基于Milvus和BGE-VL模型实现以图搜图
背景
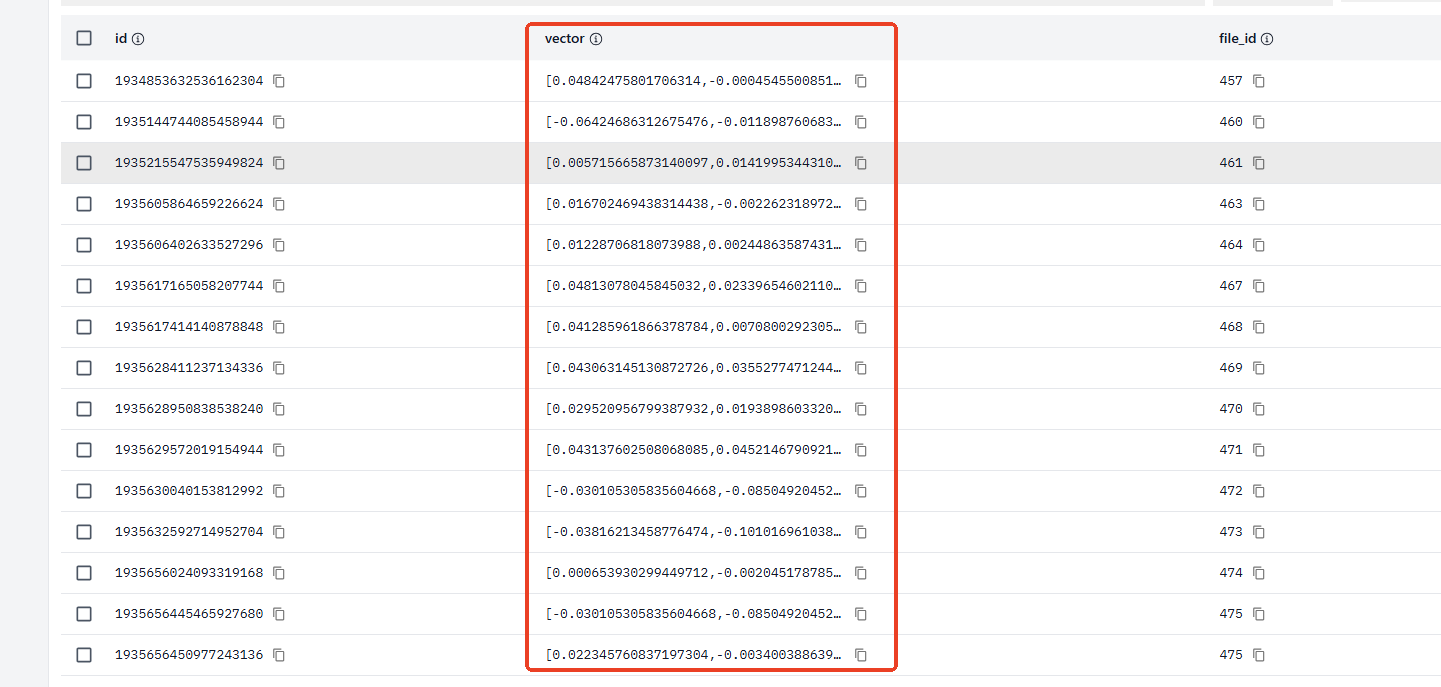
最近再做项目的时候,里面有个AI检索的功能,其中一个点就是要实现以图搜图,也就是用户上传一张图,要找出相似度比较高的图,比如下面这样,第一张是原图,第二张是图中的一部分,用户上传第二张图,要能检索到第一张完整的图


实现思路
整个实现的核心就是用向量检索,也就是在运营端上传第一张图片的时候,先把整个图片转换为向量,存储到向量数据库中,然后用户在检索的时候,把第二张图再转换为向量,与第一张图的向量进行对比,比如余弦相似度,当然,这里不用我们自己去实现,向量数据库已经实现了,我们只需要像查询普通的关系型数据库一样查询就行,整个连路途如下:
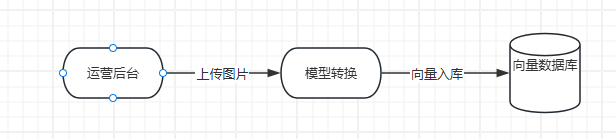
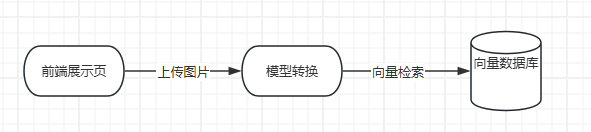
项目的后台web采用的是springboot实现,将图片转换为向量时会涉及到与python程序的交互,此处是用python的flask暴露一http接口供java调用
其中模型转换是用的BGE-VL这个模型,通过它把图片转换为向量,然后进行入库或者检索,关于该模型的详细信息,可以参考github链接:https://github.com/VectorSpaceLab/MegaPairs
向量数据库使用的是Milvus,这个数据库官方说是单机节点即可支撑10亿级别的向量数据检索,并且安装也很方便:Run Milvus in Docker (Linux) | Milvus Documentation,如果不想安装的话,有相应的python版本的数据库,也就是通过pip命令安装好milvus的依赖之后,就自带了的milvus数据库,如果是自己安装的话,官方提供了可视化的客户端工具Attu
代码实现
将图片转换为向量的核心代码用python实现如下:
import torch
from transformers import AutoModel
import os# 使用本地模型路径
MODEL_PATH = "../bgevl" # 指向本地模型文件夹# 获取绝对路径以确保路径正确
current_dir = os.path.dirname(os.path.abspath(__file__))
model_path = os.path.join(os.path.dirname(current_dir), "bgevl")print(f"正在加载本地BGE-VL模型: {model_path}")try:# 从本地路径加载模型,添加local_files_only=True确保只使用本地文件model = AutoModel.from_pretrained(model_path, trust_remote_code=True,local_files_only=True # 强制使用本地文件)# 设置处理器也使用本地路径model.set_processor(model_path)model.eval()print("✅ 本地BGE-VL模型加载成功!")except Exception as e:print(f"❌ 本地模型加载失败: {e}")print("尝试使用相对路径...")# 如果绝对路径失败,尝试相对路径model = AutoModel.from_pretrained("../bgevl", trust_remote_code=True,local_files_only=True)model.set_processor("../bgevl")model.eval()print("✅ 模型加载成功!")# 使用模型进行推理
with torch.no_grad():print("正在处理查询图片和文本...")query = model.encode(images="../images/sample2.png",)print("正在处理候选图片...")candidates = model.encode(images=["../images/sample.png", "../images/ceshi2.png"])# 计算相似度分数scores = query @ candidates.Tprint(f"相似度分数: {scores}")print(f"查询向量维度: {query.shape}")print(f"候选向量维度: {candidates.shape}")
完整版暴露http接口实现如下,其中既可以传递文件流的方式,也可以传递文件的url(因为有些图片是上传到oss的)
from flask import Flask, request, jsonify
from flask_cors import CORS
import os
import sys
import traceback
import numpy as np
from werkzeug.utils import secure_filename
import tempfile
import base64
from io import BytesIO
from PIL import Image# 添加vector模块到路径
sys.path.append(os.path.join(os.path.dirname(__file__), 'vector'))# 导入向量化器
from vector.TransformerImgToVector import ImageVectorizerAlternativeapp = Flask(__name__)
CORS(app) # 允许跨域请求# 配置
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024 # 16MB max file size
UPLOAD_FOLDER = 'temp_uploads'
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg', 'gif', 'bmp', 'webp'}# 确保上传文件夹存在
os.makedirs(UPLOAD_FOLDER, exist_ok=True)# 全局变量存储模型实例
