MYSQL:索引
文章目录
- MYSQL:索引
- 1. 本文简述
- 2. 索引是什么?
- 2.1 一个形象的比喻:书的目录
- 2.2 为什么需要索引?
- 3. 索引背后的数据结构选型
- 3.1 方案一:哈希表 (Hash Table)
- 3.2 方案二:二叉搜索树 (Binary Search Tree)
- 3.3 方案三:N 叉树 (B-Tree)
- 3.4 最终选择:B+ 树 (B+ Tree)
- 3.4.1 B+ 树的核心特点
- 3.4.2 B+ 树与 B 树的关键对比
- 4. B+ 树在 MySQL 中的物理载体:页 (Page)
- 4.1 为什么需要“页”?
- 4.2 页的内部结构:宏观视角
- 4.3 页的内部结构:数据行与行链表
- 4.4 页内查找的加速器:页目录 (Page Directory)
- 4.5 数据页头 (Page Header)
- 5. B+ 树与页的协同工作
- 5.1 B+ 树的存储能力估算
- 6. 索引的分类
- 6.1 从功能角度划分
- 主键索引 (Primary Key Index)
- 普通索引 (Normal Index)
- 唯一索引 (Unique Index)
- 全文索引 (Full-text Index)
- 6.2 从物理存储角度划分 (InnoDB)
- 聚集索引 (Clustered Index)
- 非聚集索引 (Non-Clustered Index)
- 6.3 重要的查询优化概念:回表与索引覆盖
- 回表查询 (Bookmark Lookup)
- 索引覆盖 (Covering Index)
- 7. 索引的创建与管理
- 7.1 索引的创建方式
- 方式一:自动创建
- 方式二:手动创建
- 7.2 查看索引信息
- 7.3 验证索引是否生效:`EXPLAIN`
- 7.4 删除索引
- 删除主键索引
- 删除其他索引(普通/唯一)
- 7.5 创建索引的核心原则
MYSQL:索引
1. 本文简述
- 理解索引的核心概念
- 了解索引底层所使用的数据结构
- 掌握 B+ 树在 MySQL 索引中的具体应用
- 熟悉索引的分类并掌握其使用方法
2. 索引是什么?
2.1 一个形象的比喻:书的目录
在正式介绍技术概念之前,我们不妨从一个熟悉的场景开始:查字典。一本厚厚的字典,我们之所以能快速找到想要的字,正是因为有目录的存在。无论是按拼音、按部首还是按笔画,目录都为我们提供了直达目标的“快捷方式”。
MySQL 中的“索引”就扮演着类似的角色。它本质上是一种特殊的数据结构,能够帮助数据库系统高效地组织和检索数据。通过为表中的记录建立索引,查询操作就不再需要逐行扫描整个数据表,而是可以直接通过索引快速定位到目标数据,从而极大地提升查询速度。
小思考
不同的目录(拼音、部首)对应不同的查找规则,其背后是不同的组织方式。同样,在数据库中,索引也可以基于不同的数据结构和算法来实现,这些选择将直接影响其查询效率,也就是我们常说的“时间复杂度”和“空间复杂度”。
2.2 为什么需要索引?
