LSTM网络从浅入深原理级讲解与Pytorch逐行讲解实现
第一部分:回顾RNN的缺陷
在上节博客我们讲到,标准的RNN存在长期依赖问题(Long-Term Dependencies)。由于梯度消失,RNN很难将信息从很早的时间步传递到很远的时间步。它的记忆力很短,像一条只有7秒记忆的鱼,对于长序列数据(比如一篇长文章、一段长语音)中的深层联系,它无能为力。
RNN的记忆(隐藏状态 h_t)在每个时间步都会被完全重写:
h_t = tanh(W_hh * h_{t-1} + W_xh * x_t + b_h)
旧的记忆 h_{t-1} 和新的输入 x_t 被混合在一起,然后通过 tanh 函数进行一次清洗,生成全新的记忆 h_t。在这个过程中,信息很容易丢失。就好像你每次记新东西,都得把脑子里的旧知识和新知识搅在一起,然后重新形成你的整个知识体系,这样效率太低,而且很容易忘掉重要的旧知识。
LSTM(Long Short-Term Memory)被设计出来,就是为了专门解决这个问题。
第二部分:LSTM的核心思想
LSTM的突破性创新在于它引入了一套精密的内部结构来管理信息流。其核心思想可以归结为两点:
细胞状态 (Cell State, Ct): 这是LSTM的记忆主干。可以把它想象成一条贯穿整个时间序列的信息传送带。信息可以在这条传送带上非常顺畅地流动,只进行少量的线性操作,从而保证长期信息能够被完整地保存下来。
门控机制 (Gating Mechanism): LSTM设计了三个智能的“门”(阀门),来控制信息在这条高速公路上的进出。这些门都是小型的神经网络,它们可以学习在何时、让多少信息通过。这三个门分别是:
遗忘门 (Forget Gate)
输入门 (Input Gate)
输出门 (Output Gate)
智能开关的本质:激活函数
我们所说的“门”或“开关”,在神经网络中,本质上是由激活函数控制的全连接层。LSTM主要使用了两种激活函数,它们分工明确:
Sigmoid函数 (σ): 它的输出范围是 0 到 1。这个特性使它成为完美的开关。
当输出为 0 时,代表“关闭阀门”,不允许任何信息通过。
当输出为 1 时,代表“打开阀门”,让所有信息通过。
当输出在 0 和 1 之间时,代表“半开阀门”,按比例让信息通过。 我们所有的“门”(遗忘门、输入门、输出门)都将使用它作为最终的激活函数。
Tanh函数 (双曲正切函数): 它的输出范围是 -1 到 1。这个特性使它非常适合用来描述状态或创建内容。
它可以表示正向、负向或中性的信息。它将输入数据规范化到一个中心化的范围内,这对于网络内部的状态表示非常有利。
现在,我们来详细解剖这些结构是如何协同工作的。
(上一个细胞状态 C_{t-1})|v
<----(传递记忆)---- [ LSTM 单元 ] ----(传递记忆)---->h_{t-1}, x_t | | h_t, C_t(输入) | | (输出)v v(丢弃旧信息) (添加新信息)在任意一个时间步 t,LSTM单元都会接收三个输入:
当前输入 x_t
上一个时间步的隐藏状态(工作记忆)h_t−1
以及上一个时间步的细胞状态(长期记忆)C_t−1
然后通过以下四个步骤,计算出新的 h_t 和 C_t。
第1步:遗忘门:决定要忘记什么
此门的核心任务是审视输入信息,并决定应该从长期记忆(细胞状态 C_t−1)中丢弃哪些内容。
公式:
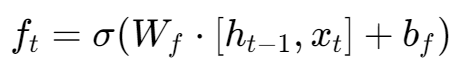
[h_{t-1}, x_t]: 这是此门的输入。它将h_t−1和x_t拼接在一起.
