Python 使用 asyncio 包处理并 发(避免阻塞型调用)
避免阻塞型调用
Ryan Dahl(Node.js 的发明者)在介绍他的项目背后的哲学时说:“我们
处理 I/O 的方式彻底错了。” 他把执行硬盘或网络 I/O 操作的函数定义
为阻塞型函数,主张不能像对待非阻塞型函数那样对待阻塞型函数。
为了说明原因,他展示了表 18-1 中的前两列。
表18-1:使用现代的电脑从不同的存储介质中读取数据的延迟情
况;第三栏按比例换算成具体的时间,便于人类理解
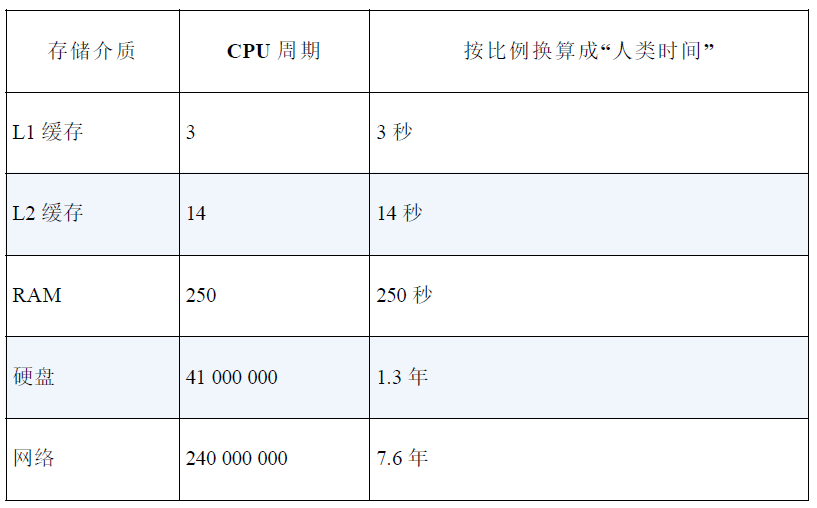
为了理解表 18-1,请记住一点:现代的 CPU 拥有 GHz 数量级的时钟频
率,每秒钟能运行几十亿个周期。假设 CPU 每秒正好运行十亿个周
期,那么 CPU 可以在一秒钟内读取 L1 缓存 333 333 333 次,读取网络 4
次(只有 4 次)。表 18-1 中的第三栏是拿第二栏中的各个值乘以固定
的因子得到的。因此,在另一个世界中,如果读取 L1 缓存要用 3 秒,
那么读取网络要用 7.6 年!
有两种方法能避免阻塞型调用中止整个应用程序的进程:
- 在单独的线程中运行各个阻塞型操作
- 把每个阻塞型操作转换成非阻塞的异步调用使用
多个线程是可以的,但是各个操作系统线程(Python 使用的是这种线
程)消耗的内存达兆字节(具体的量取决于操作系统种类)。如果要处
理几千个连接,而每个连接都使用一个线程的话,我们负担不起。
为了降低内存的消耗,通常使用回调来实现异步调用。这是一种低层概
念,类似于所有并发机制中最古老、最原始的那种——硬件中断。使用
回调时,我们不等待响应,而是注册一个函数,在发生某件事时调用。
这样,所有调用都是非阻塞的。因为回调简单,而且消耗低,所以 Ryan
Dahl 拥护这种方式。
当然,只有异步应用程序底层的事件循环能依靠基础设置的中断、线
程、轮询和后台进程等,确保多个并发请求能取得进展并最终完成,这
样才能使用回调。 事件循环获得响应后,会回过头来调用我们指定的
回调。不过,如果做法正确,事件循环和应用代码共用的主线程绝不会
阻塞。
把生成器当作协程使用是异步编程的另一种方式。对事件循环来说,调
用回调与在暂停的协程上调用 .send() 方法效果差不多。各个暂停的
协程是要消耗内存,但是比线程消耗的内存数量级小。而且,协程能避
免可怕的“回调地狱”;这一点会在 18.5 节讨论。
现在你应该能理解为什么 flags_asyncio.py 脚本的性能比 flags.py 脚本高
5 倍了:flags.py 脚本依序下载,而每次下载都要用几十亿个 CPU 周期
等待结果。其实,CPU 同时做了很多事,只是没有运行你的程序。与此
相比,在 flags_asyncio.py 脚本中,在 download_many 函数中调用
loop.run_until_complete 方法时,事件循环驱动各个
download_one 协程,运行到第一个 yield from 表达式处,那个表达
式又驱动各个 get_flag 协程,运行到第一个 yield from 表达式处,调用 aiohttp.request(…) 函数。这些调用都不会阻塞,因此在零
点几秒内所有请求全部开始。
asyncio 的基础设施获得第一个响应后,事件循环把响应发给等待结果
的 get_flag 协程。得到响应后,get_flag 向前执行到下一个 yield
from 表达式处,调用 resp.read() 方法,然后把控制权还给主循环。
其他响应会陆续返回(因为请求几乎同时发出)。所有 get_ flag 协
程都获得结果后,委派生成器 download_one 恢复,保存图像文件。
为了尽量提高性能,save_flag 函数应该执行异步操作,可
是 asyncio 包目前没有提供异步文件系统 API(Node 有)。如果
这是应用的瓶颈,可以使用 loop.run_in_executor 方法
(https://docs.python.org/3/library/asyncioeventloop.
html#asyncio.BaseEventLoop.run_in_executor),在线程池
中运行 save_flag 函数。示例 18-9 会说明做法。
因为异步操作是交叉执行的,所以并发下载多张图像所需的总时间比依
序下载少得多。我使用 asyncio 包发起了 600 个 HTTP 请求,获得所
有结果的时间比依序下载快 70 倍。
现在回到那个 HTTP 客户端示例,看看如何显示动态的进度条,并且恰
当地处理错误。