【Java面试题】缓存穿透
什么是缓存穿透
缓存穿透是指当秒杀请求在Redis中未命中缓存时,系统会转而查询数据库。若数据库中也不存在该数据,大量此类请求将直接冲击数据库,造成数据库负载激增。
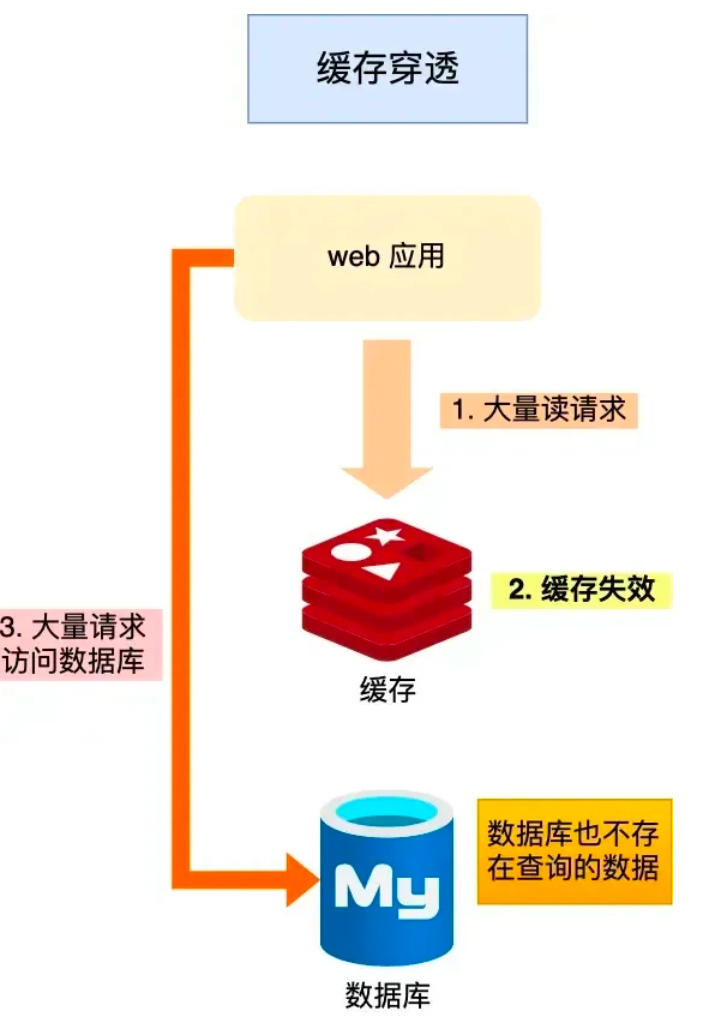
解决方案
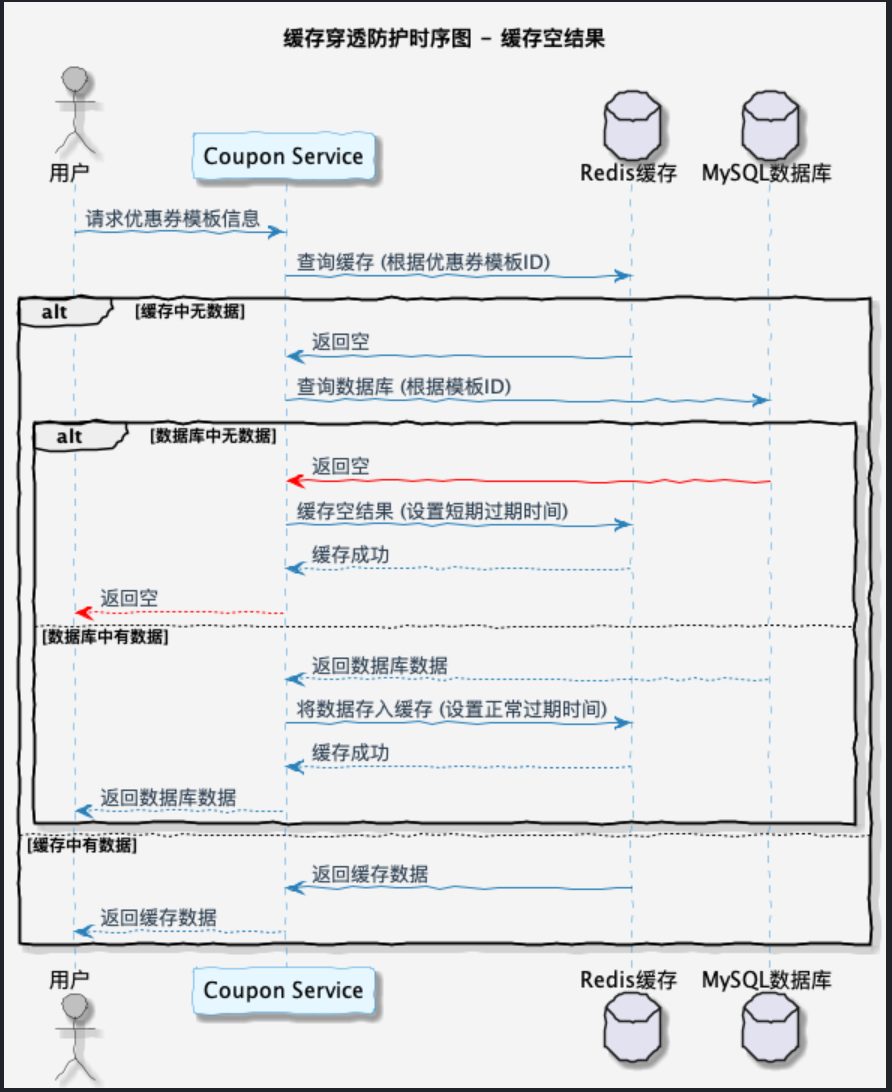
缓存空值
当我们查询数据库发现数据库当中也不存在该数据时,这时候我们可以将空值缓存到Redis当中,这样下一次请求再次查询该数据时,就会从缓存中获取信息。
public String selectUser(String userId) {String cacheData = cache.get(userId);if (StrUtil.isBlank(cacheData)) {// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程Boolean cacheIsNull = cache.hasKey("is-null_" + userId);if (cacheIsNull) {throw new RuntimeException();}String dbData = userMapper.selectId(userId);if (StrUtil.isNotBlank(dbData)) {cahce.set(userId, dbData);cacheData = dbData;} else {// 查询数据库中不存在数据,添加空值缓存并返回cache.set("is-null_" + userId, 较短过期时间);throw new RuntimeException();}}return cacheData;
}
但是这种方式也会存在一些弊端:当短时间内存在大量恶意请求时,缓存系统就会存在大量内存占用。
布隆过滤器
什么是布隆过滤器,布隆过滤器的原理
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。它以牺牲一定的准确性为代价,换取了存储空间的极大节省和查询速度的显著提升。
布隆过滤器是由一个位数组和一组哈希函数组成,当将数据存入数据库时,会先通过一组哈希函数,计算出该数据对应的哈希数值,再通过取模,将对应位数组的相应位置改为1。从而将数据进行标记。当查询数据库时,会先通过布隆过滤器检查该数据是否存在,如果该数据对应的位数组的位置全为1,则可能存在,继续查询数据库,反之,如果有任何一位为0,则一定不存在,不会去查询数据库。
