【AI论文】WebShaper:通过信息寻求形式化实现主动式数据合成
摘要:大型语言模型(LLM)驱动的智能体的出现,通过基于网络的信息检索(Information-Seeking,IS)能力,使复杂开放式任务的解决方案成为可能,从而彻底改变了人工智能领域。然而,高质量训练数据的稀缺性限制了信息检索智能体的发展。现有方法通常采用信息驱动模式,即先收集网络数据,再根据检索结果生成问题。但这种方法可能导致信息结构与推理结构、问题与答案之间出现不一致性。为缓解这一问题,我们提出了一个形式化驱动的信息检索数据合成框架WebShaper,用于构建数据集。WebShaper通过集合论对信息检索任务进行系统化形式化。形式化的核心在于知识投影(Knowledge Projections,KP)的概念,KP操作组合可实现对推理结构的精确控制。在数据合成过程中,我们首先创建种子任务,然后采用多步扩展流程。在每一步中,智能体扩展器(Expander)会根据我们的形式化方法,利用检索和验证工具,将当前形式化问题扩展为更复杂的问题。我们在合成数据集上训练模型。实验结果表明,在GAIA和WebWalkerQA基准测试中,WebShaper在开源信息检索智能体中取得了最先进的性能。Huggingface链接:Paper page,论文链接:2507.15061
研究背景和目的
研究背景:
随着大型语言模型(LLM)技术的发展,基于LLM的智能体在解决复杂、开放式的任务中展现出巨大潜力,尤其是在具备网络信息检索(Information-Seeking, IS)能力后,这些智能体能够自主寻找并处理网络信息以完成任务。然而,训练高效的IS智能体面临一个关键挑战:高质量训练数据的稀缺性。现有数据合成方法大多采用信息驱动模式,即先从网络上收集数据,再基于检索结果生成问题。这种方法可能导致信息结构与推理结构、问题与答案之间的不一致性,影响智能体的性能和泛化能力。
具体而言,当前IS数据集的构建主要依赖于从现有文本资源中提取信息并生成问答对,这一过程缺乏对任务结构的系统性建模,导致生成的数据在复杂性和多样性上存在局限。例如,WebWalkerQA等数据集通过模拟人类浏览网页的行为生成问答对,但主要限于线性信息链的构建,难以覆盖复杂的多跳推理场景。类似地,WebDancer通过聚合外部信息将简单问题扩展为复杂问题,但仍受限于信息来源的多样性和检索策略的有效性。这些方法生成的训练数据往往存在信息冗余、推理路径不清晰等问题,限制了IS智能体处理复杂任务的能力。
研究目的:
本研究旨在提出一种新的形式化驱动的数据合成框架——WebShaper,通过系统性地形式化IS任务,解决现有方法在信息结构与推理结构一致性、任务可控性、数据多样性及覆盖度方面的局限。具体目标包括:
- 构建形式化IS任务框架:基于集合论提出知识投影(KP)的概念,精确控制推理结构,确保信息结构与推理结构的一致性。
- 开发多步扩展数据合成方法:通过种子任务生成和多步扩展过程,系统化地生成覆盖广泛、结构多样的IS任务实例。
- 验证框架有效性:在标准基准测试(如GAIA和WebWalkerQA)上评估WebShaper生成的数据集,证明其能显著提升IS智能体的性能。
研究方法
1. 形式化IS任务框架:
WebShaper将IS任务形式化为基于集合论的数学表达式,核心是知识投影(KP)的概念。KP定义为实体集合E上的二元关系子空间,表示为 \( R \subseteq E \times E \)。通过KP的并集(R-Union)和交集(Intersection)操作,可以递归地构建复杂的IS任务。例如,一个基本的IS任务可以形式化为:
\[ q(T) \triangleq ?T = R_{\text{playIn}}(T_1) \cap (R_{\text{playAt}}(\{2004\}) \cup R_{\text{playAt}}(\{2005\})) \cap R_{\text{bornIn}}(\{90\text{s}\}) \]
其中,\( T_1 \) 是通过其他KP操作定义的中间变量。
2. 数据合成流程:
WebShaper的数据合成流程包括三个主要阶段:
- 种子任务生成:从维基百科离线数据库中随机游走生成大量文章,并利用LLM生成初始问答对。通过过滤和验证确保种子任务的质量。
- 多步扩展:采用层式扩展策略,每一步由智能体扩展器(Expander)根据形式化要求,利用检索和验证工具将当前形式化问题扩展为更复杂的问题。Expander使用三种核心工具:
- Search:通过谷歌搜索获取相关信息。
- Summarize:整合多个网页的信息生成并集常量集。
- Validate:验证生成的问题是否符合形式化要求,并确保其复杂性。
- 轨迹构建:基于QwQ模型采用ReAct范式构建任务完成轨迹,通过多次滚落(rollouts)确保轨迹的质量和相关性。
3. 模型训练:
使用合成数据集对IS智能体进行监督微调(SFT)和强化学习(RL)训练。SFT阶段采用交叉熵损失函数,RL阶段采用GRPO算法优化策略模型。
研究结果
1. 基准测试性能:
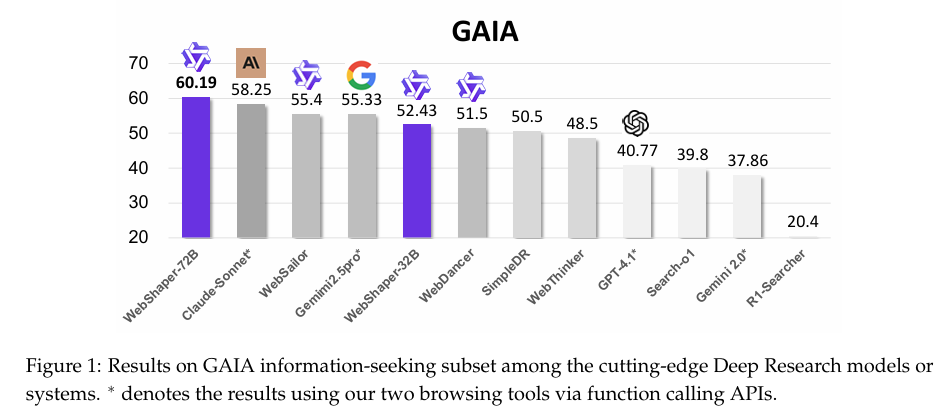
在GAIA和WebWalkerQA基准测试上,WebShaper显著优于其他开源IS智能体。具体结果如下:
- GAIA基准测试:WebShaper在Qwen-2.5-72B backbone上达到69.2的平均分,超过第二名WebSailor 4.7分。
- WebWalkerQA基准测试:WebShaper在Qwen-2.5-72B backbone上达到52.2的平均分,为所有开源方法中最高。
2. 数据多样性和覆盖度:
WebShaper生成的数据集在多个主题领域(如体育、学术、政治、娱乐等)上表现出均衡的覆盖度,避免了单一领域的过度依赖。形式化驱动的方法确保了数据在信息结构与推理结构上的一致性,减少了冗余和推理捷径问题。
3. 强化学习效果:
经过RL训练的模型在GAIA和WebWalkerQA上的性能显著提升。例如,Qwen-2.5-32B模型在GAIA上的Pass@1指标提升了7.8分,Qwen-2.5-72B模型提升了13.5分。这表明RL能有效激活LLM的高级信息检索能力。
研究局限
1. 形式化表达的局限性:
尽管基于集合论的形式化方法能有效建模IS任务,但对于某些复杂场景(如涉及时间动态、空间关系或上下文依赖的任务),形式化表达可能不够灵活或全面。
2. 数据合成的计算成本:
多步扩展和层式扩展策略虽然提高了数据质量,但也显著增加了计算成本。尤其是在大规模数据集生成时,检索和验证工具的调用次数大幅增加,导致训练时间延长。
3. 模型泛化能力的挑战:
尽管WebShaper在标准基准测试上表现优异,但在面对完全未见过的复杂任务时,模型的泛化能力仍需进一步提升。这可能是由于形式化框架对任务结构的预设限制了模型处理非结构化信息的能力。
未来研究方向
1. 扩展形式化表达:
研究更灵活的形式化方法,如引入时态逻辑、空间逻辑或上下文依赖模型,以覆盖更多复杂场景。同时,探索自动化形式化工具的开发,减少人工定义形式化规则的工作量。
2. 优化数据合成效率:
研究更高效的数据合成策略,如并行扩展、缓存机制或增量学习,以降低计算成本。同时,探索利用预训练模型进行初始检索和过滤,减少对外部工具的依赖。
3. 提升模型泛化能力:
研究如何在形式化框架中引入更多非结构化信息处理机制,如注意力机制、记忆网络或元学习,以提升模型在未知任务上的泛化能力。同时,构建更全面的基准测试集,涵盖更多领域和任务类型,以评估模型的泛化性能。
4. 跨领域应用探索:
将WebShaper框架应用于其他需要复杂推理和决策的领域,如医疗诊断、金融分析或科学发现。通过形式化不同领域的任务结构,生成特定领域的训练数据,推动相关领域AI智能体的发展。
5. 伦理和社会影响研究:
研究WebShaper生成的数据在伦理和社会影响方面的潜在问题,如数据偏见、隐私保护或误导性信息。通过引入伦理审查机制或社会责任算法,确保数据合成的公平性和可靠性。
总之,WebShaper框架通过形式化驱动的数据合成方法,为IS智能体的训练提供了高质量、多样化的数据集。未来研究将进一步优化形式化表达、提升数据合成效率、增强模型泛化能力,并探索跨领域应用和伦理影响,以推动AI智能体在复杂任务处理中的发展。