bge_model = Nonedef allowed_file(filename):"""检查文件扩展名是否允许Args:filename (str): 文件名Returns:bool: 是否允许的文件类型"""return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONSdef init_models():"""初始化所有模型"""global bge_modeltry:print("正在初始化BGE-VL模型...")# 这里需要根据你的BGE-VL模型加载逻辑进行调整current_dir = os.path.dirname(os.path.abspath(__file__))model_path = os.path.join(current_dir, "bgevl")from transformers import AutoModelbge_model = AutoModel.from_pretrained(model_path,trust_remote_code=True,local_files_only=True)bge_model.set_processor(model_path)bge_model.eval()print("✅ BGE-VL模型初始化成功")except Exception as e:print(f"❌ BGE-VL模型初始化失败: {e}")bge_model = Nonedef save_base64_image(base64_string):"""保存base64编码的图片到临时文件Args:base64_string (str): base64编码的图片数据Returns:str: 临时文件路径"""try:# 解码base64image_data = base64.b64decode(base64_string)image = Image.open(BytesIO(image_data))# 创建临时文件temp_file = tempfile.NamedTemporaryFile(delete=False, suffix='.png', dir=UPLOAD_FOLDER)image.save(temp_file.name, 'PNG')temp_file.close()return temp_file.nameexcept Exception as e:raise ValueError(f"无效的base64图片数据: {e}")@app.route('/', methods=['GET'])
def health_check():"""健康检查接口"""return jsonify({'status': 'success','message': '图像向量化API服务正常运行','models': {'bge_vl': bge_model is not None}})@app.route('/api/bge/encode', methods=['POST', 'GET'])
def bge_encode():"""BGE-VL模型编码接口支持图像和文本的联合编码GET请求参数:- url: 远程图片URL- path: 本地图片路径 - text: 文本内容(可选)POST请求:保持原有JSON格式"""if bge_model is None:return jsonify({'status': 'error','message': 'BGE-VL模型未初始化'}), 500try:images = []text = ''temp_files = []# 处理GET请求if request.method == 'GET':# 从URL参数获取图片和文本image_url = request.args.get('url')local_path = request.args.get('path')text = request.args.get('text', '')if image_url:images = [image_url]elif local_path:images = [local_path]elif not text:return jsonify({'status': 'error', 'message': '请提供url、path或text参数'}), 400# 处理POST请求(保持原有逻辑)elif request.method == 'POST':data = request.get_json()if not data:return jsonify({'status': 'error', 'message': '无效的JSON数据'}), 400images = data.get('images', [])text = data.get('text', '')if not images and not text:return jsonify({'status': 'error', 'message': '请提供图像或文本数据'}), 400# 处理图像路径 - 添加强化的远程URL下载逻辑processed_images = []for img in images:if isinstance(img, str):if img.startswith('data:image'):# Base64图像base64_data = img.split(',')[1]temp_file = save_base64_image(base64_data)processed_images.append(temp_file)temp_files.append(temp_file)elif img.startswith('http://') or img.startswith('https://'):# 远程URL - 使用多种方法绕过代理问题import tempfilefrom urllib.parse import urlparsetry:# 方法1: 使用requests禁用代理import requestsimport os# 临时清除代理环境变量original_proxies = {}proxy_vars = ['HTTP_PROXY', 'HTTPS_PROXY', 'http_proxy', 'https_proxy']for var in proxy_vars:if var in os.environ:original_proxies[var] = os.environ[var]del os.environ[var]try:# 创建session并禁用代理session = requests.Session()session.trust_env = Falsesession.proxies = {}# 设置请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}response = session.get(img, headers=headers, timeout=30, verify=False)response.raise_for_status()finally:# 恢复原始代理设置for var, value in original_proxies.items():os.environ[var] = valueexcept Exception as e1:print(f"方法1失败: {e1}")try:# 方法2: 使用urllib绕过代理import urllib.requestimport urllib.error# 创建不使用代理的openerproxy_handler = urllib.request.ProxyHandler({})opener = urllib.request.build_opener(proxy_handler)# 设置请求头req = urllib.request.Request(img,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'})with opener.open(req, timeout=30) as response:image_data = response.read()# 模拟response对象class MockResponse:def __init__(self, content):self.content = contentresponse = MockResponse(image_data)except Exception as e2:print(f"方法2失败: {e2}")try:# 方法3: 使用httpx库(如果可用)import httpxwith httpx.Client(proxies={}, verify=False) as client:response = client.get(img, timeout=30)response.raise_for_status()# 模拟response对象class MockResponse:def __init__(self, content):self.content = contentresponse = MockResponse(response.content)except Exception as e3:return jsonify({'status': 'error','message': f'所有下载方法都失败了。方法1: {str(e1)}, 方法2: {str(e2)}, 方法3: {str(e3)}'}), 400# 获取文件扩展名parsed_url = urlparse(img)file_ext = os.path.splitext(parsed_url.path)[1] or '.jpg'# 创建临时文件temp_file = tempfile.NamedTemporaryFile(delete=False, suffix=file_ext, dir=UPLOAD_FOLDER)temp_file.write(response.content)temp_file.close()processed_images.append(temp_file.name)temp_files.append(temp_file.name)else:# 本地路径processed_images.append(img)# 在BGE编码部分(大约第395-410行),修改编码逻辑# 编码import torchwith torch.no_grad():if text and processed_images:# 图像+文本编码 - 确保类型一致if len(processed_images) == 1 and isinstance(text, str):# 单个图像和单个文本:都转换为字符串encoded = bge_model.encode(images=processed_images[0], text=text)else:# 多个图像或文本:都转换为列表if isinstance(text, str):text_list = [text] * len(processed_images) # 为每个图像复制文本else:text_list = textencoded = bge_model.encode(images=processed_images, text=text_list)elif processed_images:# 仅图像编码if len(processed_images) == 1:encoded = bge_model.encode(images=processed_images[0])else:encoded = bge_model.encode(images=processed_images)else:# 仅文本编码encoded = bge_model.encode(text=text)# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)return jsonify({'status': 'success','vector': encoded.tolist() if hasattr(encoded, 'tolist') else encoded,'dimension': encoded.shape if hasattr(encoded, 'shape') else len(encoded),'model': 'BGE-VL'})except Exception as e:# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)return jsonify({'status': 'error','message': f'编码失败: {str(e)}','traceback': traceback.format_exc()}), 500@app.route('/api/bge/encode-stream', methods=['POST'])
def bge_encode_stream():"""BGE-VL模型统一编码接口支持三种向量化模式:1. 仅文字向量化:只传text参数2. 仅图片向量化:只传file参数3. 文字+图片联合向量化:同时传text和file参数请求方式:- POST multipart/form-data- 参数:- file: 图片文件流(可选)- text: 文本内容(可选)- 注意:file和text至少提供一个返回:- 成功:返回向量数据和维度信息- 失败:返回错误信息"""if bge_model is None:return jsonify({'status': 'error','message': 'BGE-VL模型未初始化'}), 500try:# 获取文本参数text = request.form.get('text', '').strip()# 检查文件上传has_file = 'file' in request.files and request.files['file'].filename != ''has_text = bool(text)# 验证至少有一个输入if not has_file and not has_text:return jsonify({'status': 'error', 'message': '请至少提供文件或文本内容中的一个'}), 400temp_files = []processed_images = []filename = Noneinput_type = None# 处理文件(如果有)if has_file:file = request.files['file']# 检查文件类型if not