问津集 #2:High Compression and Fast Search on Semi-Structured Logs
文章目录
- 引言
- 正文
- Characterizing Semi-structured Log Data
- 数据来源
- 分析维度
- Schema Variation
- Type Composition
- Repetitiveness of Variables
- Importance of Schema Search
- 设计启示
- µSlope
- 结语
引言
昏昏沉沉,一觉起来已经是下午四点,家里的飞屋小猫正四仰八叉躺在地板上思考猫生,而女朋友正在书桌前努力工作,我到底加入那一边?上进与躺平,这是个问题。
我并不是这一天都是如此消沉,早上十点送女朋友去上瑜伽课,我在那一个小时写完了论文的框架,脑子里多少是对今天要做的事情有一个基础的预期:读两篇paper+输出一点想法,但是真的到了这一刻觉得发呆一天也是一个不错的选择。
打开TODO List,这么多东西还没做,如果此时有一个AI能把知识灌到我的脑子里就好了,高带宽脑机接口!真到了那一天可能也没有必要在论文之上再做像我现在做的事情了吧,每天的工作真的就是创新型工作了。想到明天要给TEG今年实习生讲的PPT,起名叫“温和的奇点.好奇与品位”,其实也就是想告诉大家在当前时代可以把更多的精力放在思考上,把重复的工作交给AI,但是我现在所干的事情从某种意义来讲仍旧是重复的。想到这里,论文还是要读,文章还是要写,但是内容会更为简练。
好了,坐在书桌前,女朋友旁边,开始今天的工作时间。
正文
文章的主要观点是将半结构化的数据转化为结构化存储,并基于此设计了MPT(Merge Parse Tree),识别数据的Schema,每种Schema使用不同的表来存储,这样就可以保证一个Schema的数据存储在一起,以此大幅度提升压缩比,这个想法非常有洞察力,这样可以把一个日志打印点当做一个传感器。
而且也可以基于MPT去过滤一部分查询,这个其实比较简单,和influxdb引擎很像,在倒排索引中找到每个查询条件携带的时间线,如果最终交集是空,就证明不存在这样的行,也就不筛选数据就过滤了这部分查询了。
这篇文章有意思的一点是其Characterizing Semi-structured Log Data 章节描述的非常详细,这其实给我们做事情很好的启发,做事情之前的业务调研甚至比做事情本身更为重要,一个好的业务洞察已经解决了50%的问题,
Characterizing Semi-structured Log Data
数据来源
Uber 内部日志:16 个高频使用的日志数据集(命名为 LogA 至 LogP),涵盖支付、调度、地图等核心服务,均为 JSON 格式。
开源软件日志:5 个主流开源软件的日志(Apache Spark、MongoDB、CockroachDB、Elasticsearch、PostgreSQL),同样为 JSON 格式,用于验证分析结果的通用性。
每个数据集包含 100 万条记录,覆盖不同业务场景和日志生成逻辑。
