基础组件(六):网络缓冲区设计 和 定时器方案
文章目录
- 一、用户态网络缓冲区
- 1. Linux系统如何收发数据包?
- 接收网络数据包的流程
- 发送网络数据包的流程(tcp)
- 2. 网络缓冲区相关问题
- Q1.为什么为每条连接需要读写缓冲区?
- Q2.udp和tcp协议是否影响用户态缓冲区设计?
- Q3.不同网络模型是否影响用户态缓冲区设计?
- Q4.ip层分片了,为什么tcp还要分段?
- 3. 网络缓冲区实现
- 定长buffer(结构简单但频繁数据腾挪)
- ring buffer (解决数据频繁移动)
- chain buffer (块状链表)
- 二、定时器模块
- 1. 定时器构成
- 容器(存放定时任务的数据结构)
- 检测触发机制(看PDF)
- 2. 定时器优化思路
- (1)红黑树(平衡二叉搜索树)
- (2)最小堆(完全二叉树)
- (3)时间轮(多轮指针)
- Q: 有关时间轮的一些问题
一、用户态网络缓冲区
1. Linux系统如何收发数据包?
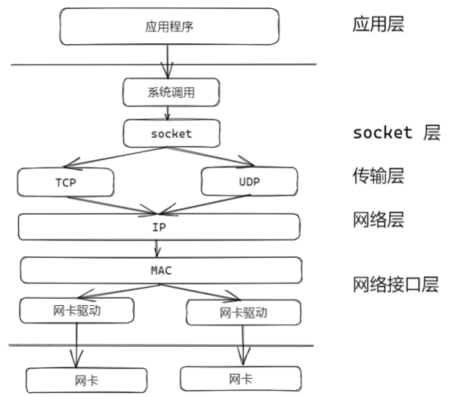
协议栈的构成
对着思维导图/流程图 反复叙述(收/发网络包流程)
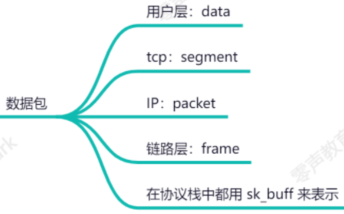
各层数据包表示
接收网络数据包的流程

- 网卡收到数据包,通过DMA将数据写入内存(ringbuffer结构)
- 网卡向CPU发起硬件中断,CPU收到中断请求,根据中断表查找中断处理函数,调用中断处理函数
- 中断处理函数将屏蔽中断,发起软件中断
避免CPU频繁被网卡中断
使用软中断处理耗时操作,避免执行时间过长,导致CPU没法响应其他硬件中断 - 内核ksoftirqd线程负责软中断处理,该线程从ringbuffer中逐个取出数据帧到sk_buff
- 从帧头取出IP协议,判断是IPv4还是IPv6,去掉帧头,帧尾
- 从IP头看上一层协议是tcp还是udp,根据五元组找到socket,并将数据提取出来放到socket的接受缓冲区
软中断处理结束后开启硬件中断 - 应用程序通过系统调用将socket的接收缓冲区的数据拷贝到应用层缓冲区
发送网络数据包的流程(tcp)

- 应用程序通过系统调用将用户数据拷贝sk_buffer并放到socket的发送缓冲区(udp不使用发送缓冲区)