allowed_file(file.filename):return jsonify({'status': 'error', 'message': f'不支持的文件类型,支持的格式:{", ".join(ALLOWED_EXTENSIONS)}'}), 400# 保存上传的文件到临时目录filename = secure_filename(file.filename)temp_file_path = os.path.join(UPLOAD_FOLDER, filename)file.save(temp_file_path)temp_files.append(temp_file_path)processed_images.append(temp_file_path)# 确定输入类型if has_file and has_text:input_type = 'image+text'elif has_file:input_type = 'image_only'else:input_type = 'text_only'try:# 使用BGE-VL模型进行编码import torchwith torch.no_grad():if input_type == 'image+text':# 图像+文本联合编码encoded = bge_model.encode(images=processed_images[0], text=text)elif input_type == 'image_only':# 仅图像编码encoded = bge_model.encode(images=processed_images[0])elif input_type == 'text_only':# 仅文本编码encoded = bge_model.encode(text=text)else:return jsonify({'status': 'error','message': '未知的输入类型'}), 400# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)# 构建响应response_data = {'status': 'success','vector': encoded.tolist() if hasattr(encoded, 'tolist') else encoded,'dimension': encoded.shape if hasattr(encoded, 'shape') else len(encoded),'model': 'BGE-VL','input_type': input_type}# 添加文件名(如果有)if filename:response_data['filename'] = filename# 添加文本内容(如果有且不太长)if has_text and len(text) <= 100:response_data['text_preview'] = textelif has_text:response_data['text_preview'] = text[:100] + '...'return jsonify(response_data)except Exception as e:# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)return jsonify({'status': 'error','message': f'BGE-VL编码失败: {str(e)}','traceback': traceback.format_exc()}), 500except Exception as e:return jsonify({'status': 'error','message': f'请求处理失败: {str(e)}','traceback': traceback.format_exc()}), 500@app.route('/api/bge/encode-multi-stream', methods=['POST'])
def bge_encode_multi_stream():"""BGE-VL模型多文件流编码接口支持同时上传多个文件流进行批量向量化处理请求方式:- POST multipart/form-data- 参数:- files: 多个图片文件流(必需)- text: 文本内容(可选)返回:- 成功:返回向量数据和维度信息- 失败:返回错误信息"""if bge_model is None:return jsonify({'status': 'error','message': 'BGE-VL模型未初始化'}), 500try:# 检查是否有文件上传if 'files' not in request.files:return jsonify({'status': 'error', 'message': '没有上传文件流'}), 400files = request.files.getlist('files')if not files or all(f.filename == '' for f in files):return jsonify({'status': 'error', 'message': '没有选择有效文件'}), 400# 获取可选的文本参数text = request.form.get('text', '')# 处理多个文件temp_files = []processed_images = []filenames = []for file in files:if file.filename != '' and allowed_file(file.filename):# 保存文件到临时目录filename = secure_filename(file.filename)temp_file_path = os.path.join(UPLOAD_FOLDER, filename)file.save(temp_file_path)temp_files.append(temp_file_path)processed_images.append(temp_file_path)filenames.append(filename)if not processed_images:return jsonify({'status': 'error','message': f'没有有效的图片文件,支持的格式:{", ".join(ALLOWED_EXTENSIONS)}'}), 400try:# 使用BGE-VL模型进行批量编码import torchwith torch.no_grad():if text and processed_images:# 图像+文本联合编码encoded = bge_model.encode(images=processed_images, text=text)elif processed_images:# 仅图像编码encoded = bge_model.encode(images=processed_images)else:return