【2025CVPR-扩散模型方向】TKG-DM:免训练的色度关键内容生成扩散模型
一、研究背景与问题
- 现有模型局限性
主流扩散模型(如Stable Diffusion、DeepFloyd)难以生成前景物体置于纯色背景(如绿幕) 的图像,导致前景与背景无法分离,需额外微调或后处理。 - 现有解决方案缺陷
- MAGICK:依赖提示工程与人工后处理,背景精度不足。
- LayerDiffuse:需微调百万级数据集(未公开),资源消耗大。
二、核心创新:TKG-DM方法
提出无需训练的扩散模型优化方案,通过操控初始噪声实现前景与纯色背景分离:
- 通道均值偏移(Channel Mean Shift)
- 原理:调整初始噪声张量 zT∈Rh×w×4 各通道均值,控制生成图像的色调。
- 计算目标:通过迭代调整偏移量 Δc,使通道正像素比例满足预设值:TargetRatioc=InitialRatioc+TargetShiftc
- 输出:生成单色背景噪声 zT∗=Fc(zT)。
- 原理:调整初始噪声张量 zT∈Rh×w×4 各通道均值,控制生成图像的色调。

- 噪声选择策略(Init Noise Selection)
- 高斯掩码融合:结合原始噪声 zT 与背景噪声 zT∗,生成最终输入噪声:zTkey(i,j)=A(i,j)⋅zT(i,j)+(1−A(i,j))⋅zT∗(i,j)
- A(i,j) 为高斯掩码,参数 (μi,μj,σ) 控制前景位置与尺寸。
- 多前景支持:通过多个高斯掩码生成复杂场景。
- 高斯掩码融合:结合原始噪声 zT 与背景噪声 zT∗,生成最终输入噪声:zTkey(i,j)=A(i,j)⋅zT(i,j)+(1−A(i,j))⋅zT∗(i,j)
三、关键技术机制
- 背景颜色控制
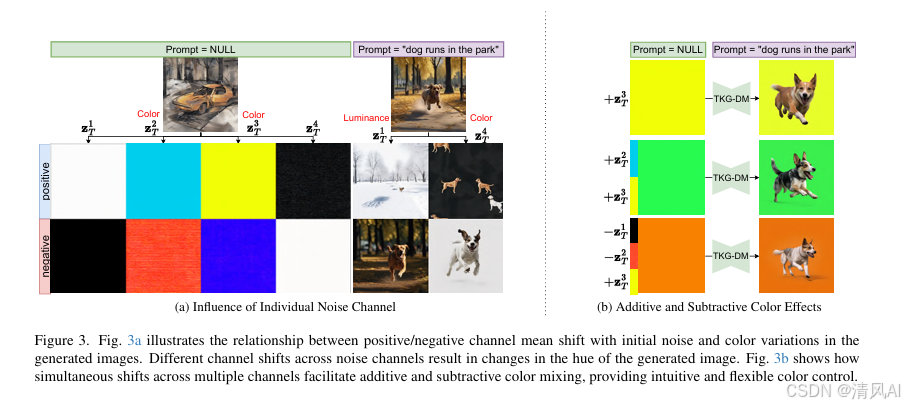
- 通道偏移方向与颜色映射(如图3):
- 通道2(+)→ 青色,通道3(+)→ 黄色。
- 多通道组合实现混合色(如通道2+3→绿色)。
- 通道偏移方向与颜色映射(如图3):
- 前景-背景分离原理
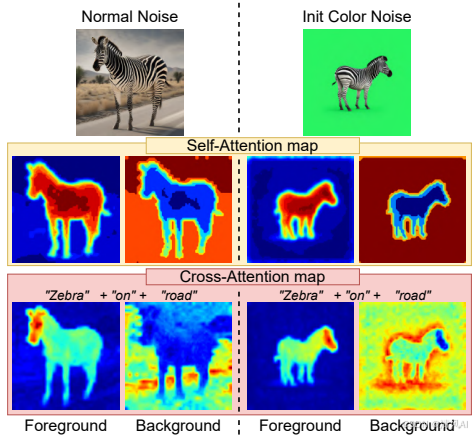
- 自注意力机制:维持前景内部一致性。
- 交叉注意力机制:将文本提示与前景强关联(训练数据偏置)。
- 背景生成:初始背景噪声主导,弱化文本干扰。
四、实验结果
- 评估指标
- FID(图像质量)、m-FID(掩码精度)、CLIP-I/S(语义对齐)。
- 性能对比
- 定性结果(图5、图6):