- 网络协议栈从socket的发送缓冲区取出sk_buff,并克隆出一个新的sk_buffer(tcp支持丢失重传)
- 向下传递依次增加TCP/UDP头部,IP头部,帧头(MAC头部),帧尾(tcp分段,ip分片)
TCP 分段是为了根据应用的需要,控制数据流的传输。
IP 分片是为了保证数据包大小符合网络层的传输限制。 - 触发软中断通知网卡驱动程序,有新的网络包需要发送
- 网卡驱动程序从发送队列依次取出sk_buff写ringbuffer(内存DMA区域)
- 触发网卡发送,发送成功,触发硬件中断,释放sk_buff和ringbuffer内存
tcp对应的是克隆而来的
udp对应的是原始的 - 当收到tcp报文的ack应答时,将释放原始的sk_buff
2. 网络缓冲区相关问题
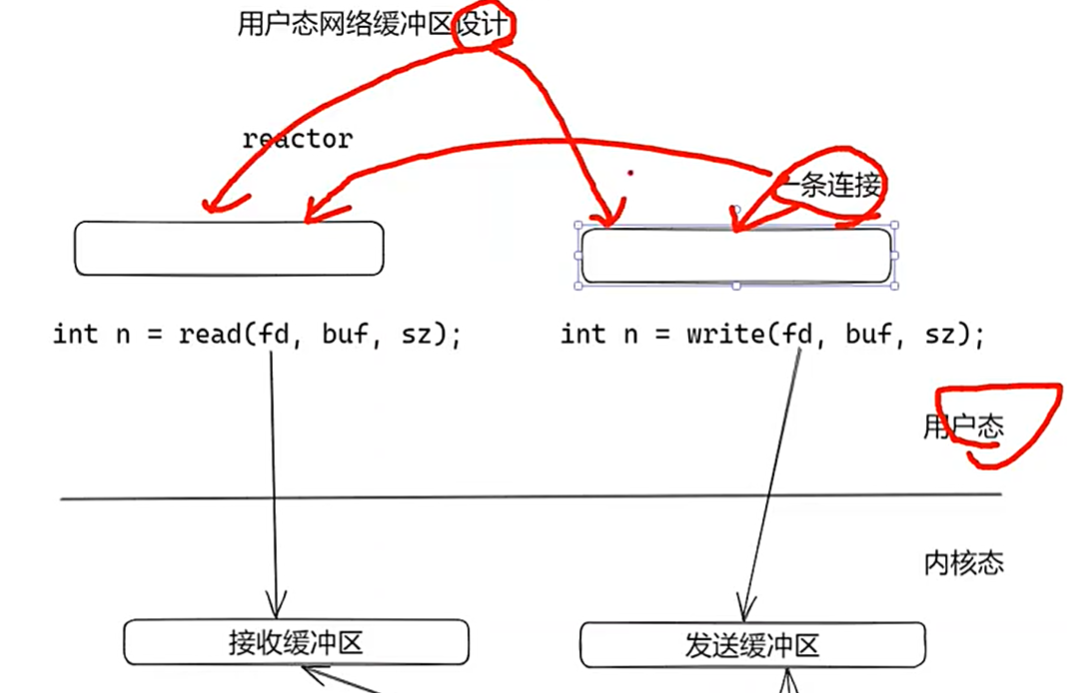
Q1.为什么为每条连接需要读写缓冲区?
- 读缓冲区
从读缓冲区取出的数据不一定包含一个完整的数据包。
生产者的速度 > 消费者的速度。 - 写缓冲区
数据包不能一次性全部传输。
生产者的速度大于消费者的速度。
不同网络模型是否影响用户态缓冲区设计?
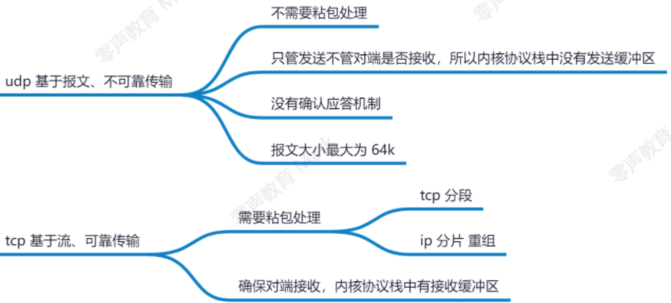
Q2.udp和tcp协议是否影响用户态缓冲区设计?
不会影响, 两者粘包处理方式不同
Q3.不同网络模型是否影响用户态缓冲区设计?
不会影响, 但两者对内核缓冲区数据读取出来方式不同
- 接收缓冲区:
阻塞 IO:线程阻塞,等待数据到达。
Reactor:通过 IO 多路复用检测缓冲区就绪,使用事件驱动模型通知用户态调用 read。
Proactor:异步投递请求,内核拷贝数据后,通过完成通知回调用户态。 - 发送缓冲区:
阻塞 IO:write() 调用阻塞直到数据写入内核的发送缓冲区。
Reactor:通过 epoll 监听可写事件,避免缓冲区满时阻塞。
Proactor:异步 WriteFile() 提交请求,内核完成数据拷贝后通过完成通知回调。
Q4.ip层分片了,为什么tcp还要分段?
if tcp层不分段 + ip层分片的话,当数据传输到ip层,一个小包丢失整个包都要重传。
tcp层分段,ip层分片 的话只需 重传丢失的这小段数据包即可.
