[论文阅读] 人工智能 + 软件工程 | Trae Agent:让AI智能体高效解决仓库级软件问题,登顶SWE-bench排行榜
Trae Agent:让AI智能体高效解决仓库级软件问题,登顶SWE-bench排行榜
论文:Trae Agent: An LLM-based Agent for Software Engineering with Test-time Scaling
arXiv:2507.23370
Trae Agent: An LLM-based Agent for Software Engineering with Test-time Scaling
Trae Research Team: Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, Yun Lin, Yingfei Xiong, Chao Peng, Xia Liu
Comments: Pengfei Gao and Zhao Tian contributed equally to this technical report
Subjects: Software Engineering (cs.SE); Artificial Intelligence (cs.AI)
一段话总结:
Trae Agent是首个基于智能体的集成推理方法,用于仓库级软件问题解决,通过将目标转化为最优解搜索问题,解决了大集成空间和仓库级理解两大挑战。其核心包括补丁生成(通过编码器智能体并行生成多样候选补丁)、补丁修剪(结合去重和回归测试减少冗余/错误补丁)、补丁选择(通过选择器智能体构建仓库级理解并采用多数投票)三大组件。在SWE-bench基准上,Trae Agent在三个顶尖LLM上均优于四种现有集成推理技术,平均Pass@1提升10.22%,在SWE-bench Verified排行榜排名第一,Pass@1达75.20%,并已开源(GitHub星数超8000)。
研究背景:软件问题自动解决的困境与挑战
想象一下,当你作为开发者收到一个用户反馈的软件bug时,你需要通读大量代码、理清文件间的依赖关系、反复测试可能的修复方案——这往往耗时又费力。而在软件工程领域,自动解决软件问题(比如修复bug、实现新功能)一直是追求的目标,因为它能大幅减轻开发者负担,提升团队效率。
近年来,大语言模型(LLMs)在代码生成、自动程序修复等函数级任务中表现亮眼。例如,GPT-4o在函数级代码测试集HumanEval上的正确率能达到92.70%。但当面对更复杂的仓库级任务(涉及整个代码库的多个文件、跨模块逻辑)时,LLMs的表现却断崖式下跌——在仓库级测试集SWE-bench上,GPT-4o的正确率仅为11.99%。
为什么会这样?因为仓库级问题需要"全局视野":不仅要理解单段代码,还要掌握整个代码库的结构、文件间的依赖,甚至能检测那些涉及多个组件的隐蔽bug。