答案很明确:为了提升数据检索的效率。在一个典型的应用程序中,数据查询(SELECT)的频率通常远高于增加(INSERT)、删除(DELETE)和修改(UPDATE)的频率。因此,优化查询性能是数据库设计的重中之重,而索引正是实现这一目标的关键手段。
3. 索引背后的数据结构选型
既然索引如此重要,那么它在底层应该用什么样的数据结构来实现呢?这是一个很有趣的问题,也是理解索引工作原理的关键。让我们来一步步探讨几种备选方案。
3.1 方案一:哈希表 (Hash Table)
哈希表以其 O(1) 的平均时间复杂度著称,查询速度极快。但 MySQL 并没有选择它作为索引的默认数据结构。最核心的原因在于,哈希表不支持范围查找。它只能高效地处理等值查询(例如 WHERE id = 100),而无法应对像 WHERE id > 50 这样的范围查询,这在实际业务中是致命的缺陷。
3.2 方案二:二叉搜索树 (Binary Search Tree)
二叉搜索树的中序遍历结果是一个有序序列,似乎很适合做索引。但它存在两个严重问题:
- 树的深度不可控: 在最坏的情况下,如果插入的数据是依次递增或递减的,二叉搜索树会退化成一个链表,查询时间复杂度将恶化到 O(n)。
- I/O 成本高: 树的深度直接关系到磁盘 I/O 的次数。
小思考
即使是像 AVL 树或红黑树这样的自平衡二叉树,虽然解决了退化成链表的问题,但它们本质上仍然是“二叉”的。这意味着当数据量巨大时,树的高度依然会非常可观。在数据库系统中,性能最大的瓶颈之一就是磁盘 I/O。数据是存储在磁盘上的,每次从磁盘读取一个节点到内存,就是一次 I/O 操作。树越深,意味着从根节点到叶子节点需要经历的 I/O 次数就越多。因此,我们的优化目标非常明确:必须有效控制树的高度,从而减少 I/O 次数。
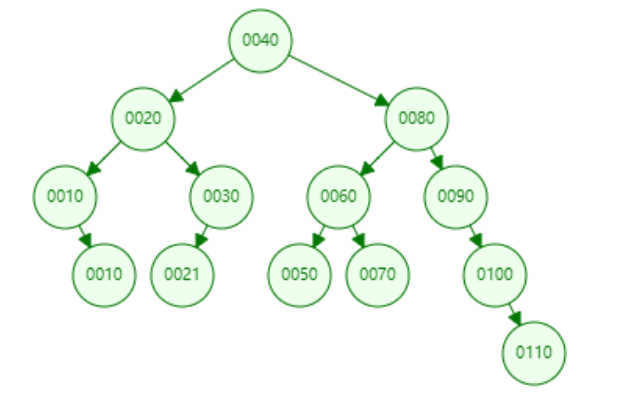
3.3 方案三:N 叉树 (B-Tree)
为了解决树高的问题,一个自然的想法是:让每个节点拥有更多的子节点,从“二叉”变成“N叉”。这样,树就从“高瘦”变得“矮胖”了。对于同样多的数据,N 叉树的高度会远远小于二叉树,从而显著减少查询时的 I/O 次数。这已经很接近我们的理想模型了,但 MySQL 觉得还可以更进一步。
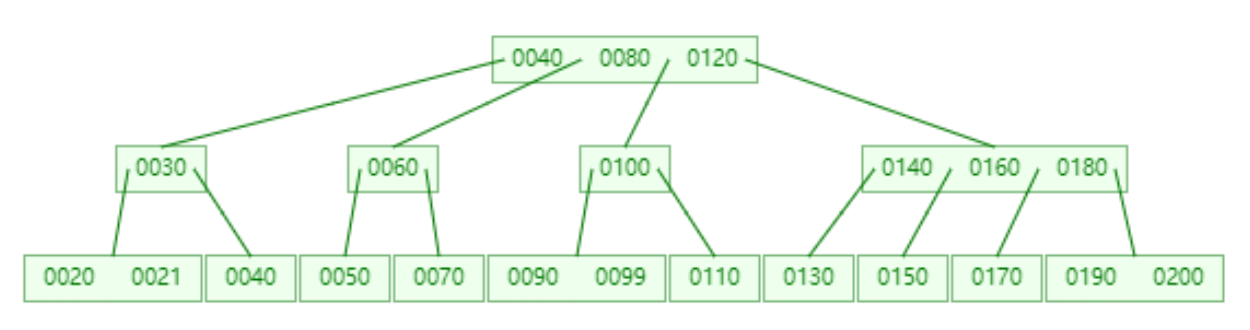
3.4 最终选择:B+ 树 (B+ Tree)
B+ 树是 B 树的一种优化变体,也是 MySQL InnoDB 存储引擎最终采用的数据结构。它在数据库和文件系统中被广泛应用。下面是一个 4 阶 B+ 树的示意图:

3.4.1 B+ 树的核心特点
- 数据稳定有序: 能够保持键值的有序性,并且在插入和修改后,通过分裂、合并等操作维持树的平衡,确保查询性能的稳定性。
- 非叶子节点只存索引: 这是与 B 树最大的不同之一。B+ 树的非叶子节点(内节点)只存储键值和指向下一层节点的指针,不存储实际的数据记录。这使得单个节点可以容纳更多的键值,从而进一步降低树的高度。
- 所有数据都在叶子节点: 所有的真实数据记录都存储在叶子节点上。
- 叶子节点形成有序链表: 所有的叶子节点通过指针相互连接,形成一个有序的双向链表。这个特性使得 B+ 树在进行范围查询时极为高效,可以直接在叶子节点层级上进行遍历。
3.4.2 B+ 树与 B 树的关键对比
- 范围查询更高效: B+ 树的叶子节点是连续且相互链接的,进行范围查找时,只需定位到范围的起始点,然后沿着链表顺序遍历即可,无需像 B 树那样进行中序遍历。
- 查询性能更稳定: 因为所有数据都存储在叶子节点,所以任何一次查询都必须从根节点走到叶子节点,查询路径的长度是固定的。这使得 B+ 树的查询性能非常均衡和稳定。
- 空间利用率更高: 非叶子节点不存储数据,可以存放更多的索引键,使得树更“矮胖”,I/O 次数更少。
4. B+ 树在 MySQL 中的物理载体:页 (Page)
我们已经知道 B+ 树是索引的逻辑结构,那么它在磁盘上是如何存储的呢?这就引出了一个至关重要的概念:页 (Page)。
4.1 为什么需要“页”?