jsonify({'status': 'error','message': '没有提供有效的图像或文本数据'}), 400# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)return jsonify({'status': 'success','vector': encoded.tolist() if hasattr(encoded, 'tolist') else encoded,'dimension': encoded.shape if hasattr(encoded, 'shape') else len(encoded),'model': 'BGE-VL','input_type': 'images+text' if text else 'images_only','file_count': len(filenames),'filenames': filenames})except Exception as e:# 清理临时文件for temp_file in temp_files:if os.path.exists(temp_file):os.remove(temp_file)return jsonify({'status': 'error','message': f'BGE-VL批量编码失败: {str(e)}','traceback': traceback.format_exc()}), 500except Exception as e:return jsonify({'status': 'error','message': f'多文件流处理失败: {str(e)}','traceback': traceback.format_exc()}), 500@app.route('/api/similarity', methods=['POST'])
def calculate_similarity():"""计算向量相似度接口"""try:data = request.get_json()if not data:return jsonify({'status': 'error', 'message': '无效的JSON数据'}), 400vector1 = np.array(data.get('vector1', []))vector2 = np.array(data.get('vector2', []))if len(vector1) == 0 or len(vector2) == 0:return jsonify({'status': 'error', 'message': '请提供两个向量'}), 400if len(vector1) != len(vector2):return jsonify({'status': 'error', 'message': '向量维度不匹配'}), 400# 计算余弦相似度similarity = np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2))return jsonify({'status': 'success','similarity': float(similarity),'vector1_dim': len(vector1),'vector2_dim': len(vector2)})except Exception as e:return jsonify({'status': 'error','message': f'相似度计算失败: {str(e)}'}), 500if __name__ == '__main__':print("正在启动图像向量化API服务...")init_models()print("\n🚀 服务启动成功!")print("API文档:")print(" - GET / : 健康检查")print(" - POST /api/clip/vectorize : CLIP图像向量化")print(" - POST /api/bge/encode : BGE-VL编码")print(" - POST /api/similarity : 向量相似度计算")print("\n访问地址: http://localhost:5000")app.run(host='0.0.0.0', port=5000, debug=True)java操作milvus数据库核心代码:
import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.util.IdUtil;
import io.milvus.client.MilvusServiceClient;
import io.milvus.common.clientenum.ConsistencyLevelEnum;
import io.milvus.grpc.DataType;
import io.milvus.grpc.DescribeCollectionResponse;
import io.milvus.grpc.MutationResult;
import io.milvus.grpc.SearchResults;
import io.milvus.param.IndexType;
import io.milvus.param.MetricType;
import io.milvus.param.R;
import io.milvus.param.RpcStatus;
import io.milvus.param.collection.*;
import io.milvus.param.dml.InsertParam;
import io.milvus.param.dml.SearchParam;
import io.milvus.param.index.CreateIndexParam;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;/*** Milvus 操作服务类*/
@Service