W_f, b_f: 这是遗忘门的权重和偏置。它们是模型通过大量数据训练学来的“智慧”,模型靠它们来判断什么信息在什么情况下是需要被遗忘的。
sigma(...): 最终通过Sigmoid函数,生成一个遗忘向量 f_t。这个向量里的每个元素都是0到1之间的数字,它将与旧的长期记忆 Ct−1 进行相乘,从而实现“按比例遗忘”。
第2步:输入门 (Input Gate) :决定要记住什么
此门负责处理新信息,并决定将哪些内容更新到长期记忆中。这个过程分为两部分。
a) 筛选要更新的信息 首先,一个Sigmoid层(输入门)决定了我们要更新哪些维度的值。 公式:
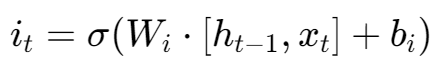
和遗忘门一样,它看着相同的输入,但使用自己独立的权重 Wi 来学习“什么信息是重要的、值得被记录的”。其输出 i_t 是一个0到1的开关向量。
b) 创建要写入的新内容 然后,一个tanh层创建一个新的候选记忆向量 C~t,它包含了所有可能被添加的新内容。
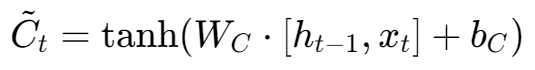
这里的关键是使用了 tanh 函数。它将新信息处理成一个范围在-1到1之间的向量,这是一种标准化的、适合存入记忆网络的状态。
第3步:更新细胞状态 (Update Cell State) : 执行记忆更新
这是LSTM核心的一步。它将旧的记忆与经过筛选的新记忆结合,生成全新的长期记忆 Ct。
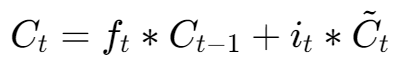
这里的 * 代表逐元素相乘
ft∗Ct−1: 这是忘记的部分。旧的长期记忆 Ct−1 与“遗忘向量”ft 相乘,那些被标记为“遗忘”(ft 中接近0的元素)的旧信息就被清除了。
it∗C~t: 这是写入的部分。“候选记忆向量”C~t 与“输入门开关”it 相乘,只有那些被认为重要的信息才能被保留下来准备写入。
最后,将“遗忘”后剩下的旧记忆与“筛选”后留下的新记忆相加,就得到了更新后的、全新的长期记忆 Ct。
第4步:输出门 (Output Gate):
最后,模型需要根据更新后的长期记忆 Ct 来决定当前时间步的输出,也就是ht。
a) 决定要输出哪些信息 一个Sigmoid层(输出门)决定细胞状态的哪些部分是对当前任务有用的。 公式:
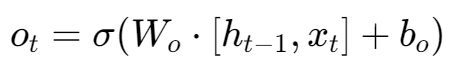
b) 生成最终输出 我们将更新后的细胞状态 Ct 通过一个tanh函数进行规范化,然后与输出门的开关 ot 相乘,得到最终的输出 ht。
公式:
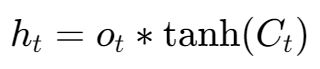
ht 就是LSTM单元在这一时刻的最终输出。它既是当前时刻的“工作重点”,也会作为输入传递给下一个时间步,继续影响后续的决策。
至此,我们已经打开了LSTM的黑盒,看到了它内部由Sigmoid门和Tanh内容生成器组成的精密结构。我们理解了信息是如何通过遗忘、筛选、写入、相加、输出这一系列步骤,在长期记忆(细胞状态 Ct)和短期记忆(隐藏状态 ht)之间流动和更新的。
这种设计使得长期记忆 Ct 的变化是平缓的、加性的,而短期记忆 ht 则是根据当前任务动态生成的,这正是LSTM能够克服“健忘”的根本原因。
第三部分:深入LSTM原理
1. 问题之源:标准RNN梯度流动的“先天缺陷”
要理解LSTM的巧妙,我们必须先看清标准RNN的死穴。回忆一下RNN的隐藏状态更新公式:
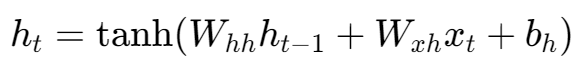
在训练过程中,当梯度从后向前传播时(BPTT),它需要通过链式法则计算。从 ht 到 ht−1 的梯度会包含一项对 Whh 的乘法。这意味着,当梯度从序列末端传向开端时,它会不断地、重复地乘以这个相同的权重矩阵 Whh。
这就导致了:
梯度消失 (Vanishing): 如果权重矩阵 Whh 的某些特性(技术上说是其雅可比矩阵的最大奇异值)小于1,经过多次连乘后,梯度会以指数级速度衰减,迅速趋近于0。这使得模型无法根据遥远的过去来进行参数更新。
梯度爆炸 (Exploding): 反之,如果该值大于1,梯度会指数级增长,导致训练过程极其不稳定。
这个连乘效应是RNN的先天缺陷,它使得梯度流动的路径非常崎岖和危险。
2. LSTM的解决方案:梯度流动的快捷通道
现在,让我们聚焦于LSTM最核心的细胞状态更新公式:
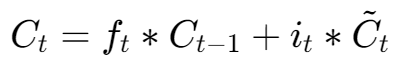
