LLM 多语言数据集
多语言数据感觉主要还是fineweb和fineweb2, 其他数据都是主要针对特定语种比较多
101 Billion Arabic Words Dataset
ClusterlabAi/101_billion_arabic_words_dataset
数据主要从e Common Crawl WET 中提取,并采用了创新的技术来进行去重和筛选,主要解决大部分语料是从英语翻译过来的问题。
数据收集 :
- 时间 : week 39 of 2021 to week 27 of 2022的时间段内
- 从3000个网站中,筛选出250个阿拉伯网站,
数据清洗 :
数据去重 :
基于minihash的方式对 总文本和段落分别进行去重。
使用了一些专门针对阿拉伯语设计的分词和处理的工具 : Camel tools library version 1.5.2, Tnkeeh v0.0.9。
最终数据集的情况:

缺陷 : 没有对伦理、有害、敏感的数据进行去除,大部分依赖URL进行过滤和进行简单的去重操作。
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
m-a-p/MAP-CC
数据来源 : 包含CC, 学术论文, 百科全书, 书籍.
数据处理流程 :
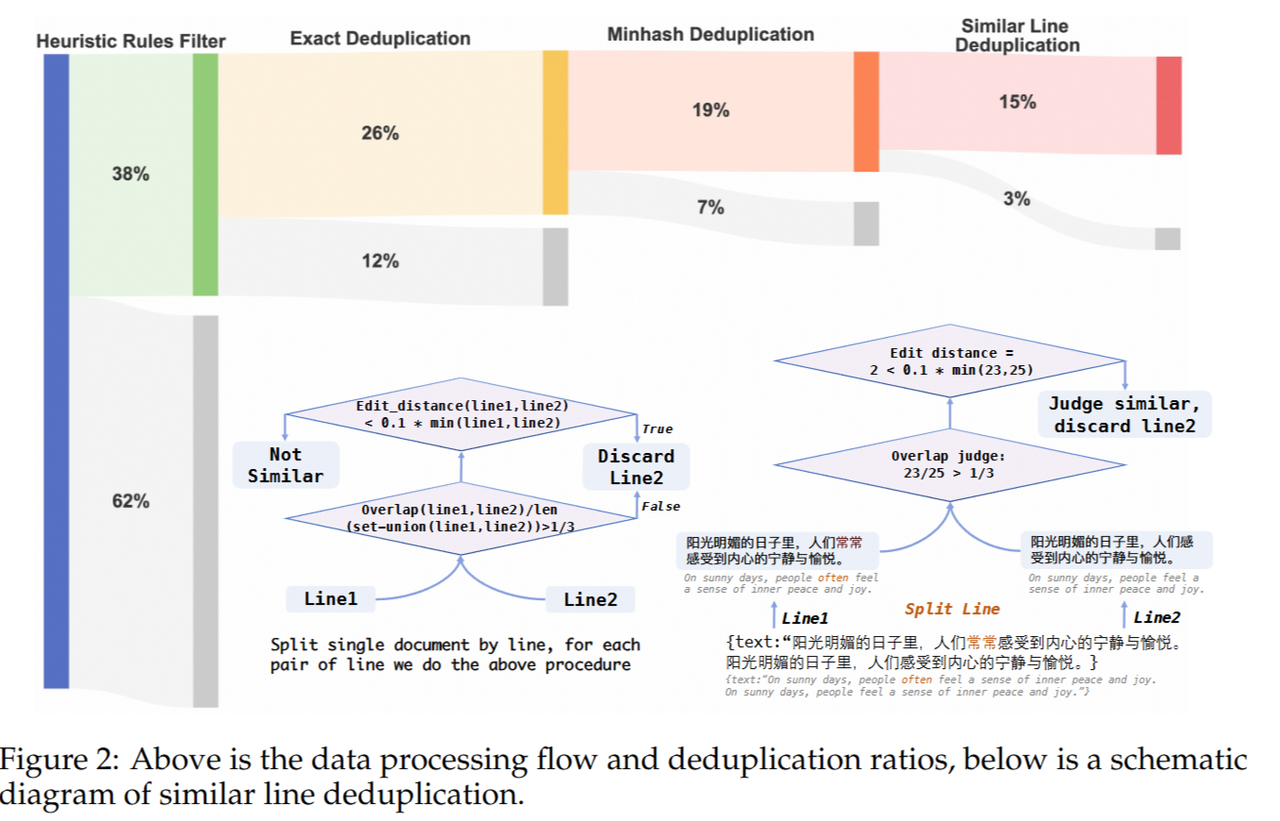

对于上述的启发式过滤采用了右图办法。附带了一个CHC-Bench,评估在中文上的模型性能。
CroissantLLM: A Truly Bilingual French-English Language Model
(论文提到的Tokenizer也有变化,可以去看一看)
法语数据来源(英语和Code数据来源是公开数据集) :
-
Oscar、mC4等多个网络爬虫项目 + 比利时、瑞士和摩洛哥等非洲国家的主流新闻源
-
法国法律行政数据,5.3B
-
文化数据
• 古登堡计划(Hart, 1971)截至2023年10月的全部法语公版书籍(3.02亿token)
• 法国国家图书馆(BnF)的手稿与文档:经OCR处理、公版认证且通过质量筛选(保留2700万token,原始语料大部分因质量剔除)
• 诗歌网站爬取的法语经典诗歌
• 高质量语音转文字生成的播客文本(规模有限)
• OpenSubtitles电影字幕(4180万token) -
百科全书数据
-
工业数据
在对于Web Data做了一些数据清洗的工作,对于其他数据没有进行系统的数据清洗