udp就不需要分段, 因为udp不提供可靠传输,无重传机制,所以一个小包丢失就是整个包丢弃。
3. 网络缓冲区实现
网络缓冲区设计 : 生产消费者模型, 用队列结构
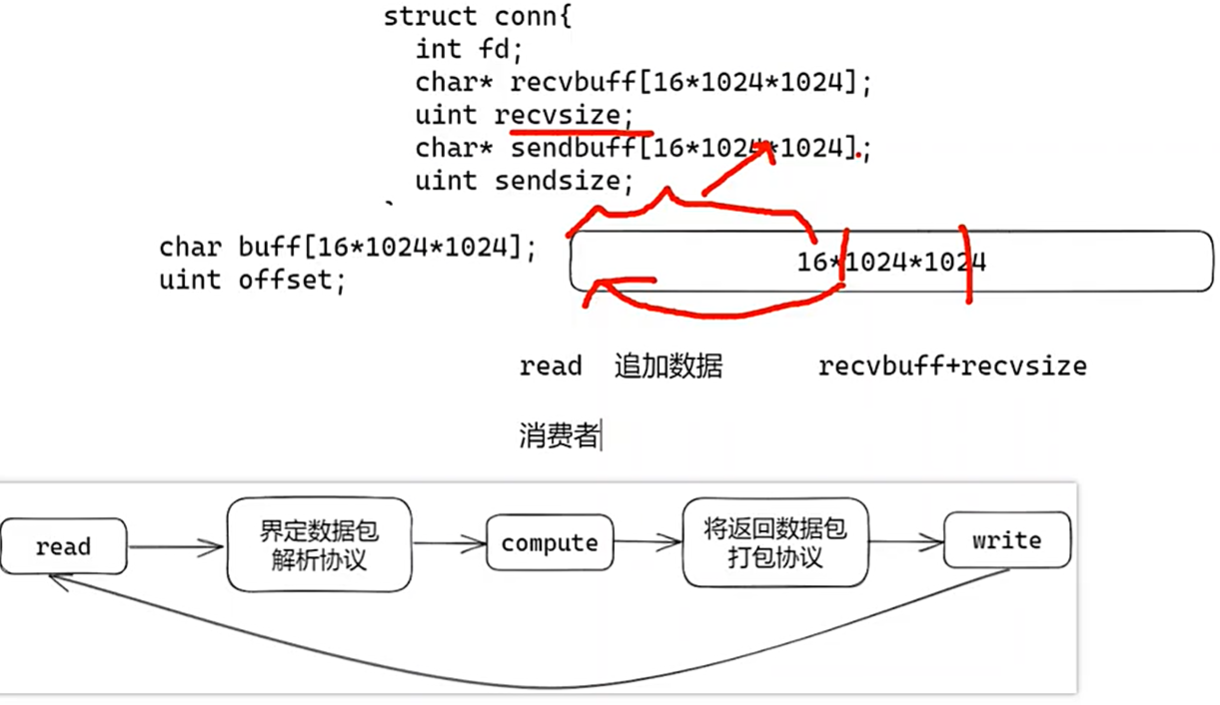
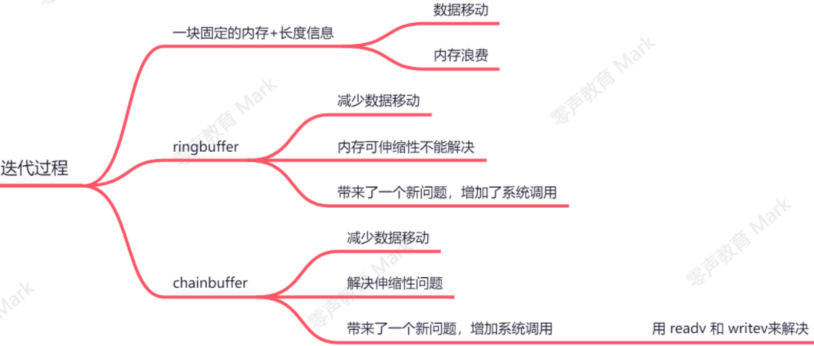
定长buffer(结构简单但频繁数据腾挪)
实现简单,因为每次取出数据后需要将数据腾挪到头部,都需要对齐,
但空间浪费,空间不足还会引起数据频繁移动。

ring buffer (解决数据频繁移动)
针对解决:无锁队列ring buffer 、环形缓冲区避免数据频繁移动 √,
但未解决空间伸缩容问题❌
因为没有腾挪数据可能造成离散数据,会增加系统调用❌
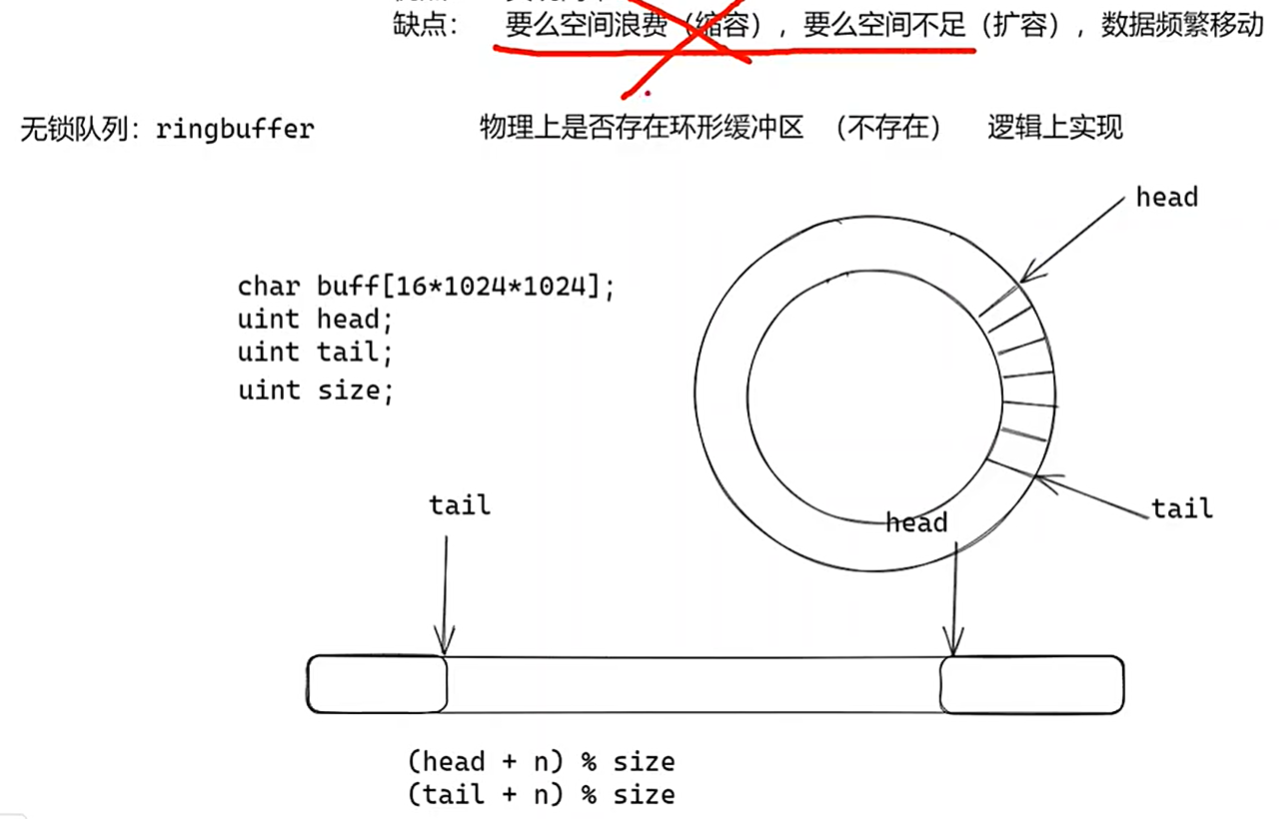
头尾指针解决数据导入时的对齐问题
取余操作 > 位运算操作 : m % 2^n == m & (2^n -1)
ring buffer设计> 缓冲区读取不涉及多线程, 采取编译器屏障
do{asm volatile(‘’ ‘’ :::‘’ memory)}while (0);
CPU屏障 mb( ) rmb( ) wmb( )
chain buffer (块状链表)
- 特点:
不需要腾挪数据,避免数据频繁移动√,
动态扩缩容且无需数据拷贝,也解决空间伸缩容问题√
造成不连续空间,可能引发多次系统调用❌
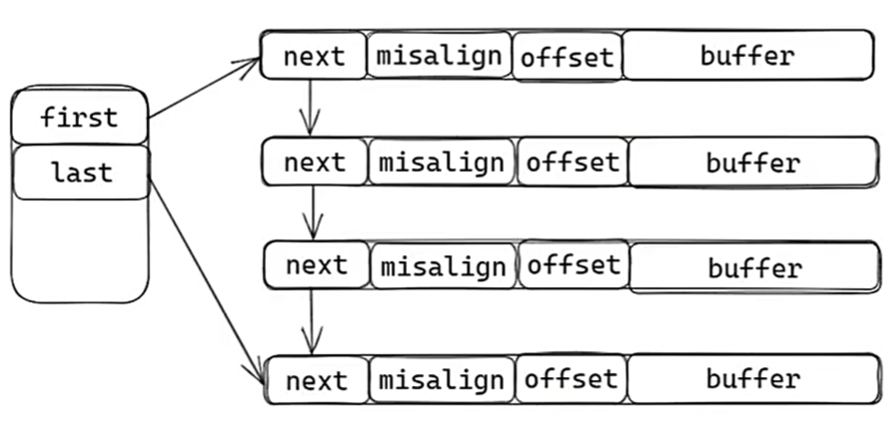
代码实现
misalign:从开头以及取走的长度,下次从开头加上misalign就是数据开始点
offset:有效数据长度
二、定时器模块
1. 定时器构成
定时器模块 = 容器组织大量定时任务 + 检测触发机制
作用:组织管理大量延时任务的模块,不过度占用线程,高效处理定时任务。没有定时器系统只能被动等待或手动轮询,会极大浪费 CPU性能 或使任务无法按时触发。
容器(存放定时任务的数据结构)
定时器管理结构(调度容器):存放所有定时任务的核心数据结构,用于高效地插入、删除、查询最近即将触发的任务。
- 按触发时间排序的结构 : 红黑树STL(map, set, multimap, multiset) 、最小堆(priority_queue)
- 按执行序排列的结构: 时间轮(针对当前时间指针做偏移)
检测触发机制(看PDF)
定时任务触发机制(驱动器):是实际触发到期任务的机制,有点类似“闹钟”。
在定时器的管理结构中,虽然我们知道每个任务的目标触发时间,但还必须解决:“如何及时、高效地检测并触发已经到期的任务?”
现在的检测触发方式主要有以下两种设计理念:
- 采用io多路复用的epoll_awit最后一个参数timeout触发(eg. redis、nginx)
int ret = epoll_wait(epfd, events, max_events,3000); //最多等3秒
