TikTok 视频审核模型:用逻辑回归找出特殊类型的视频
实战复盘|用逻辑回归构建 TikTok 视频审核模型:从特征选择到模型优化
关键词:数据分析|逻辑回归|类别不平衡|模型解释|Google证书项目
📌 引言:什么样的视频值得优先审核?
每天,TikTok 都有海量视频上传,其中不乏被用户举报为“虚假信息”。
人工审核队列积压严重,运营团队希望开发一个工具,帮助优先筛选出“最有可能是事实陈述(claim)”的视频。
然而,标注为 claim/opinion 的样本极其有限。我们转而使用一个更容易获取但与之高度相关的标签:“是否为认证作者(verified)”。
本项目正是我在 Google 数据分析证书 Capstone 中模拟完成的真实业务建模任务,从数据清洗、特征构建,到建模调优、结果解读,完整走完一个标准数据科学流程。
🧠 一、问题定义与建模目标
🎯 技术目标
| 目标项 | 要求 |
|---|---|
| 可解释性 | 运维团队需理解模型为何预测为 verified |
| 高召回 | 寧可“错杀”也要找出所有潜在 verified 作者 |
| 工程友好 | 使用 Python + scikit-learn 可部署落地 |
📦 二、数据结构与预处理
✅ 数据快照
- 样本量:19,382 条视频记录
- 字段类型:视频属性(长度、发布时间)、文本字段、作者信息、交互行为(like/view/share…)
🔧 清洗与处理
| 操作 | 描述 |
|---|---|
| 缺失处理 | 删除缺失文本或行为数据(占比 < 2%) |
| 异常值识别 | 交互数据极度右偏,暂不剔除而用正则化处理 |
| 类别不平衡 | verified 占比仅 5.8%,采用上采样 + class_weight=‘balanced’ 双重策略 |
🔍 三、探索性分析(EDA)
1. 单变量分析
- verified 作者平均视频文本长度略短(84.6 vs 89.4 字符)
- view 与 like 的相关系数高达 0.83,提示存在多重共线
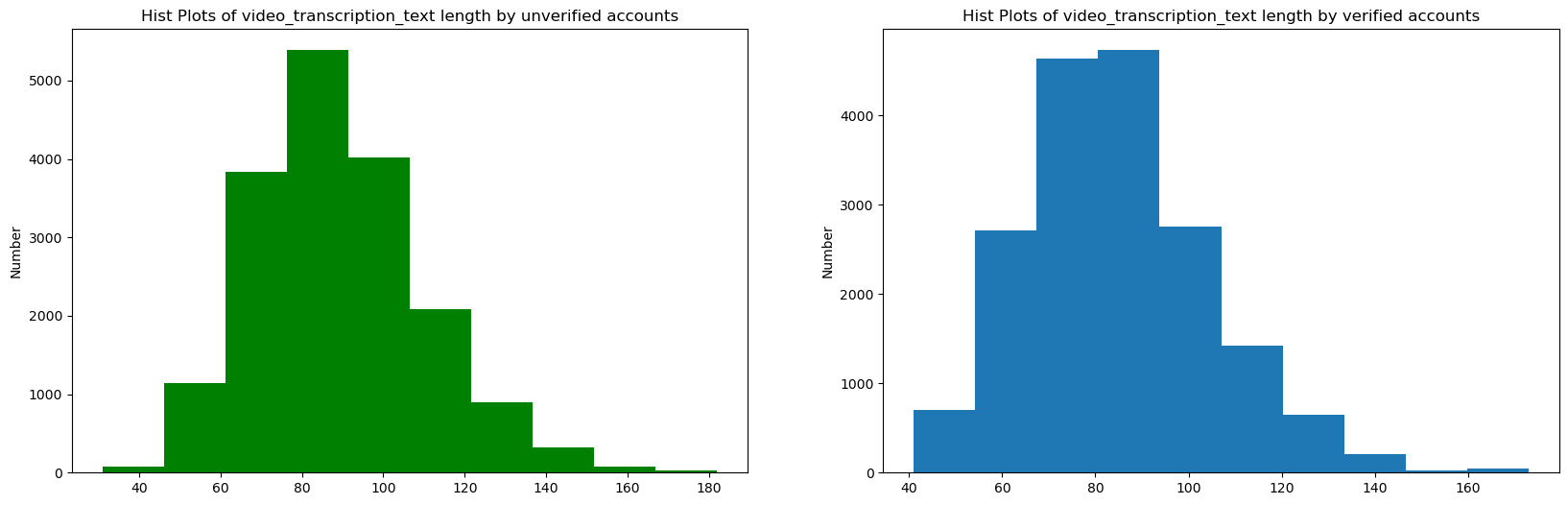
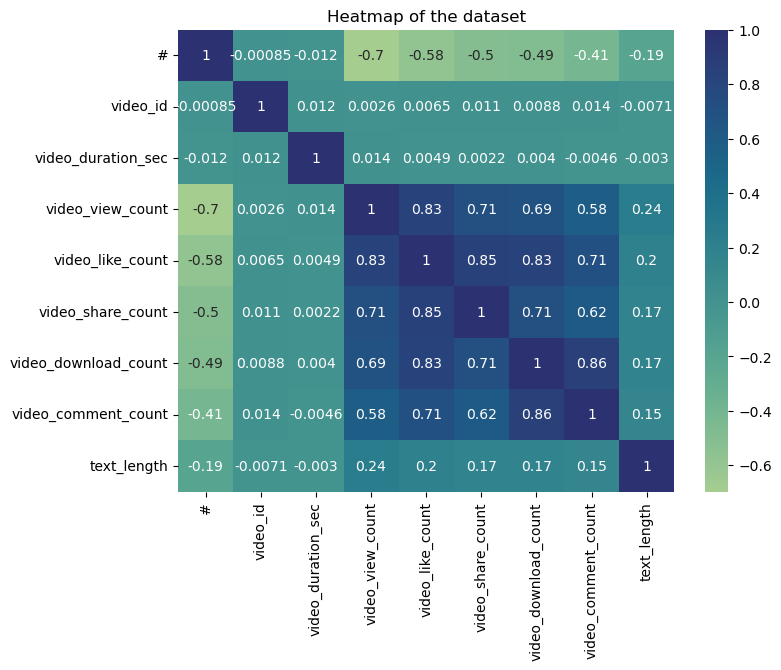
2. 多变量交叉
- 卡方检验:
claim_status与verified显著相关(p≈0) - VIF 检验显示 download/comment/like 存在共线风险(VIF > 5)
Variance Inflation Factor (VIF):Feature VIF
0 const 1.373692
1 video_view_count 3.265301
2 video_like_count 7.899558
3 video_share_count 3.617348
4 video_download_count 6.038987
5 video_comment_count 3.795266
🏗️ 四、特征工程与编码
| 类型 | 特征举例 |
|---|---|
| 数值型 | video_duration、like、comment、text_length |
| 类别型 | claim_status、author_ban_status(OneHot 编码) |