分析维度

上面就是一条日志,其实就是一个典型的宽事件,opentelemery的上报就是这样。
每条半结构化日志record对应一个root。上图展示了两条record,一个日志数据集包含若干这样的record。每条record的schema可以用一棵树来表示。图1展示了这两棵schema tree。每个节点记录一个字段,该字段由key的名称及其值的类型组成。
这和时间线的定义不太一样,时间线是将一组tagkey=tagvalue作为一个独立的所谓schema,也就是tdengine的子表概念。
本文中实际使用key的组合来标识一个schema,这样做在半结构化转结构化来说没有任何问题,很trick。
Schema Variation

JSON的Schemaless的特征意味着records之间的模式变化范围可以从0%(即所有records具有相同的schema)到100%(即所有schema都不同)。
上图展示了每个数据集的独特schema。除两个数据集外,所有数据集都有不止1种独特schema,其中LogE的变化最大(6176种独特schema)。所有数据集的独特schema中位数为40。
尽管存在较大程度的差异,但也存在较大程度的重复。平均而言,每个具有相同模式的数据集中有25000条记录;如果增加样本量,这种重复程度会更大。即使是噪声最大的数据集LogE,每个模式平均仍有162条记录。
为了理解Schema Variation,论文进一步衡量单个key的变化情况。上图还展示了每个数据集的唯一key数量。当且仅当两个key的全名和值类型都相同时,才被视为相同的key。一个key的全名包括所有嵌套键(即在模式树中的前驱节点)。例如,“serviceA.traceID” 是全名,而 “traceID” 不是。唯一键的中位数为138,且变化幅度很大。LogM只有20个唯一键(并且只有1种模式),而Spark日志有5627个唯一键。
这一结果表明Schema Variation是由于variation of individual keys,而非它们的组合效应。理论上,schema的巨大变化可能是少数几个key的结果:n个唯一key可以产生2n2^n2n 种不同的组合,从而产生 2n2^n2n 种模式。然而在21个数据集中,有18个数据集的唯一键数量大于模式数量,这与组合效应相反。
论文中还讨论了KF( key frequency),

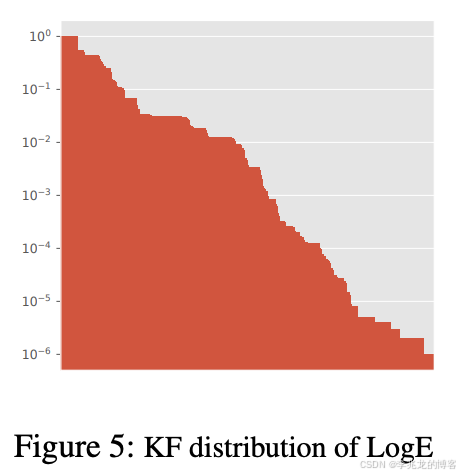
上图以LogE为例展示了KF的分布情况。每个柱状图代表一个key。LogE有6176个模式和704个键。
- 有少数(21个)键具有KF=1.0,这表明它们出现在每条记录中。这些是日志记录库统一添加的键,如“时间戳”和“级别”。
- 83.0% 的键具有KF <0.1。其中大多数是程序中不同的数据结构,这些数据结构记录了与特定事件相关的程序状态。
也存在这样的情况,即schema的变化是由key名称的巨大差异导致的,比如Spark使用路径名作为键名,或者一些数据集使用通用UUID作为键名。