这里为等待三秒。使用这些 timeout 参数,可以无需额外定时器结构,也能被动检测“时间是否过去”,这样做可避免轮询带来的cpu消耗;但这种方式也具有一定的缺点:不够精确(毫秒级);如果需要动态更新超时时间(如堆顶任务改变),需不断传入新 timeout;适合小型服务或简化实现。
- 采用timerfd将定时事件转化为io处理, 让io多路复用进行检测 (eg. workflow)
timerfd是 Linux 提供的一种定时器机制,它的本质是一个文件描述符(fd),可以表示一个定时器;到期后变为 可读 状态(就像 socket 一样);可与 epoll / select 等 I/O 多路复用接口集成;支持一次性或周期性触发;精度高,可达 纳秒级;
主要接口:
1.timerfd_create() 创建定时器,生成一个 fd
2.timerfd_settime() 设置超时时间
3.epoll_ctl() 监听 timerfd 的 超时事件,统一交给 epoll_wait 处理
简单实现
#include <sys/epoll.h>
#include <sys/timerfd.h>
#include <time.h> // 用于 timespec 和 itimerspec
#include <unistd.h> // close()
#include <functional>
#include <chrono>
#include <set>
#include <memory>
#include <iostream>using namespace std;// 定时器基础结构体,存储任务的唯一 ID 和触发时间,用于排序和查找
struct TimerNodeBase {time_t expire; // 过期时间(毫秒级)uint64_t id; // 唯一 ID
};// 继承自 TimerNodeBase,添加回调函数,构成完整的定时任务
struct TimerNode : public TimerNodeBase {using Callback = std::function<void(const TimerNode &node)>;Callback func; // 任务回调函数// 构造函数,设置任务的 id、到期时间与执行函数TimerNode(int64_t id, time_t expire, Callback func) : func(func) {this->expire = expire;this->id = id;}
};// 定义小于运算符,用于 std::set 排序,先按到期时间排,再按 id 排
bool operator < (const TimerNodeBase &lhd, const TimerNodeBase &rhd) {if (lhd.expire < rhd.expire) {return true;} else if (lhd.expire > rhd.expire) {return false;} else return lhd.id < rhd.id;