public class MilvusService {@Autowiredprivate MilvusServiceClient milvusClient;/*** 创建集合(Collection)* @param collectionName 集合名称* @param dimension 向量维度* @return 是否创建成功*/public boolean createCollection(String collectionName, int dimension) {try {// 定义字段FieldType idField = FieldType.newBuilder().withName("id").withDataType(DataType.Int64).withPrimaryKey(true).withAutoID(true).build();FieldType vectorField = FieldType.newBuilder().withName("vector").withDataType(DataType.FloatVector).withDimension(dimension).build();// 创建集合模式CreateCollectionParam createCollectionParam = CreateCollectionParam.newBuilder().withCollectionName(collectionName).withDescription("图像向量集合").addFieldType(idField).addFieldType(vectorField).build();R<RpcStatus> response = milvusClient.createCollection(createCollectionParam);return response.getStatus() == R.Status.Success.getCode();} catch (Exception e) {e.printStackTrace();return false;}}/*** 创建索引* @param collectionName 集合名称* @return 是否创建成功*/public boolean createIndex(String collectionName) {try {CreateIndexParam createIndexParam = CreateIndexParam.newBuilder().withCollectionName(collectionName).withFieldName("vector").withIndexType(IndexType.IVF_FLAT).withMetricType(MetricType.L2).withExtraParam("{\"nlist\":1024}").build();R<RpcStatus> response = milvusClient.createIndex(createIndexParam);return response.getStatus() == R.Status.Success.getCode();} catch (Exception e) {e.printStackTrace();return false;}}/*** 加载集合到内存* @param collectionName 集合名称* @return 是否加载成功*/public boolean loadCollection(String collectionName) {try {LoadCollectionParam loadCollectionParam = LoadCollectionParam.newBuilder().withCollectionName(collectionName).build();R<RpcStatus> response = milvusClient.loadCollection(loadCollectionParam);return response.getStatus() == R.Status.Success.getCode();} catch (Exception e) {e.printStackTrace();return false;}}/*** 插入向量数据* @param collectionName 集合名称* @param vectors 向量列表* otherFields 其他字段* @return 插入的ID列表*/public List<Long> insertVectors(String collectionName, List<List<Float>> vectors, Map<String,Object> otherFields) {try {List<InsertParam.Field> fields = new ArrayList<>();// 添加向量字段fields.add(new InsertParam.Field("vector", vectors));fields.add(new InsertParam.Field("id", List.of(IdUtil.getSnowflakeNextId())));if (!CollectionUtil.isEmpty(otherFields)) {otherFields.forEach((k, v) -> {fields.add(new InsertParam.Field(k, List.of(v)));});}InsertParam insertParam = InsertParam.newBuilder().withCollectionName(collectionName).withFields(fields).build();R<MutationResult> response = milvusClient.insert(insertParam);if (response.getStatus() == R.Status.Success.getCode()) {return response.getData().getIDs().getIntId().getDataList();}} catch (Exception e) {e.printStackTrace();}return new ArrayList<>();}/*** 向量相似性搜索* @param collectionName 集合名称* @param queryVectors 查询向量* @param topK 返回最相似的K个结果* @return 搜索结果*/public List<SearchResult> searchVectors(String collectionName, List<List<Float>> queryVectors, int topK) {try {R<Boolean> hasCollection = milvusClient.hasCollection(HasCollectionParam.newBuilder().withCollectionName("file_collection").build());System.out.println("Has collection: " + hasCollection.getData());SearchParam searchParam = SearchParam.newBuilder().withCollectionName(collectionName).withConsistencyLevel(ConsistencyLevelEnum.STRONG).withMetricType(MetricType.IP).withOutFields(Arrays.asList("id", "file_id")) // 