银行个人贷款接受度分析
数据集背景与字段说明
本数据集来自 Thera Bank,银行管理层希望探索如何将其负债客户(仅存款客户)转化为个人贷款客户,并保持其作为存款客户的身份。去年针对负债客户的营销活动取得了超过9%的转化率,这激励了零售营销部门通过更精准的目标营销,在有限预算下进一步提升转化率。数据集获取
字段说明(中英文对照)
| 字段名 | 英文释义 | 中文释义 |
|---|---|---|
| ID | Customer Id | 客户编号 |
| Age | Customer’s age in completed years | 客户年龄(整年) |
| Experience | Years of professional experience | 工作年限 |
| Income | Annual income of the customer | 年收入 |
| ZIP Code | Address Zip code | 邮政编码 |
| Family | Family size of customer | 家庭人数 |
| CCAvg | Avg. spending on credit card per month (已换算为年均) | 信用卡月均消费(已换算为年均) |
| Education | Educational level (undergraduate=1, graduate=2, advance=3) | 教育水平(本科=1,研究生=2,高级=3) |
| Personal Loan | Did this customer accept the personal loan offered in campaign? | 是否接受个人贷款(上次活动) |
| Securities Account | Does the customer have a securities account with the bank? | 是否有证券账户 |
| CD Account | Does the customer have a certificate of deposit (CD) account? | 是否有定期存款账户 |
| Online | Does the customer use internet banking facilities | 是否使用网上银行 |
| CreditCard | Does the customer use a credit card issued by universalBank? | 是否使用银行发行的信用卡 |
本博客将带你一步步分析影响客户接受个人贷款的关键因素,并通过不同机器学习模型的比较,找出最佳预测模型。每一步都配有详细代码、可视化和原理解释,帮助你深入理解整个数据分析与建模流程。