让我们思考一下,当梯度从 Ct 反向传播到 Ct−1 时会发生什么。
对上述公式求导,我们会发现:
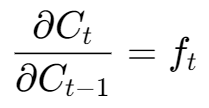
这意味着,从 Ct 到 Ct−1 的梯度传递,仅仅是和遗忘门 ft 的输出进行了一次简单的逐元素相乘。
梯度在长期记忆(细胞状态)这条路径上反向传播时,不再需要反复乘以一个固定的、复杂的权重矩阵 W。取而代之的是,它在每个时间步乘以一个动态的、由数据驱动的“开关”向量 ft。
梯度的快速路: 如果遗忘门 ft 学会了在需要保留长期记忆时,让其输出的许多元素都接近1,那么梯度就可以几乎毫无衰减地沿着这条路径传递回去。这就好比为梯度专门开辟了一条“高速公路”,让它安全、稳定地到达遥远的过去。
智能的流量控制: 遗忘门 ft 就像是这条高速公路上的智能收费站。它可以在每个时间点,根据当前情况,动态地决定让多少梯度“流量”通过。它学会了保护重要的历史信息,并丢弃不重要的。
通过这种方式,LSTM成功地将梯度流从复杂的非线性计算中解耦出来,放在一个简单的、加性的、可控的路径上,从而解决了梯度消失问题。
第四部分:pytorch逐行讲解实现
这次我们举例使用Seq2Seq模型应用,以对应我们前文Transformer,有助于理解.
因为这是一个教学示例,为了让代码尽可能清晰易懂,我们会做一些简化:
字符级 (Character-level):我将把单词拆成字符来进行处理。例如,"go" -> 'g', 'o'。这样做的好处是不需要庞大的词典,能让我们专注于模型结构本身。
小数据集:我们只用几句话作为示例,这样可以快速地在CPU上完成训练并看到结果。
这篇讲解会非常长,但会包含所有必要的步骤和逐行解释。
整体步骤
准备数据:加载数据,创建字符词典,将文本转换为数字张量。
构建模型:分别定义Encoder、Decoder和将它们组合在一起的Seq2Seq模型。
训练模型:编写训练循环,定义优化器和损失函数,开始训练。
评估与推理:编写一个函数来实际进行翻译,看看我们模型的效果。
第1步: 准备数据 (Data Preparation)
我们首先要明白,计算机本身不认识 'h'、'e'、'l'、'l'、'o' 这些字符,更不认识 ‘你’、‘好’。它的世界里只有数字。
所以,数据准备的唯一目的,就是建立一套规则,把像 'hello' 这样的字符串,严谨地转换成计算机能处理的数字列表,比如 [5, 6, 7, 7, 8]。
我们需要定义我们的原始数据,并将其处理成模型能够接受的数字格式。
1.定义微型数据集
import torch
import torch.nn as nn
import torch.optim as optim
import random# 格式:[英文, 中文]
raw_data = [['hello', '你好'],['i am a student', '我是一个学生'],['how are you', '你好吗'],['good morning', '早上好'],['see you later', '待会见'],
]2. 定义特殊符号
# SOS: Start of Sequence,句子的开始
# EOS: End of Sequence,句子的结束
# PAD: Padding,用于填充,使所有句子长度一致
SOS_token = 0
EOS_token = 1
PAD_token = 23. 创建字符词典 ,我们需要为源语言(英文)和目标语言(中文)分别创建词典
Lang 类: 这是一个辅助类,用来构建从字符到数字索引的映射。char2index是字符->索引的字典,index2char是索引->字符的字典,n_chars记录了词典的总大小。
class Lang:def __init__(self, name):self.name = nameself.char2index = {}self.index2char = {SOS_token: "SOS", EOS_token: "EOS", PAD_token: "PAD"}self.n_chars = 3 # 先算上SOS, EOS, PAD
