分布式系统的基石:ZooKeeper架构设计与实战指南
摘要
本文系统剖析了ZooKeeper作为分布式协调服务的核心机制与最佳实践。从ZAB协议的强一致性实现、树形数据模型的节点特性,到Watch机制和选举算法,层层深入其设计原理。结合分布式锁、服务发现等典型场景,对比分析与其他组件(如Flink、Dubbo)的集成方案,并提供生产级配置调优参数与异常处理经验。通过理论结合实践,帮助开发者掌握ZooKeeper在高并发、高可用系统中的关键作用。
一、核心定义
1. 分布式协调服务
- 提供统一的命名服务、配置管理、分布式锁、集群管理等功能,充当分布式系统的"指挥中心"。
- 基于ZAB协议(ZooKeeper Atomic Broadcast)实现强一致性。
2. 核心特性
特性名称 | 技术实现原理 | 应用场景示例 |
顺序一致性 | 通过全局单调递增的zxid(64位事务ID)保证所有事务操作严格有序,客户端看到的更新顺序与服务器处理顺序完全一致 | 分布式锁实现、Master选举等需要严格操作顺序的场景 |
原子性 | 基于ZAB协议的2PC(两阶段提交)机制,确保事务要么在所有节点成功提交,要么全部回滚 | 配置更新、状态同步等需要完整性的操作 |
单一系统映像 | 通过Leader统一处理写请求+Follower数据同步机制,保证所有节点数据视图最终一致 | 服务发现、配置中心等需要全局一致性的场景 |
可靠性 | 写操作持久化到磁盘日志+内存数据快照,支持故障恢复后数据重建 | 关键配置存储、元数据管理等需要持久化的场景 |
二、数据模型
1. 基本结构
- 树形层次化命名空间:采用类似文件系统的结构,每个节点称为ZNode
- 节点标识:通过类似文件路径的绝对路径唯一标识(如/services/order),必须以斜杠开头,支持Unicode字符
2. 核心特性
- 与文件系统的关键区别
- 兼具文件和目录特性:既可存储数据又可包含子节点。
- 原子性操作:读写操作针对整个节点数据。
- 节点类型支持:
- 持久节点(Persistent):显式删除才消失
- 临时节点(Ephemeral):会话结束自动删除
- 顺序节点(Sequential):自动附加递增序号
3. 节点类型详解
类型 | 生命周期 | 顺序性 | 典型应用场景 |
持久节点 | 显式删除才消失 | 无 | 配置信息存储 |
临时节点 | 会话结束自动删除 | 无 | 服务注册发现 |
持久顺序节点 | 显式删除才消失 | 自动附加递增序号 | 分布式任务队列 |
临时顺序节点 | 会话结束自动删除 | 自动附加递增序号 | 分布式锁实现 |
4. ZNode组成要素
要素名称 | 数据类型 | 描述 | 功能作用 | 示例/取值范围 |
数据内容(Data) | byte[] | 节点存储的实际数据 | 存储配置信息、状态数据等 | 最大1MB(默认配置) |
访问控制列表(ACL) | List<ACL> | 节点的权限控制列表 | 定义访问及操作权限 | [scheme:id:permissions] |
元数据(Stat) | Stat结构体 | 包含13个属性字段 | 记录节点状态和版本信息 | 详见元数据子表 |
