2025年1中科院1区顶刊SCI-投影迭代优化算法Projection Iterative Methods-附完整Matlab免费代码
Projection-Iterative-Methods-based优化器(PIMO)是一种受投影迭代方法启发的新型元启发式算法。PIMO引入了四种新的算子来引导种群走向最优收敛,同时提高了探索和收敛速度。这种方法首次提出,集成了Kaczmarz和随机梯度下降等技术,以提高性能并防止收敛到局部最优。PIMO的有效性通过三组实验得到验证。PIMO是一种受投影迭代法启发的新型元启发式算法。于2025年7月在线发表、9月正式发表在JCR 1区,中科院1区 SCI 期刊 Knowledge-Based Systems。
1 提出的方法
1.1灵感来源
投影方法广泛用于约束优化,主要用于确保每次更新后的解满足约束条件。通过这种操作,可以避免优化过程中解违反约束而导致不现实的结果。特别是在具有复杂约束的非线性优化问题中,投影方法展现出独特优势。受此启发,本文设计了基于投影迭代方法的优化器(PIMO)。设目标函数为f(x)f(x)f(x),其中x∈Rdx\in\mathbb{R}^{d}x∈Rd为解向量,约束集为CCC。优化问题可表述为:
minx∈Rdf(x)(1)\min_{x\in\mathbb{R}^{d}}f(x) \tag{1}x∈Rdminf(x)(1)
在每次迭代中,通过投影操作将当前解xt(i)x^{(i)}_{t}xt(i)映射回约束集CCC:
xt(reg(i)=projC(x(i))(2)x^{(reg(i)}_{t}=proj_{C}\left(x^{(i)}\right) \tag{2}xt(reg(i)=projC(x(i))(2)
设当前函数值为Ft=f(xt)F_{t}=f(x_{t})Ft=f(xt),最优解为:
xtest=xtest(reg(i),Ftest=Ftest(reg(i)(3)x_{test}=x^{(reg(i)}_{test}, \quad F_{test}=F^{(reg(i)}_{test} \tag{3}xtest=xtest(reg(i),Ftest=Ftest(reg(i)(3)
1.2 投影集群初始化
给定种群规模NNN和变量维度DDD,每个投影代理的初始化公式为:
Xij=τ0×(UBj−LBj)+LBj(4)X_{ij}=\tau_{0}\times(UB_{j}-LB_{j})+LB_{j} \tag{4}Xij=τ0×(UBj−LBj)+LBj(4)
其中LBj=[b1,b2,...,bDj]LB_{j}=[b_{1},b_{2},...,b_{Dj}]LBj=[b1,b2,...,bDj],UBj=[ab1,ab2,...,abDj]UB_{j}=[ab_{1},ab_{2},...,ab_{Dj}]UBj=[ab1,ab2,...,abDj]分别表示变量上下界。
1.3 残差引导投影(RGP)
RGP过程通过整合Kaczmarz行动作迭代更新策略与随机梯度下降(SGD),建立协同混合框架。根据随机数τ1\tau_{1}τ1和τ2\tau_{2}τ2的比较结果选择策略:
Xst,Xst={P=(F)2∑i=1n(F)2→1,若τ1≥τ2Ft→Ftest,否则(5)X_{st},X_{st}=\begin{cases} P=\frac{(F)^{2}}{\sum_{i=1}^{n}(F)^{2}}\to 1, & \text{若}\tau_{1}\geq\tau_{2} \\ F_{t}\to F_{test}, & \text{否则} \end{cases} \tag{5}Xst,Xst={P=∑i=1n(F)2(F)2→1,Ft→Ftest,若τ1≥τ2否则(5)
当τ1≥τ2\tau_{1}\geq\tau_{2}τ1≥τ2时,平方残差(F)2(F)^{2}(F)2的归一化概率分布P∈[0,1]P\in[0,1]P∈[0,1]使算法更关注误差较大区域。
解更新时使用的梯度信息G1G_{1}G1计算如下:
G1={R⋅(Xst−Xtest)+(1−R)⋅(Xst−Xtest)2,若∃τ1≥2τ2R⋅(Xst−Xtest)+(1−R)⋅(Xst−Xtest)2,否则(6)G_{1}=\begin{cases}
\frac{R\cdot(X_{st}-X_{test})+(1-R)\cdot(X_{st}-X_{test})}{2}, & \text{若}\exists\tau_{1}\geq 2\tau_{2} \\
\frac{R\cdot(X_{st}-X_{test})+(1-R)\cdot(X_{st}-X_{test})}{2}, & \text{否则}
\end{cases} \tag{6}G1={2R⋅(Xst−Xtest)+(1−R)⋅(Xst−Xtest),2R⋅(Xst−Xtest)+(1−R)⋅(Xst−Xtest),若∃τ1≥2τ2否则(6)
其中R,τ1,τ2R,\tau_{1},\tau_{2}R,τ1,τ2为[0,1]区间随机数。
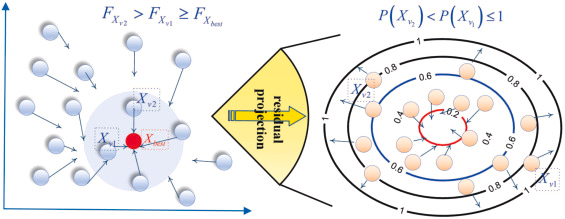