#index2char 提前写入了三个固定映射,因此 n_chars 初始值为 3。def add_sentence(self, sentence): #作用:将句子中所有字符逐一添加到词典。for char in sentence: # 遍历句子中的每个字符self.add_char(char)def add_char(self, char):if char not in self.char2index: # 检查字符是否为新字符self.char2index[char] = self.n_chars# 为新字符分配当前 n_chars 值self.index2char[self.n_chars] = charself.n_chars += 1 # 计数器 +1
4. 准备源语言和目标语言的词典实例
input_lang = Lang('eng')
output_lang = Lang('chi')
# 创建两个空的 Lang 对象,即两本空词典for eng_sent, chi_sent in raw_data:input_lang.add_sentence(eng_sent)output_lang.add_sentence(chi_sent)
# 遍历原始数据,填充这两本词典展示一下试试:
print(f"英文词典大小: {input_lang.n_chars}")
print(f"中文词典大小: {output_lang.n_chars}")
print(f"英文 'h' 的索引: {input_lang.char2index['h']}")
print(f"中文 '好' 的索引: {output_lang.char2index['好']}")此时我们的原始句子 'hello' 和 '你好' 本身,还依然是文字,它们并没有被改变。
5.定义两个辅助函数
现在我们有了词典这个“工具”,但我们的最终目的是要得到一个全是数字的数据集,而不是词典本身。所以,第4步我们重新回到 raw_data,拿出第一句 'hello',然后翻开我们刚刚在第3步做好的 input_lang 词典,一个一个地查:'h' -> 3, 'e' -> 4, 'l' -> 5, 'l' -> 5, 'o' -> 6。然后把查到的数字 [3, 4, 5, 5, 6] 记录下来。
# 将句子转换为索引列表的辅助函数
def sentence_to_indexes(lang, sentence):return [lang.char2index[char] for char in sentence]
# 对于每个字符,去指定的lang词典的char2index里查找它对应的数字ID。# 将索引列表转换为句子的辅助函数
def indexes_to_sentence(lang, indexes):return ''.join([lang.index2char[idx] for idx in indexes])
将所有数据转换为索引对
indexed_pairs = []
for eng_sent, chi_sent in raw_data:# 每个句子后面都要加上结束符input_indexes = sentence_to_indexes(input_lang, eng_sent) + [EOS_token]output_indexes = sentence_to_indexes(output_lang, chi_sent) + [EOS_token]indexed_pairs.append((input_indexes, output_indexes))# 打印一个例子看看
print("\n数据转换示例:")
print(f"原始句对: {raw_data[0]}")
print(f"索引句对: {indexed_pairs[0]}")indexed_pairs: 这是我们最终处理好的数据集,原始的文本对已经被转换成了数字列表对,可以直接被模型使用了。
第2步: 构建模型 (Building the Model)
现在我们来定义Seq2Seq模型的三个核心部分:Encoder, Decoder, 和将它们组合起来的Seq2Seq主模型。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")编码器部分::
__init__: 初始化了两个关键层。nn.Embedding负责将输入的数字(如5)变成一个有意义的、稠密的向量(比如一个128维的向量)。nn.LSTM是我们的循环网络核心。
输出:
output:每个时间步的隐藏状态([seq_len, batch, hidden_size])
(h_n, c_n):最终时间步的隐藏状态和细胞状态(上下文向量)
