逻辑斯蒂回归的模型优化
引言
在信用卡欺诈检测的实际场景中,风险识别的精准性直接关系到金融安全与用户体验。在上篇案例中,我们通过逻辑斯蒂回归模型构建了基础的欺诈检测框架,利用其简单高效、可解释性强的特点,初步实现了对欺诈交易的识别。然而,面对现实中高度不平衡的交易数据(欺诈样本占比往往低于 0.1%)、复杂的特征关联以及严苛的误判成本要求,基础模型的性能往往难以满足实际业务需求 —— 例如,可能出现对欺诈样本的漏检率偏高,或对正常交易的误判率过高等问题。
正是基于这些实际挑战,逻辑斯蒂回归模型的优化工作显得尤为关键。如何通过特征工程挖掘更有价值的信息、如何通过正则化策略平衡模型的拟合能力与泛化能力、如何结合数据不平衡特性调整训练策略,以及如何通过阈值调优实现精确率与召回率的动态平衡,成为进一步提升模型效能的核心方向。本文将围绕这些优化维度展开探讨,旨在为信用卡欺诈检测场景提供更稳健、更贴合业务需求的逻辑斯蒂回归模型方案。
逻辑斯蒂回归作为经典的线性分类模型,其优化需要从数据处理、模型本身和训练策略等多个维度入手。以下是一些具体且可落地的优化方法,结合实际场景(如欺诈检测)说明:
一、核心优化方向
逻辑斯蒂回归的优化可从 特征工程、正则化策略、求解器选择、不平衡处理、超参数调优 等方面展开,具体如下:
1. 特征工程优化
特征质量直接影响模型性能,尤其对于逻辑回归这种线性模型,优质特征能显著提升效果。特征选择:去除冗余、噪声或低重要性特征(逻辑回归对无关特征敏感)。
异常值处理:信用卡数据中可能存在极端值(如异常交易金额),需处理以避免模型偏移。
特征转换:对非线性关系特征进行转换(如对数变换),或构建交互特征捕捉变量间关系。
共线性处理:逻辑回归对多重共线性敏感,需通过 VIF(方差膨胀因子)检测并消除高共线性特征。
2. 正则化与求解器优化
(1)正则化:控制模型复杂度的核心手段
本质:通过在损失函数中加入惩罚项,限制模型参数(系数)的大小,避免过拟合(过度拟合训练数据中的噪声)。
(2)正则化强度控制(参数 C)
正则化强度由超参数C控制(C = 1/λ,λ 为惩罚系数):
C越小:正则化越强(惩罚越重),系数越接近 0,模型越简单(可能欠拟合)
C越大:正则化越弱(惩罚越轻),系数更自由,模型越复杂(可能过拟合)
不同 C 值下的决策边界:C=0.01(强正则化,欠拟合)→ C=1(平衡)→ C=100(弱正则化,过拟合)
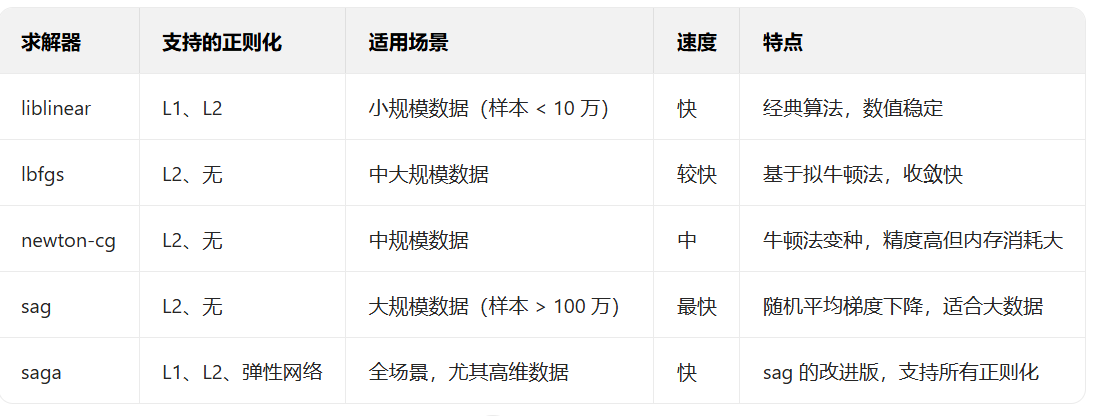
(3)求解器:参数优化的 “引擎”
1. 常用求解器对比
3. 类别不平衡处理优化
在分类任务中(如欺诈检测、疾病诊断),类别不平衡是常见问题 —— 多数类样本远多于少数类(如正常交易:欺诈交易 = 1000:1)。这种情况下,模型会偏向多数类,导致少数类(如欺诈样本)识别效果极差。
1. 过采样:增加少数类样本
原理:通过合成新的少数类样本,平衡类别比例。
代表方法:SMOTE(合成少数类过采样技术)
不是简单复制少数类,而是在相似样本间生成新样本(避免过拟合)。
步骤:① 找少数类样本的近邻 → ② 在样本与近邻间生成新样本 → ③ 平衡后的数据分布
2. 欠采样:减少多数类样本
原理:从多数类中筛选部分样本,降低其比例。
常用方法:
随机欠采样:随机删除多数类样本(简单但可能丢失重要信息)。
聚类欠采样:对多数类聚类,保留聚类中心样本(保留关键信息)。
3. 类别权重调整(算法层面)
原理:不改变数据分布,通过给少数类赋予更高权重,让模型更关注少数类。
实现:逻辑回归中设置class_weight='balanced',自动根据样本比例分配权重。
4. 阈值调优(后处理层面)
原理:不改变模型,通过调整分类阈值(默认 0.5),平衡少数类的召回率和精确率。
方法:通过 PR 曲线找到最优阈值(如最大化 F1 分数或满足业务要求的召回率)。