图2. RGP过程的选择策略示意图
雅可比矩阵JJJ是描述非线性优化问题中解对输入变化敏感性的关键工具。对目标函数f(x)f(x)f(x)进行雅可比计算后,RGP能基于目标函数的局部线性化执行更精确的投影更新。
当目标函数f(x)f(x)f(x)输出mmm维向量且输入xxx为nnn维向量时,雅可比矩阵元素JijJ_{ij}Jij表示目标函数对变量xix_ixi的偏导数:
Jij=∂f∂xi≈f(x+sei)−f(x)s(7)J_{ij}=\frac{\partial f}{\partial x_{i}}\approx\frac{f\left(x+s e_{i}\right)-f(x)}{s} \tag{7}Jij=∂xi∂f≈sf(x+sei)−f(x)(7)
其中fj(x)f_j(x)fj(x)是目标函数的第jjj个分量,eie_iei是第iii位为1的标准基向量,sss为微小扰动值。通过扰动xix_ixi计算每个分量的雅可比值:
Jji=fj(x1,...,xi+s,...,xn)−fj(x1,...,xn)s(8)J_{ji}=\frac{f_{j}\left(x_1,...,x_i+s,...,x_n\right)-f_j\left(x_1,...,x_n\right)}{s} \tag{8}Jji=sfj(x1,...,xi+s,...,xn)−fj(x1,...,xn)(8)
最终形成m×nm\times nm×n维雅可比矩阵:
J=[J11⋯J1n⋮⋱⋮Jm1⋯Jmn]J=\begin{bmatrix}J_{11}&\cdots&J_{1n}\\ \vdots&\ddots&\vdots\\ J_{m1}&\cdots&J_{mn}\end{bmatrix}J=J11⋮Jm1⋯⋱⋯J1n⋮Jmn
位置更新公式结合梯度与投影操作:
Xijt+1={Xi−δ×G1,若 3τ1≥2τ2Xi+J×δ×G1T,否则(9)X_{ij}^{t+1}=\begin{cases}
X_i - \delta \times G_1, & \text{若 }3\tau_1 \geq 2\tau_2 \\
X_i + J \times \delta \times G_1^T, & \text{否则}
\end{cases} \tag{9}Xijt+1={Xi−δ×G1,Xi+J×δ×G1T,若 3τ1≥2τ2否则(9)
动态参数δ\deltaδ随迭代变化:
KaTeX parse error: Expected '\right', got 'EOF' at end of input: …right) \tag{10}
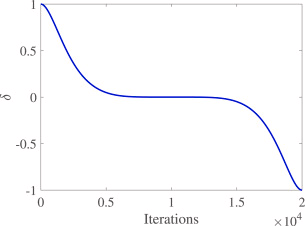
图3.动态衰减步长示意图
1.4 双重随机投影(DRP)
通过双重随机性增强算法全局搜索能力:
-
随机选择两个索引v3v_3v3和v4v_4v4作为投影参考点:
v3,v4=randi(N,2)∈{1,...,N}(11)v_3,v_4 = \text{randi}(N,2) \in \{1,...,N\} \tag{11}v3,v4=randi(N,2)∈{1,...,N}(11) -
梯度投影更新(当τ3≥2τ4\tau_3 \geq 2\tau_4τ3≥2τ4时):
{gt=R⋅(Xv3−Xbest)+(1−R)⋅(Xv4−Xbest)2Xit+1=Xi−δ×gt(12)\begin{cases} g_t = \frac{R \cdot (X_{v3}-X_{best}) + (1-R) \cdot (X_{v4}-X_{best})}{2} \\ X_i^{t+1} = X_i - \delta \times g_t \end{cases} \tag{12}{gt=2R⋅(Xv3−Xbest)+(1−R)⋅(Xv4−Xbest)Xit+1=Xi−δ×gt(12) -
雅可比矩阵投影更新(当τ3<2τ4\tau_3 < 2\tau_4τ3<2τ4时):
{gt=R⋅(Xv3−Xbest)+(1−R)⋅(Xv4−Xbest)2Xit+1=Xi+J×δ×gtT(13)\begin{cases} g_t = \frac{R \cdot (X_{v3}-X_{best}) + (1-R) \cdot (X_{v4}-X_{best})}{2} \\ X_i^{t+1} = X_i + J \times \delta \times g_t^T \end{cases} \tag{13}{gt=2R⋅(Xv3−Xbest)+(1−R)⋅(Xv4−Xbest)Xit+1=Xi+J×δ×gtT(13)
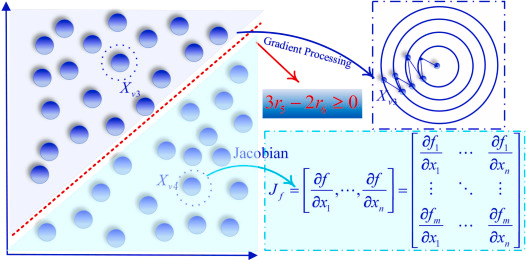
图4 双重随机投影流程示意图
1.5 加权随机投影更新(WRPU)
加权随机投影更新是通过随机加权和自适应调节来引导粒子在解空间中向最优解移动的优化过程。该过程结合随机性和结构化投影,在探索过程中保持粒子的全局和局部特性平衡,从而提高优化效率。
- 随机因子生成:投影起点
决定粒子位置更新分量权重的随机因子r7r_7r7和r8r_8r8:
r7=1+rand,r8=1+rand(14)r_7=1+rand, \quad r_8=1+rand \tag{14}r7=1+rand,r8=1+rand(14)
这两个动态参数确保每次位置更新的多样性和不可预测性。
- 投影路径构建:多路径策略
粒子位置更新基于两种投影路径:
路径1:随机加权投影
Xn3proj(t+1)=r7×Xi+(1−R)×Xbest+r8×(Xi−Xbest)(15)X^{proj(t+1)}_{n3}=r_7 \times X_i + (1-R) \times X_{best} + r_8 \times (X_i - X_{best}) \tag{15}Xn3proj(t+1)=r7×Xi+(1−R)×Xbest+r8×(Xi−Xbest)(15)
通过随机权重r7r_7r7平衡当前位置XiX_iXi和目标位置XbestX_{best}Xbest,扰动项r8r_8r8增强路径灵活性以跳出局部最优。
路径2:自适应校正投影
Xn3proj(t+1)=Xi+α×(Xn1proj(t+1)−Xbest)(16)X^{proj(t+1)}_{n3}=X_i + \alpha \times (X^{proj(t+1)}_{n1} - X_{best}) \tag{16}Xn3proj(t+1)=Xi+α×(Xn1proj(t+1)−Xbest)(16)
其中自适应因子α=(1−t/T)×rand\alpha=(1-t/T)\times randα=(1−t/T)×rand随迭代调节步长:初期α≈rand\alpha \approx randα≈rand支持全局探索,后期α→0\alpha \to 0α→0促进局部收敛。
维度因子rand/jrand/jrand/j决定路径选择:当rand/j>randrand/j>randrand/j>rand时选择路径1,其他情况选择路径2,随着维度jjj增加更倾向于选择稳定路径,保持高维解的稳定性。
1.5 Lévy飞行引导投影(LFGP)
通过模拟自然界生物的随机运动实现高效全局搜索和局部优化。
- 触发机制:Lévy投影概率
Plevy=12(tanh(9×tT−5)+1)(17)P_{levy}=\frac{1}{2}\left(\tanh\left(9\times\frac{t}{T}-5\right)+1\right) \tag{17}Plevy=21(tanh(9×Tt−5)+1)(17)
通过概率控制在不同迭代阶段触发:
- 初期:较低概率保留探索空间
- 后期:渐增概率加强最优解引导

1.6 Lévy飞行步长生成
{z=u∣v∣1/β,其中u∼N(0,σu2),v∼N(0,1)σu=(Γ(1+β)×sin(πβ/2)Γ((1+β)/2)×β×2(β−1)/2)1/β(18)
\begin{cases}
z = \frac{u}{|v|^{1/\beta}}, & \text{其中} u \sim N(0, \sigma_u^2), v \sim N(0, 1) \\
\sigma_u = \left(\frac{\Gamma(1+\beta) \times \sin(\pi \beta/2)}{\Gamma((1+\beta)/2) \times \beta \times 2^{(\beta-1)/2}}\right)^{1/\beta}
\end{cases} \tag{18}
⎩⎨⎧z=∣v∣1/βu,σu=(Γ((1+β)/2)×β×2(β−1)/2Γ(1+β)×sin(πβ/2))1/β其中u∼N(0,σu2),v∼N(0,1)(18)
式中:β\betaβ为[0,2]区间内的随机数,vvv为[0,1]区间内的随机数,Γ\GammaΓ表示伽马函数
Lévy分布用于生成长尾随机步长,使粒子能在解空间中进行长距离跳跃,避免陷入局部最优解。该机制通过β\betaβ参数控制步长分布形态,当β\betaβ接近2时趋向高斯分布,接近0时呈现显著的长尾特性。
位置更新通过结合最优解XEliteX_{Elite}XElite和当前解XiX_iXi实现,并采用随机权重动态调节:
d=rand×(1−t/T)2(19)d = rand \times (1 - t/T)^2 \tag{19}d=rand×(1−t/T)2(19)
位置更新公式如下
Xn4proj(t+1)=r9×XElite+(1−r9)×z×d×(XElite−Xi×(2tT))(20)X^{proj(t+1)}_{n4} = r_9 \times X_{Elite} + (1-r_9) \times z \times d \times \left(X_{Elite} - X_i \times \left(2\frac{t}{T}\right)\right) \tag{20}Xn4proj(t+1)=r9×XElite+(1−r9)×z×d×(XElite−Xi×(2Tt))(20)
其中:XElite=Best{Xn1proj(t+1),Xn2proj(t+1),Xn3proj(t+1)}X_{Elite} = Best\{X^{proj(t+1)}_{n1}, X^{proj(t+1)}_{n2}, X^{proj(t+1)}_{n3}\}XElite=Best{Xn1proj(t+1),Xn2proj(t+1),Xn3proj(t+1)}表示前三步最优粒子,r9r_9r9为[0,1]区间随机数,权重ddd随迭代逐渐减小,实现从全局搜索到局部收敛的过渡。
