【AI绘画】Stable Diffusion 全面指南:安装、版本对比、功能解析与高级应用
引言:Stable Diffusion 概述
在人工智能图像生成领域,商业工具如Midjourney凭借其集成化服务与高质量输出占据市场,而Stable Diffusion(简称SD)则以开源特性构建了差异化优势。与商业工具依赖云端资源、受限于订阅费用及使用配额不同,SD采用完全免费开源的开发模式,允许用户本地部署并规避资源限制,这一特性为个人创作者与专业团队提供了灵活定制与成本优化的双重价值。作为基于深度学习的扩散模型(diffusion model),SD的核心功能包括通过文本描述(Prompt)生成逼真图像、艺术风格作品及对现有图像进行修改,其源代码与模型权重均在GitHub公开,支持开发者与用户进行二次开发,推动生成式人工智能技术的普及应用。
自2022年由Stability AI、慕尼黑大学机器视觉学习组(CompVis)及Runway联合推出以来,SD经历了多代技术迭代:2022年发布的SD1.5奠定主流应用基础,2023年的SDXL版本提升细节呈现与风格多样性,2024年的SD3与Flux模型进一步优化精度与智能化水平。截至2025年,最新版本Stable Diffusion 3.5(SD3.5)实现了关键技术突破:作为多模态扩散变换器(MMDiT)模型,其在图像生成质量、排版准确性、复杂提示理解及资源效率方面均有显著改进,支持百万像素级输出与多模态输入,可精准生成色彩还原度高、细节丰富的视觉内容。此外,SD3.5首次开放免费商用授权,进一步拓展了商业项目的应用场景,成为连接创意与技术落地的重要工具。
SD的开源生态与技术演进为用户提供了从基础应用到高级定制的全流程支持。后续章节将围绕其安装部署指南、版本特性对比、核心功能解析及高级应用场景展开详细探讨,为不同需求的用户提供系统性技术参考。
Windows安装指南
系统要求与环境准备
在进行Stable Diffusion安装前,需明确设备的硬件与软件兼容性,以下从系统要求、设备自查及环境配置三方面进行说明。
一、系统与硬件要求
1. 操作系统
最低配置为Windows 10及以上版本;推荐使用Windows 10/11专业版以保障稳定性。若计划使用SD3.5版本,建议升级至Windows 11 23H2或更高版本;Mac设备需升级至macOS 15及以上。
2. 硬件配置
- CPU:无强制性最低要求,但推荐8代酷睿I5级别及以上处理器以提升运算效率。
- 内存:最低8GB,推荐16GB及以上,以支持模型加载与多任务处理。
- 显卡与显存:
- 最低配置:需Nvidia独立显卡,显存至少4GB(如GTX 1650);A卡或集成显卡仅支持CPU渲染,速度显著降低。
- 推荐配置:Nvidia RTX 2060(6GB显存)及以上型号(如RTX 3060、RTX 4060 8GB),显存8GB及以上;SD3.5版本对显存要求更高,Medium版需至少12GB,Large版需24GB及以上。
- 移动端设备需确认显卡是否支持CUDA(Nvidia)或Metal(Mac)框架。
- 磁盘空间:最低30GB可用空间,推荐使用固态硬盘(SSD)存放整合包及模型文件,以提升加载速度。
| 配置项 | 最低配置 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10+ | Windows 10/11专业版 或 Windows 11 23H2+ (SD3.5) |
| CPU | 无强制要求 | 8代酷睿I5级别及以上处理器 |
| 内存 | 8GB | 16GB及以上 |
| 显卡 | NVIDIA独立显卡(4GB显存) | RTX 2060(6GB显存)及以上型号 SD3.5要求: - Medium版:12GB显存 - Large版:24GB显存 |
| 显存 | 4GB (如GTX 1650) | 8GB及以上 (如RTX 3060/4060) |
| 磁盘空间 | 30GB | SSD固态硬盘30GB以上 |
二、设备兼容性自查
用户可通过Windows任务管理器查看GPU显存:打开任务管理器(快捷键Ctrl+Shift+Esc),切换至“性能”选项卡,选择“GPU”,在“专用GPU内存”处查看显存容量,确认是否满足对应版本的显存要求。
三、环境准备
1. Python环境配置
必须安装Python 3.10.6版本(官网:python.org/downloads),安装时需勾选“Add Python 3.10 to PATH”以配置环境变量;若已安装其他Python版本,需先卸载旧版本。
2. Git安装与配置
需安装Git工具(官网:https://git-scm.com/download,选择64位Windows安装包),安装时确保勾选“Add Git to PATH”以配置环境变量。
3. 其他注意事项
- 关闭360等安全软件及防火墙,避免拦截文件下载;
- Windows系统需解除Powershell执行策略限制:以管理员身份运行Powershell,执行命令“Set-ExecutionPolicy Unrestricted”并确认;
- Nvidia用户需确保显卡驱动支持CUDA,可通过NVIDIA官网下载对应驱动;
- 首次启动时将自动下载约10GB的VAE和CLIP模型文件,需确保系统盘(通常为C盘)有足够空间。
安装方法:整合包与手动部署
Stable Diffusion 的安装方法主要分为整合包安装与手动部署两种,二者适用于不同需求的用户群体。整合包安装(又称“懒人安装法”)适合新手用户,其核心优势在于简化依赖配置流程,通过预打包的环境和工具实现快速启动;手动部署则面向进阶用户,支持按需定制插件与环境,灵活性更高。以下从优缺点对比、分步教程及安全验证三方面展开说明。
