深入解析 Java Stream 设计:从四幕剧看流水线设计与执行机制
java.util.stream 包是 Java Stream API 的核心,它提供了一套用于以声明式方式处理数据序列的工具。其内部实现涉及多个类和接口,它们协同工作以支持流的创建、转换和聚合操作,尤其是在并行处理方面。
Stream的一个完整流程分析:四幕剧
我们可以把整个 list.stream().filter(...).xxx().toArray() 的过程想象成一场精心编排的四幕剧。
第一幕:搭建舞台(懒加载的流水线构建)
list.stream(): 创建了流水线的源头 (Source Stage)。它内部封装了一个指向list的Spliterator的Supplier(提供者)。【ReferencePipeline.Head】.filter(...): 这步什么数据都没处理! 它只是创建了一个新的中间阶段 (Intermediate Stage),这个阶段记录了两件事:1. 它要执行的操作是“过滤”;2. 它的上游是stream()那个源头阶段。然后它返回自己,以便链式调用。【ReferencePipeline.StatelessOp】.xxx(): 同样,创建更多中间阶段,像链条一样一个接一个地挂在上一个阶段后面。【StatelessOp和ReferencePipeline.StatefulOp】
此时,我们只是构建了一个执行计划,一个由 AbstractPipeline 对象组成的双向链表。就像设计好了一张工厂流水线的蓝图,但没有按下任何一个按钮,没有一个元素被处理。这就是延迟计算 (Lazy Evaluation) 的核心。
第二幕:按下开关(终端操作的触发)
.toArray(): 这是终端操作 (Terminal Operation)。它是整场剧的“总导演”和“启动按钮”。- 当调用
.toArray()时,它内部会调用 evaluateToArrayNode(根据有状态和无状态不同处理),进而调用evaluate方法。这个evaluate方法是整个流水线的总开关。
只有终端操作才能启动数据流。没有终端操作,Stream 流水线就是一个永远不会被执行的静态结构。
第三幕:组装处理器链(Sink Chaining)
这是最精妙的一步,发生在 evaluate 方法内部。
evaluate方法会从流水线的最后一个阶段开始,反向遍历整个链条。- 它对每个阶段调用
opWrapSink(flags, downstreamSink)方法。 - 这个方法的作用是,把下游(后一个操作)的
Sink(处理器)作为输入,用自己这个阶段的逻辑包装一下,生成一个新的Sink并返回。
我们以 filter(f).map(m).toArray() 为例:
toArray首先创建了一个最终的Sink,这个Sink就是一个Node.Builder(比如FixedNodeBuilder),它的accept方法就是把元素加入内部数组。- 然后轮到
map阶段,它调用opWrapSink,把Node.Builder这个Sink包装成一个新的Sink(我们称之为MappingSink)。MappingSink的accept方法会先对元素执行m.apply(),然后把结果传给它内部包裹的Node.Builder。 - 最后轮到
filter阶段,它也调用opWrapSink,把MappingSink包装成一个新的Sink(我们称之为FilteringSink)。FilteringSink的accept方法会先用f.test()判断元素,只有通过了,才会把原始元素传给它内部包裹的MappingSink。
这个过程最终形成了一个“俄罗斯套娃”式的 Sink 链:FilteringSink(MappingSink(Node.Builder))。这个最终的、最外层的 Sink 就是即将处理所有数据的“总处理器”。
第四幕:数据流动(Spliterator 驱动)
evaluate方法(调用的子方法)拿到了最终的Sink链(FilteringSink)和源头的Spliterator。- 它执行一个核心操作:
sourceSpliterator.forEachRemaining(sinkChain)。 forEachRemaining会遍历源Spliterator中的每一个元素,并把元素喂给Sink链的入口。
一个元素的旅程:
"apple"从list中取出,被喂给FilteringSink。FilteringSink.accept("apple")->predicate.test("apple")-> true -> 调用下游MappingSink.accept("apple")。MappingSink.accept("apple")->mapper.apply("apple")-> 得到"APPLE"-> 调用下游Node.Builder.accept("APPLE")。Node.Builder.accept("APPLE")->array[curSize++] = "APPLE"。(正如你所指出的!)"cat"从list中取出,被喂给FilteringSink。FilteringSink.accept("cat")->predicate.test("cat")-> false -> 方法直接返回,处理链中断。"cat"永远不会到达MappingSink和Node.Builder。
总结
极致的性能:操作融合 (Operation Fusion) 这是对描述的流程最重要的补充。整个过程不是
filter遍历一遍生成一个新集合,然后map再遍历一遍生成另一个新集合。而是,每个元素只被遍历一次,一次性地流过所有中间操作的逻辑(对于无状态操作,每个OP其实只是函数调用,没有产生中间集合)。这避免了创建任何中间集合的开销,极大地提升了性能和降低了内存占用。单一职责原则的典范
Spliterator只负责数据的分割和遍历。AbstractPipeline的各个阶段只负责构建流水线和定义opWrapSink的包装逻辑。Sink只负责处理单个元素并传递给下游。TerminalOp只负责启动和协调整个过程(toArray没有专门的TerminalOp,通过方法调用处理)。 每个组件的职责都非常清晰。
优雅的扩展性 这个模型可以非常自然地扩展到并行流。只需将源头的
Spliterator通过trySplit()分割成多个,然后让多个线程分别用同一套Sink链逻辑去处理自己的数据块,最后由终端操作负责将多个线程产生的部分结果(多个Node)合并起来即可。
Stream API 的强大之处不仅在于链式调用的简洁语法,更在于其内部通过延迟计算、操作融合和清晰的职责划分所带来的极致性能和优雅架构。nin FixedNodeBuilder.accept 正是这个高效数据流的最后一站。
核心接口和类
BaseStream<T, S extends BaseStream<T, S>>:- 这是一个基础接口,定义了所有流类型(
Stream,IntStream,LongStream,DoubleStream)共有的基本操作,如iterator(),spliterator(),isParallel(),sequential(),parallel(),onClose(),close()。 - 它是一个泛型接口,
T代表流中元素的类型,S代表具体的流类型(例如Stream<String>中的S就是Stream<String>)。
- 这是一个基础接口,定义了所有流类型(
Stream<T>:- 继承自
BaseStream<T, Stream<T>>。 - 定义了针对对象引用类型元素的流操作,例如
map(),filter(),flatMap(),collect(),reduce()等。 - 提供了一些静态方法。
- 继承自
IntStream,LongStream,DoubleStream:- 分别继承自
BaseStream<Integer, IntStream>,BaseStream<Long, LongStream>,BaseStream<Double, DoubleStream>。 - 它们是针对原始数据类型
int,long,double的特化流,提供了针对这些类型的特定操作(例如sum(),average())以及避免自动装箱/拆箱的性能优势。 - 它们也定义了各自的
mapToObj(),mapToXxx()(例如IntStream.mapToLong()) 等转换方法。
- 分别继承自
Spliterator<T>(位于java.util包):- 虽然不在
java.util.stream包下,但它是 Stream API 实现的基石。 Spliterator(Splitable Iterator,可分割迭代器) 用于遍历和分割源数据。它支持并行处理,因为它可以将数据源有效地分割成多个部分,供不同的线程处理。- Stream 的源(如集合、数组)都会提供一个
Spliterator。
- 虽然不在
PipelineHelper<P_OUT>:- 这是一个抽象类,封装了执行流管道阶段的逻辑。
- 它知道如何将操作应用于
