,里面有个这个参数
-
shuffle参数:默认为True(随机划分),会在划分前打乱数据顺序。若设为False,则按原始数据顺序划分(前一部分为训练集,后一部分为测试集),不打乱数据 -
random_state参数:若不设置,每次运行会得到不同的随机划分结果,当shuffle=True时,random_state用于固定随机种子,确保每次划分结果一致(便于复现),你设置了随机数种子和不管运行几次他都是一样的划分数据集。
这两个数据集的元素数量肯定是要一样的,然后先将他们的序列提取出来,进行打不打乱,然后按着参数test_size来从左往右拿多少,这里就可以看到他们的对应位置是一样,为什么要这么设计,我们现在先学习的是监督学习,每一个样本都是有一个目标值,我们需要保持一一对应涩。
a,b 就是data1划分的数据集,c,d就是data2划分的数据集
知道原理了,不管几个数据集都能划分的。
from sklearn.model_selection import train_test_split
data1 = [1, 2, 3, 4, 5]
data2 = ["1a", "2a","3a", "4a", "5a"]a, b, c, d = train_test_split(data1, data2, test_size=0.4, random_state=22)
print(a,b,c,d) #[4, 1, 5] [2, 3] ['4a', '1a', '5a'] ['2a', '3a']