定点数 与 浮点数
定点数:
小数点固定;例如 「 Q3.12 」描述的是一个整体长度为16位的2进制有符号定点数,它的整数部分长度是3,而小数部分长度是12。根据小数部分的长度,可以推断出分辨率为 2^-12。
浮点数:
利用二进制的科学计数法表示, 因此小数点可以浮动(小数点受阶码E编码, 因此阶码运算后,小数点自然浮动), 可以对标十进制的科学计数法去理解二进制浮点数;
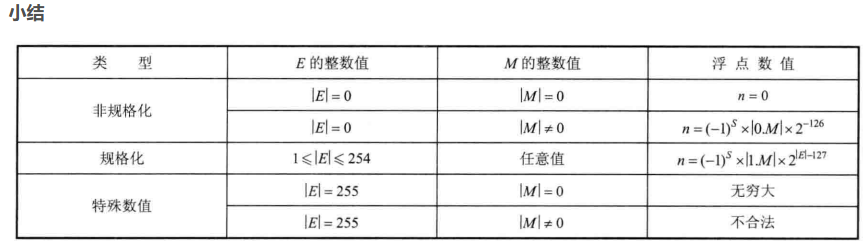
浮点数转定点数
请重点理解分辨率这个概念(小数点决定二进制小数分辨率, 十进制小数转二进制是存在误差的,因此有转换精度的概念)
- 对于整数二进制, 分辨率为1, 因此d100–> d100/1=d100(份)–>b1100100 * 1 =b1100100(根据分辨率2^0移位)
- 对于小数二进制, 假设小数点保留五位, 则小数精度(分辨率)为2^-5, 因此d100.1415 --> d100.1415 / 2^-5 = d3,204.528(份)–> d3204(取整) = b1100 1000 0100 --> 结果b1100100.00100(小数点左移5位)
- 请注意, 这里和数电中十进制转二进制方法(整数除2,小数乘2, 根据需要取小数点)的区别, 流程变为, 先定好小数点, 将原数/分辨率再取整, 转为二进制, 根据分辨率移动二进制小数点
- 再以二进制浮点数转二进制定点数为例(定点, 移位, 取整):
- 定规则:确定小数部分位数 n(如 n=3)。左移 n 位:二进制浮点数左移 n 位(对应前面的原数/分辨率),将小数部分 “挪” 到整数位(相当于 ×(2^n))。取整:对移位后的数截断或四舍五入,保留整数部分。插小数点:在整数结果的右侧第 n 位插入小数点,得到二进制定点数。
-
举个例子:把二进制浮点数 101.001101 转成 “小数部分 3 位” 的二进制定点数
步骤 1:明确定点化规则,指定小数部分保留 n=3 位(整数部分位数根据数值范围自动确定)。
步骤 2:“放大” 二进制浮点数(左移 n 位,去掉小数点)二进制的 “放大 (2^n) 倍” 等价于 向左移动 n 位小数点:原数 101.001101(二进制),左移 3 位后 → 101001.101(小数点移到整数部分末尾)。
步骤 3:取整(截断或四舍五入)移完后若有小数部分,根据精度需求处理:
这里 101001.101 的小数部分是 101(二进制),若截断则保留整数部分 101001;若四舍五入(二进制中末位≥1 则进 1),101 对应十进制 5≥4,所以进 1 → 101010。
步骤 4:还原成定点数(固定小数点位置)将整数结果按 “小数部分 3 位” 插回小数点:截断后:101001 → 从右数 3 位插小数点 → 101.001(二进制)四舍五入后:101010 → 插小数点 → 101.010(二进制)
无损定点化
这里再引入一个无损定点化的概念,所谓【无损定点化】只是数学概念,==只要量化误差小于精度的一半,就认为是“无损”的。==按照这个标准,那对小数点采取四舍五入的结果必然是无损的。但是校招时很多题采取的是“量化后直接去除小数”,即我前面提到的直接去掉小数部分,那么最终的结果小数部分大于 0.5 则不是无损的了。
什么意思?
我还是拿 3.1415举例,定点化过程中首先利用公式:定点数 = 浮点数 × 2^小数位数(按5位), 3.1415 × 2 ^ 5 = 100.528,这里的小数部分大于了0.5,那么我们如果直接舍弃,就可以认为这个转化是有损的,当然我们也可以计算出他的量化误差:0.528/28=0.0020625,很明显这个值是大于量化精度的一半29=0.0019531,所以是有损的,用这两种办法我们都可以用来判断转化有损还是无损,位宽是否合适等。
定点数到浮点数
还是要先说明,这个浮点数不是IEEE754规定的浮点数,仅指10进制小数,显然这就是定点化的逆过程。以 定点数0_0011_00100 的转换为例:
首先需要确定该定点数的规格,假设其规格如下:1位符号位 + 4位整数部分 + 5位小数部分
符号位为0说明这是一个正数
整数部分的值为0011,即10进制的3
小数部分的值为00100,即10进制的0.125(可以理解为0.03125×4)
综合起来的结果就是 +3.125
整个过程相对简单,只要将整数部分和小数部分分别从2进制转换为10进制,再结合起来即可。
定点数据的两种溢出处理模式
两种常见的溢出处理方式:Saturate(饱和)和Wrap(绕回/截断)。
饱和处理 (Saturate)
饱和逻辑是当数据超过能够表示的范围时,直接将结果固定在最大值或最小值。
例如,假设你有8位有符号数(范围为-128到127),如果运算结果为150,那么饱和处理会将它限制为127(正向溢出),如果结果为-200,则饱和为-128(负向溢出)。
绕回处理 (Wrap / 截断)
绕回处理是直接忽略溢出的高位,只保留符合当前位宽的部分。例如,对于一个8位无符号数(范围为0到255),如果运算结果为300,二进制表示为100101100,那么系统只保留低8位,结果为00101100,即十进制44。
尽管饱和和绕回的处理不能保留原本正确的数值,但它们的目的并不是为了提供精确的数学结果,而是为了保证在硬件资源有限的情况下(如固定位宽)能有效处理溢出,避免程序崩溃或不稳定。
怎么尽可能的保留原本正确的溢出数值?
1、增加位宽(扩展数据位宽)
解决方案:如果系统允许,增加数据处理的位宽。例如,从8位扩展到16位或32位。
2、多字节存储(进位)
通过使用多个字节来存储超出位宽的数据,这样当数据溢出时,能够利用额外的字节来存储溢出的部分,从而保持正确的结果。
假设我们在一个8位无符号系统中表示的最大数是255。如果两个数相加会超过255,就会发生溢出。比如:
200+100=300,但8位系统只能表示到255,所以结果会变为44(300 - 256)。
那我们就可以将数据分为高位字节和低位字节来表示:
300可以表示为两个字节:高位字节1(表示256的一部分)和低位字节44(D)(剩余部分)。
高位字节存储溢出的部分,低位字节存储余数部分,这样可以正确存储300。