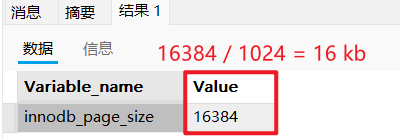
在 InnoDB 存储引擎中(数据通常存储在 .ibd 文件里),页是内存与磁盘进行数据交互的最小单元。默认情况下,一个页的大小是 16KB。这意味着,每当 MySQL 需要从磁盘读取数据时,它不会只读取需要的一行记录,而是一次性读取至少 16KB 的数据块到内存中。
这么做的理论基础是计算机科学中著名的 “局部性原理”:
- 时间局部性 (Temporal Locality): 如果一个数据项正在被访问,那么在不久的将来它很可能被再次访问。
- 空间局部性 (Spatial Locality): 如果一个数据项正在被访问,那么与它相邻的数据项也很可能即将被访问。
通过一次性加载一整页的数据,当后续操作需要访问同一页内的其他数据时,就可以直接从内存中快速获取,从而大大减少了昂贵的磁盘 I/O 次数,有效提升了性能。
核心关联
B+ 树的一个节点,就对应着磁盘上的一个页。 每一个页,即使没有存满数据,也会占用 16KB 的存储空间。我们可以通过以下命令查看当前数据库的页大小:
SHOW VARIABLES LIKE 'innodb_page_size';
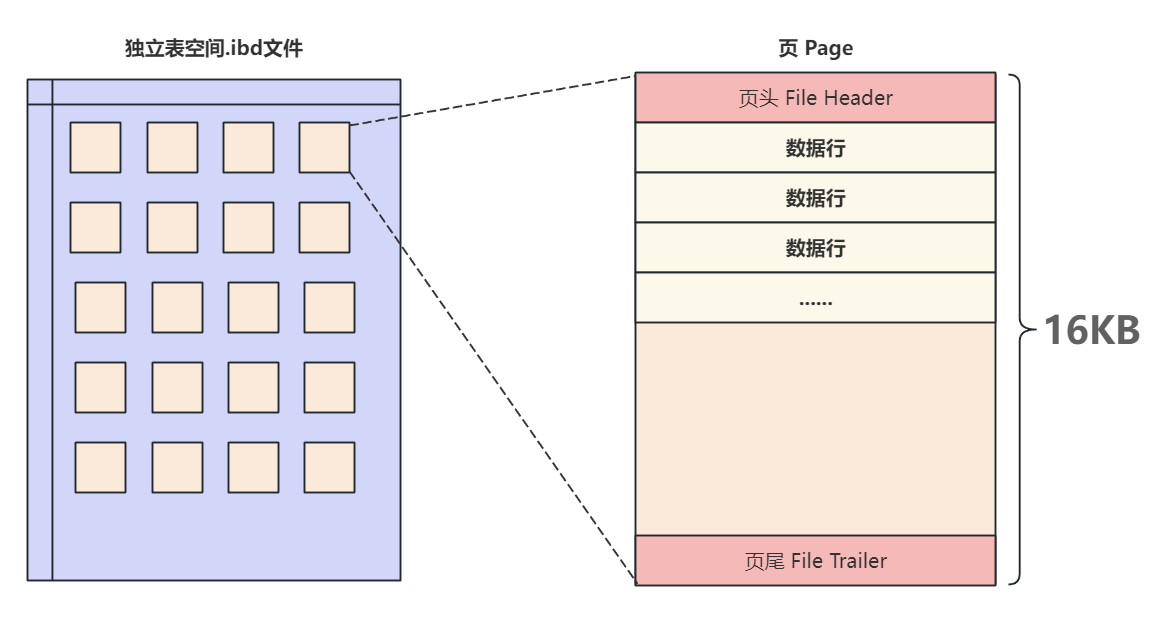
MySQL 中有多种类型的页,我们最关心的是用于存储索引和数据的“索引页”(也称“数据页”)。无论哪种页,其内部结构都遵循一定的规范,主要由页头、页尾和中间的数据行区域组成。
补充说明
当我们为每张表使用独立表空间时(这是默认设置),每张表的数据和索引都会保存在一个独立的.ibd文件中。