整合包安装:新手友好的快速部署方案
整合包安装的核心优势在于“开箱即用”,无需手动配置依赖环境,且通常自带基础模型与优化插件。其优点包括:安装流程简化(解压后双击启动器即可)、自动更新依赖组件、集成常用插件(如xformers加速模块);缺点则表现为灵活性受限,可能集成冗余插件,第三方整合包还存在缺失关键组件或植入广告程序的风险。
推荐工具与分步教程:
主流整合包包括秋葉aaaki整合包(适合新手)和独立研究员-星空整合包(优化AMD/低配置设备)。以秋葉整合包为例,具体步骤如下:
- 下载与解压:从官方或可信渠道下载整合包,解压至无中文路径的磁盘(建议预留至少50GB空间)。
- 安装依赖:运行整合包内的“启动器运行依赖-dotnet-6.0.11.exe”,完成基础依赖配置。
- 启动与优化:双击“A启动器”,首次启动时系统自动更新组件;若显存≤8GB,可在启动器设置中添加“--medvram”参数优化内存占用;AMD用户需在高级选项中将生成引擎切换为A卡模式。
- 访问界面:启动成功后,通过浏览器访问默认地址“http://127.0.0.1:7860”进入WebUI。
手动部署:进阶用户的定制化方案
手动部署适合需深度定制插件或进行模型训练的用户,其优点为可按需选择插件、便于问题排查;缺点是需手动配置环境依赖与模型文件,对技术基础有一定要求。
分步教程:
-
环境准备:
- 安装Python 3.10.6(勾选“Add Python 3.10 to PATH”以配置环境变量)。
- 安装Git(官网下载64位版本,默认配置即可)。
- 解除Powershell安全锁(管理员模式运行Powershell,执行“Set-ExecutionPolicy RemoteSigned”)。
-
代码克隆与配置:
- 在无中文路径的文件夹中打开命令行,执行克隆命令:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git。 - 进入克隆目录,编辑“webui-user.bat”文件,添加优化参数:
set COMMANDLINE_ARGS=--xformers(启用xformers加速);若显存≤8GB,追加“--medvram”。
- 在无中文路径的文件夹中打开命令行,执行克隆命令:
-
启动与模型部署:
- 运行“webui-user.bat”,系统自动下载依赖组件并启动服务。
- 从Hugging Face等官方渠道下载基础模型(如SD 1.5的“v1-5-pruned-emaonly.safetensors”),放入“stable-diffusion-webui/models/Stable-diffusion”目录。
-
访问界面:启动成功后,通过浏览器访问“http://127.0.0.1:7860”进入WebUI。
模型文件的合法性与安全验证
为避免恶意文件风险,需对下载的安装包与模型文件进行安全校验:
- 官方渠道优先:推荐从Stability AI官网(stability.ai)下载安装包,检查数字签名(证书颁发者为“Stability AI Ltd.”);第三方平台选择带蓝色认证徽标的仓库(如GitHub的AUTOMATIC1111项目)。
- SHA-256校验:官网提供压缩包的SHA-256哈希值(可在“下载校验”页面查询),通过工具计算本地文件哈希值并比对,确保文件未被篡改。
- 模型完整性:官网下载包包含完整模型库与安全校验文件,第三方整合包需确认无组件缺失(如SD 3.5需包含Large/Turbo模型及Clip文件)。
| 验证方法 | 适用场景 | 具体操作 | 验证目标 |
|---|---|---|---|
| 数字签名 | 官网安装包验证 | 检查证书颁发者为"Stability AI Ltd." | 文件来源合法性 |
| 哈希校验 | 第三方平台文件验证 | 计算SHA-256值并与官网"下载校验"页面比对 | 文件完整性 |
| 组件完整性 | 模型文件验证 | 确认SD 3.5包含Large/Turbo模型及Clip文件 | 关键组件完备性 |
| 仓库认证 | GitHub资源验证 | 认准蓝色认证徽标仓库 | 资源来源可靠性 |
通过上述方法,可有效降低恶意软件感染风险,确保安装环境的安全性与稳定性。
SD 3.5特殊安装步骤
Stable Diffusion 3.5(SD 3.5)因采用MMDiT架构及支持多模态输入,其安装流程与旧版本存在显著差异。核心区别在于需通过ComfyUI部署,且模型文件与文本编码器需分离存放。以下为具体安装步骤及优化方案:
一、环境准备与文件部署
-
ComfyUI安装
需使用最新版本ComfyUI以支持SD 3.5的技术特性。建议下载ComfyUI免安装版并更新至最新版本,无需复杂配置即可直接运行。 -
模型与文本编码器分离存放
- 基础模型:将SD 3.5模型文件(如sd3.5_large.safetensors或sd3.5_large_turbo.safetensors)放入ComfyUI/models/checkpoint目录。
- 文本编码器:SD 3.5的多模态输入依赖独立文本编码器,需将Clip模型(clip_g.safetensors、clip_l.safetensors)及T5XXL系列模型(如t5xxl_fp16.safetensors或t5xxl_fp8_e4m3fn.safetensors)存放于ComfyUI/models/clip目录。其中,T5XXL模型提供FP16(高精度)和FP8(低显存)两种版本,FP8量化模型(如t5xxl_fp8_e4m3fn_scaled.safetensors)适用于显存受限设备。