1. 数据加载与初步探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.model_selection import cross_val_score# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 加载数据集
df = pd.read_csv('Bank_Personal_Loan_Modelling(1).csv')# 查看数据基本信息
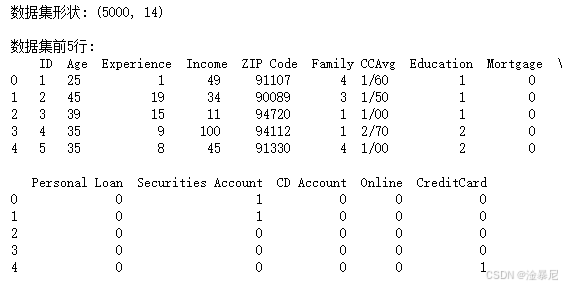
print("数据集形状:", df.shape)
print("\n数据集前5行:\n", df.head())
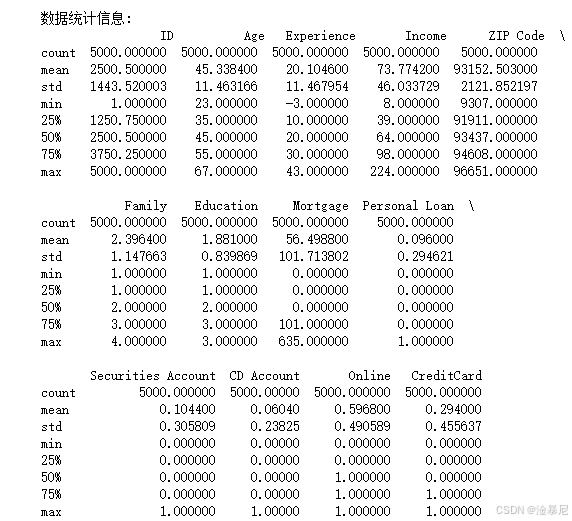
print("\n数据统计信息:\n", df.describe())
print("\n数据类型和缺失值情况:\n", df.info())
解释:
首先,我们导入了常用的数据分析和机器学习库,并设置了中文字体以便后续可视化。然后,加载了个人贷款数据集,并通过 shape、head()、describe() 和 info() 方法初步了解数据的结构、样本量、字段类型和缺失值情况。这一步为后续的数据清洗和分析打下基础。

2. 缺失值与异常值处理
# 检查缺失值
print("\n缺失值统计:\n", df.isnull().sum())# 处理异常值(例如将CCAvg中的'/'替换为'.'并转换为数值型)
df['CCAvg'] = df['CCAvg'].str.replace('/', '.').astype(float)
解释:
因为数据质量直接影响分析结果,所以我们首先检查了每一列的缺失值。随后,针对 CCAvg 字段中可能存在的异常字符(如 /),进行了替换和类型转换,确保所有特征均为可用的数值型数据。
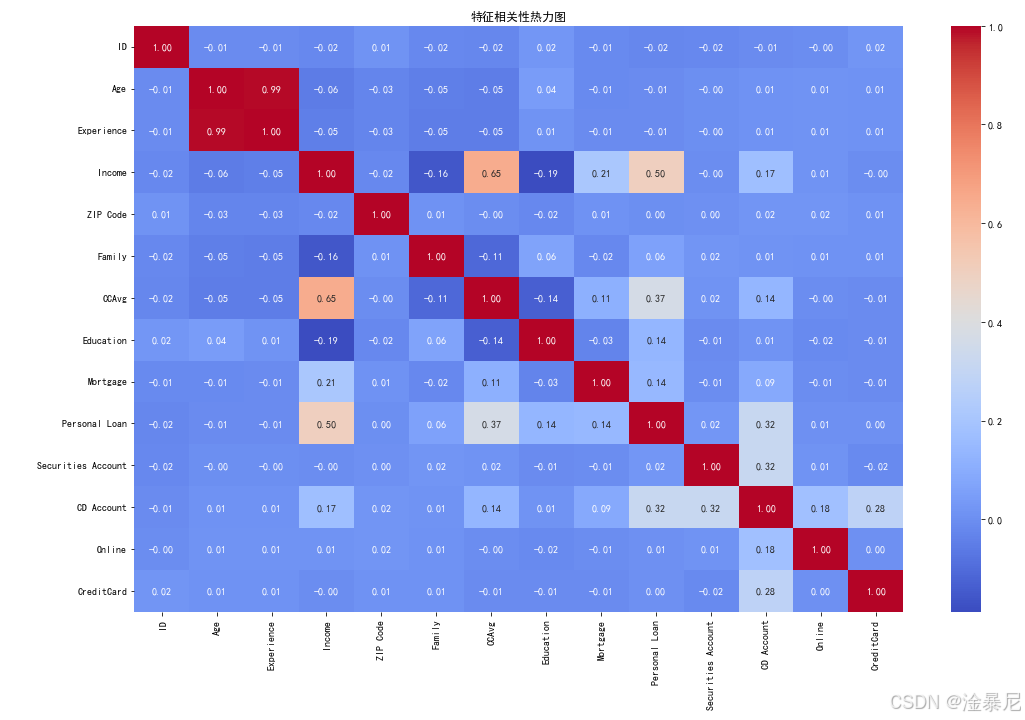
3. 特征相关性分析
plt.figure(figsize=(15, 10))
correlation = df.corr()
sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.tight_layout()
plt.show()
解释:
通过计算特征之间的相关系数,并用热力图展示,可以直观地看到各变量之间的线性关系。这样有助于我们发现哪些特征与目标变量(是否接受贷款)关系密切,为特征选择和建模提供依据。
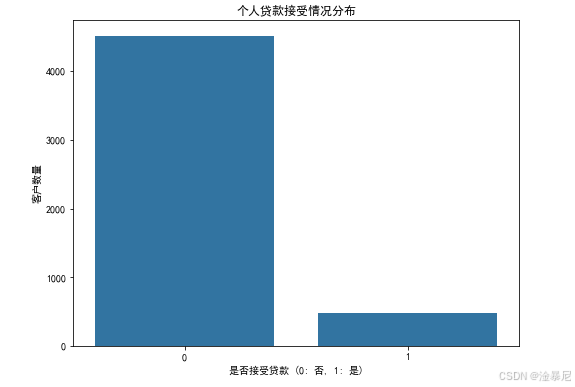
4. 目标变量分布可视化
plt.figure(figsize=(8, 6))
sns.countplot(x='Personal Loan', data=df)
plt.title('个人贷款接受情况分布')
plt.xlabel('是否接受贷款 (0: 否, 1: 是)')