子节点列表 | List<String> | 直接子节点的名称集合 | 维护节点层次结构 | ["child1", "child2"] |
5. 元数据(Stat)关键字段
字段名 | 类型 | 描述 | 作用场景 |
czxid | long | 创建该节点的事务ID | 全局唯一操作标识 |
mzxid | long | 最后修改该节点的事务ID | 数据变更追踪 |
ctime | long | 节点创建时间戳(毫秒) | 节点生命周期管理 |
mtime | long | 节点最后修改时间戳 | 数据新鲜度判断 |
version | int | 数据版本号(修改次数) | 乐观锁控制(CAS) |
cversion | int | 子节点版本号 | 子节点变更追踪 |
aversion | int | ACL版本号 | 权限变更追踪 |
ephemeralOwner | long | 临时节点所属会话ID(0表示持久节点) | 会话绑定管理 |
dataLength | int | 节点数据长度(字节) | 存储监控 |
numChildren | int | 子节点数量 | 树形结构维护 |
pzxid | long | 最后修改子节点的事务ID | 子树变更追踪 |
三、核心机制
1. ZAB协议(ZooKeeper Atomic Broadcast)
设计目标:实现分布式系统的原子广播协议,保证数据一致性和可靠性
a. 崩溃恢复模式
选主流程:
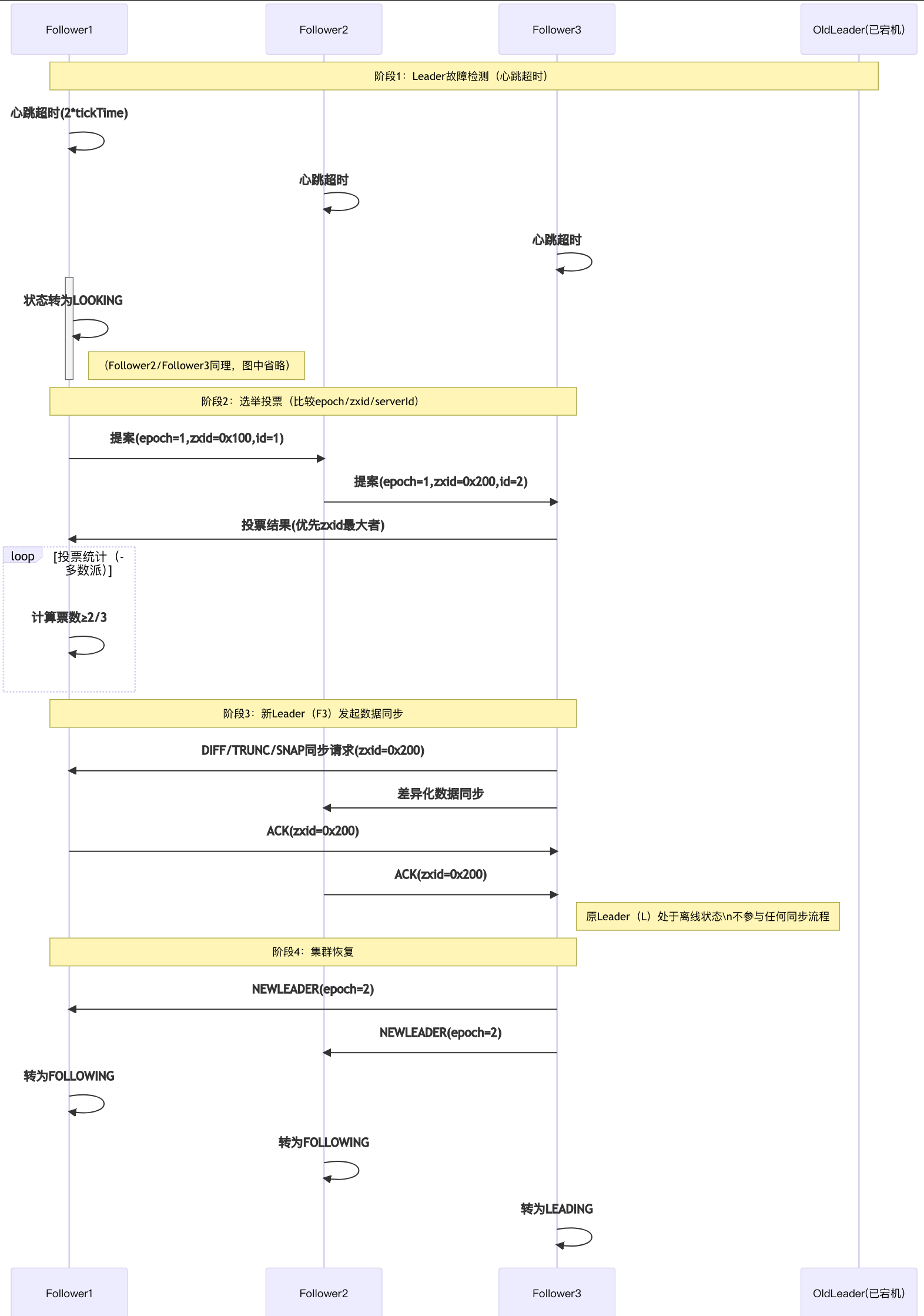
- 选主流程:
- 节点进入LOOKING状态
- 比较epoch(任期编号)、zxid(事务ID)和serverId
- 获得半数以上投票的节点成为Leader
- 数据同步:
- 新Leader确定后进入同步阶段
- 通过DIFF差异同步、TRUNC截断同步或SNAP全量同步方式
- 确保所有Follower与Leader数据完全一致
b. 消息广播模式
- 两阶段提交流程:
- Leader生成事务提案并分配zxid
- 将提案广播给所有Follower
- 收集Follower的ACK响应
- 收到半数以上ACK后提交事务
- 通知所有Follower提交事务
- 特点:
- 保证事务的原子性
- 支持消息的有序广播
2. Watch机制
a. 一次性触发特性
- 通知触发后自动失效
- 避免重复通知导致的"惊群效应"
- 客户端需要重新注册才能继续监听
b. 事件类型:
事件类型 | 触发条件 | 典型应用场景 |
NodeCreated | 节点创建 | 服务发现注册 |
NodeDeleted | 节点删除 | 服务下线通知 |
NodeDataChanged | 数据变更 | 配置更新通知 |
NodeChildrenChanged | 子节点变化 | 集群成员变更 |
c. 注意事项:
- 通知可能丢失(网络问题)
- 客户端必须处理连接断开后的状态重建
- 建议采用"获取数据+注册Watch"的原子操作模式
3. 选举算法
a. 比较规则(优先级从高到低):
- epoch(任期编号):数值越大优先级越高
- zxid(最后事务ID):数值越大数据越新
- serverId(配置ID):数值越大优先级越高