二、启动与工作流配置
-
启动ComfyUI
运行ComfyUI根目录下的一键启动脚本(run_nvidia_gpu.bat),脚本将自动配置环境并启动服务。启动成功后,通过浏览器访问本地地址http://127.0.0.1:8188即可进入操作界面. -
加载官方工作流
在ComfyUI界面中,拖入官方提供的SD 3.5工作流文件(如SD3.5L_Turbo_example_workflow.json),系统将自动加载模型及编码器配置。对于Large Turbo版本,需注意采样步数默认设为4步,CFG参数建议降低至1以匹配模型特性;Medium版本(参数量为Large版的30%)则可直接使用默认参数,显存占用更低。
三、显存优化方案
针对SD 3.5的高显存需求,可通过以下方式优化:
- 启动参数调整:在启动脚本中添加--medvram参数,减少显存占用。
- 量化模型应用:使用FP8量化的T5XXL模型(如t5xxl_fp8_e4m3fn_scaled.safetensors)及fp8_scaled工作流文件,实验数据表明可降低约40%显存占用。
- 模型版本选择:优先选用Medium或Large Turbo版本,其设计目标为平衡性能与显存消耗,适合中端硬件设备。
四、注意事项
- 环境依赖:安装过程需保持网络畅通,以确保实时下载依赖库;首次启动时,系统会进行硬件性能测试,未通过测试的设备可强制启用“基础模式”运行。
- 驱动兼容性:若提示显卡驱动不兼容,需前往NVIDIA或AMD官网更新至最新版驱动(建议NVIDIA驱动版本≥550.00,AMD驱动版本≥24.7.1)。
- 文件校验:模型加载失败多因文件路径错误或版本不匹配,建议从官方渠道获取模型文件,并核对存放目录是否符合ComfyUI规范。
版本区别与选择指南
经典版本对比:SD 1.5/SDXL/SD3
版本核心维度对比表
| 维度 | SD 1.5 | SDXL | SD3 |
|---|---|---|---|
| 硬件门槛 | 4GB显存即可运行,兼容低配设备(如6GB显存显卡) | 需8GB显存以流畅运行,推荐高性能显卡(如RTX 40系) | 硬件要求更高,具体配置未明确,但多模态功能对计算资源需求显著 |
| 功能强度 | 生态最丰富(大量插件、Lora及Checkpoint模型),支持512×512分辨率,生成速度快 | 35亿参数量(较SD 1.5的8.9亿提升60%细节处理能力),支持1024×1024高清生成,细节接近专业摄影,新增智能提示词补全和25种艺术风格预设 | 多模态输入(文本、草图、风格参考),优化Prompt理解力(减少偏差、提高一致性),支持复杂场景生成 |
| 适用用户 | 新手、低配置设备用户,需快速出图或社交媒体内容(头像、插画) | 专业创作者(设计师、商业插画师),需高精度渲染(广告海报、电影预览图) | 高级用户或企业级场景,需复杂多模态创作(电影级概念设计、3D建模结合) |
版本选择建议
从硬件适配角度,SD 1.5以4GB显存的低门槛成为低配设备(如老旧显卡或笔记本)的首选,其轻量化特性确保在有限资源下仍能快速生成图像。对于配备RTX 3060及以上显卡(8GB显存)的用户,SDXL凭借1024×1024分辨率和细腻细节,可满足专业级画质需求,尤其在色彩光影还原和复杂场景表现上接近专业摄影水平。而SD3作为新一代模型,虽未明确最低显存要求,但其多模态输入和精准控制力更适合拥有高性能硬件且需处理复杂创作场景(如多主体融合、跨模态风格迁移)的进阶用户。
从需求场景看,若目标是快速出图或二次创作(如二次元、卡通风格),SD 1.5丰富的生态资源(如预制模型和插件)可显著降低操作成本。SDXL则更适合对画质有严格要求的场景,例如商业插画或 advertising 素材,其智能提示词补全和格式兼容性(WebP/PSD)进一步提升专业工作流效率。SD3目前处于预览阶段,多模态功能(如草图驱动生成)使其在概念设计和跨媒介创作中具备潜力,但需注意其尚未广泛可用且可能受安全措施影响性能。
SD 3.5版本解析:Large/Turbo/Medium
Stable Diffusion 3.5(SD3.5)在技术架构上实现了显著突破,核心改进包括QK归一化(大型Transformer模型的标准优化方法)和双注意力层(在MMDiT结构中引入两个注意力模块),这些创新提升了模型的特征提取精度与生成稳定性,为不同应用场景提供了性能基础。该版本包含三个子模型,分别针对专业需求、实时交互与轻量化应用进行优化,其真实感表现优于前代SDXL,在商业场景中具备较强竞争力。
SD3.5 Large作为完整模型,参数规模达80亿,原生支持百万像素级分辨率输出(如1024×1024,即1兆像素),图像细节与真实感表现卓越。该模型需20个采样步骤,单张图像处理时间约20秒,推荐配置16GB以上显存以确保流畅运行,适用于专业设计、商业营销内容创作等高精度需求场景,如游戏概念艺术、高端广告素材制作等专业商业用途。
| 参数 | SD3.5 Large | SD3.5 Large Turbo | SD3.5 Medium |
|---|---|---|---|
| 参数规模 | 80亿 | 与Large相近 | 25亿 |
| 分辨率支持 | 百万像素级<br>(如1024×1024) | 与Large相同 | 0.25-2百万像素 |
| 生成步骤 | 20步 | 4步 | 未明确 |
| 单张处理时间 | ≈20秒 | ≈10秒 | 未明确 |
| 推荐显存 | ≥16GB | ≥8GB | 12GB可流畅运行 |