class Encoder(nn.Module):def __init__(self, input_size, embedding_dim, hidden_size):super(Encoder, self).__init__()self.hidden_size = hidden_size# 嵌入层: 将输入的数字索引转换为密集向量self.embedding = nn.Embedding(input_size, embedding_dim)# LSTM层: 核心的循环神经网络self.lstm = nn.LSTM(embedding_dim, hidden_size)forward: 定义了前向传播。它接收一个数字序列,先通过嵌入层,然后送入LSTM。我们只关心LSTM最后的隐藏状态hidden和细胞状态cell,因为它们就是包含了整个句子信息的“上下文向量”。
def forward(self, input_seq):# input_seq: [seq_len] -> 转换为 [seq_len, 1] 以符合LSTM输入要求input_seq = input_seq.view(-1, 1)# 1. 嵌入: [seq_len, 1] -> [seq_len, 1, embedding_dim]embedded = self.embedding(input_seq)# 2. LSTM处理# 我们不需要中间的outputs,只需要最后的hidden和cell状态# outputs: [seq_len, 1, hidden_size]# hidden, cell: [1, 1, hidden_size]outputs, (hidden, cell) = self.lstm(embedded)# 3. 返回最终的隐藏状态和细胞状态作为上下文向量return hidden, cellDecoder:
__init__: 与Encoder类似,但多了一个nn.Linear全连接层和nn.LogSoftmax层。nn.Linear负责将LSTM的输出(通常是隐藏层维度,如256)映射回我们的目标词典大小(比如中文有30个字符,就映射到30维),每一维代表一个字符的得分。LogSoftmax则将这些得分转换成对数概率。forward: 解码器的工作方式是一次只处理一个字符。它接收当前的输入字符和上一步的hidden,cell状态,然后输出对下一个字符的预测,以及更新后的hidden,cell状态。
用deepseek生成一下网络图,有助于帮助大家理解:
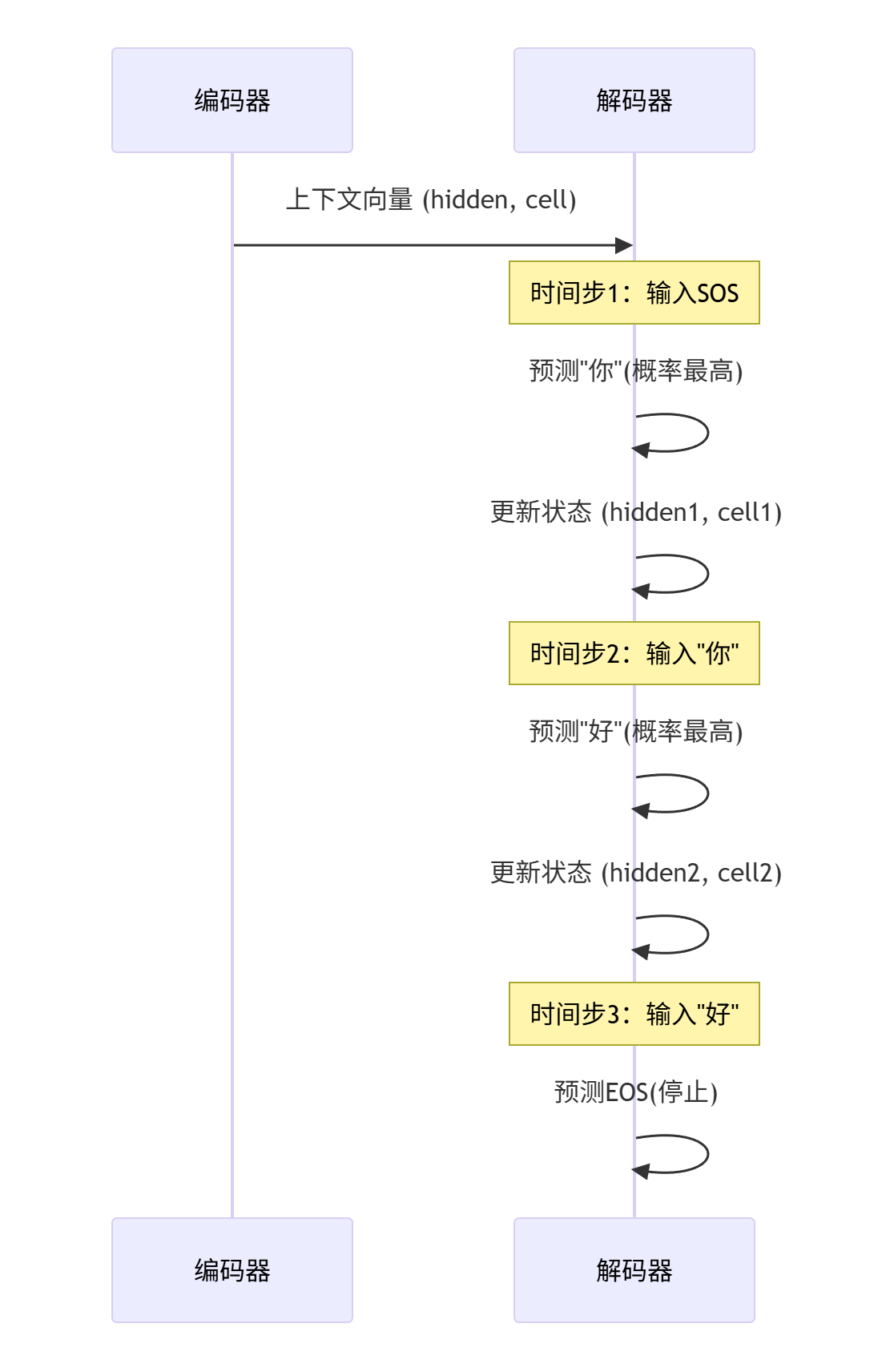
class Decoder(nn.Module):def __init__(self, output_size, embedding_dim, hidden_size):super(Decoder, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(output_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_size)# 全连接层: 将LSTM的输出映射回词典大小,用于预测下一个字符self.out = nn.Linear(hidden_size, output_size)# LogSoftmax: 用于计算对数概率self.softmax = nn.LogSoftmax(dim=1)def forward(self, input_char, hidden, cell):# input_char: [1] -> 转换为 [1, 1]input_char = input_char.view(1, -1)# 1. 嵌入: [1, 1] -> [1, 1, embedding_dim]embedded = self.embedding(input_char)# 2. LSTM处理 (解码器一次只处理一个字符)# output: [1, 1, hidden_size]# hidden, cell: [1, 1, hidden_size]output, (hidden, cell) = self.lstm(embedded, (hidden, cell))# 3. 预测下一个字符# output.squeeze(0): [1, hidden_size]prediction = self.softmax(self.out(output.squeeze(0)))return prediction, hidden, cell
Seq2Seq 主模型 :