b. 选举要求:
- 必须获得集群半数以上投票
- 选举期间集群不可用(处于不可服务状态)
- 通常选举在200ms内完成
c. 集群容错能力:
节点总数 | 可容忍故障节点数 | 最少正常运行节点数 |
3 | 1 | 2 |
5 | 2 | 3 |
7 | 3 | 4 |
最佳实践:
- 奇数节点配置更优
- 跨机房部署需要考虑网络分区情况
对比维度 | 奇数节点优势 | 偶数节点问题 |
容错能力 | 相同容错下资源更少(如5节点≈6节点容错) | 资源浪费(如4节点容错=3节点) |
脑裂风险 | 天然避免对称分割 | 可能因网络分区导致完全不可用 |
选举效率 | 更快达成多数派 | 票数接近时可能延迟 |
写入性能 | 所需ACK数更少(如5节点需3票 vs 6需4票) | 更高延迟 |
四、典型应用场景
1. 分布式锁实现
实现原理:
- 利用ZK的临时顺序节点特性(EPHEMERAL_SEQUENTIAL)
- 通过节点序号判断锁获取顺序,避免惊群效应
关键点:
- 临时节点保证锁释放(连接断开自动删除)
- 顺序节点实现公平锁
- Watch机制减少轮询开销
2. 服务注册发现(Dubbo + ZK实战)
架构流程:
- 服务注册:Dubbo Provider启动时在ZK创建临时节
/dubbo/com.example.Service/providers/ └── host:port (临时节点,存储服务元数据) - 服务发现:Consumer监听节点变化,动态更新服务列表
- 故障剔除:Provider宕机时临时节点自动删除
ClickHouse集成示例(CK + ZK):
- 集群协调:CK使用ZK存储分片和副本元数据
- 服务发现:通过/clickhouse/tables/{table}/replicas路径管理副本状态
3. 配置中心(Spring Cloud + ZK)
实现方案:
- 存储结构:
/config/appname/ ├── db.url (持久节点) └── cache.size (持久节点) - 动态更新:
zk.getData("/config/appname/db.url", event -> { if (event.getType() == EventType.NodeDataChanged) { reloadConfig(); // 触发配置热更新 } }, null);
与Nacos对比优势:
- 强一致性:ZAB协议保证配置变更全局有序
- 事件驱动:Watch机制避免轮询
4. 大数据场景(Flink + ZK)
应用案例:
- Leader 选举:JobManager 主备节点切换时通过 ZooKeeper 选举新主节点
- 元数据存储:保存检查点(Checkpoint)和作业恢复所需的元数据
- 服务发现:TaskManager 动态发现 JobManager 地址
关键结论:
- Flink 1.12 之前:HA 必须依赖 ZooKeeper
- Flink 1.12 之后:Kubernetes 环境可通过原生机制替代 ZooKeeper
场景对比总结
场景 | ZK核心能力 | 框架集成示例 |
分布式锁 | 临时节点+Watch | Dubbo + ZK |