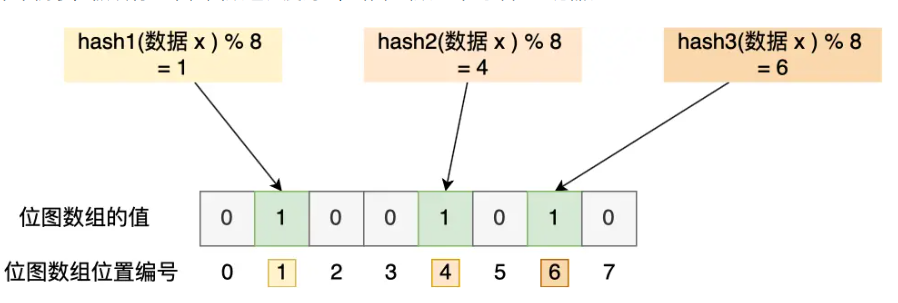
布隆过滤器的优点和缺点
布隆过滤器的优点在于它可以高效地判断一个元素是否属于一个大规模集合,且具有极低的存储空间要求。如果存储 1亿元素,误判率设置为 0.001 也就是千分之一,仅需要占用 171M 左右的内存。
缺点在于可能会存在一定的误判率。
它在实际应用中常用于缓存场景下缓存穿透问题,对访问请求做一个快速判断机制。使用布隆过滤器能够有效减轻对底层存储系统的访问以及缓存系统的存储压力。
但是布隆过滤器本身也存在一些“弊端”,那就是不支持删除元素。因为它是一种基于哈希的数据结构,删除元素会涉及到多个哈希函数之间的冲突问题,这样会导致删除一个元素可能会影响到其他元素的正确性。
总的来说,布隆过滤器是一种非常高效的数据结构,适用于那些可以容忍一定的误判率的场合。
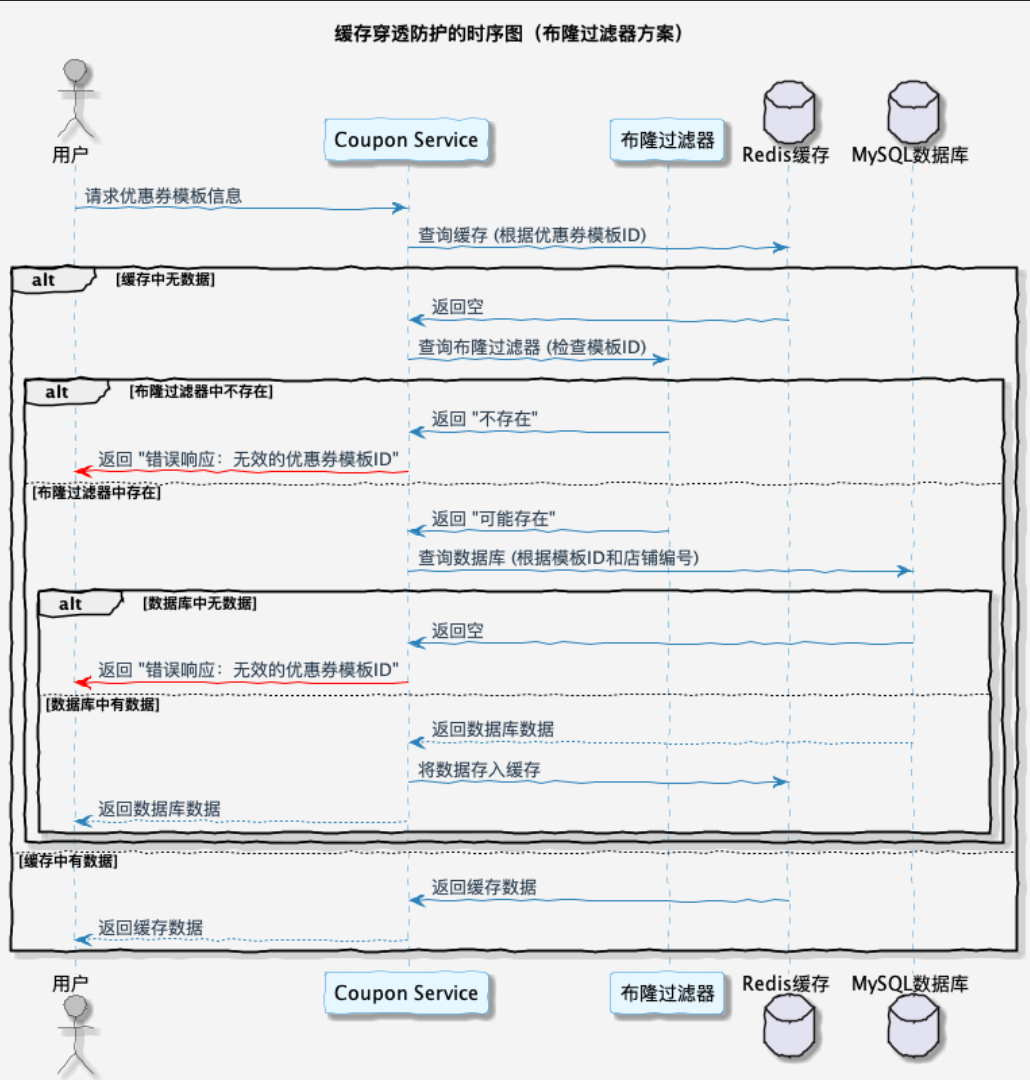
用布隆过滤器解决缓存穿透伪代码
public String selectUser(String userId) {String cacheData = cache.get(userId);if (StrUtil.isBlank(cacheData)) {if (!bloomFilter.contains(fullShortUrl)) {throw new RuntimeException();}String dbData = userMapper.selectId(userId);if (StrUtil.isNotBlank(dbData)) {cahce.set(userId, dbData);cacheData = dbData;}}return cacheData;
}
但是使用布隆过滤器还有可能发生哈希碰撞,导致判断错误。还是有可能导致该请求进入到数据库。那么接下来就需要将这些方法组合到一起使用。
布隆过滤器,缓存空值,分布式锁
当一个秒杀请求进入Redis,先判断Redis中是否有值,发现没有,接着去判断布隆过滤器中是否含有该数据,如果没有,直接返回无。如果监测到存在,就去先获取分布式锁,再去数据库当中进行查询。同时在查询之前还需要进行双重判断,即再次判断一下缓存中是否有值。(目的是防止该线程在等待锁期间其他线程已经查询到信息并将信息缓存到Redis当中)当从数据库中查询到后,再将该数据存入到Redis当中,并返回结果。