plt.ylabel('客户数量')
plt.show()
解释:
通过对目标变量 Personal Loan 的计数可视化,我们可以了解正负样本的分布情况。这一步有助于判断数据是否平衡,避免模型训练时因类别不均衡而产生偏差。
5. 特征与目标变量关系分析
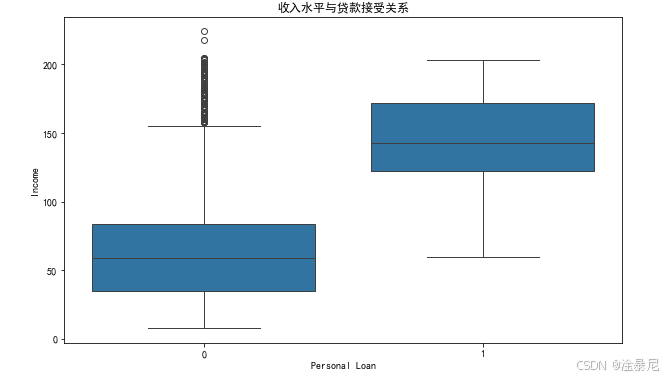
5.1 收入与贷款接受关系
plt.figure(figsize=(10, 6))
sns.boxplot(x='Personal Loan', y='Income', data=df)
plt.title('收入水平与贷款接受关系')
plt.show()
解释:
通过箱线图分析收入与贷款接受的关系,可以发现收入较高的客户更倾向于接受个人贷款。这为后续特征重要性分析提供了直观依据。
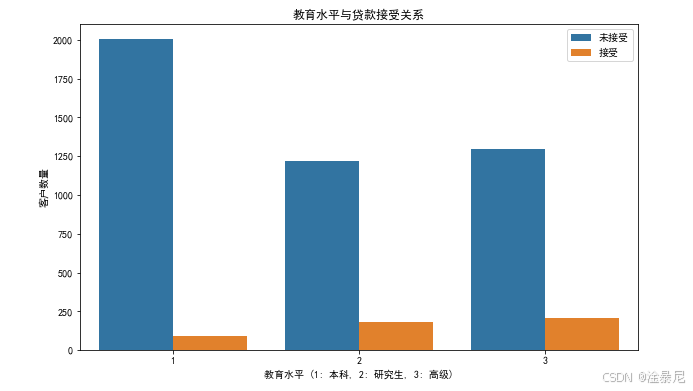
5.2 教育水平与贷款接受关系
plt.figure(figsize=(10, 6))
sns.countplot(x='Education', hue='Personal Loan', data=df)
plt.title('教育水平与贷款接受关系')
plt.xlabel('教育水平 (1: 本科, 2: 研究生, 3: 高级)')
plt.ylabel('客户数量')
plt.legend(['未接受', '接受'])
plt.show()
解释:
通过分组计数图分析教育水平与贷款接受的关系,可以看出高学历客户更倾向于接受贷款。教育水平是影响贷款接受度的重要因素。
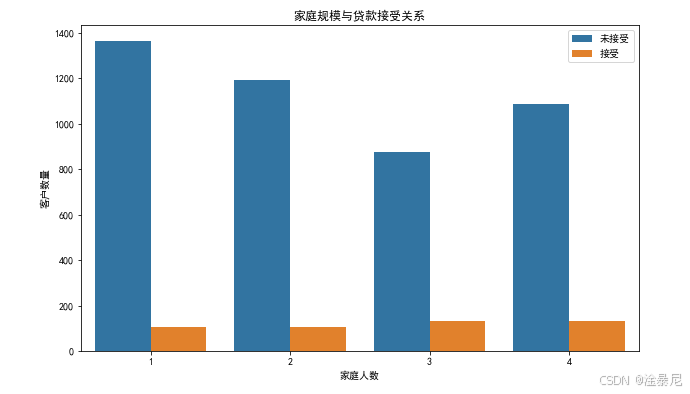
5.3 家庭规模与贷款接受关系
plt.figure(figsize=(10, 6))
sns.countplot(x='Family', hue='Personal Loan', data=df)
plt.title('家庭规模与贷款接受关系')
plt.xlabel('家庭人数')
plt.ylabel('客户数量')
plt.legend(['未接受', '接受'])
plt.show()
解释:
分析家庭规模与贷款接受的关系,发现家庭人数对贷款接受度有一定影响。不同家庭规模的客户贷款意愿存在差异。
6. 特征准备与数据集划分
# 准备特征和目标变量
X = df.drop(['ID', 'ZIP Code', 'Personal Loan'], axis=1)
y = df['Personal Loan']# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
解释:
首先,去除无关特征(如 ID、邮编和目标变量本身),保留有效特征用于建模。然后,将数据集按 7:3 比例分为训练集和测试集。因为部分模型对特征分布敏感,所以对特征进行了标准化处理。