为了提升LLMs的表现,研究者们提出了集成推理技术——生成多个候选修复方案(补丁),再从中选最优的。但现有方法存在两个大问题:
- 大集成空间难处理:候选补丁越多,LLMs越难区分细微差异,常因表面语法比较而错过正确方案;
- 缺乏仓库级理解:无法跟踪代码依赖、执行验证步骤,难以判断补丁在整个代码库中是否真的有效。
这就像你要从一堆简历中挑最合适的人,但既看不懂简历里的"隐藏信息",又不知道公司各部门的实际需求——自然容易选错。
主要作者及单位信息
- 核心作者:Pengfei Gao、Zhao Tian(共同贡献)、Xiangxin Meng等
- 单位:Trae Research(北京)
- 开源地址:https://github.com/bytedance/trae-agent(截至2025年7月,已获超8000星标)
创新点:Trae Agent的三大"独门秘籍"
Trae Agent是首个基于智能体的仓库级集成推理方案,它把软件问题解决转化为"最优解搜索问题",通过三个模块精准击破现有方法的痛点:
-
多样化补丁生成:不依赖单一LLM,而是用"编码器智能体"结合多工具(文件编辑、命令行交互等),通过高温采样和多LLM轮询(如Gemini 2.5 Pro、Claude 3.7 Sonnet)生成更多样的候选补丁。
-
分层补丁修剪:先通过"去重"移除语义重复的补丁(比如仅格式不同的方案),再用"回归测试"过滤掉那些会破坏现有功能的补丁,大幅缩小候选范围。
-
仓库级补丁选择:"选择器智能体"模拟真实开发者的理解过程——既静态分析相关代码片段,又动态执行测试用例,最后通过"多数投票"选出最可靠的补丁,减少LLM"幻觉"影响。
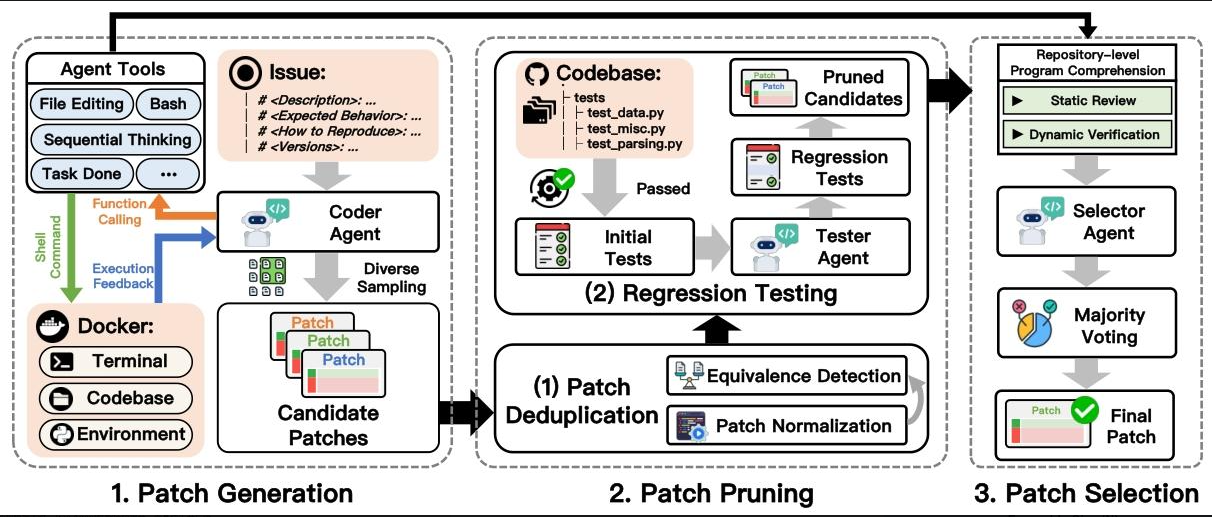
研究方法:Trae Agent如何一步步解决问题?
步骤1:生成多样化候选补丁
- 编码器智能体工作流:
- 分析问题描述,明确目标;
- 探索代码库,定位相关文件;
- 复现bug,确认问题;
- 诊断根因,生成补丁;
- 测试验证,确保补丁初步有效。
- 增强多样性:用高温采样让LLM生成更多样化的输出,同时让三个顶尖LLM轮流出力,避免单一模型的偏见。
步骤2:修剪冗余/错误补丁
- 补丁去重:
- 把补丁转化为标准化格式(移除空格、注释等无关信息);
- 对比标准化后的补丁,移除完全相同的冗余项。
- 回归测试:
- 从原始代码库中筛选出关键测试用例;
- 用这些测试验证每个补丁,淘汰那些导致现有功能失效的方案。
步骤3:选择最优补丁
- 选择器智能体工作流:
- 收集与问题相关的代码(被修改的文件、依赖模块等),建立静态理解;
- 生成并执行新测试用例,通过运行结果建立动态理解;
- 多次独立评估后,用多数投票选出最终补丁。
实验方法