以上观察符合预期的,因为每一个日志点所需的指标可能是完全不同的。
Type Composition
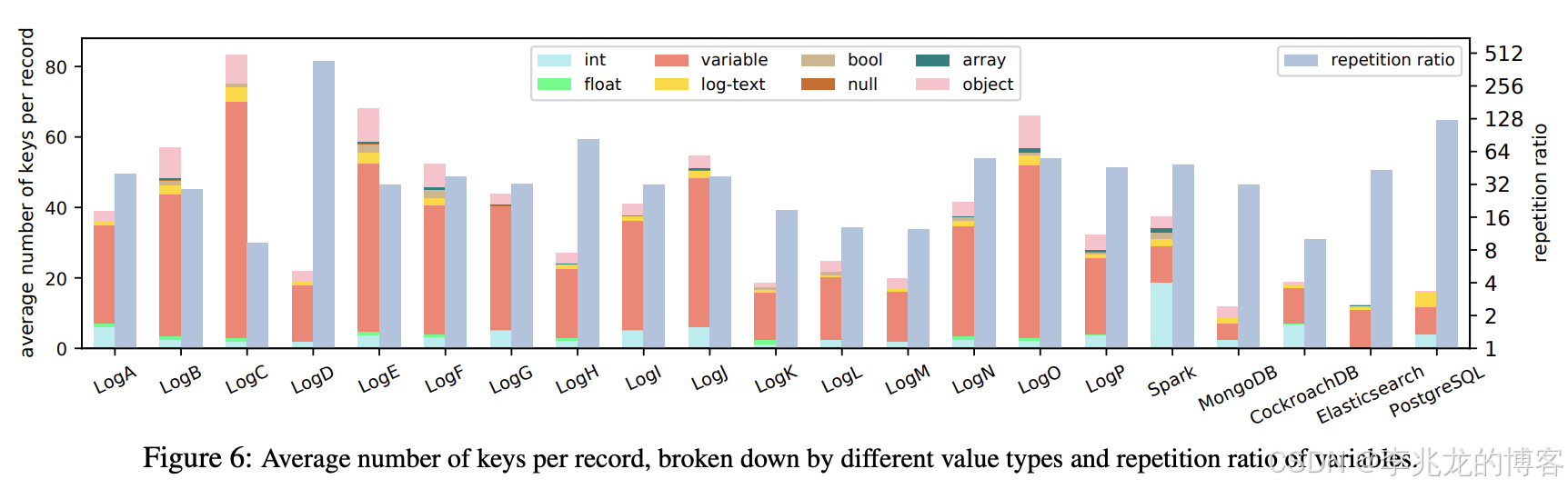
论文中还对值类型进行细分。值类型可以是对象、数组或基本类型之一。论文中进一步细化类型如下。
- 将数字类型细分为整数和浮点数。
- 对于字符串,我们将单字词值与多字词值分开(使用空格作为单词分隔符),因为前者很可能是一个变量(例如,标识符),而后者是自由文本日志
上图展示了每个数据集中值类型的细分情况。
- 每个数据集中70.8% 的值是单字符串。10.8% 是对象,即在模式树中通向嵌套键的非叶节点。相比之下,布尔值、浮点数、空值的占比很低,平均分别为1.74%、1.21%、0.22%。
- 数组字段的占比也很低,仅为0.79%。此外,在7665个查询中,只有28个(0.4%)明确针对数组字段进行搜索。而且,这些明确的数组搜索平均仅匹配0.05%的数据。
- 每条日志记录平均包含1.6个日志文本key。此外,41%的唯一查询包含对日志文本的筛选条件,因此对日志文本进行高效搜索非常重要。
- 一条记录平均包含4.0个整数字段。
Repetitiveness of Variables
单个单词的字符串在日志构成中占主导地位:这些值是否具有重复性?
图6展示了重复率。所有数据集的重复率中位数为37.8,平均值为58.2。重复率最高可达433.4(LogD),甚至最小值仍为9.29(LogC)。这意味着字典去重可能会有效果。
Variables也经常被查询。平均每个查询包含3.450个过滤器,其中2.663个是Variables。例如,level:“warn” OR level:“error”是一个对level键有两个字符串过滤器的查询。最大的查询有93个字符串过滤器。
此外通配符在实际应用中很常见。例如,*:“aUUID” 匹配任何键,只要其值为 “aUUID”。在7665个独特查询中,有2271个包含通配符键。这些过滤器对搜索用户来说更容易表达,但会带来严重的性能风险。在最坏的情况下,此类过滤器可能会对整个记录进行扫描,从而大大削弱查询结构化数据的优势。然而,使用字典来存储变量将显著加快此类查询的速度,因为我们只需要在字典中搜索匹配的值。
Importance of Schema Search
近三分之一(29%)的查询与任何schema结构都不匹配。也就是说,无需扫描值即可返回这些查询结果。示例包括
- 搜索不存在的键
- 键存在但值类型不匹配
- 键/值类型的组合不存在。
例如,工程师会定期验证某些错误事件是否不存在。
设计启示
- 83.0% 的键KF < 0.1,仅将关系型数据库管理系统(RDBMS)简单扩展为仅将那些结构化的键具体化为列是不够的,需要精确跟踪半结构化数据的模式
- 大量记录具有相同的模式,这为按相同模式对它们进行分组提供了机会
- 70.8% 的键是单字字符串。它们具有高度重复性,并且经常被查询。这表明将它们存储在变量字典中可以有效地对其进行去重,同时加快搜索速度。