添加 file_id 字段到输出.withTopK(topK).withVectors(queryVectors).withVectorFieldName("vector").withParams("{\"nprobe\":10}").build();R<SearchResults> response = milvusClient.search(searchParam);if (response.getStatus() == R.Status.Success.getCode()) {return parseSearchResults(response.getData());}} catch (Exception e) {e.printStackTrace();}return new ArrayList<>();}/*** 解析搜索结果* @param searchResults 原始搜索结果* @return 格式化的搜索结果*/private List<SearchResult> parseSearchResults(SearchResults searchResults) {List<SearchResult> results = new ArrayList<>();for (int i = 0; i < searchResults.getResults().getNumQueries(); i++) {for (int j = 0; j < searchResults.getResults().getTopK(); j++) {int index = (int) (i * searchResults.getResults().getTopK() + j);long id = searchResults.getResults().getIds().getIntId().getData(index);float score = searchResults.getResults().getScores(index);// 获取 file_id 字段值String fileId = null;try {// 检查是否有字段数据if (searchResults.getResults().getFieldsDataList() != null && !searchResults.getResults().getFieldsDataList().isEmpty()) {// 遍历字段数据找到 file_idfor (var fieldData : searchResults.getResults().getFieldsDataList()) {if ("file_id".equals(fieldData.getFieldName())) {// 根据字段类型获取值if (fieldData.getScalars().hasStringData()) {var stringDataList = fieldData.getScalars().getStringData().getDataList();if (index < stringDataList.size()) {fileId = stringDataList.get(index);}} else if (fieldData.getScalars().hasLongData()) {var longDataList = fieldData.getScalars().getLongData().getDataList();if (index < longDataList.size()) {fileId = String.valueOf(longDataList.get(index));}}break;}}}} catch (Exception e) {// 如果获取 file_id 失败,记录日志但不影响主要结果System.err.println("获取 file_id 失败: " + e.getMessage());}results.add(new SearchResult(id, score, fileId));}}return results;}/*** 删除集合* @param collectionName 集合名称* @return 是否删除成功*/public boolean dropCollection(String collectionName) {try {DropCollectionParam dropCollectionParam = DropCollectionParam.newBuilder().withCollectionName(collectionName).build();R<RpcStatus> response = milvusClient.dropCollection(dropCollectionParam);return response.getStatus() == R.Status.Success.getCode();} catch (Exception e) {e.printStackTrace();return false;}}/*** 搜索结果内部类*/public static class SearchResult {private long id;private float score;private String fileId; // 新增 fileId 字段public SearchResult(long id, float score) {this.id = id;this.score = score;}public SearchResult(long id, float score, String fileId) {this.id = id;this.score = score;this.fileId = fileId;}// Getters and Setterspublic long getId() { return id; }public void setId(long id) { this.id = id; }public float getScore() { return score; }public void setScore(float score) { this.score = score; }public String getFileId() { return fileId; }public void setFileId(String fileId) { this.fileId = fileId; }}
}其中的SearchResult需要自行根据项目的数据来定,重点是insertVectors写入数据和searchVectors查询数据这两个方法的实现
,milvus在定义数据索引(类似于关系型数据库的表)的时候必须包含一个主键id和vevtor字段,vector就是存储的图片的向量,file_id是自定义的字段,根据业务需求来定即可,我这里的file_id是图片文件对应的mysql数据表里面的主键id