- 测试集:SWE-bench Verified(500个经专业开发者验证的真实GitHub问题);
- 对比方法:4种现有集成推理技术(Augment、DeiBase及其带修剪的版本);
- 评估指标:Pass@1(补丁通过所有测试的比例,数值越高越好)。
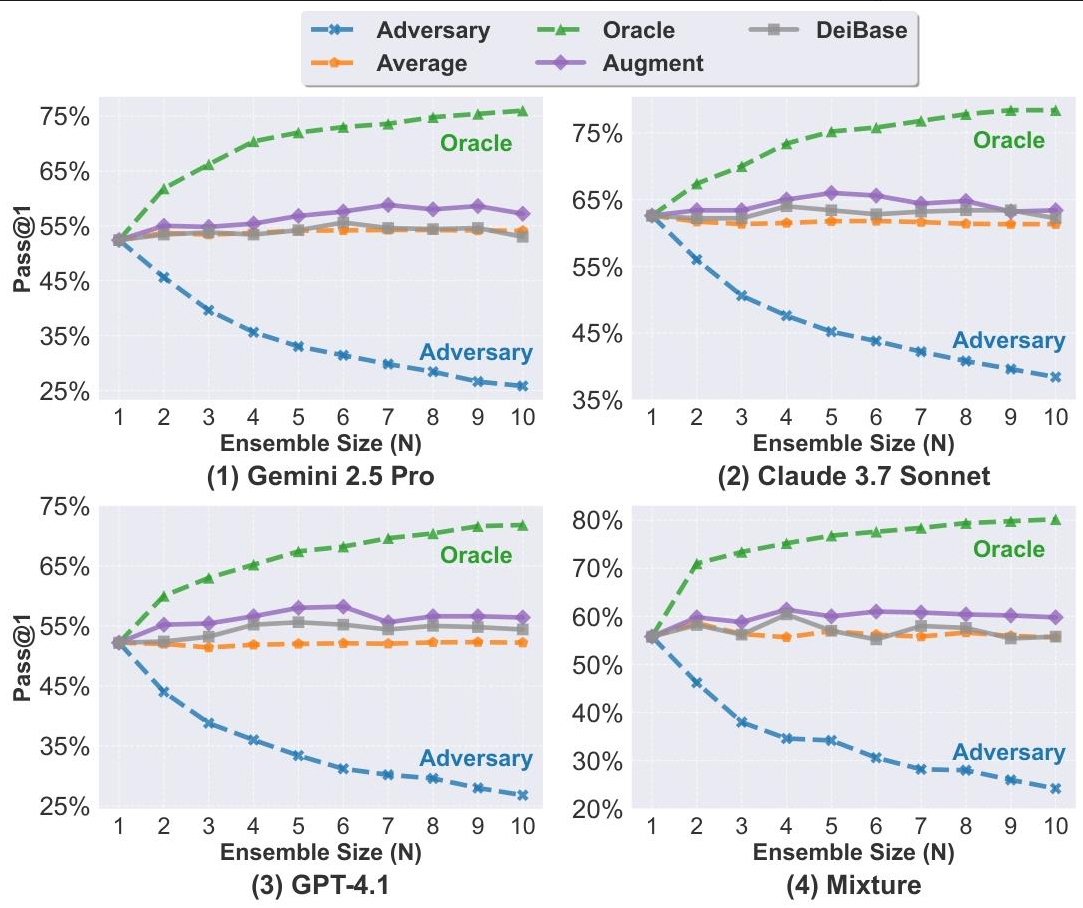
主要贡献:Trae Agent到底有多厉害?
-
性能碾压现有方法:在三个顶尖LLM上,Trae Agent的Pass@1比现有方法平均高10.22%,最高提升达14.60%;
-
登顶权威排行榜:在SWE-bench Verified排行榜上排名第一,Pass@1达75.20%,远超第二名的74.40%;
-
组件设计经得住检验:
- 补丁修剪能减少28.90%的冗余,让其他方法性能提升3.91%~4.72%;
- 选择器智能体和多数投票能减少LLM误判,单独贡献4%左右的性能提升;
-
开源赋能社区:所有资源开源,帮助研究者进一步推进该领域发展。
思维导图:

详细总结:
1. 研究背景与挑战
- 软件问题解决(自动处理bug或功能请求)是软件工程关键任务,可减少开发者负担并提升生产力。
- LLM在函数级代码任务(如代码生成、自动程序修复)表现优异,但在仓库级任务中性能差距显著(如GPT-4o在HumanEval达92.70%,SWE-bench仅11.99%),因需全局理解代码库、跨文件推理等。
- 现有集成推理方法(如Augment、DeiBase)依赖提示词,存在局限:难以处理大集成空间(候选补丁增多时难区分)、缺乏仓库级理解(无法跟踪依赖或验证补丁在全局代码库中的正确性)。
2. Trae Agent的核心方法
- 定位:首个基于智能体的仓库级集成推理方法,将问题转化为最优解搜索问题。
- 三大组件:
- 补丁生成:
- 编码器智能体结合多工具(文件编辑、Bash、顺序思考等),遵循标准化流程(分析问题→定位文件→复现bug→诊断→生成补丁→验证等)。
- 采用高温采样和多LLM轮询(Gemini 2.5 Pro、Claude 3.7 Sonnet、GPT-4.1)提升候选补丁多样性。
- 补丁修剪:
- 去重:通过归一化(移除无关元素如空格、注释)和等价检测,消除语义等价补丁,平均减少28.90%冗余。
- 回归测试:测试智能体执行原始代码库中的测试,筛选通过所有回归测试的补丁,错误率仅3.69%。
- 补丁选择:
- 选择器智能体通过静态审查(分析相关代码片段)和动态验证(生成并执行单元测试)构建仓库级理解。
- 多数投票:并行执行选择器智能体N次,选得票最高的补丁,减少LLM幻觉影响。
- 补丁生成:
3. 实验结果
- 整体性能(RQ1):