- 高效地存储模式结构并将其与记录值数据解耦,将显著加快29%仅通过查询模式结构即可完成的查询的速度
µSlope
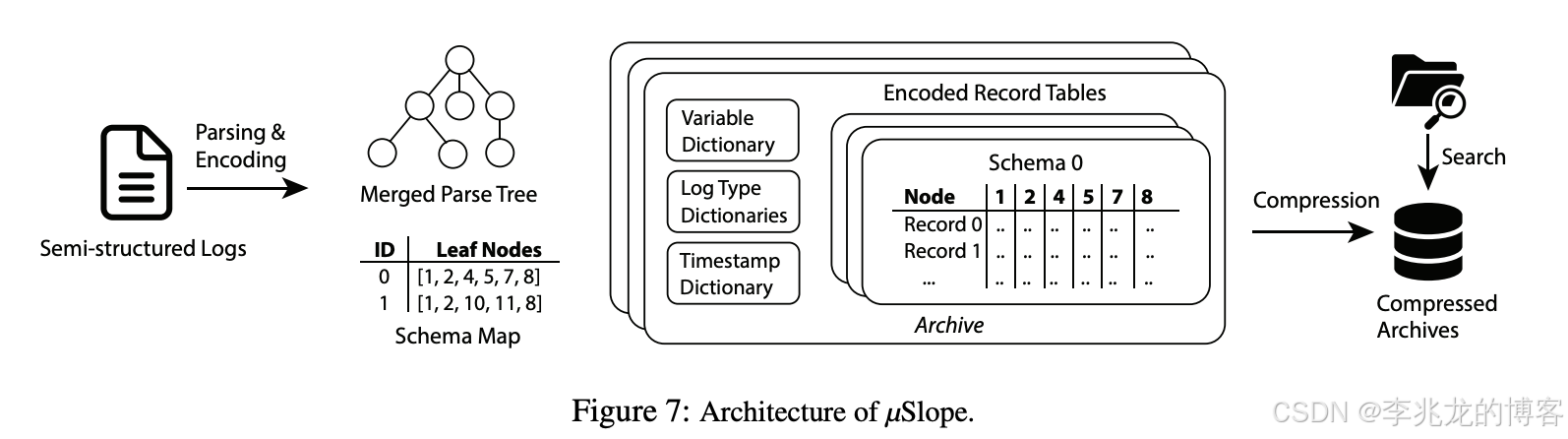
上图展示了µSlope的架构。在写入数据时,µSlope会解析每条record并提取其schema。它使用两种核心数据结构来跟踪模式结构:
- MPT(Merged Parse Tree):
- Schema Map
MPT和Schema Map 统称为模式元数据。尽可能减小模式元数据的大小至关重要,但同时仍需捕捉日志中高度重复的结构。
MPT 是MST的通用形式,与 MST 相比,它有四个不同之处:
- 可以包含特殊的unnamed nodes,用于标记某些键值对的截断。当键名包含随机数据(如 UUID 或文件路径)时,多个键可以映射到同一个未命名节点。包含此类非重复键名会使元数据膨胀。这就是一个经典的降维操作
- 有时一个键的值可能高度重复。例如,来自同一应用程序的所有记录在 application - name 键下都会有相同的值。此时MPT 还允许一个节点包含值(仅当该值高度重复时)
- 可以使用键值对编码字符串的结构。这使得µSlope能够从字符串中捕获更多的结构信息,从而提升压缩和搜索性能。例如,对于记录{… “message”: “… latency=35, status=OK, type=READ, …”},µSlope会分别为“latency”、“status”和“type”创建三个节点,作为“message”键的子节点
- MPT存储更细粒度的字符串类型。字符串值可以是时间戳、单字词字符串或日志文本。存储细粒度类型,在MPT上提供了更多过滤机会,从而提升搜索性能。
Schema Map将日志数据集中的每个唯一Schema存储在哈希表中。一个schema可以通过MPT中的叶节点列表明确识别。例如,图7中的模式映射展示了图1中两条记录的两种模式,其中节点ID与图2所示的MST相对应。
μSlope 利用元数据和字典查找的效率来优化搜索性能。它使用 Kibana 查询语言 (KQL) 作为查询语言,将查询转换为AST以执行一系列优化,包括确定查询是否与任何模式匹配以及过滤模式是否与任何字典值匹配。如果不匹配,μSlope 将提前终止查询处理。否则,最终只解压缩并搜索相关的 ERT。
压缩和搜索都是高度并行的。在压缩过程中,当解析新记录时,μSlope 会提取每个日志记录的键值对。相应的键节点被添加到 MPT 中,叶节点 ID 统称为一个schema。值通过各种方法编码并存储在 ERT 中。
结语
很深入的观察,发现Semi-Structured Logs可以通过对schema分组,而不是传统思路按照时间线分组,这种思路对于日志场景非常有帮助,其实非结构化日志也可以通过分词后使用这种方案。
真正的关键点在于对唯一Schema和KF的业务洞察,得到了这种结论:
- 唯一Schema数量有限,可以基于此方案分组
- 83.0% 的键具有KF <0.1,简单的把所有的列归一化到一个schema中会造成巨大的元数据浪费(宽列)和空值存储。