Spliterator,并处理顺序和并行执行的细节。 - 每个流操作(如
map,filter)在内部通常会对应一个PipelineHelper的实现,用于构建和执行流管道。
AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>:- 这是所有流管道实现类的抽象基类,它实现了
PipelineHelper和相应的BaseStream接口。 - 它管理着流的源、上游阶段 (source stage)、流的特性 (stream flags,如
ORDERED,DISTINCT) 以及并行执行的深度。 - 具体的流实现(如
ReferencePipeline,IntPipeline)都继承自这个类。
- 这是所有流管道实现类的抽象基类,它实现了
ReferencePipeline<P_IN, P_OUT>:AbstractPipeline的一个具体实现,用于处理对象引用类型的流 (Stream<T>)。- 它有内部类(也是它的子类,由此也是stream,形成链式调用)如
Head(表示流的源头)、StatelessOp(无状态中间操作如map,filter) 和StatefulOp(有状态中间操作如sorted,distinct)。
IntPipeline,LongPipeline,DoublePipeline:- 类似于
ReferencePipeline,但分别用于处理IntStream,LongStream,DoubleStream。
- 类似于
TerminalOp<E_IN, R>:- 表示流管道中的终端操作。它定义了如何评估流并产生最终结果。
- 例如,
count(),forEach(),reduce(),collect()等操作都有对应的TerminalOp实现。
Sink<T>:- 这是一个接口,代表流管道中一个阶段的消费者。它定义了接受元素 (
accept())、开始 (begin()) 和结束 (end()) 信号的方法,以及是否可以取消 (cancellationRequested())。 - 中间操作通常会创建一个
Sink链,每个Sink包装下一个阶段的Sink。当元素从源流出时,它会依次通过这个链。 Sink.ChainedReference<T, E_OUT>是Sink的一个常见实现,用于链接处理对象引用的操作。类似地,也有针对原始类型的Sink.ChainedInt等。
- 这是一个接口,代表流管道中一个阶段的消费者。它定义了接受元素 (
Collector<T, A, R>:- 用于执行可变聚合操作(如将流元素收集到
List、Set或Map中,或者计算总和、平均值等)。 Collectors(注意末尾的 's') 是一个实用工具类,提供了大量预定义的Collector实现。
- 用于执行可变聚合操作(如将流元素收集到
AbstractTask<P_IN, P_OUT, R, K extends AbstractTask<P_IN, P_OUT, R, K>>:- 这是 Stream API 中用于并行处理的 Fork/Join 任务的抽象基类。
- 它继承自
java.util.concurrent.CountedCompleter。 - 当一个流管道以并行模式执行时,数据源的
Spliterator会被分割,每个分割出的部分会由一个AbstractTask的子类来处理。 AbstractTask管理任务的分割逻辑、子任务的跟踪以及中间结果的合并。- 它的核心方法是
compute(),该方法决定是直接处理当前任务的数据块(如果足够小,即叶子节点任务),还是将其进一步分割成子任务。 - 子类需要实现
doLeaf()(处理叶子节点) 和makeChild()(创建子任务),并可能重写onCompletion()(合并子任务结果)。 LEAF_TARGET和suggestTargetSize()等方法用于确定任务分割的粒度。
各种
*Task类 (例如ForEachTask,ReduceTask,FindTask,CollectTask等):- 这些是
AbstractTask的具体子类,分别对应不同的终端操作或有状态的并行操作。 - 它们实现了特定操作在并行环境下的计算和结果合并逻辑。
- 这些是
StreamSupport:- 一个实用工具类,提供了基于
Spliterator或Supplier创建各种流(Stream,IntStream等)的静态方法。 - 例如,
Collection.stream()内部就可能通过StreamSupport.stream(collection.spliterator(), false)来创建流。