服务发现 | 临时节点+列表监听 | Dubbo/Spring Cloud |
配置中心 | 持久节点+数据监听 | Apollo/Nacos兼容层 |
大数据协调 | 选举+元数据存储 | Flink/ClickHouse |
五、生产实践问题
1. 集群部署建议
a. 节点数量:3/5/7(必须奇数)
- 奇数优势:避免脑裂,保证多数派决策。
- 生产推荐:中小规模用3节点,高可用场景用5节点,超大规模用7节点(需权衡资源成本)
b. JVM配置:-Xms4g -Xmx4g
- 堆内存设置:避免动态扩容开销,建议Xms=Xmx
- 调优建议:
- 监控GC日志,避免Full GC频繁(如-XX:+UseG1GC -XX:MaxGCPauseMillis=200)
- 堆外内存限制:-XX:MaxDirectMemorySize=1g(防止Netty堆外内存泄漏)
c. 磁盘选择:SSD保证ZAB协议性能
- ZAB协议依赖:事务日志(WAL)写入性能直接影响吞吐量
2. 性能调优参数
关键参数示例:
tickTime=2000 # 基础时间单元(ms),影响心跳检测和会话超时
autopurge.snapRetainCount=5 # 保留的快照数,避免磁盘爆满
preAllocSize=65536 # 预分配事务日志文件块大小(字节)
maxClientCnxns=1000 # 单节点最大连接数(根据业务规模调整)
syncLimit=5 # follower同步超时的tick次数
globalOutstandingLimit=1000 # 全局请求队列限制
调优原则:
- 低延迟场景:减小tickTime(如1000ms),但会增加CPU负载
- 高吞吐场景:增大preAllocSize,减少磁盘碎片化
3. 常见异常处理
a. CONNECTION_LOSS
- 原因:网络抖动或ZK节点短暂不可用
- 解决方案:
- 客户端实现自动重试(如Curator的RetryPolicy)
- 检查网络延迟和防火墙规则
b. SESSION_EXPIRED
- 原因:心跳超时(通常因GC暂停或网络分区)
- 解决方案:
- 重建会话并恢复临时节点(需业务层容错设计)
- 调整sessionTimeout(建议≥10s)
c. AUTH_FAILED
- 原因:ACL权限配置错误或凭证失效
- 解决方案:
- 检查addauth指令(如digest:user:password)
- 使用getAcl命令验证节点权限
六、总结
技术总结:ZooKeeper通过ZAB协议的原子广播与崩溃恢复机制,构建了高可靠的分布式协调服务。其树形数据模型(ZNode)与Watch机制的组合,为分布式锁、服务发现等场景提供了标准化解决方案。
实践建议:
- 生产部署时需关注initLimit与磁盘I/O配置,避免选举超时;
- 临时节点与会话管理是服务注册场景的核心优化点;
- 建议结合Kubernetes StatefulSet实现云原生高可用部署。
演进方向:随着服务网格技术发展,ZooKeeper在轻量化场景中可能面临etcd等组件的竞争,但其强一致性模型仍是大规模分布式系统的首选基石。
扩展思考:如何设计一个兼顾性能与一致性的ZK集群跨机房部署方案?