自监督学习
文章目录
- 前言
- 定义
- 区别
- 优点
- 基于前置任务的自监督学习
- 位置预测(上下文预测)
- Relative positioning
- Solving the jigsaw拼图
- 旋转预测
- 上色(Colorization)
- 聚类预测
- 基于对比学习的自监督学习
- SimCLR
- MoCo:Momentum Contrast基于动量的对比学习
- 基于掩码重建的自监督学习(MIM)
- BEiT
前言
由于人工的标签稀缺,而且会耗费很大的人力。目前,互联网上存在很多没有标签的数据,我们现在就是想利用这些没有标注的数据。
自监督学习是无监督学习的一种,它不需要任何标签,而是通过从输入的数据当中提取某些信息,并预测新的信息自动生成这个标签。
定义
自监督学习是一种学习的策略,能够使用数据内部结构,而不是外在标签,来从数据当中的一部分去预测另外一部分
区别
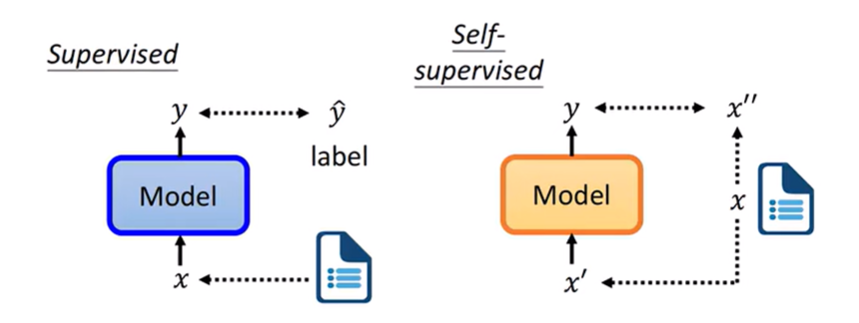
左边的是有监督学习,可以看出,不仅需要原始数据的x,而且还需要对应标签的y_hat,然后构建一个模型,学习从x到y的一个映射。
通过y和y的label之间的一个距离来构建loss。
右边是自监督学习,从原始数据中就可以抽取出x’和x’‘,而x’‘可以看成是一种数据当中的一个label,模型是通过x’来预测出y,最后只需要约束y和x’'之间的距离来构建一个loss。
优点
自监督学习有非常强的统一性,对于不同的任务,比如分类检测、分割等任务,都需要标注不同的标签,哪儿怕是同一个数据集,想要实现不同的任务都需要几乎重新标注标签。
- 比如上图中左边图的有监督学习,要想实现动作识别y_hat就是一个动作类别;要想实现分割任务y_hat就是基于前景的一个msk。简而言之,针对不同的任务,y_hat也是不同的。
- 而自监督学习,不管做什么任务,最后都要把他统一起来,因为不需要任何的标注信息,那么就可以把所有的数据集,不管是针对哪儿个任务的、不管有没有标签、全部都可以把他们放一起训练。