- 一个实用工具类,提供了基于
Streams:- 一个包级私有的实用工具类,包含了一些 Stream 实现内部使用的辅助方法和内部类,例如
ConcatSpliterator(用于Stream.concat()) 和StreamBuilderImpl(用于Stream.builder())。
- 一个包级私有的实用工具类,包含了一些 Stream 实现内部使用的辅助方法和内部类,例如
关系图谱(简化版)
为了更清晰地展示它们的关系,我们可以想象一个简化的依赖和继承关系:
mermaid
graph TDsubgraph java.utilSpliteratorendsubgraph java.util.concurrentForkJoinPoolCountedCompleterendsubgraph "java.util.stream (Core)"direction LRsubgraph "Stream Creation & Support"StreamSupportCollectorsStreamsendsubgraph "Stream Pipeline"BaseStreamStream["Stream / IntStream / LongStream / DoubleStream"] --> BaseStreamAbstractPipeline["AbstractPipeline (Implements BaseStream, Uses PipelineHelper)"]ReferencePipeline["Specific Pipelines (e.g., ReferencePipeline)"] --> AbstractPipelineendsubgraph "Pipeline Operations"SinkTerminalOp["TerminalOp (e.g., forEach, reduce)"]endsubgraph "Parallel Execution"AbstractTask["AbstractTask (Extends CountedCompleter)"]ForEachTask["Specific Tasks (e.g., ForEachTask)"] --> AbstractTaskendend%% --- Key Relationships --- Spliterator -- "Used by for data source" --> AbstractPipelineSpliterator -- "Used by for data source" --> StreamSupportAbstractPipeline -- "Creates/Uses for processing" --> SinkAbstractPipeline -- "Initiates" --> TerminalOpAbstractPipeline -- "For Parallel Processing" --> AbstractTaskTerminalOp -- "For Parallel Processing" --> AbstractTaskForkJoinPool -- "Executes" --> AbstractTaskCountedCompleter -- "Base for" --> AbstractTask 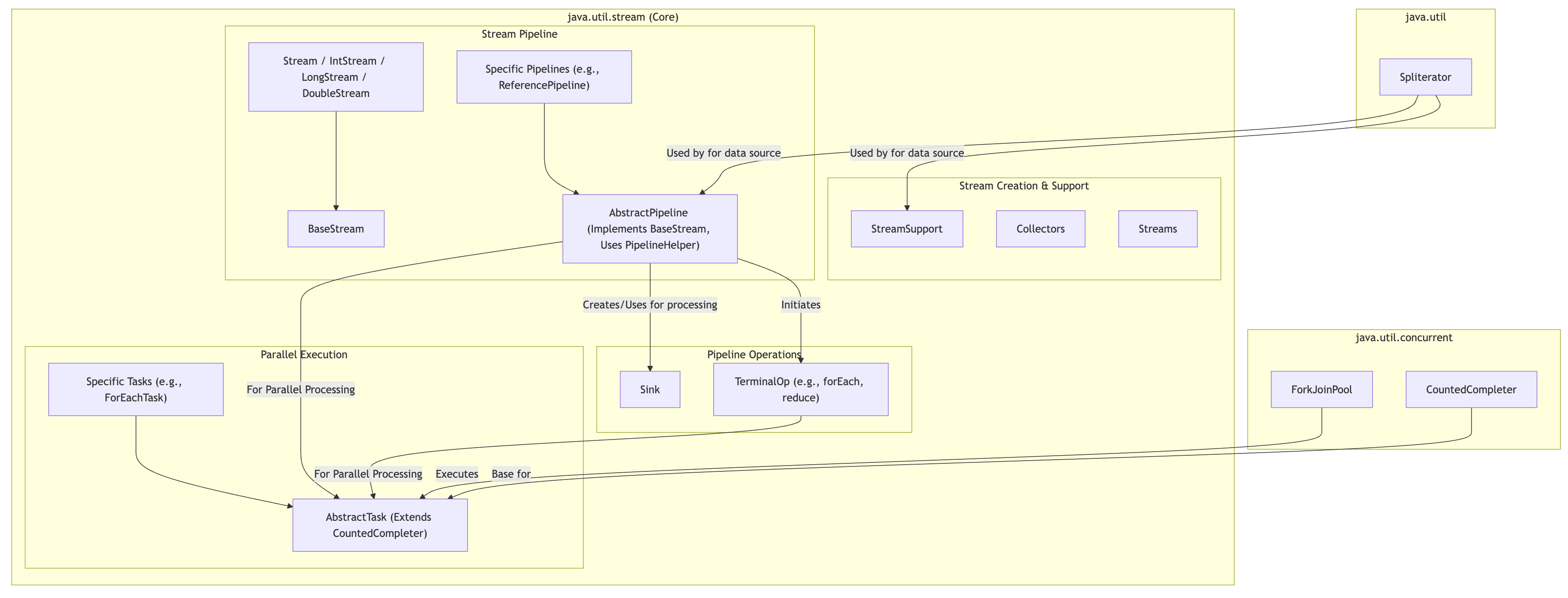
解释:
- 流的创建: 通常通过集合的
stream()方法、Arrays.stream()、Stream.of(),Stream.generate(),Stream.iterate()或StreamSupport类来创建。这些方法最终会构造一个*Pipeline对象(如ReferencePipeline),并关联一个源Spliterator。 - 中间操作: 调用如
map(),filter()等中间操作时,会在当前的*Pipeline对象上附加一个新的操作阶段,形成一个*Pipeline链。每个阶段内部会创建一个Sink来处理从上一个阶段传递过来的元素,并将处理结果传递给下一个阶段的Sink。 - 终端操作: 当调用终端操作(如
collect(),forEach(),reduce())时,会触发整个流管道的执行。- 顺序执行:
TerminalOp会驱动数据从源Spliterator流经Sink链,并最终计算出结果。 - 并行执行:
- 终端操作会创建一个顶层的