4.2 页的内部结构:宏观视角
从宏观上看,一个页主要包含以下部分,其中页头和页尾的信息帮助我们将各个页组织起来。
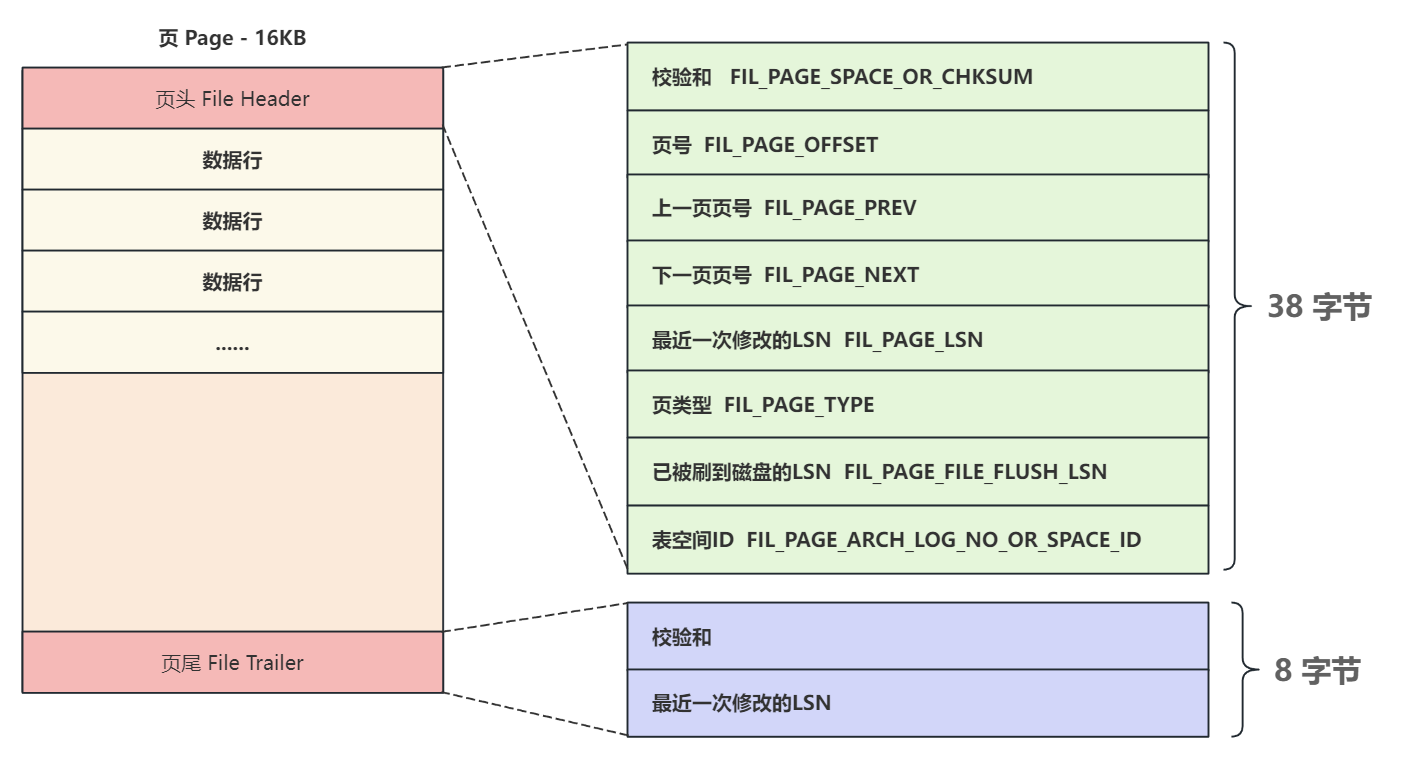
- 文件头 (File Header): 记录了页的通用信息,比如页号、上一页和下一页的页号等。
- 页主体 (Page Body): 存放实际的数据记录(行)。
- 文件尾 (File Trailer): 包含校验信息,用于确保页数据的完整性。
通过文件头中的“上一页”和“下一页”指针,所有的数据页被链接成一个双向链表,这对于实现 B+ 树叶子节点的有序链接至关重要。
小思考
知道了页号和页大小(16KB),我们就可以计算出任何一页在磁盘文件中的物理偏移量,从而实现精确定位。