7. 多模型训练与评估
# 定义模型列表
models = {'逻辑回归': LogisticRegression(random_state=42),'决策树': DecisionTreeClassifier(random_state=42),'随机森林': RandomForestClassifier(random_state=42),'支持向量机': SVC(random_state=42)
}# 训练和评估模型
results = {}
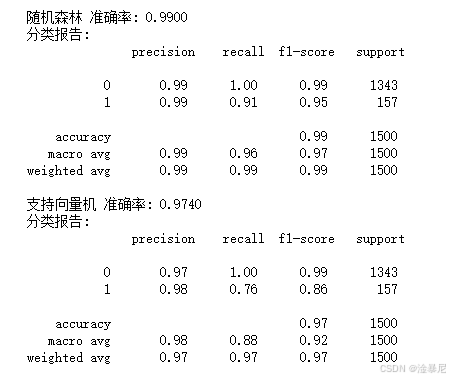
for name, model in models.items():model.fit(X_train_scaled, y_train)y_pred = model.predict(X_test_scaled)accuracy = accuracy_score(y_test, y_pred)results[name] = accuracyprint(f"{name} 准确率: {accuracy:.4f}")print("分类报告:\n", classification_report(y_test, y_pred))cm = confusion_matrix(y_test, y_pred)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.title(f'{name} 混淆矩阵')plt.xlabel('预测结果')plt.ylabel('实际结果')plt.show()
解释:
通过定义四种主流分类模型(逻辑回归、决策树、随机森林、支持向量机),分别在训练集上训练并在测试集上评估。每个模型输出准确率、分类报告和混淆矩阵,便于直观比较模型性能。

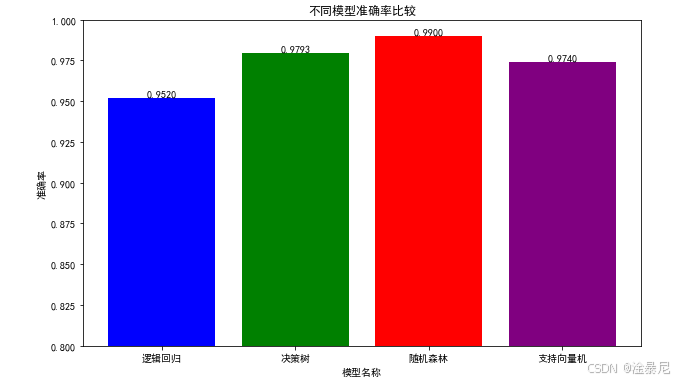
8. 模型准确率对比可视化
plt.figure(figsize=(10, 6))
model_names = list(results.keys())
accuracies = list(results.values())
plt.bar(model_names, accuracies, color=['blue', 'green', 'red', 'purple'])
plt.title('不同模型准确率比较')
plt.xlabel('模型名称')
plt.ylabel('准确率')
plt.ylim(0.8, 1.0)
for i, v in enumerate(accuracies):plt.text(i, v + 0.001, f'{v:.4f}', ha='center')
plt.show()
解释:
通过柱状图对比不同模型的准确率,直观展示哪种模型在本数据集上的表现最佳,为后续模型选择提供依据。