AbstractTask(例如ReduceTask)。 - 这个顶层任务的
compute()方法会被调用(通常在ForkJoinPool.commonPool()中)。 compute()方法会检查当前任务持有的Spliterator的大小。如果数据量较大且可以分割 (trySplit()成功),它会创建子任务 (makeChild()),并将其中一个子任务fork()出去(提交给ForkJoinPool执行),然后当前任务递归处理另一半。- 这个过程会持续进行,直到任务的数据块足够小(达到
targetSize),此时任务成为叶子节点,并调用doLeaf()方法处理其数据块。 - 当子任务完成时,
onCompletion()方法会被调用,用于合并子任务的结果。CountedCompleter机制确保了父任务在其所有子任务完成后才继续执行onCompletion。 - 最终,顶层任务的结果就是整个并行流操作的结果。
- 终端操作会创建一个顶层的
- 顺序执行:
PipelineHelper的作用: 在整个过程中,PipelineHelper负责协调操作的执行,无论是顺序的还是并行的。它知道如何包装Sink,如何结合Spliterator进行遍历,以及如何为并行执行创建和协调AbstractTask。
关键组件及其作用
Spliterator: 数据的直接来源,负责提供元素和支持可能的并行分割。- Pipeline Operation Classes (OPs) (如
ReferencePipeline.Head,*.StatelessOp):- 代表 Stream 中的各个操作阶段(源、中间操作)。
- 它们是构建 Stream 管道“蓝图”的组件。
- 它们不直接处理每个数据元素。
- 它们的核心职责之一是在终端操作触发时,通过
opWrapSink()方法创建并连接相应的Sink实例链。
Sink(及其子接口和实现类如ChainedReference):- 实际执行数据处理的“工人”。
- 每个
Sink实例封装了一个特定阶段的操作逻辑(如过滤、映射、聚合)。 - 它们通过
downstream引用链接起来,形成数据处理链。 - 遵循
begin() -> accept()* -> end()的生命周期。
StreamOpFlag: (我们之前也提到过) 这些标志描述了流和操作的特性(如SIZED,SORTED,DISTINCT,SHORT_CIRCUIT),它们可以影响Sink的行为和优化。例如,max()不是短路操作,所以cancellationRequested()在这个例子中不那么关键,但对于findFirst()这样的操作就非常重要。
流程图概览:
构建阶段 (声明式):
[Spliterator]->[Head OP]->[Filter OP]->[MapToInt OP]执行阶段 (终端操作
max()触发):- Sink 链构建 (由 OPs 完成, 从尾到头):
maxTerminalSink<--mapToIntProcessingSink(包装maxTerminalSink) <--filterProcessingSink(包装mapToIntProcessingSink) - 数据流动 (由 Head OP 驱动, 从头到尾):
Spliterator--元素-->filterProcessingSink--过滤后元素-->mapToIntProcessingSink--转换后int-->maxTerminalSink-->max()结果
- Sink 链构建 (由 OPs 完成, 从尾到头):
这个例子 清晰地展示了 Stream API 如何将操作的声明(Pipeline OPs)与操作的执行(Sinks)分离开来,从而实现了延迟执行和灵活的组合。每个 "OP" 知道如何为自己代表的操作创建一个 Sink,并将这个 Sink 连接到下游的 Sink。
推荐的学习路径
阶段一:理解核心API和基本概念
用户接口 (
Stream,IntStream,LongStream,DoubleStream):- 目的: 熟悉最终用户直接使用的接口,理解各种流操作(中间操作和终端操作)的语义和用途。
- 源码:
java.util.stream.Streamjava.util.stream.IntStreamjava.util.stream.LongStreamjava.util.stream.DoubleStreamjava.util.stream.BaseStream(它们共同的父接口)
- 关注点:
- 每个接口定义了哪些方法?