Trae Agent在所有设置中Pass@1最优,在Gemini 2.5 Pro、Claude 3.7 Sonnet、GPT-4.1及混合设置中分别达62.27%、66.40%、59.00%、65.67%,平均优于四种基线方法5.83%~14.60%,且稳定性更高(标准差0.19%)。 - 超参数影响(RQ2):
集成规模(N=1~10)增大时,Trae Agent性能持续提升,而基线先升后降(因信息稀释)。 - 组件贡献(RQ3):
移除补丁修剪(Trae Agent woP)平均Pass@1下降5.57%;移除选择器智能体(Trae Agent A)平均下降4.08%;移除多数投票(Trae Agent woM)平均下降4.14%。 - 集成空间影响(RQ4):
补丁修剪使集成空间平均减少27.80%~39.15%,且集成空间与选择效果呈强相关(Pearson’s r 0.73~0.91)。
4. 实际影响与未来工作
- 实际影响:Trae Agent在SWE-bench Verified排行榜排名第一(Pass@1 75.20%),开源仓库星数超8000。
- 未来工作:集成多问题解决智能体增强多样性、扩大集成规模、探索LLM-based补丁去重技术。
关键问题:
-
Trae Agent相比现有集成推理方法的核心创新是什么?
核心创新在于采用基于智能体的模块化架构:通过编码器智能体解决补丁多样性问题,通过修剪智能体解决大集成空间问题,通过选择器智能体(结合静态+动态理解)和多数投票解决仓库级理解问题,而现有方法依赖单一提示词,无法处理复杂仓库级任务。 -
Trae Agent在实验中的性能表现如何?有哪些关键数据支持?
Trae Agent在SWE-bench基准上表现优异:在Gemini 2.5 Pro、Claude 3.7 Sonnet、GPT-4.1及混合设置中,Pass@1分别达62.27%、66.40%、59.00%、65.67%,平均优于四种基线方法5.83%~14.60%;在SWE-bench Verified排行榜排名第一,Pass@1达75.20%。 -
补丁修剪组件在Trae Agent中起到什么作用?效果如何?
补丁修剪通过去重和回归测试减少集成空间,提升后续选择效率。其中,去重平均减少28.90%冗余补丁,回归测试错误率仅3.69%;将该组件整合到Augment和DeiBase中,平均Pass@1分别提升3.91%和4.72%,证明其有效性和通用性。
总结
Trae Agent通过"生成-修剪-选择"的模块化智能体架构,首次实现了仓库级软件问题的高效集成推理。它解决了现有方法在大集成空间处理和仓库级理解上的短板,在权威测试集上表现远超同类技术,为自动软件问题解决提供了新的标杆。
核心成果:
- 提出首个基于智能体的仓库级集成推理方案;
- 在SWE-bench Verified上以75.20%的Pass@1排名第一;
- 平均比现有方法性能提升10.22%,且组件设计具有通用性,可扩展到其他软件工程任务。