4.3 页的内部结构:数据行与行链表
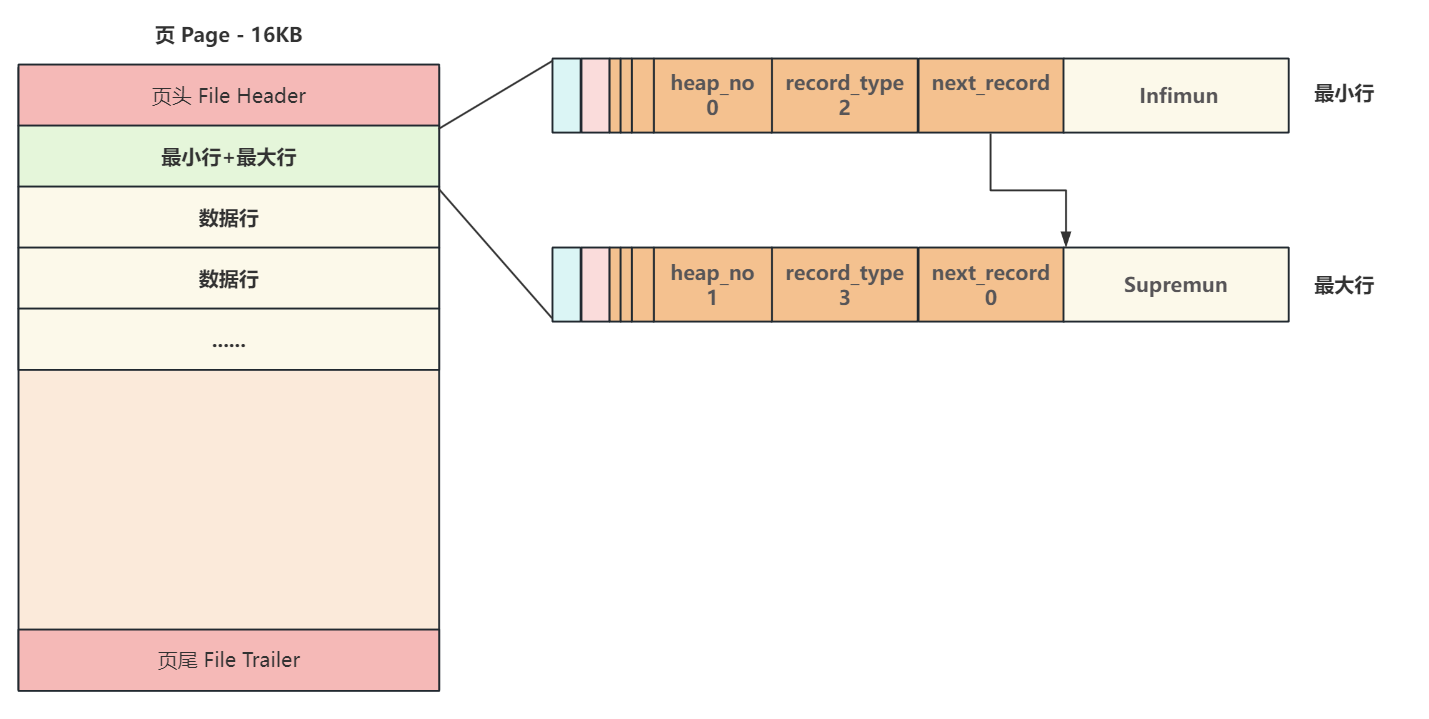
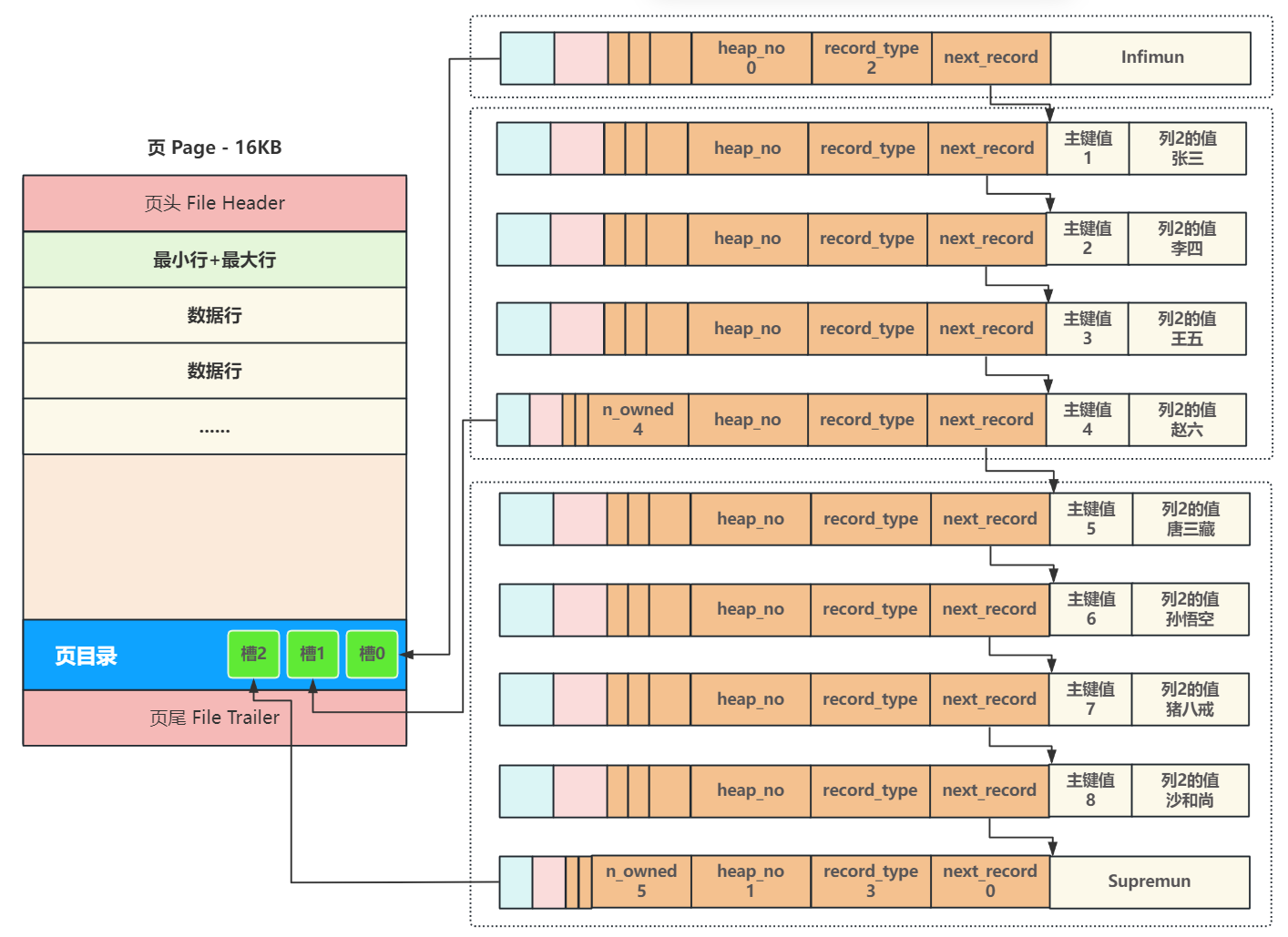
页的主体部分是保存真实数据的主要区域。一个新创建的页会包含两个特殊的“伪记录”:
Infimum记录:代表页内的“最小值”。Supremum记录:代表页内的“最大值”。
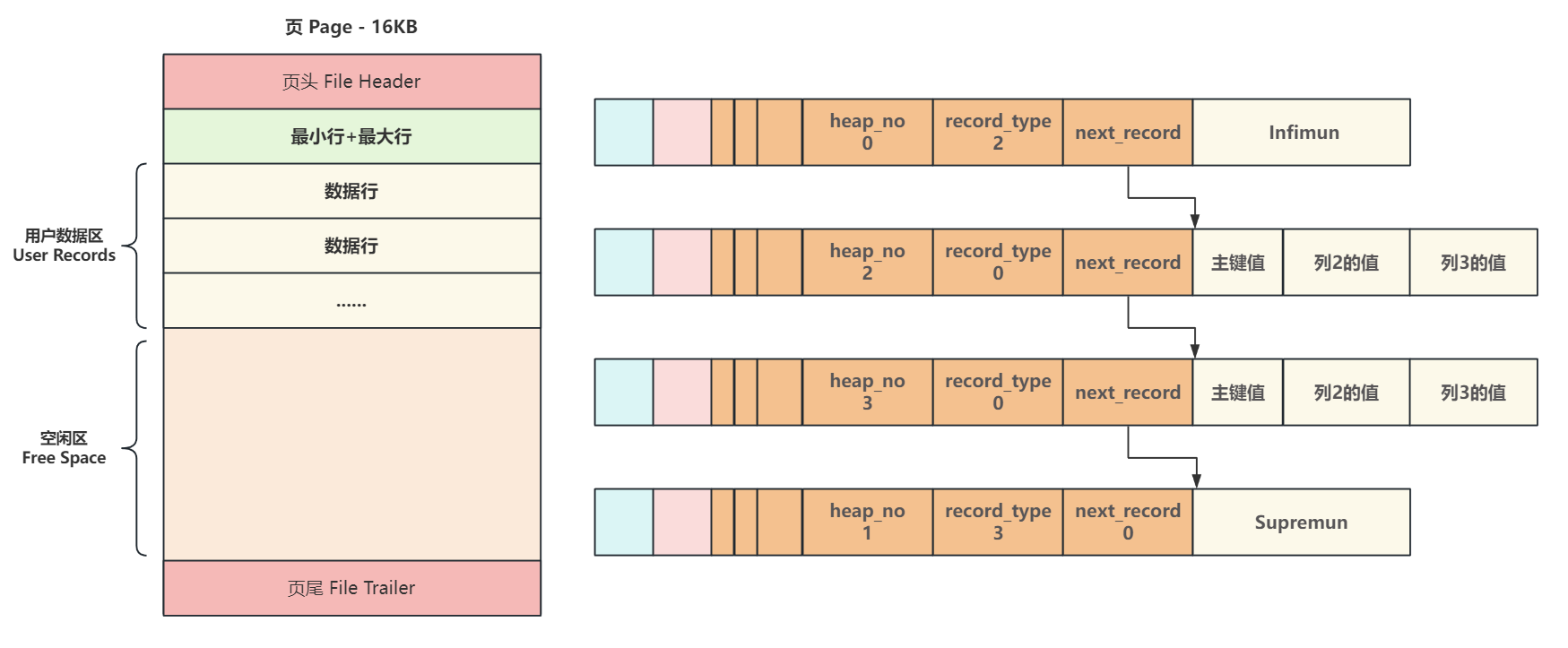
它们不存储真实数据,而是作为页内数据行链表的哨兵节点(头和尾)。当新数据行插入时,它们会按照主键从小到大的顺序,通过 next_record 指针链接起来,形成一个单向链表。
随着数据行的不断插入,这个链表会保持有序。