| 核心优势 | 专业高精度图像 | 实时交互速度 | 消费级硬件优化 |
| 适用场景 | 专业设计/商业营销 | 直播草图生成 | 个人创作者日常使用 |
SD3.5 Large Turbo是Large版本的蒸馏优化模型,通过时间步蒸馏技术将生成步骤压缩至4步,单张图像生成时间缩短至10秒(部分场景可实现更快速度),参数规模与Large相近但计算效率显著提升,推荐8GB以上显存即可运行。其核心优势在于快速迭代能力,适合实时交互场景,如直播中的草图即时生成、设计方案快速预览等对响应速度要求高的应用。
SD3.5 Medium则以25亿参数实现了质量与效率的平衡,支持0.25至2百万像素分辨率输出,针对消费级硬件优化,在12GB显存的普通设备上即可流畅运行。该模型采用改进的MMDiT-X架构及训练方法,通过在变换器前13层引入自注意力模块增强多分辨率生成能力与图像一致性,兼顾了生成质量与硬件友好性,适用于个人创作者、低配设备用户的日常使用及轻量化商业需求。
综合来看,SD3.5系列通过技术创新与模型细分,在真实感表现上较前代有显著提升,其三个子版本分别覆盖了专业高精度、实时交互与轻量化应用场景,凭借卓越的图像质量与灵活的部署能力,在商业生成式设计领域展现出强劲竞争力。
核心功能解析
WebUI界面与基础操作
完成Stable Diffusion安装后,通过运行懒人包的run.bat或标准安装的webui-user.bat启动服务,首次启动将自动弹出浏览器界面,或手动访问http://127.0.0.1:7860进入AUTOMATIC1111开发的WebUI界面,该界面基于浏览器运行,支持直观调整参数和管理插件,核心功能围绕“文生图(txt2img)”工作流展开。
文生图工作流核心步骤
1. 模型选择
界面左上角的下拉框用于切换Stable Diffusion大模型,模型决定生成图像的基础风格与类型,其存放目录为stable-diffusion-webui/models/Stable-diffusion,拷贝模型文件后刷新或重新加载即可生效。此外,VAE模型(存放于stable-diffusion-webui/models/VAE)可通过设置界面添加至快速选项,用于滤镜效果和画面微调,常用型号如“840000”,能优化图像色彩与细节表现。
2. 提示词编写
提示词分为正向与反向两类:
- 正向提示词:明确生成内容的细节描述,如“1girl, blue dress, sunset”,需精准传达主体、场景、风格等要素。
- 反向提示词:指定需规避的特征,如“malformed hands, extra fingers, lowres”,可有效降低畸形手脚、模糊等不良特征的生成频率,其效果优于通过括号调整关键词权重的强调符方法。
3. 参数配置
- 采样方法与迭代步数:人物图像推荐使用“DPM++ 2S a”采样器,迭代步数设置为25-30,可在保证生成质量的同时平衡效率;若步数过低(如<20)可能导致图像出现视觉缺陷。
- 无分类指导比例(CFG值):建议设置为7-10,低数值(如5-7)适合创意场景,高数值(如9-12)适合需要严格匹配提示词的具体输出。
- 图像尺寸:基础分辨率推荐方图512×512(SD 1.x)、768×768(SD 2.x)或1024×1024(SDXL),竖图或横图需保持等比例缩放以避免变形。
4. 高清修复与生成优化
“高清修复”功能可对生成图像进行放大处理,提升细节清晰度,适合基础分辨率生成后进一步优化画质。生成批次与每批数量参数控制图像产出效率,每批数量建议设为1以降低显存占用。
汉化设置(降低中文用户门槛)
通过安装汉化插件(如stable-diffusion-webui-localization-zh_Hans)可将界面转为中文。具体步骤为:在WebUI的“Extensions”选项卡中搜索插件名称,安装后重启界面,在“Settings→User interface→Localization”中选择“zh-Hans”并应用,即可完成汉化。
高级功能:ControlNet与多模态输入
ControlNet作为Stable Diffusion的核心高级控图工具,通过引入外部控制图(如边缘检测结果、人体姿势骨架、深度图等)实现生成过程的精准调控,其核心机制在于将输入控制信号与生成模型的中间特征层绑定,从而约束图像生成的结构与细节。该功能支持Canny边缘检测、Openpose姿势估计、Depth深度估计等10余种预处理器,可根据需求选择对应工具生成控制图,显著提升复杂场景下的生成可控性。
在具体应用中,ControlNet与辅助工具的联动可实现高度定制化的控图效果。例如,结合Openpose-editor插件生成的人体骨架图作为控制输入时,模型能够严格遵循骨架定义的关节位置与肢体姿态,生成符合自定义动作要求的人物图像。这一流程突破了传统生成中人物姿势随机性的限制,尤其适用于动漫角色、虚拟偶像等需要精准动作设计的场景。此外,通过Depth预处理器生成的深度图可作为控制信号,辅助Depth2img模型保留原始图像的空间结构关系,在场景重构或视角调整任务中,能够有效维持物体间的前后位置与比例关系,避免传统生成中常见的空间扭曲问题。
Stable Diffusion 3.5(SD 3.5)的多模态输入功能进一步拓展了可控性边界,支持文本、草图、风格参考图的联动输入,其核心改进在于引入结构化提示词语法,解决了旧版“关键词堆砌”模式下语义解析精度低、风格控制模糊的局限性。结构化提示词通过[风格:XXX]语法(如[风格:赛博朋克])实现对生成风格的精准锚定,系统能够优先解析标签内的风格指令,并将其与文本描述、参考图像等多模态信息融合,确保风格特征在生成过程中的一致性与主导性。相较于旧版依赖关键词权重调整(如“赛博朋克, 未来感, 霓虹灯光::5”)的粗放式控制,结构化语法显著降低了风格偏移风险,尤其在复杂风格混合(如[风格:巴洛克]+[风格:蒸汽波])场景下,可实现更细腻的视觉过渡效果。