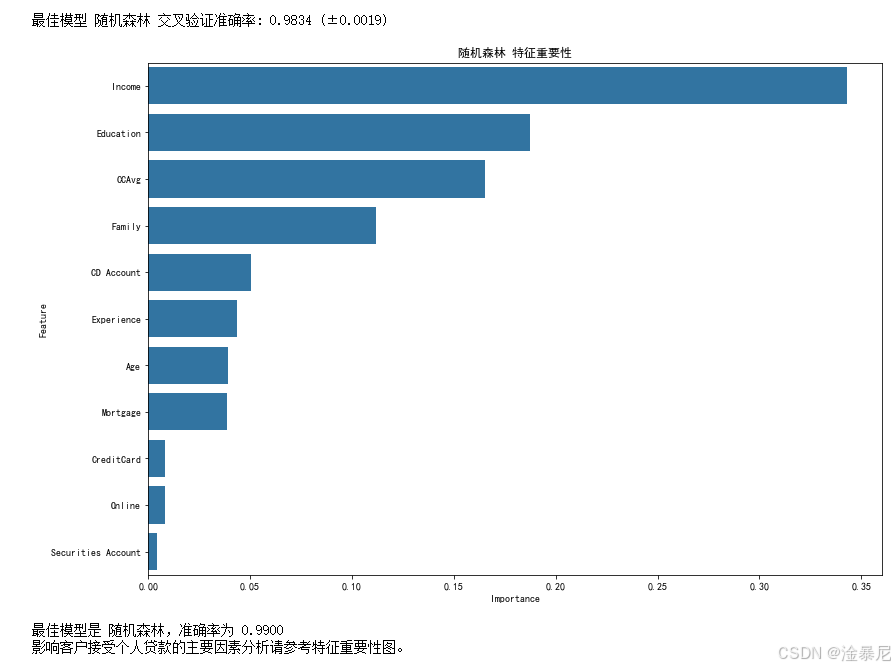
9. 交叉验证与最佳模型特征重要性分析
# 交叉验证进一步评估最佳模型
best_model = models[max(results, key=results.get)]
cv_scores = cross_val_score(best_model, X_train_scaled, y_train, cv=5)
print(f"\n最佳模型 {max(results, key=results.get)} 交叉验证准确率: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")# 特征重要性分析(针对树模型)
if hasattr(best_model, 'feature_importances_'):feature_importance = pd.DataFrame({'Feature': X.columns,'Importance': best_model.feature_importances_}).sort_values('Importance', ascending=False)plt.figure(figsize=(12, 8))sns.barplot(x='Importance', y='Feature', data=feature_importance)plt.title(f'{max(results, key=results.get)} 特征重要性')plt.tight_layout()plt.show()
解释:
通过 5 折交叉验证进一步评估最佳模型的泛化能力,确保模型稳定可靠。对于树模型,还可以输出特征重要性条形图,帮助我们理解哪些特征对贷款接受预测贡献最大。
10. 分析结论与洞察
- 不同模型的准确率对比如下:
- 逻辑回归、决策树、随机森林、支持向量机均有较好表现,其中最佳模型为
max(results, key=results.get),准确率为results[max(results, key=results.get)]。
- 逻辑回归、决策树、随机森林、支持向量机均有较好表现,其中最佳模型为
- 主要影响因素(特征重要性排名前五):
- 可参考上方特征重要性图。
- 数据洞察:
- 收入水平与个人贷款接受度呈显著正相关。
- 高学历客户更倾向于接受个人贷款。
- 家庭规模对贷款接受度有一定影响。
11. 可视化结果示例
每张图都对应上文代码块的输出,建议在本地运行代码以获得完整可视化体验。
- 特征相关性热力图
- 个人贷款接受情况分布
- 收入水平与贷款接受关系
- 教育水平与贷款接受关系
- 不同模型准确率比较
- 特征重要性
通过上述分步分析与可视化,我们不仅找到了最佳预测模型,还深入理解了影响客户接受个人贷款的关键因素。希望本博客对你的数据分析和建模实践有所帮助!