基于前置任务的自监督学习
设计一个任务,但是不同于分割、检测这类任务。设计任务的时候,要求标签label可以从原始数据本身中创造或者生成出来,这样的一个好处就是不需要人为标注标签信息。
这类方法有很多不同的前置任务,具体如下。
位置预测(上下文预测)
NLP中
NLP中的上下文预测指的是每个单词前后的单词和内容。
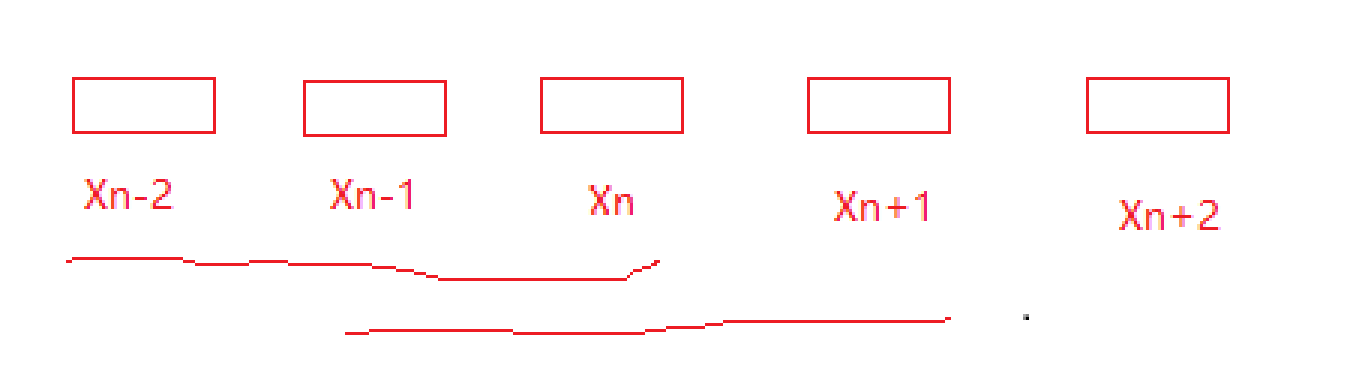
如上图所示,可以通过Xn-2、Xn-1、Xn输入给网络,让网络来预测Xn+1这个单词,也可以通过Xn-1、Xn、Xn+1输入给网络,让网络来预测Xn+2的单词。
Relative positioning
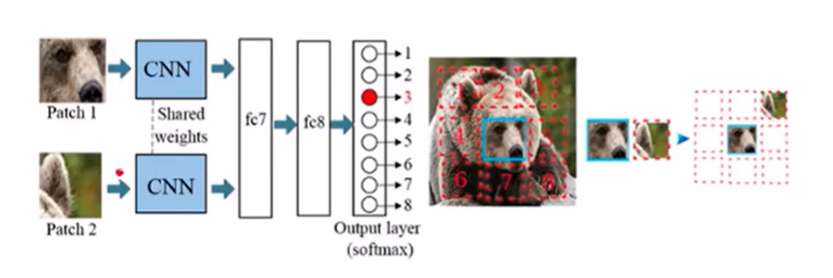
通常会把一个完整的图像拆分成去多个小的patch,那每个patch和它上下左右周围之间的patch之间的位置关系就是代表的就是类似NLP当中的上下文中的含义。
这样就可以让网络去预测每个patch之间的相对位置的关系,去实现自监督的学习。
如上图所示,选择完整图像的中间的patch块作为核心patch块,然后把这个patch周围的块作为第二个patch块,上图中我们把红色数字标记为3的图像块作为patch2,中间的蓝色图像块作为patch1。 此时,上图显示的是patch1和patch2各连接着一个CNN,说明输入的是2个CNN网络,但是这两个网络之间还有Shared Weights表示的是权重共享,说明CNN是相同的,故这两个patch输入到相同的CNN网络中,然后再经过两个全连接层,做一个分类让网络去预测patch2,相较于patch1这个patch2属于patch1的上下左右哪儿一个,如果是3号的图像块,说明预测正确;反之,预测错误。
Solving the jigsaw拼图

根据上图,将图像切分成3X3的patch,随后随便打乱patch的位置,把打乱后的图像传入到CFN 网络,让其预测打乱的排列方式是采用哪儿种方式。
旋转预测
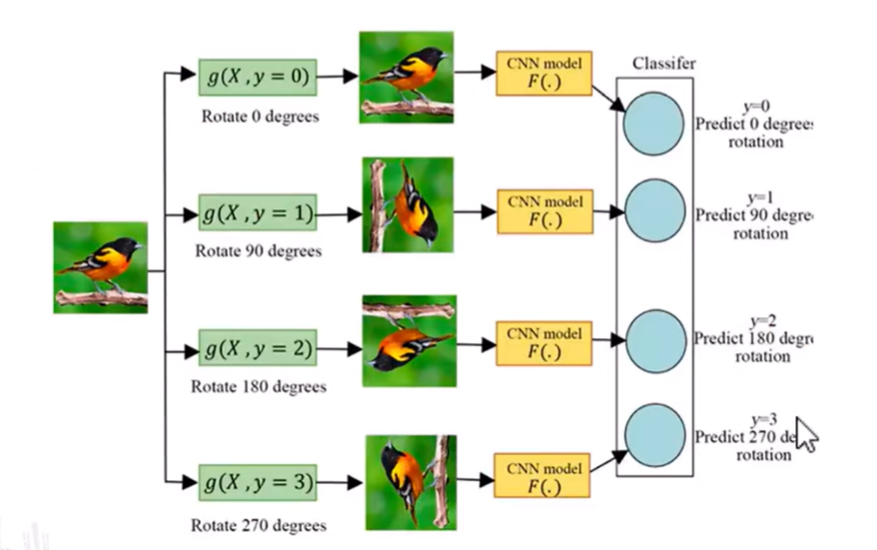