不同阈值下的召回率变化:降低阈值(如 0.3)可显著提高少数类召回率
4. 交叉验证策略优化
1.交叉验证设计
用分层抽样交叉验证(StratifiedKFold),确保每个折中类别比例与原始数据一致,避免评估偏差。对极度不平衡数据,可采用重复分层交叉验证(RepeatedStratifiedKFold),减少随机波动影响。
2. 评估指标与阈值调优
不依赖准确率(Accuracy),改用更适合不平衡数据的指标:
召回率(Recall):确保欺诈样本尽可能被识别(减少漏报)。
F1 分数:平衡精确率和召回率(避免一味追求高召回率导致大量误判)。
PR 曲线下面积(PR-AUC):比 ROC-AUC 更能反映不平衡数据的模型性能。
阈值调优:通过 PR 曲线找到最优阈值(如最大化 F1 分数或满足业务要求的召回率),而非默认 0.5。
二、优化代码实现
1. 导入库
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler # 特征标准化工具
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.linear_model import LogisticRegression # 逻辑斯蒂回归模型
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn import metrics # 模型评估指标
from imblearn.over_sampling import SMOTE # 处理类别不平衡的过采样工具
from sklearn.metrics import precision_recall_curve, f1_score # 阈值调优相关指标2. 数据加载与预处理
# 加载信用卡交易数据(包含正常交易和欺诈交易)
data = pd.read_csv('creditcard1.csv')# 标准化交易金额特征(逻辑斯蒂回归对特征尺度敏感)
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']]) # 将Amount列标准化为均值0、方差1# 移除时间特征(假设Time列对欺诈检测无显著意义)
data1 = data.drop(['Time'], axis=1)3. 特征与标签分离
x = data1.iloc[:, :-1] # 取所有行,除最后一列外的所有列作为特征(输入变量)
y = data1.iloc[:, -1] # 取所有行的最后一列作为标签(输出变量,1表示欺诈,0表示正常)4. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, # 测试集占比30%,训练集占比70%random_state=100 # 随机种子,保证每次划分结果一致
)5. 处理类别不平衡(核心步骤)
信用卡欺诈数据中,欺诈样本(正例)通常仅占 0.1% 左右,属于严重不平衡数据。
# 初始化SMOTE过采样器(合成少数类样本,平衡类别比例)
oversampler = SMOTE(random_state=0)# 对训练集进行过采样:增加欺诈样本,使正负样本比例接近1:1
os_x_train, os_y_train = oversampler.fit_resample(x_train, y_train)SMOTE 原理:不是简单复制少数类样本,而是在相似样本间生成新样本,避免过拟合。
6. 超参数 C 调优(基于交叉验证)
逻辑斯蒂回归中,C是正则化强度的倒数(C越小,正则化越强),需通过调优确定最优值。
scores = [] # 存储不同C值对应的平均召回率