此外,SD 3.5的多模态输入支持跨模态信息的协同优化。例如,用户可同时输入文本描述(“未来城市夜景”)、草图轮廓(勾勒建筑布局)及风格参考图(赛博朋克色调样本),系统通过结构化提示词[风格:赛博朋克]统一风格基准,结合ControlNet的Depth预处理器保留草图的空间布局,最终生成既符合构图要求又精准匹配目标风格的图像,体现了“文本-图像-控制信号”多维度协同的高级生成能力。
模型类型与应用
基础模型(Checkpoint)
基础模型(Checkpoint,简称底模或大模型)是Stable Diffusion生成图像的“画风基石”,作为核心知识库决定生成内容的整体风格走向,如二次元、真人写实、2.5D等类型,其文件格式通常为.ckpt或.safetensors,体积普遍在2GB至8GB之间。该类模型通过控制画面构图、色彩基调、细节表现等核心要素,为后续生成任务提供基础框架,是AI绘画风格的根本决定因素。例如,动漫风格可选用Counterfeit-V3.0(厚涂油质感)、AbyssOrangeMix3(油光质感人物/景物),真实风格可选用AWPortrait(高逼真肖像)、ChilloutMix(逼真风景与人物)等专用模型,而通用基础模型如SD1.5(轻量级入门)、SDXL(高画质)、SD3(专业级)及其衍生版本(如Anything V5、majicMIX系列)则需根据场景需求选择或融合使用。
在模型管理方面,不同工具的存放路径存在差异:WebUI环境下通常存放于stable-diffusion-webui/models/Stable-diffusion目录,ComfyUI则对应ComfyUI/models/checkpoints路径,用户可通过WebUI顶部的模型切换栏快速切换不同底模,实现多风格任务的灵活调度。以SD 3.5版本为例,其基础模型系列包括Large(80亿参数,支持1MP+高清图像生成与微调)、Large Turbo(精简版,四步快速生成,速度优先但质量略降)及Medium(25亿参数,支持2MP图像,低内存占用适配消费级硬件),用户可根据硬件性能与画质需求选择对应模型文件。
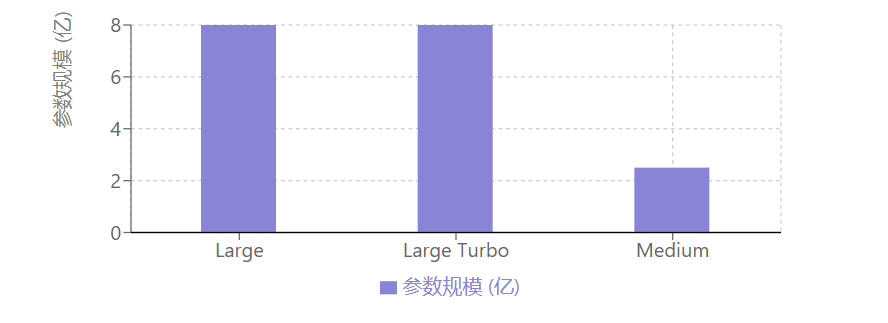
文件格式方面,.ckpt与.safetensors是两种主流类型。.ckpt为TensorFlow格式,包含模型权重及训练状态信息,适用于需要保留训练细节的微调场景,但存在潜在恶意代码风险且体积较大;.safetensors由HuggingFace设计,仅存储张量权重数据,具有无恶意代码风险、加载速度快、体积更精简等优势,因此在直接出图场景中推荐优先使用。需注意,部分旧版WebUI需升级后才能支持.safetensors格式加载。
微调模型:LoRA与Embedding
在Stable Diffusion的模型微调技术中,LoRA(低秩自适应模型)与Embedding(文本反转模型)是两种针对不同需求设计的轻量化工具,二者在功能定位、体积规模及应用场景上存在显著差异,且可通过组合使用实现更精准的生成控制。
从功能特性来看,LoRA的核心价值在于对特定角色、物品或艺术风格的精细化微调。作为基于大模型的低秩自适应技术,其通过优化模型参数的低秩矩阵,实现对目标特征的定向强化,例如固定角色的面部特征、特定画风(如二次元、写实)或物品细节的复刻。相比之下,Embedding的功能聚焦于提示词的简化与打包:正向提示词中,它可将多个描述性词汇压缩为单个触发词(如用“鸣人”代替“黄色头发、蓝色眼睛、护额”等长串特征描述);负向提示词中,其能将“低画质、模糊、变形”等常见负面词汇打包为统一向量,典型案例如EasyNegative模型,通过单个关键词即可调用预设的负面提示词集合。
体积规模上,二者差异悬殊。LoRA模型因需存储微调后的低秩矩阵参数,文件体积通常为几十至几百MB,常见规格包括36M、72M、144M等,格式多为.ckpt、.safetensors或.pt。而Embedding作为文本向量的压缩结果,仅需存储训练得到的文本反转向量,文件体积极小(通常为几十KB),格式为.pt。
使用场景的分化进一步体现了二者的互补性。LoRA适合对固定角色或风格进行深度微调,例如通过训练特定角色的LoRA模型,在生成时保持角色特征的一致性,部分LoRA需通过触发词激活(如“jellyfishforest”),且支持多模型同时加载以叠加效果。Embedding则更适用于简化提示词流程,尤其在负向提示词管理中优势显著,例如通过EasyNegative(下载地址:https://civitai.com/models/7808/easynegative)可快速调用标准化的负面词汇集合,减少重复输入。
在实际应用中,LoRA与Embedding的组合使用可显著提升生成效率与质量。典型流程为:以通用基础模型(如SD1.5)为底模,通过LoRA模型调整细节特征(如角色服饰、场景光影风格),同时加载Embedding优化提示词结构(如正向用Embedding简化角色描述,负向用EasyNegative打包负面词汇)。例如,在ComfyUI工作流中,可通过串联LoRA模型实现风格微调,并同步调用Embedding触发词以精简提示词输入,形成“底模+LoRA细节控制+Embedding提示词优化”的协同模式,兼顾生成精度与操作便捷性。