可以将输入的图像随机旋转一个角度,把旋转后的图像输入到一个CNN网络进行分类,让网络去预测这个旋转的度数。
可以识别嘴巴、眼睛等任务。
上色(Colorization)
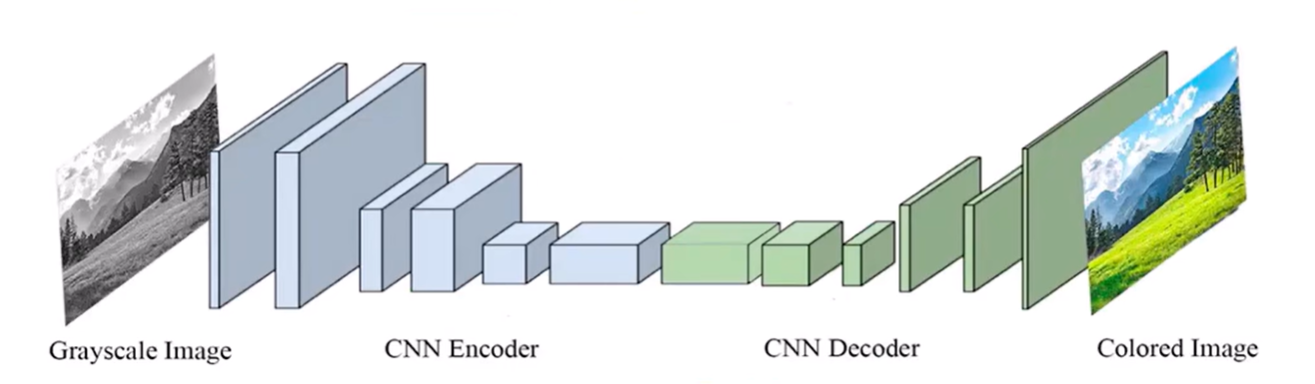
如上图所示,输入的图像是一张灰度图,先对图像进行编码,然后在进行解码,最后会得到一张带有颜色的图像。
上色要求网络对每一个像素都要打上颜色,因此更关注细粒度的特征。对于分割的任务会更有效。
聚类预测
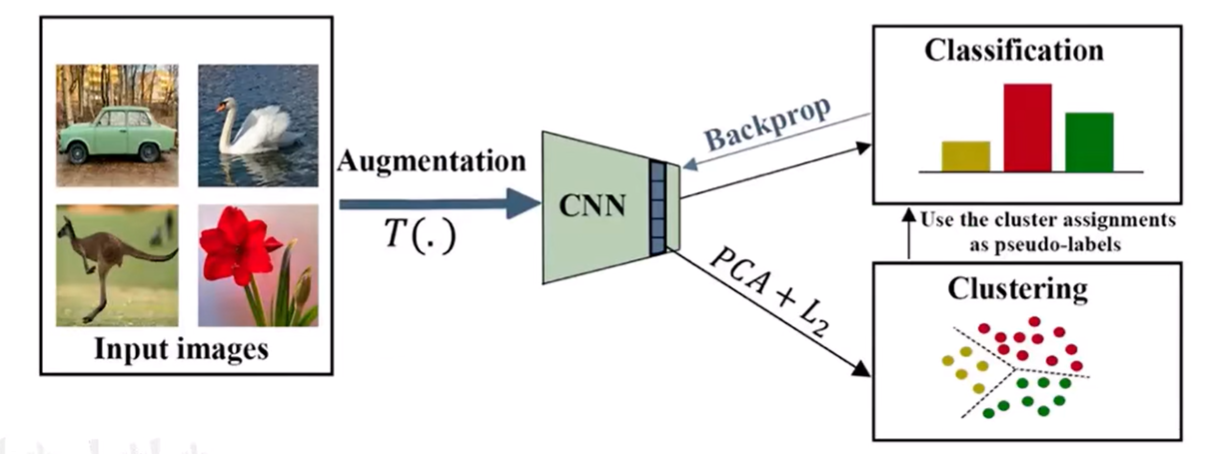
如上图所示,大量的不同的图像通过CNN网络可以获得到不同图像的特征,然后再对这些特征进行一个聚类,上图把特征聚类成了三类,把聚类得到的类别作为它的假标签。
举个例子,比如上图的第一张图像(车),经过增强,再经过CNN,然后这个图像被聚到黄色的这个类别的话,就认为这个车的图像的label是1(假标签),然后用假标签作为他分类网络的一个label,对他进行一个反向传播训练CNN ,让这个CNN 最后输出的结果就是1。
通过不断的重复上述过程,每一次聚类CNN都会变得更加好,每次都用更新后的CNN得到的特征再去聚类得到一个假标签。
主要就是通过聚类得到一个假标签,而非认为标注的标签。
基于对比学习的自监督学习
原理:创建一对pair的样本,让正样本之间的距离尽可能地近,让负样本之间的距离尽可能的远。
正样本:把一张图像做各种数据增强以后,既然是通过数据增强之后产生的,那么他们之间肯定属于正样本。
负样本:把一张图像和数据集当中另一张毫无关联的图像拼一起,那他们就是负样本。
这种把正样本拉近,把负样本拉远的能力是通过对比学习的loss实现。
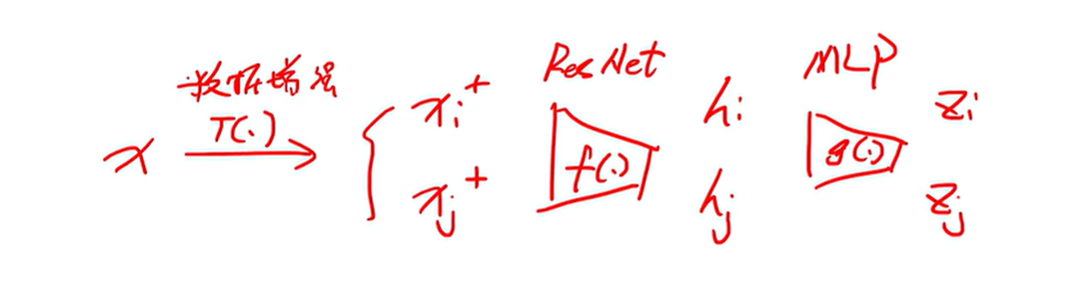
简单的思路就是,输入图像x,经过数据增强后得到两张图像,一个是Xi,Xj,既然是经过数据增强后得到的图像,所以这两个都是正样本。然后经过ResNet网络提取得到hi和hj两个特征,然后再经过MLP网络提取又得到Zi和Zj两个特征,经过MLP之后得到的特征构建loss明显比通过ResNet网络之后构建特征要好。