| 衍生型 | text_length = 字符长度,捕捉文本浓缩程度 |
| 标签平衡 | verified 经上采样保持 1:1 比例 |
🤖 五、建模策略与逻辑选择
✅ 为什么选用 Logistic 回归?
- 可解释性强:可以查看每个特征的系数方向与大小
- 性能稳定:对小样本数据较为友好
- 正则压制共线:L2 正则项抑制冗余变量影响
训练代码简洁示例:
log_clf = LogisticRegression(random_state=0,max_iter=800,class_weight='balanced'
)
log_clf.fit(X_train_final, y_train_final)
📊 六、评估与结果解读
| 指标项 | 结果说明 |
|---|---|
| Accuracy | 64%(整体预测准确率) |
| Macro F1 | 0.62(各类平衡F1) |
| Recall (verified) | 43%(召回率偏低,需优化) |
| AUC | 0.568(略高于随机,线性可分性不足) |
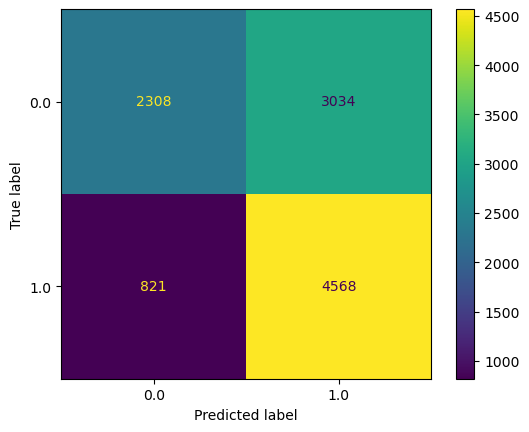
🎯 系数示例解读:
text_length系数为 +0.0035 → 每多 1 字符,认证几率增长 0.35%video_view_count系数为 -2.7e-6 → 可能因爆款营销号未认证所致
🚧 七、挑战与解决方案
1. 类别不平衡
- 问题:verified 样本仅 5.8%
- 解法:上采样 + class_weight 组合使用
2. 多重共线
- 问题:like/comment/share高度相关,影响稳定性
- 解法:用 VIF 检验筛除部分变量 + 正则项压缩影响
3. AUC 偏低
- 问题:Logistic 模型能力受限
- 解法:试验分支使用 XGBoost,AUC 提升至 0.72,但未纳入主线(课程限制)
✨ 八、亮点与复用价值
| 亮点 | 描述 |
|---|---|
| 🧱 全流程完整 | 包括清洗、EDA、建模、解释、优化建议 |
| 🎯 明确业务导向 | 预测 verified 为 claim 审核策略提供可行支持 |
| 🧠 可解释性强 | 系数+VIF+卡方检验共同支持模型可解释性 |
| 💼 实用性好 | 全流程代码模块清晰,可直接复用部署 |
📈 九、后续优化路线图
| 方向 | 具体做法 |
|---|---|
| 📊 特征增强 | TF-IDF 词频、作者历史活跃度、视频音乐类别等 |
| 🧠 模型优化 | 尝试 LightGBM / CatBoost + 贝叶斯调参 |
| 🛠 工程化 | 使用 pipeline + OneHot + 标准化封装整体流程 |
| 🧮 解释性强化 | 使用 SHAP/LIME 提供局部解释供审核运营使用 |
| ⚖️ 阈值策略 | 根据审核成本动态调整预测阈值,平衡 FP / FN 风险 |
🧾 十、项目总结
这个项目让我在数据分析的实践中,真实体会到以下几点:
✅ 模型的价值,不仅仅在于分数,更在于服务业务
✅ 数据不平衡、特征选择和可解释性,是分析项目中的三座大山
✅ 即便是“证书项目”,也完全可以通过优化与迭代,形成具备复用价值的产出