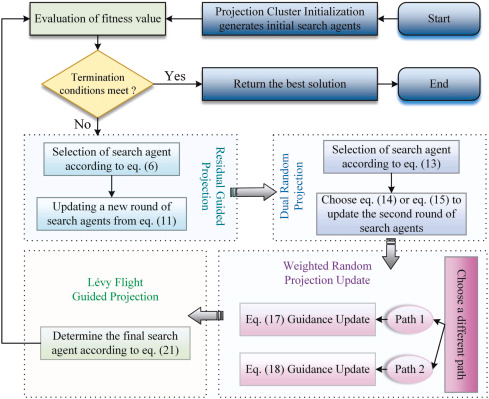
2、 完整代码
% Projection-Iterative-Methods-based Optimizer: A novel metaheuristic
% algorithm for continuous optimization problems and feature selection
function [Best_Score, Best_Pos, CG_curve] = PIMO(N, Max_iter, lb, ub, dim, fobj)Position = initialization(N, dim, ub, lb); Fitness = zeros(N, 1); epsilon = 1e-6;alphabet = 1 : N;%% Record the initial optimal solution and fitnessfor i = 1:NFitness(i) = fobj(Position(i,:)); end[~, Ind] = sort(Fitness); Best_Score = Fitness(Ind(1));Best_Pos = Position(Ind(1),:);CG_curve = zeros(1, Max_iter);% Store convergence information%% Main optimization loopfor it = 1:Max_iterdelta = sin(pi/2 * (1 - (2*it / Max_iter)).^5); % eq.(12)a = (1 - it/Max_iter) * rand(1, dim);for i = 1:Nrr1 = rand;rr2 = rand;if rr1 >= rr2Pr = (Fitness.^2)/((norm(Fitness)^2));P = randsrc(1, 2, [alphabet; Pr']);P1 = P(1);P2 = P(2);elseP = Ind(1:2);P1 = P(1);P2 = P(2);endr = rand;J = Get_jacobian(fobj, Position(P1, :), epsilon); % Generalised Jacobi matrixif 3*rand >= 2*rand% eq.(14)grad = (r * (Position(P1, :) - Best_Pos) + (1-r) * (Position(P2, :) - Best_Pos)) / 2;pos_n1 = Position(i,:) - delta * grad;else% eq.(15)grad = (r * (Position(P2, :) - Best_Pos) + (1-r) * (Position(P1, :) - Best_Pos)) / 2;pos_n1 = Position(i,:) + delta * J * grad';endnewpos1 = max(min(pos_n1, ub), lb);fitt = fobj(newpos1);if fitt < Fitness(i)Fitness(i)= fitt;Position(i,:) = newpos1;endif rand > randP = randperm(N, 2); % eq.(13)P1 = P(1);P2 = P(2);if 3*rand >= 2*rand% eq.(14)grad = (r * (Position(P1, :) - Best_Pos) + (1-r) * (Position(P2, :) - Best_Pos)) / 2;pos_n2 = Position(i,:) - delta * grad;else% eq.(15)grad = (r * (Position(P2, :) - Best_Pos) + (1-r) * (Position(P1, :) - Best_Pos)) / 2;pos_n2 = Position(i,:) + delta * J * grad';endnewpos2 = max(min(pos_n2, ub), lb);fitt = fobj(newpos2);if fitt < Fitness(i)Fitness(i)= fitt;Position(i,:) = newpos2;endendfor j = 1 : dimr1 = 1+rand;r2 = 1+rand; % eq.(16)pho_1 = r1 * Position(i, :) + (1-r1) * Best_Pos + r2 * (Position(i, :) - Best_Pos); % eq.(17)pho_2 = Position(i,:) + a.* (newpos1 - Best_Pos); % eq.