}// 定时器管理器类,负责定时任务的添加、删除、触发检测与执行
class Timer {
public:// 获取当前时间(单位:毫秒)static inline time_t GetTick() {return chrono::duration_cast<chrono::milliseconds>(chrono::steady_clock::now().time_since_epoch()).count();}// 添加定时任务,生成唯一 ID,根据到期时间插入到排序容器中TimerNodeBase AddTimer(int msec, TimerNode::Callback func) {time_t expire = GetTick() + msec;// 插入时若早于现有最大时间,用普通 emplace;否则使用 emplace_hint 优化if (timeouts.empty() || expire <= timeouts.crbegin()->expire) {auto pairs = timeouts.emplace(GenID(), expire, std::move(func));return static_cast<TimerNodeBase>(*pairs.first);}auto ele = timeouts.emplace_hint(timeouts.crbegin().base(), GenID(), expire, std::move(func));return static_cast<TimerNodeBase>(*ele);}// 删除定时任务(若存在),通过 node 信息匹配void DelTimer(TimerNodeBase &node) {auto iter = timeouts.find(node);if (iter != timeouts.end())timeouts.erase(iter);}// 处理所有已到期任务:按时间顺序遍历,执行并移除void HandleTimer(time_t now) {auto iter = timeouts.begin();while (iter != timeouts.end() && iter->expire <= now) {iter->func(*iter); // 执行任务回调iter = timeouts.erase(iter); // 移除已执行任务}}// 根据最早过期任务更新 timerfd,确保 epoll 能及时返回virtual void UpdateTimerfd(const int fd) {struct timespec abstime;auto iter = timeouts.begin();if (iter != timeouts.end()) {abstime.tv_sec = iter->expire / 1000;abstime.tv_nsec = (iter->expire % 1000) * 1000000;} else {abstime.tv_sec = 0;abstime.tv_nsec = 0;}struct itimerspec its = {.it_interval = {},.it_value = abstime};timerfd_settime(fd, TFD_TIMER_ABSTIME, &its, nullptr);}private:// 全局递增 ID 生成器,用于唯一标识每个定时任务static inline uint64_t GenID() {return gid++;}static uint64_t gid;// 使用 std::set 按过期时间排序任务,便于快速获取最早任务set<TimerNode, std::less<>> timeouts;
};
uint64_t Timer::gid = 0;// 主函数,注册 timerfd 到 epoll,添加定时任务,并进入事件循环
int main() {// 创建 epoll 实例,用于监听 timerfd 事件int epfd = epoll_create(1);// 创建 timerfd(Linux 提供的高精度定时器),用于精确唤醒int timerfd = timerfd_create(CLOCK_MONOTONIC, 0);struct epoll_event ev = {.events=EPOLLIN | EPOLLET};// 将 timerfd 注册到 epoll,使用边缘触发epoll_ctl(epfd, EPOLL_CTL_ADD, timerfd, &ev);unique_ptr<Timer> timer = make_unique<Timer>();int i = 0;// 添加定时任务,测试 1s、2.1s、3s 三个任务触发效果timer->AddTimer(1000, [&](const TimerNode &node) {cout << Timer::GetTick() << " node id:" << node.id << " revoked times:" << ++i << endl;});timer->AddTimer(3000, [&](const TimerNode &node) {cout << Timer::GetTick() << " node id:" << node.id << " revoked times:" << ++i << endl;});auto node = timer->AddTimer(2100, [&](const TimerNode &node) {cout << Timer::GetTick() << " node id:" << node.id << " revoked times:" << ++i << endl;});// 删除其中一个定时任务,用于测试删除功能是否生效timer->DelTimer(node);struct epoll_event evs[64] = {0};while (true) {// 每次 epoll_wait 前,更新 timerfd,设置最近任务触发时间timer->UpdateTimerfd(timerfd);int n = epoll_wait(epfd, evs, 64, -1);time_t now = Timer::GetTick();// epoll 触发后处理已过期任务,执行对应回调函数timer->HandleTimer(now);}close(timerfd);close(epfd);return 0;
}
2. 定时器优化思路
(1)红黑树(平衡二叉搜索树)
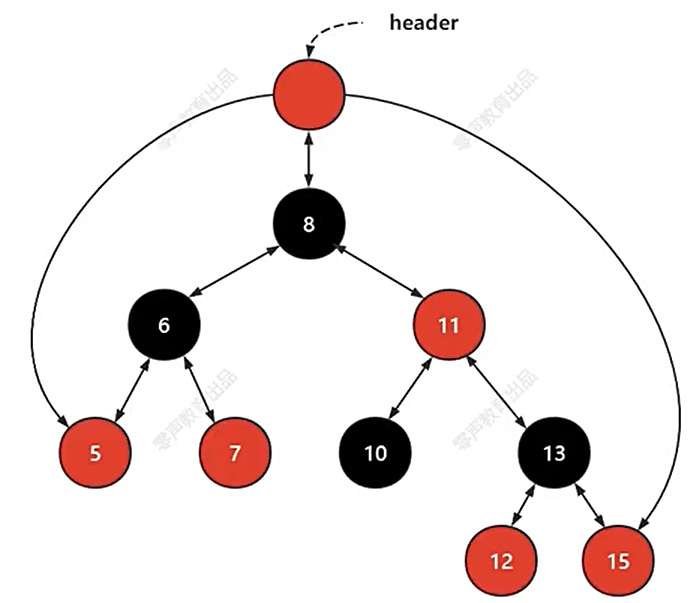
第一个head红节点本身不存数据, 有三个指针: 左连begin() 红黑树最小元素、中连root、右连最右侧元素.end() 失效迭代器不存数据
右连end()不是 红黑树最大元素=crbegin()=end()-1才是倒叙数第一个元素
平衡 二叉 搜索树 : 维持增删改查操作 时间复杂度在O(log n),使每次比较都能排除一半的节点(二分查找)
平衡左右子树高度 ==> 从root出发左右子树 黑节点个数一样
红黑树特征:有序、平衡、黑节点高度一致。
红黑树操作:增删改查,左旋转右旋转,重新着色。
红黑树在定时器中的应用:组织定时任务,保持平衡。
clock-timer.h #时间表盘的实现timewheel.h #时间轮的实现 mh-timer #最小堆rbt-timer #红黑树timer_with_timerfd.cc # 面试推荐的方法timerNodeBase面试题: 现场写个 定时器, 建议使用 multimap
(2)最小堆(完全二叉树)
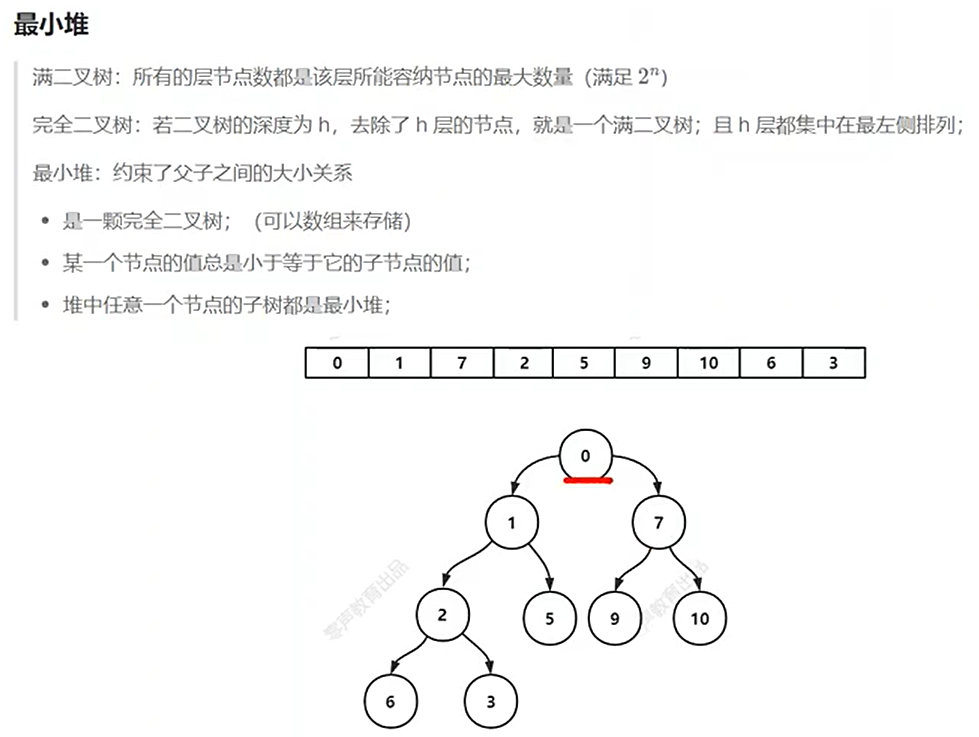

最小堆操作:添加节点和删除节点,时间复杂度为O(log n)
最小堆在定时器中的应用:快速找到最小值,驱动定时器运行
(3)时间轮(多轮指针)
时间轮通常用于多线程环境, 红黑树、最小堆用于单线程
时间轮 : 时间指针 + 最小精度+ 最大范围
时间指针 :按照最小精度进行移动, 添加定时任务就是对时间指针的偏移
最小精度1s : 能接受的误差
最大范围 : 能支持的最大间隔时间任务

为什么设计多个时间轮 : 时间指针 + 最小精度1s + 最大范围层级 : 解决空间浪费问题

时间轮就像一个时钟表盘,将时间划分为等长的“槽(slot)”,每个槽代表一个固定的时间区间。例如:一共 60 个槽,每个槽表示 100ms,那么一圈表示 6 秒;定时任务被放入某个槽位中,等待“时针”转动到这个槽时触发。
(1)基本结构
时间轮使用指针数组存储任务,每个格子(Slot)对应一个任务链表,存储在同一时间触发的任务。