伪代码
public String selectUser(String userId) {String cacheData = cache.get(userId);if (StrUtil.isBlank(cacheData)) {// 判断 Key 是否存在布隆过滤器,存在则继续流程,否则直接返回if (!bloomFilter.contains(fullShortUrl)) {throw new RuntimeException();}
// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程Boolean cacheIsNull = cache.hasKey("is-null_" + userId);if (cacheIsNull) {throw new RuntimeException();}
// 获取分布式锁Lock lock = getLock(userId);lock.lock();
try {// 拿到锁之后进行双重判定,如果缓存已经存在则直接返回即可cacheData = cache.get(userId);if (StrUtil.isNotBlank(cacheData)) {return cacheData;}
// 拿到锁之后进行双重判定,如果空值缓存已经存在则直接终止流程即可cacheIsNull = cache.hasKey("is-null_" + userId);if (!cacheIsNull) {throw new RuntimeException();}
// 根据用户标识查询数据库记录String dbData = userMapper.selectId(userId);if (StrUtil.isNotBlank(dbData)) {cahce.set(userId, dbData);cacheData = dbData;} else {// 查询数据库中不存在数据,添加空值缓存并返回cache.set("is-null_" + userId, 较短过期时间);throw new RuntimeException();}} finally {lock.unlock();}}return cacheData;
}