具体的公式实现如下所示
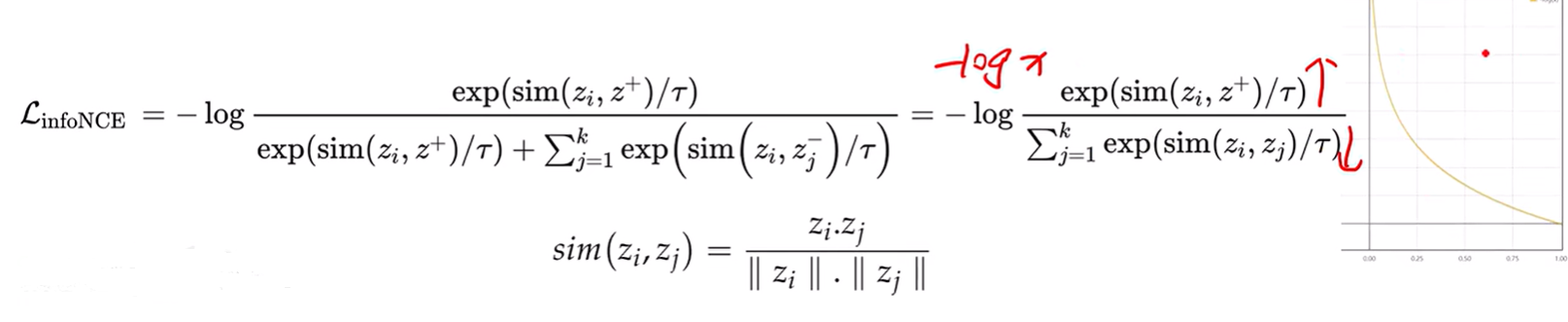
上式种,分母为所有样本的和,分子为正样本的相似度。
分子要尽可能的近(正样本的相似度要尽可能的高),分母的相似度要尽可能的低,整个分式越大越好。
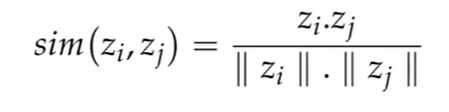
相似度采用的是cos的相似度。

上图是对原始图像进行的数据增强后的图像。
SimCLR
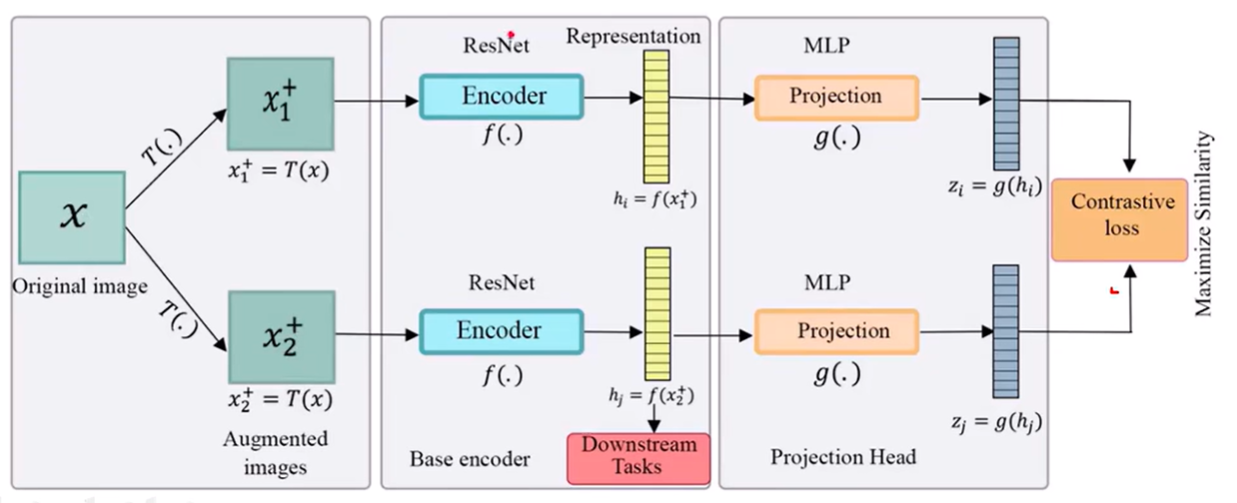
上图的流程简单的介绍一下。
- 首先,通过输入一张原始图像X,然后对X做两种随机的数据增强,得到2张X1+和X2+。
- 得到的这两张图像分别经过ResNet网络提取图像特征,得到hi和hj
- 然后,再通过MLP网络进行一个映射,得到Zi和Zj,来计算对比的LOSS
- 注意:做下游任务的时候,只是用的是hi和hj,上图中的Zi和Zj只是为了更好的去训练对比学习
MoCo:Momentum Contrast基于动量的对比学习
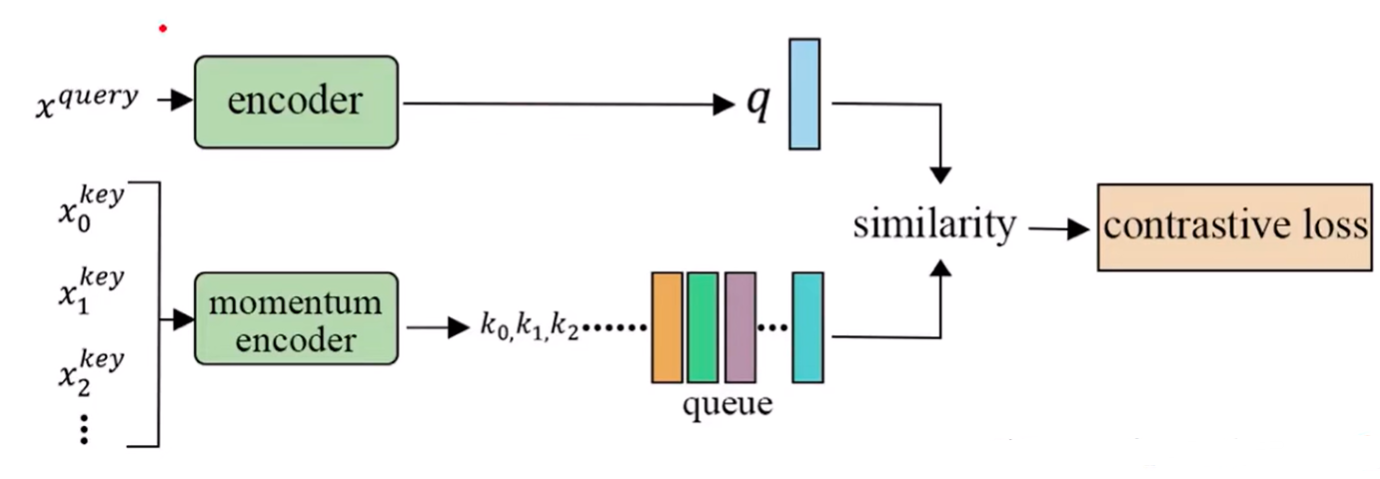
- 把负样本装到一个队列queue或者memory back中,通过检索的方式计算特征,
代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models import resnet50
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor#数据加载
transform = ToTensor()
dataset = CIFAR10(root="./cifar10",train=True,transform=transform,download=True)
loader = DataLoader(dataset,batch_size=64,shuffle=True)