- 中间操作 (e.g.,
filter,map,flatMap,sorted,distinct,limit,skip,peek) 的特性(无状态/有状态,短路)。 - 终端操作 (e.g.,
forEach,toArray,reduce,collect,min,max,count,anyMatch,allMatch,noneMatch,findFirst,findAny) 的特性。 - 静态工厂方法 (e.g.,
Stream.of(),Stream.iterate(),Stream.generate(),Stream.concat(),Stream.builder())。
Spliterator接口 (java.util.Spliterator):- 目的: 理解 Stream API 数据源的抽象。
Spliterator是实现惰性求值和并行处理的关键。 - 源码:
java.util.Spliterator及其针对原始类型的子接口 (Spliterator.OfInt,Spliterator.OfLong,Spliterator.OfDouble)。 - 关注点:
tryAdvance(Consumer): 如何处理单个元素。forEachRemaining(Consumer): 如何处理剩余所有元素。trySplit(): 如何将数据源分割以支持并行处理。这是并行流的核心。estimateSize(): 获取大小估计。characteristics():Spliterator的特性 (e.g.,ORDERED,SIZED,SUBSIZED,DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT) 及其对流操作优化的影响。
- 目的: 理解 Stream API 数据源的抽象。
函数式接口 (
java.util.function):- 目的: Stream API 大量使用函数式接口作为操作参数。
- 源码:
Predicate,Function,Consumer,Supplier,UnaryOperator,BinaryOperator, 以及它们的原始类型特化版本。 - 关注点: 理解它们的抽象方法和在 Stream 中的应用场景。
阶段二:深入流的创建和管道构建
StreamSupport:- 目的: 理解如何从
Spliterator或Supplier<Spliterator>创建流。这是连接数据源和流管道的桥梁,也是许多集合类(如Collection.stream())内部创建流的起点。 - 源码:
java.util.stream.StreamSupport - 关注点:
stream(Spliterator<T> spliterator, boolean parallel)stream(Supplier<? extends Spliterator<T>> supplier, int characteristics, boolean parallel)- 以及它们为
IntStream,LongStream,DoubleStream提供的类似方法。 - 注意它们是如何实例化
ReferencePipeline.Head或相应原始类型管道的Head类的。
- 目的: 理解如何从
AbstractPipeline和具体管道实现:- 目的: 理解流管道的内部表示和操作链的构建。
- 源码:
java.util.stream.AbstractPipeline(所有流管道实现的基类)java.util.stream.ReferencePipeline(用于Stream<T>)java.util.stream.IntPipeline,LongPipeline,DoublePipeline(用于原始类型流)
- 关注点:
- 管道阶段如何链接 (source stage, upstream stage)。
- 流标志 (
StreamOpFlag) 如何从Spliterator特性初始化并在管道中传播。 sourceSpliterator,sourceSupplier字段。opWrapSink方法的抽象概念(虽然具体实现在子类)。Head,StatelessOp,StatefulOp这些内部类是如何代表不同类型的管道阶段的。
Sink接口:- 目的: 理解元素如何在流管道的各个阶段之间传递和处理。
- 源码:
java.util.stream.Sink及其链式实现 (e.g.,Sink.ChainedReference,Sink.ChainedInt)。 - 关注点:
begin(long size): 开始处理前调用。accept(T t)/accept(int i): 接受并处理单个元素。end(): 所有元素处理完毕后调用。cancellationRequested(): 用于支持短路操作。- 中间操作(如
map,filter)通常会创建一个新的Sink实例,该实例包装(或称为“下游”)下一个阶段的Sink。
阶段三:理解终端操作和并行执行
TerminalOp接口:- 目的: 理解终端操作是如何触发流计算并产生结果的。
- 源码:
java.util.stream.TerminalOp - 关注点:
evaluateSequential(PipelineHelper<T> helper, Spliterator<P_IN> spliterator)evaluateParallel(PipelineHelper<T> helper, Spliterator<P_IN> spliterator)- 研究具体的终端操作实现类,例如:
java.util.stream.ForEachOps(实现了forEach,forEachOrdered)java.util.stream.ReduceOps(实现了reduce)java.util.stream.MatchOps(实现了anyMatch,allMatch,noneMatch)java.util.stream.FindOps(实现了findFirst,findAny)java.util.stream.CollectOps(实现了collect)
Collector接口和Collectors工具类:- 目的: 理解可变聚合操作是如何工作的。
- 源码:
java.util.stream.Collectorjava.util.stream.Collectors
- 关注点:
Collector接口的五个方法:supplier(),accumulator(),combiner(),finisher(),characteristics()。Collectors类中各种预定义收集器的实现,例如toList(),toSet(),toMap(),groupingBy(),joining()。
并行处理核心:
AbstractTask及其子类:- 目的: 这是 Stream 并行处理的核心,理解 Fork/Join 框架如何被用于并行化流操作。
- 源码:
java.util.stream.AbstractTask(Fork/Join 任务的基类,继承自CountedCompleter)- 各种具体的 Task 实现,如
ForEachTask,ReduceTask,SliceTask,FindTask,CollectTask等。
- 关注点:
compute(): 任务执行的核心逻辑,决定是进一步拆分还是执行叶子节点操作。makeChild(Spliterator<P_IN> spliterator): 创建子任务。doLeaf(): 叶子节点任务的具体处理逻辑。onCompletion(CountedCompleter<?> caller): 子任务完成时合并结果。targetSize和LEAF_TARGET: 控制任务拆分的粒度。- 与
Spliterator.trySplit()的交互。
有状态中间操作的实现:
- 目的: 理解像
distinct(),sorted(),limit(),skip()这样的有状态操作是如何实现的,尤其是在并行模式下。 - 源码:
java.util.stream.DistinctOpsjava.util.stream.SortedOpsjava.util.stream.SliceOps(用于limit和skip)
- 关注点:
- 它们通常需要缓冲元素。
- 并行实现可能更复杂,需要协调不同子任务的结果。例如,并行
sorted()可能涉及样本排序或归并。
- 目的: 理解像
阶段四:辅助和工具类
Streams(包级私有工具类):- 目的: 包含一些 Stream 实现内部使用的辅助方法和内部类。
- 源码:
java.util.stream.Streams - 关注点:
ConcatSpliterator,StreamBuilderImpl,composedClose等。
StreamOpFlag(枚举):- 目的: 理解流的各种特性(如
ORDERED,DISTINCT,SORTED,SIZED)是如何被编码、传播和用于优化的。 - 源码:
java.util.stream.StreamOpFlag
- 目的: 理解流的各种特性(如
学习建议
- 从简单到复杂: 先理解顺序流的执行,再深入并行流。先理解无状态操作,再学习有状态操作。
- 使用IDE: 利用 IDE 的“查找用法”、“跳转到定义/实现”、“调试”等功能,可以极大地帮助跟踪代码逻辑。
- 调试执行: 选择一个简单的 Stream 链 (例如
List.of(1,2,3).stream().map(i -> i * 2).filter(i -> i > 3).findFirst()),然后在关键的 JDK 方法(如StreamSupport.stream,ReferencePipeline.Head构造函数,AbstractPipeline.opWrapSink,Sink.accept,TerminalOp.evaluateSequential,AbstractTask.compute等)打上断点,单步调试,观察调用栈和变量状态。 - 阅读 Javadoc: JDK 源码中的 Javadoc 通常包含重要的设计思路和实现细节。
- 画图: 对于复杂的流程,如 Sink 链的构建或并行任务的拆分合并,画图可以帮助理解。
- 带着问题学习: 例如,“
map操作是如何实现的?”、“并行reduce是如何合并结果的?”、“distinct在并行时如何保证正确性?”