综上,LoRA与Embedding通过差异化的“功能-体积-场景”定位,共同构成了轻量化微调的核心工具链:LoRA以中等体积实现高精度风格/角色控制,Embedding以极小体积简化提示词流程,二者的组合应用为 Stable Diffusion 的精细化生成提供了灵活解决方案。
辅助模型:VAE与Hypernetwork
在Stable Diffusion的图像生成流程中,基础模型(底模)可能面临色彩暗淡、细节模糊等问题,导致输出图像呈现“灰蒙蒙”的视觉效果。这一问题的核心在于基础模型在图像解码过程中对色彩和细节的还原能力有限,而变分自编码器(VAE)作为辅助模型,通过优化解码阶段的特征映射,成为解决该问题的关键方案。
VAE的核心功能是通过调整图像的色彩映射与细节重构,改善生成结果的视觉质量。具体而言,当基础模型生成的图像存在颜色暗淡、对比度不足等问题时,外挂VAE模型可显著提升色彩饱和度与亮度,同时增强细节锐利度。其文件格式通常为.ckpt、.pt或.safetensors,体积约300MB,需存放于models/VAE目录下,使用时通过WebUI顶部设置栏切换sd_vae参数实现启用。需注意的是,部分大模型(如Chilloutmix)已内置VAE功能,额外添加外部VAE可能导致色彩失真(如生成“蓝色废图”),此时需将VAE模式切换为“Automatic”以避免冲突。常用的VAE模型包括Stability AI发布的EMA(锐利风格,对应文件vae-ft-ema-560000-ema-pruned.safetensors)和MSE(平滑风格,对应文件vae-ft-mse-840000-ema-pruned.safetensors),用户可根据生成需求选择适配类型。
与VAE不同,Hypernetwork作为另一类辅助模型,其设计初衷是通过微调网络权重影响生成风格,但在实际应用中逐渐被LoRA取代。Hypernetwork的核心特点是模型体积较小(通常几十MB),文件格式为.pt,存放于models/hypernetwork目录,使用时需在提示词中通过\<hypenet:filename:multiplier>格式调用。然而,相较于LoRA,Hypernetwork存在显著局限性:其一,其对模型特征的调控能力较弱,被视为“低配版LoRA”;其二,训练过程难度较高,难以稳定生成高质量效果;其三,随着LoRA技术的成熟,Hypernetwork的功能已被更高效的LoRA覆盖。因此,目前Hypernetwork的适用场景极为有限,仅在特定 legacy 工作流中可能保留使用,大多数情况下建议优先选择LoRA以实现更精准、高效的风格调控。
插件系统与常用插件
插件安装与管理
Stable Diffusion WebUI的插件安装主要通过WebUI界面完成,具体流程可分为两种方式。第一种是通过插件市场搜索安装:在WebUI中进入“Extensions”页面,选择“Available”选项卡,点击“Load from”加载插件列表,随后搜索目标插件(如汉化插件“hans”和“bilingual”),选中后点击安装,完成后需点击“Apply and restart”使插件生效。第二种是通过GitHub链接安装,适用于需指定版本或未在市场收录的插件(如ControlNet):在“Extensions”页面选择“Install from URL”,输入插件的GitHub仓库链接(例如ControlNet的官方链接https://github.com/Mikubill/sd-webui-controlnet),点击“install”,待提示“installed into”后重启WebUI即可启用。
插件安装后需特别注意版本兼容性。由于Stable Diffusion核心版本升级可能导致API变化,例如SD3.5因核心API更新,要求ControlNet插件版本需为4.0及以上,否则可能出现功能异常或无法加载。对于存在兼容性问题的经典插件(如LoRA训练器),官方已推出兼容层转换工具,可通过该工具适配新版本WebUI。
插件管理功能可通过WebUI的“Installed”页面实现,用户可在此查看所有已安装插件,并根据需求禁用或卸载冲突插件,以避免功能重叠或运行异常。此外,推荐安装Civitai Helper插件,该插件可解决模型预览图缺失、插件版本更新检测、模型断点续传下载等实际使用痛点,提升插件与模型管理的效率。
必备插件推荐
在Stable Diffusion的创作流程中,插件的合理搭配能够显著提升效率与成果质量。以下按“前期准备-中期生成-后期优化”的创作流程,结合显存优化与局部编辑等实操需求,提供插件组合方案,并说明SD3.5版本的插件兼容性要点。
一、前期:提示词优化与准备
前期核心需求为提升提示词(Prompt)的准确性与完整性,减少手动输入负担。TagComplete是该阶段的核心插件,其支持自动补全Embeddings、LoRA、Hypernetwork等模型名称,通过输入\<e:>(触发Embeddings)、\<l:>(触发LoRA)、\<h:>(触发Hypernetwork)等前缀即可快速调用资源,大幅提升提示词编写效率。辅助工具可搭配sd-webui-prompt-all-in-one(实现提示词翻译与顺序调整)及Tag反推插件(通过图片获取提示词,辅助逆向学习),形成“提示词生成-补全-优化”的完整前期流程。
二、中期:图像生成与控制
中期聚焦于图像生成过程的精准控制、大分辨率输出及局部调整,需结合显存优化策略。
- 控图核心:ControlNet插件通过输入图像(如姿势图、边缘图)或控制参数引导生成,支持人体姿势、物体边缘等精细控制,是实现“所想即所得”的关键工具。配合Inpaint局部重绘(支持普通局部重绘与手涂蒙版),可对生成图像的特定区域进行针对性调整,例如修正局部构图或细节。