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super(Seq2Seq, self).__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self, src_seq, trg_seq, teacher_forcing_ratio=0.5):# src_seq: 源句子索引序列# trg_seq: 目标句子索引序列trg_len = len(trg_seq)trg_vocab_size = self.decoder.out.out_features# 用于存储解码器每一步的输出outputs = torch.zeros(trg_len, trg_vocab_size).to(self.device)# 1. 编码器处理整个输入序列,得到上下文向量encoder_hidden, encoder_cell = self.encoder(src_seq)# 2. 解码器的第一个输入是 <SOS> 符号decoder_input = torch.tensor([SOS_token], device=self.device)# 3. 将编码器的最终状态作为解码器的初始状态decoder_hidden, decoder_cell = encoder_hidden, encoder_cell# 4. 循环生成输出序列for t in range(trg_len):# 调用解码器生成一步的输出decoder_output, decoder_hidden, decoder_cell = self.decoder(decoder_input, decoder_hidden, decoder_cell)# 存储这一步的输出outputs[t] = decoder_output# 决定下一个输入是"真实标签"还是"模型自己的预测"# 这就是 Teacher Forcing 技术teacher_force = random.random() < teacher_forcing_ratio# 获取概率最高的预测字符top1 = decoder_output.argmax(1)# 如果是Teacher Forcing,下一个输入是真实的目标字符;否则是模型自己的预测decoder_input = trg_seq[t] if teacher_force else top1return outputsSeq2Seq:
__init__: 这个主模型很简单,就是把encoder和decoder作为自己的成员。forward: 这是整个模型的核心逻辑。先调用
encoder处理源序列,得到上下文向量。然后,将上下文向量作为
decoder的初始状态。解码器的第一个输入永远是特殊的
SOS_token。进入循环,一步步生成输出。
Teacher Forcing: 这是一个非常重要的训练技巧。在训练时,我们有一定概率(
teacher_forcing_ratio)直接将正确的答案(trg_seq[t])作为解码器的下一步输入,而不是使用它自己上一部的预测。这样做可以帮助模型在早期更快、更稳定地收敛。在推理时,这个比例必须是0。
第3步: 训练模型 (Training the Model)
现在模型已经定义好了,我们可以编写训练逻辑来教它如何翻译。
# --- 定义超参数 ---
INPUT_SIZE = input_lang.n_chars
OUTPUT_SIZE = output_lang.n_chars
EMBEDDING_DIM = 64
HIDDEN_SIZE = 128
N_EPOCHS = 1000
LEARNING_RATE = 0.005
PRINT_EVERY = 100# --- 实例化模型 ---
encoder = Encoder(INPUT_SIZE, EMBEDDING_DIM, HIDDEN_SIZE).to(device)
decoder = Decoder(OUTPUT_SIZE, EMBEDDING_DIM, HIDDEN_SIZE).to(device)
model = Seq2Seq(encoder, decoder, device).to(device)# --- 定义优化器和损失函数 ---
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# Negative Log Likelihood Loss,与 LogSoftmax 配合使用
criterion = nn.NLLLoss()# --- 开始训练 ---
print("\n开始训练...")