(18)pos_n3 = Position(i,:);if rand/j > randpos_n3(j) = pho_1(j);elsepos_n3(j) = pho_2(j);endnewpos3 = max(min(pos_n3, ub), lb);fitt = fobj(newpos3);if fitt < Fitness(i)Fitness(i)= fitt;Position(i,:) = newpos3;endend endif rand <= 1/2*(tanh(9*it/Max_iter-5)+1)pos_n4 = zeros(1, dim);d=rand()*(1-it/Max_iter)^2;Step_length=levy(N, dim,1.5);Elite=repmat(Best_Pos, N, 1);r=rand;for i=1:Nfor j=1:dimpos_n4(j)=r*Elite(i,j)+(1-r)*Step_length(i,j)*d*...(Elite(i,j)-Position(i,j)*(2*it/Max_iter)); % eq.(21)endnewpos4 = max(min(pos_n4, ub), lb);fitt = fobj(newpos4);if fitt < Fitness(i)Fitness(i) = fitt;Position(i,:) = newpos4;endendend%% Record convergence curve[~, Ind] = sort(Fitness); if Fitness(Ind(1)) < Best_ScoreBest_Score = Fitness(Ind(1));Best_Pos = Position(Ind(1),:);endCG_curve(it) = Best_Score;end
end
% Finite difference method for approximating generalised Jacobi matrix
function J = Get_jacobian(fobj, x, epsilon)
% f: handle to target function, accepts vector x
% x: current point (vector)
% epsilon: small perturbation valuen = length(x);fx = fobj(x);m = length(fx);J = zeros(m, n); % Calculate the finite difference in each direction according to eqs. (9) and (10).for i = 1:nx_perturbed = x;x_perturbed(i) = x_perturbed(i) + epsilon;f_perturbed = fobj(x_perturbed);J(:, i) = (f_perturbed - fx) / epsilon;end
end
function [z] = levy(n,m,beta)% beta is set to 1.5 in this papernum = gamma(1+beta)*sin(pi*beta/2);den = gamma((1+beta)/2)*beta*2^((beta-1)/2);sigma_u = (num/den)^(1/beta); % eq.(20)u = random('Normal',0,sigma_u,n,m);v = random('Normal',0,1,n,m);z =u./(abs(v).^(1/beta));
end
% Initialization function
function X = initialization(N, Dim, UB, LB)B_no = size(UB, 2); % number of boundariesif B_no == 1X = rand(N, Dim) .* (UB - LB) + LB;end% If each variable has a different lb and ubif B_no > 1X = zeros(N, Dim);for i = 1:DimUb_i = UB(i);Lb_i = LB(i);X(:, i) = rand(N, 1) .* (Ub_i - Lb_i) + Lb_i;endend
end
Dongmei Yu, Yanzhe Ji, Yiqiang Xia,Projection-Iterative-Methods-based Optimizer: A novel metaheuristic algorithm for continuous optimization problems and feature selection,Knowledge-Based Systems,Volume 326,2025,113978,https://doi.org/10.1016/j.knosys.2025.113978.