- 放大与显存优化:Tiled Diffusion + Tiled VAE组合专为小显存设备设计,可生成大分辨率图像。文生图场景下仅启用Tiled VAE即可,图生图场景需同时启用两者以平衡显存占用与生成质量。实操中建议同步启用
--xformers参数优化显存分配,进一步提升大分辨率生成的稳定性。若需分块放大或修改原图,可补充Ultimate Upscaler插件,通过ESRGAN、GFPGAN等算法实现高清放大。
三、后期:细节修复与增强
后期重点在于修复生成图像中的细节瑕疵,提升整体质感。Adetailer(After Detailer) 插件可自动识别并增强人脸、手部等关键区域的细节,无需手动蒙版即可实现精准修复,是后期优化的核心工具。若需针对性修复脸部,可补充Face Editor插件,通过图生图模式进一步调整 facial features 的清晰度与自然度。
SD3.5插件兼容性说明
当前SD3.5版本的插件生态存在一定限制:WebUI(Automatic1111)暂未完全支持其插件系统,多数经典插件(如ControlNet、Tiled Diffusion)的功能适配仍在开发中。建议优先使用ComfyUI的插件生态,其支持中文语言包(如AIGODLIKE-ComfyUI-Translation)、语法检查插件及兼容层转换工具,可适配SD3.5的新特性与模型架构。
高级应用与优化
性能优化:显存与速度平衡
Stable Diffusion的高效运行需在显存占用与生成速度间实现动态平衡,针对不同硬件配置(低配、中配、高配)需采取差异化优化策略。以下结合具体硬件场景与技术参数,提供系统性解决方案,以解决显存不足、生成缓慢等核心问题。
一、低配硬件(显存≤8GB,如GTX 1060等)
此类设备需优先解决显存瓶颈,同时保障基础生成效率。显存优化方面,可通过启动参数与精度控制实现资源高效利用:开启“--medvram”参数(适用于8GB以下显存)并配合FP16混合精度模式(在WebUI设置中启用“Use mixed precision (FP16)”),可将512×512图像生成的显存需求从6GB降至3GB。启用xFormers加速(启动参数添加“--xformers”)可提升注意力计算速度,进一步降低显存占用。速度优化方面,推荐使用SD 3.5 Large Turbo模型,其仅需4步采样即可生成图像,单张处理时间约10秒,适配低配设备算力限制。存储层面,建议将模型文件存放于SSD,相较机械硬盘可减少3-5倍加载时间。
二、中配硬件(显存8-12GB,如RTX 3060等)
中配设备可在显存控制基础上进一步提升生成效率。针对RTX 3060等NVIDIA显卡,启用“--medvram-sdxl”参数可针对性适配SDXL模型,结合xFormers加速与FP16模式,实现显存占用与速度的双重优化。对于AMD Radeon 7000系列显卡,安装24.30+版本驱动后,使用ONNX优化版模型(后缀“_amdgpu”)可使SD 3.5 Large Turbo生成速度提升2.1倍。显存优化还可采用bitsandbytes量化技术,通过Diffusers库加载NF4精度模型(需安装transformers与bitsandbytes依赖),在保持生成质量的前提下降低显存需求。此外,SD 3.5系列通过架构优化降低了显存占用,Medium版本因参数量较少,更适合中配设备运行更大模型。
三、高配硬件(显存≥12GB,如RTX 3090、AMD Radeon RX 9070 XT等)
高配设备可聚焦速度优化与高级功能启用,同时通过精细化控制实现资源高效利用。显存管理上,SD 3.5推荐配置为12GB(最低)、24GB(最佳)、32GB(更好),Large型号需重点优化推理阶段显存占用,结合SDXL智能缓存技术可提升30%显存利用率,支持生成更大尺寸图像。速度优化方面,SD 3.5 Large Turbo仅需4步采样,AMD显卡配合ONNX优化模型可使SD 3.5 Large生成速度提升3.3倍;生成4K分辨率图像时,多级渲染技术可将处理时间缩短40%。对于ComfyUI用户,可采用实验性fp8_scaled工作流(如使用t5xxl_fp8_e4m3fn_scaled.safetensors替代t5xxl_fp16模型),在32GB以上内存环境下进一步优化显存占用。此外,合理调整批处理大小(根据显存容量设置)可避免OOM错误,配合SSD存储实现模型快速加载,最大化硬件性能。
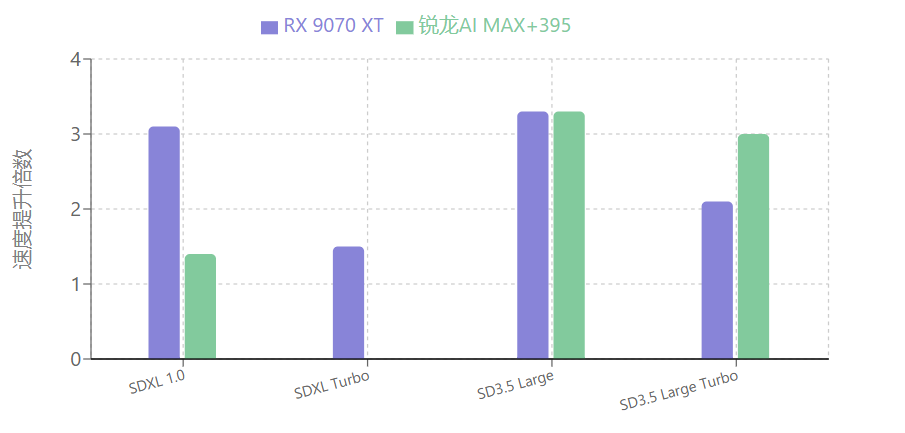
通过上述策略,不同硬件配置可实现针对性优化:低配设备显存占用降低40%以上,中高配设备生成速度提升2-3.8倍,从而在各类硬件环境下实现Stable Diffusion的高效运行。
商业应用与版权规范
在Stable Diffusion的商业应用中,版权合规是不可忽视的核心议题,实践中因版权意识薄弱导致的法律风险已多次显现。例如,某设计公司因误用未经授权的社区修改版模型被追责,最终造成12万美元的经济损失,这一案例凸显了商业用户明确许可条款、规避版权风险的重要性。
Stable Diffusion系列模型的商业使用权限因版本和许可类型存在明确界定。以Stable Diffusion 3.5为例,其在社区许可证框架下发布,免费使用范围包括研究或非商业用途,以及年总收入不足100万美元的组织或个人的商业用途;若商业用户年营收超过100万美元,则需申请企业许可证。此外,不同版本的许可条款存在差异:SD 1.5、2.1及XL版本采用CreativeML Open RAIL许可,允许广泛商业使用;而SD 3.x系列则更新了条款,明确将年收入100万美元作为商业用途的阈值,超过该标准的用户需通过官方渠道获取授权。