'''
网络构建
'''
def get_resnet50(output_dim):model = resnet50(pretrained=False)model.fc = nn.Linear(model.fc.features,output_dim)return model
'''
设备选择
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")C = 1024
N = loader.batch_size
K = 4096
# 模型初始化
f_q = get_resnet50(C).to(device)
f_k = get_resnet50(K).to(device)
f_k.load_state_dict(f_q.state_dict()) # 一开始的时候f_k和f_q是一样的,故要把f_q的状态和f_k设置为一样#队列初始化成C x K的这样的维度,然后放到GPU上
queue = torch.randn(C,K).to(device)
queue_ptr = 0 # 需要设置一个指针,来代表目前这个队列进行到了哪儿一步#为momentum encoder设置一个权重
m = 0.99'''
优化器啊设置
'''
#设置一个优化器,learning rate取0.001,此优化器只对f_q进行梯度反向传播
optimizer = optim.Adam(f_q.parameters(),lr=0.001)#实际过程中,encoder会进行梯度方向传播,而动量encoder则会通过一个m权重进行一个加权分析'''
简单的数据增强函数
'''
def agu(x):return x + 0.1 *torch.randn_like(x)def info_nce_loss(q,k,queue,temperature=0.07):q = nn.functional.normalize(q,dim=1,p=2) #(64,1024) 