struct TimerTask {int rotations; // 还有几圈后触发std::function<void()> callback;TimerTask* next;
};std::vector<TimerTask*> slots; // 每个槽是一个链表
int current_slot = 0; // 当前指针位置
(2)任务添加
将一个设定延迟时间的任务放入时间轮的合适位置,等待将来触发。
变量:current_slot: 当前时间轮指针位置;interval: 每个槽代表的时间间隔;slot_count: 时间轮的总槽数;timeout: 任务延迟时间;
ticks = timeout / interval //计算出需要延后的位置
slot_index = (current_slot + ticks) % slot_count //计算出放置任务的位置
rotations = ticks / slot_count // 表示再转多少圈后才能触发
(3)任务触发
在时间轮每“跳动”一格(即经过一个 interval 时间)时,判断当前槽位中哪些任务可以执行。每次 tick() 时,指针移动到下一个槽位 current_slot++;遍历当前槽位的链表中所有任务。对每个任务:若 rotations == 0:立即触发执行;否则:rotations–,等待下一轮。

(4)任务的重新映射
当时间轮转满一圈:
单层时间轮:超时任务需要重新映射到新槽位
多层时间轮:
高层时间轮(如分钟层)每次移动一格(触发低层重新映射)
任务触发时间减去当前时间,计算新槽位存放
Q: 有关时间轮的一些问题
(1)时间轮怎么保证线程安全?
- 时间轮通常涉及多个线程(定时线程、任务添加线程、任务执行线程),需要处理并发问题:
1.任务添加同步:
使用锁(mutex、spinlock)或 无锁数据结构(lock-free queue)确保线程安全
或者使用事件队列(event queue),让时间轮线程自行处理任务添加
2.任务检测并发:
读写锁(RWLock):防止多个线程同时访问任务链表
CAS(Compare-And-Swap):用于无锁操作
3.任务执行并发:
任务执行通常由线程池处理,避免阻塞时间轮
(2)时间轮线程为什么不直接执行任务?
- 时间轮的核心职责是检测任务是否超时,直接执行任务会有以下问题:
1.任务可能耗时较长,导致时间指针无法及时移动,影响任务触发的准确性
2.影响高精度定时,多个任务需要在不同时间执行,可能造成任务堆积
3.更好的线程管理:时间轮线程 只负责任务检测,将任务放入 任务队列 或 线程池 处理任务执行线程 由 线程池 管理,提高并发执行能力。
优秀笔记:
1.1 用户态网络缓冲区
1.2 用户态网络缓冲区设计
2.1 基于红黑树,时间轮,最小堆的定时器方案
2.2 定时器方案红黑树,时间轮,最小堆
参考学习:https://github.com/0voice