| SD版本 | 许可类型 | 免费商业使用条件 | 收入阈值 | 授权要求 |
|---|---|---|---|---|
| SD 3.5 / SD 3.x | 社区许可证 | 年收入 < 100万美元 | 100万美元 | 超过阈值需企业许可证 |
| SD 1.5/2.1/XL | CreativeML Open RAIL | 允许广泛商业使用 | 无 | 无需额外授权 |
为降低法律风险,商业用户需采取针对性措施确保合规。首先,应严格区分模型许可类型:对于年营收达到或超过100万美元的企业,需通过Stability AI官网的“企业服务”通道申请正式授权;个人创作者或小型企业(年营收低于100万美元)可在免费许可范围内商用,但需避免使用未授权的衍生模型,此类模型可能因训练数据或修改权限问题存在版权瑕疵。其次,推荐通过专业平台筛选合规模型,例如在Civitai等社区中利用许可类型过滤功能,选择明确标注“可商用”的模型,从源头确保使用权限无争议。
版权合规是Stable Diffusion商业应用的前提,任何忽视许可条款、误用未授权模型的行为都可能导致法律追责。商业用户应建立完善的版权审查机制,结合自身营收规模选择合适的授权方式,确保AI生成内容的合法使用,从根本上规避法律风险。
总结与资源推荐
核心要点总结
Stable Diffusion作为当前AI绘画领域的主流工具,其核心优势体现在三个方面:一是免费开源特性,降低了技术使用门槛,允许用户自由部署与二次开发;二是功能体系完善,覆盖文生图、图生图、控图(如ControlNet插件支持)等全流程创作需求;三是生态系统丰富,提供多样化模型(动漫、真实风格等)与插件支持(如Deforum动画生成),适用于艺术创作、设计开发等多元场景。
定制化学习建议
针对不同用户需求,建议采取差异化学习路径:
- 入门用户:优先选择低门槛工具与轻量模型。硬件配置有限时,推荐SD1.5版本(资源丰富、易于上手)或SD 3.0 Lite轻量版(8GB显存即可运行,内置200+预设风格模板及智能提示词优化器);若需降低学习成本,可尝试SDXL版本,其智能提示功能与预设模板能简化参数调试流程。
- 专业用户:聚焦高画质与技术深度。推荐使用SDXL(需8GB以上显存)或SDXL Turbo企业版,搭配RTX 3060及以上显卡以保障4K图像处理效率;工具方面,建议掌握ComfyUI进行节点式工作流设计,结合ControlNet等插件实现精准控图,并通过Hugging Face、Civitai等平台获取专业模型(如写实风格、行业专用模型)。
- 商业用户:注重效率与规模化应用。可优先采用在线平台(如DreamStudio、Clipdrop)快速生成内容,或通过Stability AI开发者API(https://platform.stability.ai/)集成至业务系统;模型管理推荐使用千帆大模型开发与服务平台,实现模型下载、训练与协作流程的一体化管理,同时关注Siliconflow等优化平台以提升部署效率。
| 用户类型 | 推荐工具 | 硬件要求 | 核心功能优势 |
|---|---|---|---|
| 入门用户 | SD1.5 / SD 3.0 Lite轻量版 | 8GB显存 | 200+预设风格模板 智能提示词优化器 |
| 专业用户 | SDXL / SDXL Turbo企业版 | RTX 3060+显卡<br>8GB+显存 | 4K图像处理 节点式工作流设计 |
| 商业用户 | DreamStudio/Clipdrop在线平台 Stability AI开发者API | 无特定要求 | 快速内容生成 业务系统集成 |
权威资源平台推荐
为支持用户持续学习与资源获取,推荐以下权威渠道:
- 官方核心渠道:Stability AI官网(https://stability.ai)提供最新公告与研究成果;GitHub仓库(如AUTOMATIC1111/stable-diffusion-webui、comfyanonymous/ComfyUI)包含开源代码、安装指南及社区贡献插件。
- 中文学习资源:Stable Diffusion中文网(www.stablediffusion-cn.com)提供汉化教程、模型下载、中文语言包插件(如AIGODLIKE-ComfyUI-Translation)及技术社群支持(通过网站右侧二维码加入万人交流群)。
- 模型与插件获取:Hugging Face(https://huggingface.co)、Civitai(https://civitai.com)为核心模型库,覆盖从基础模型到风格化模型;Liblib.art(https://www.liblib.art/)提供中文模型分享,Lexica(https://lexica.art/)可参考提示词案例。
- 工具与平台:在线生成工具包括stablediffusionweb.com、Replicate;本地部署需配置Python 3.10.6、Git及WebUI/ComfyUI;云服务推荐HyperAI超神经(提供免费算力时长)与haoee.com的ComfyUI云镜像(内置预设工作流)。
AI创作的协作理念
Stable Diffusion的发展始终强调“人类引导+AI辅助”的协作模式。AI工具通过高效生成与技术赋能拓展创作边界,而人类创作者则在创意构思、审美判断、参数调控中发挥主导作用。建议用户以开放心态探索技术与艺术的融合,通过精准提示词设计、插件工具组合与模型微调,将AI辅助转化为个性化创作能力,最终实现技术效率与艺术表达的协同提升。