其中,64是batch_sizek = nn.functional.normalize(k,dim=1,p=2) #(64,1024)queue=nn.functional.normalize(queue,dim=0,p=2) #(1024,4096) 这里的1024指的是每一个样本的特征维度,4096是队列的长度(可以装得下4096个负样本)positive_similarity = torch.bmm(q.view(N,1,C),k,view(N,C,1)) # (64, 4096)negative_similarity = torch.mm(q,queue) # (64, 4096)logits= torch.cat([positive_similarity.squeeze(-1), negative_similarity], dim=1) # (64, 4097)labels = torch.zeros(N, dtype=torch.long).to(device) # (64,)loss = nn.CrossEntropyLoss()(logits / temperature, labels) # 计算交叉熵损失return lossfor x,_ in loader:x = x.to(device)x_q = agu(x) #数据增强后的qx_k = agu(x) #数据增强后的kq = f_q(x_q) #把数据增强后的q放入到传统的encoderk = f_k(x_k) #把数据增强后的k放入到动量encoder'''得到q和k之后,需要进行计算loss'''loss = info_nce_loss(q,k,queue)optimizer.zero_grad()loss.backward() # 反向传播梯度optimizer.step() # 更新参数with torch.no_grad():# 更新动量encoderfor param_q, param_k in zip(f_q.parameters(), f_k.parameters()):param_k.data = m * param_k.data + (1 - m) * param_q.data# 更新队列batch_size = x.size(0)queue[:, queue_ptr:queue_ptr + batch_size] = k.t()queue_ptr = (queue_ptr + batch_size) % K # 更新队列指针基于掩码重建的自监督学习(MIM)
来源:这个方法的思想来源于NLP中的bert,在bert中的一个自监督任务是完形填空,就是随机的把输入序列当中的某些单词给MASK遮盖掉,让网络去预测输出被MASK遮盖掉的内容。从这个任务中,网络就可以学习到上下文的这种语义特征。
把NLP中的思想迁移到CV领域,如下所示。
BEiT
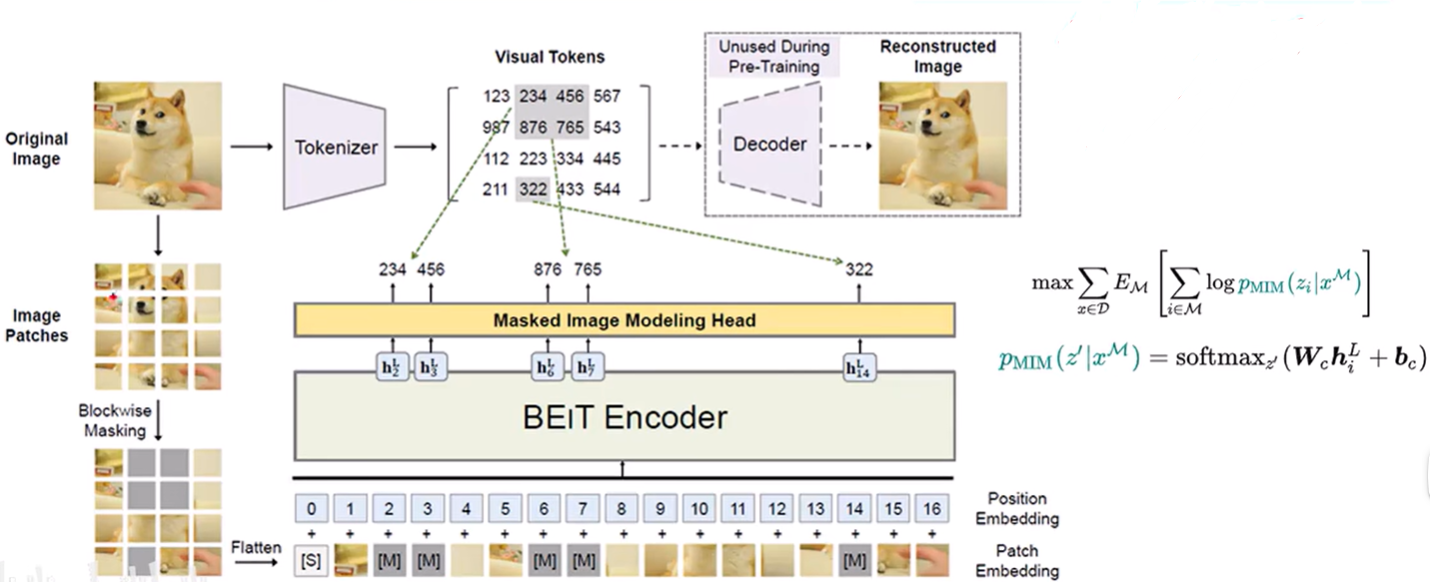
如上图所示,把输入的原始图像切分成很多个patch块,然后随机的去MASK掉部分patch块(也就是把这些部分替换成一个可以学习的编码),再通过Flatten把这些patch块进行展平,展平后的每个图像块就是Patch Embedding,再在前面加入一个特殊的token,每个图像块都对应着一个位置编码也就是Position Embedding。
再经过一个基于ViT的多层Encoder之后,就去预测每一个MASK的位置原先是什么。
把输入的图像进行一个Tokenizer化,也就是说对于每一个patch都把他映射成一个视觉的Token(一堆代码),去预测的时候就去预测这些代码,对于被遮盖掉的地方,都把他看成是一个分类的一个任务。
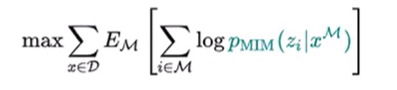
上面的公式中,XM是盖住的patch,Zi是最后预测得到的视觉token,p是一个条件概率,意思就是在**盖住XM的情况下,这个patch属于Zi这个类别的概率。整体的值越大,说明预测的就越对,故最外面是max。其中,i∈M指的是所有被mask掉的地方。x∈D指的是一个bacth中的所有的训练数据。