c_values = [0.01, 0.1, 1, 10, 100] # 候选C值(对数尺度,覆盖不同正则化强度)for c in c_values:# 初始化逻辑斯蒂回归模型(L2正则化,最大迭代次数1000确保收敛)lr = LogisticRegression(C=c, penalty='l2', max_iter=1000)# 10折交叉验证计算召回率(欺诈检测中,召回率比准确率更重要,需优先识别欺诈样本)score = cross_val_score(lr, os_x_train, os_y_train, cv=10, scoring='recall')# 计算平均召回率并存储score_mean = sum(score) / len(score)scores.append(score_mean)print(score_mean) # 打印当前C值的平均召回率7. 训练最优模型
# 选择召回率最高的C值作为最佳超参数
best_c = c_values[np.argmax(scores)]# 用最佳C值初始化模型并训练
model = LogisticRegression(max_iter=1000, C=best_c)
model.fit(os_x_train, os_y_train) # 用SMOTE处理后的训练集拟合模型核心逻辑总结
1. 数据层面:通过 SMOTE 解决类别不平衡,让模型更关注少数类(欺诈样本)。
2. 模型层面:通过交叉验证调优正则化参数C,平衡模型复杂度与泛化能力。
3. 业务导向:选择召回率作为核心指标(优先减少欺诈样本漏检),符合信用卡风控的实际需求。
完整代码如下:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from imblearn.over_sampling import SMOTE
from sklearn.metrics import precision_recall_curve, f1_score
data=pd.read_csv('creditcard1.csv')
scaler=StandardScaler()
data['Amount']=scaler.fit_transform(data[['Amount']])
data1=data.drop(['Time'],axis=1)
x=data1.iloc[:,:-1]
y=data1.iloc[:,-1]
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=100)
oversampler= SMOTE(random_state=0)
os_x_train, os_y_train = oversampler.fit_resample(x_train, y_train)
scores=[]
c=[0.01,0.1,1,10,100]
for i in c:lr=LogisticRegression(C=i,penalty='l2',max_iter=1000)score=cross_val_score(lr,os_x_train,os_y_train,cv=10,scoring='recall')score_mean=sum(score)/len(score)scores.append(score_mean)print(score_mean)
best_c=c[np.argmax(scores)]
model = LogisticRegression(max_iter=1000,C=best_c)
model.fit(os_x_train, os_y_train) 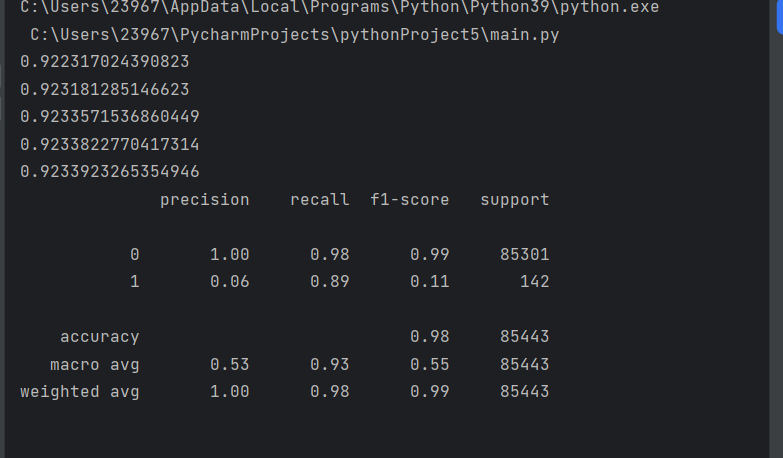
整个流程紧扣合欺诈检测的业务需求(高召回率优先),通过数据平衡和参数调优,使简单高效的逻辑斯蒂回归模型能在欺诈识别任务中发挥良好性能,同时保持模型的可解释性(便于风控规则解释)。