 TKG-DM生成纯净背景,无提示工程需求。
TKG-DM生成纯净背景,无提示工程需求。- 基线模型(SDXL+GBP)出现背景伪影与前景染色。
- 定量结果:
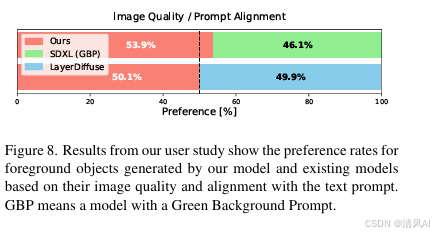
模型 FID (↓) m-FID (↓) CLIP-I (↑) CLIP-S (↑) SDXL (GBP) 45.32 39.17 0.759 0.272 LayerDiffuse 29.34 29.82 0.778 0.276 TKG-DM 41.81 31.43 0.763 0.273 - 用户研究(图8):80%用户偏好TKG-DM的前景质量与文本对齐性。
- 定性结果(图5、图6):
五、应用扩展
- ControlNet集成
- 支持边缘图等条件输入,精准控制前景结构(图9)。
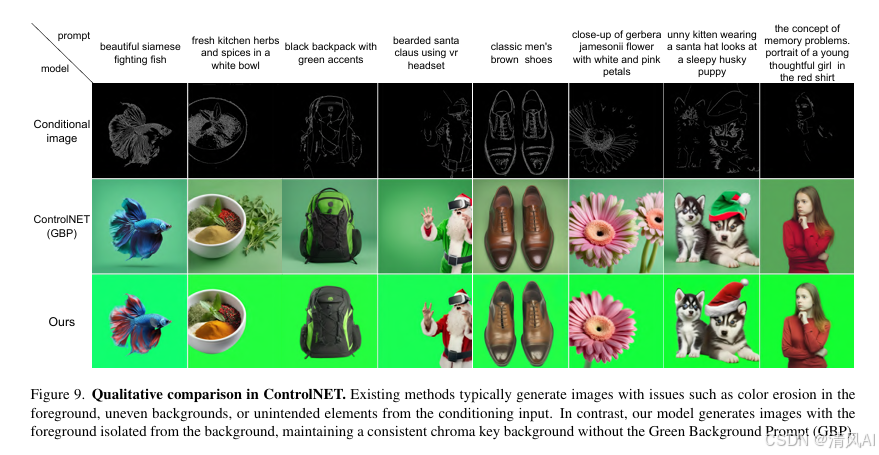
- 支持边缘图等条件输入,精准控制前景结构(图9)。
- 布局感知生成
调整高斯掩码参数控制前景位置与尺寸(图10)。

3. 文本→视频生成
结合AnimateDiff生成背景一致的视频序列。
4. 一致性模型适配
在少步生成中保持高性能。
六、局限性与未来方向
- 当前限制
- 无法生成复杂背景(如风景)。
- 极小前景物体易丢失(图11)。
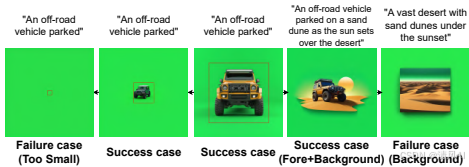
- 未来改进
- 支持背景独立生成与动态控制。
- 优化多物体微尺度生成。
七、总结
TKG-DM是首个通过初始噪声色彩操控实现免训练绿幕生成的方法:
- 核心价值:无需微调/数据集,支持背景色、布局、多前景的精确控制。
- 性能优势:在FID/m-FID上提升超33%,媲美微调模型。
- 应用潜力:广告设计、游戏开发、视频编辑等需前景分离的场景。
论文地址:https://openaccess.thecvf.com/content/CVPR2025/papers/Morita_TKG-DM_Training-free_Chroma_Key_Content_Generation_Diffusion_Model_CVPR_2025_paper.pdf