for epoch in range(1, N_EPOCHS + 1):epoch_loss = 0# 从数据集中随机选择一个句对进行训练input_indexes, output_indexes = random.choice(indexed_pairs)# 转换为PyTorch张量input_tensor = torch.tensor(input_indexes, dtype=torch.long, device=device)output_tensor = torch.tensor(output_indexes, dtype=torch.long, device=device)# 清空梯度optimizer.zero_grad()# 模型前向传播outputs = model(input_tensor, output_tensor)# 计算损失# NLLLoss要求输入是(N, C)和(N)# outputs: [trg_len, vocab_size]# output_tensor: [trg_len]loss = criterion(outputs, output_tensor)# 反向传播loss.backward()# 更新权重optimizer.step()epoch_loss += loss.item()if epoch % PRINT_EVERY == 0:print(f"Epoch {epoch}/{N_EPOCHS}, Loss: {epoch_loss:.4f}")超参数: 定义了模型和训练过程中的一些关键数字,如嵌入维度、隐藏层大小、训练轮数等。
实例化: 创建了
encoder,decoder, 和model的实例,并用.to(device)将它们移动到GPU或CPU上。优化器和损失函数:
Adam是一种常用的、效果很好的优化器。NLLLoss是专门用来处理分类问题的损失函数,当模型的最后一层是LogSoftmax时,用它正合适。训练循环:
我们这里为了简单,每次只从数据集中随机取一个样本来训练(这叫随机梯度下降,Stochastic Gradient Descent)。在实际项目中,我们会用
DataLoader来进行小批量(mini-batch)训练。optimizer.zero_grad(): 每次计算梯度前,必须先将之前的梯度清零。model(...): 调用模型,得到预测输出。criterion(...): 计算模型的预测outputs和真实标签output_tensor之间的差距(损失)。loss.backward(): PyTorch会自动计算所有参数的梯度。optimizer.step(): 根据计算出的梯度,更新模型的所有参数(权重)。
第4步: 评估与推理 (Evaluation and Inference)
模型训练好了,我们得看看它到底学会了没有。推理函数和训练函数最大的不同在于,Teacher Forcing必须关闭。
def evaluate(src_sentence):# 将模型设置为评估模式model.eval()with torch.no_grad(): # 在评估时,我们不需要计算梯度input_indexes = sentence_to_indexes(input_lang, src_sentence) + [EOS_token]input_tensor = torch.tensor(input_indexes, dtype=torch.long, device=device)# 编码encoder_hidden, encoder_cell = model.encoder(input_tensor)# 解码初始化decoder_input = torch.tensor([SOS_token], device=device)decoder_hidden, decoder_cell = encoder_hidden, encoder_celldecoded_indexes = []max_length = 20 # 设置一个最大长度,防止无限循环for _ in range(max_length):decoder_output, decoder_hidden, decoder_cell = model.decoder(decoder_input, decoder_hidden, decoder_cell)# 选择概率最高的字符topv, topi = decoder_output.topk(1)# 如果是结束符,就停止if topi.item() == EOS_token:decoded_indexes.append(EOS_token)breakelse:decoded_indexes.append(topi.item())# 下一步的输入是当前预测的字符decoder_input = topi.squeeze().detach()return indexes_to_sentence(output_lang, decoded_indexes)# --- 测试几个例子 ---
print("\n开始评估...")
for eng_sent, chi_sent in raw_data:translated_sent = evaluate(eng_sent)print(f"源文: {eng_sent}")print(f"真值: {chi_sent}")print(f"翻译: {translated_sent}")print("-" * 20)推理循环:
编码部分和训练时一样。
解码部分,我们创建了一个
decoded_indexes列表来收集翻译结果。循环的每一步,我们都用
decoder_output.topk(1)或.argmax(1)来获取概率最高的那个字符的索引topi。我们检查
topi是否是EOS_token,如果是,就说明翻译结束,跳出循环。最关键的一步:
decoder_input = topi.squeeze().detach()。这里,解码器必须使用它自己上一步的预测结果作为下一步的输入,完全没有“老师”来纠正它。.detach()是为了切断计算图,因为我们不需要对这个操作进行反向传播。
最后: 我们将收集到的索引列表转换回中文字符串,并打印出来与真实标签进行对比。
由于我们的数据集和模型都非常小,翻译结果可能不完美,希望大家可以从中学习到LSTM的核心思想。