4.4 页内查找的加速器:页目录 (Page Directory)
如果要在页内查找某条记录,沿着单向链表逐个比较显然效率太低(一个 16KB 的页可能存放数百行数据)。为了解决这个问题,InnoDB 在页内引入了 页目录 (Page Directory) 的设计,实现了页内的“二分查找”。
它的工作方式如下:
- 分组: 将页内的所有行(包括
Infimum和Supremum)进行分组。Infimum记录自成一组,Supremum和它之前的 1 到 8 条记录成为一组,其他行则是每 4 到 8 条为一组。 - 创建槽 (Slot): 页目录由多个“槽”组成。每个槽存储对应分组中“最大记录”的地址偏移量。
- 二分查找: 当需要在页内查找时,首先通过对页目录中的槽进行二分查找,快速定位到记录所在的分组。
- 组内遍历: 然后在确定的小分组内(最多8条记录),再进行链表遍历,找到目标记录。
通过“页目录二分查找 + 组内遍历”的两步法,极大地提升了在单个数据页内部的查找效率。
[查找流程总结]
- 通过 B+ 树(跨页查找)定位到记录所在的页。
- 在页内通过页目录(页内查找)定位到记录所在的槽(分组)。
- 在分组内遍历链表找到最终的记录。
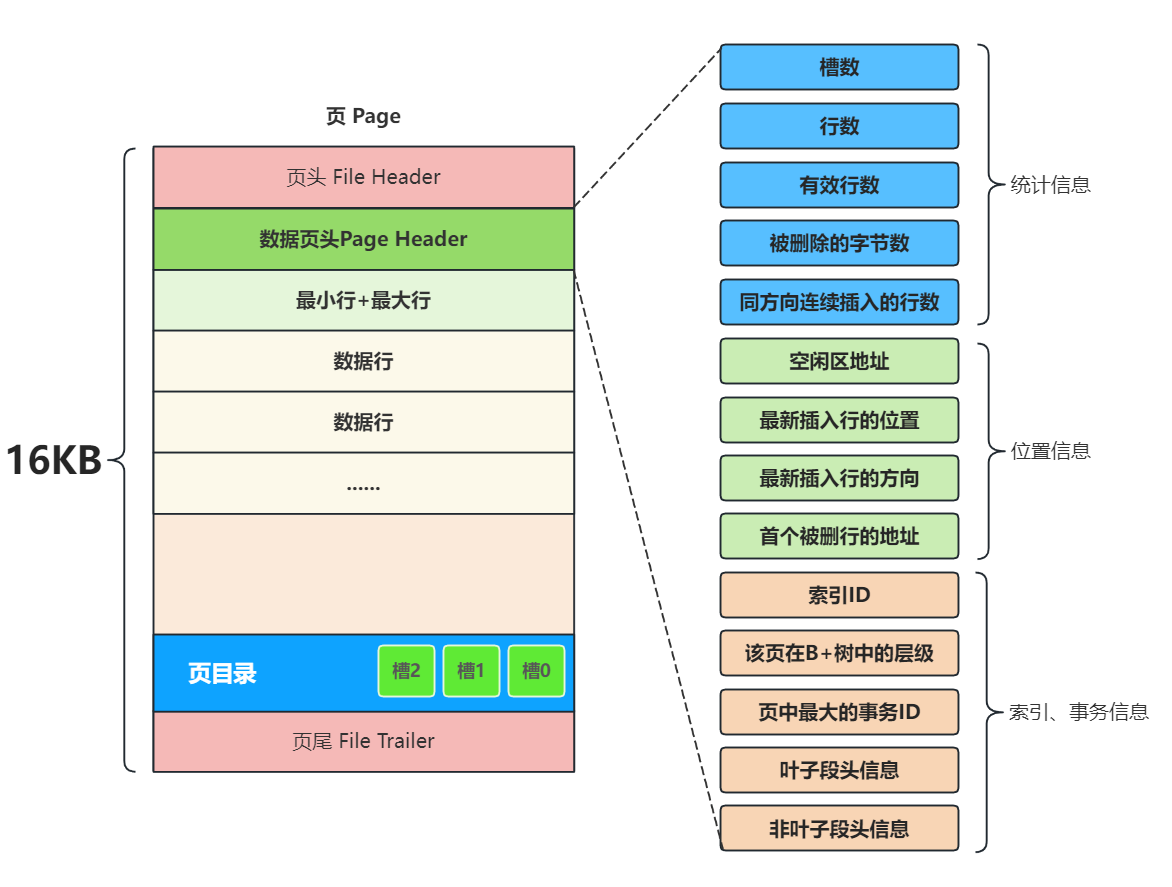
4.5 数据页头 (Page Header)
除了文件头,页内还有一个数据页头,专门记录与数据存储相关的信息,例如页目录中的槽数量、第一个记录的地址等。
5. B+ 树与页的协同工作
现在,我们将 B+ 树的逻辑结构和页的物理结构结合起来,看看它们是如何在 MySQL 中协同工作的。
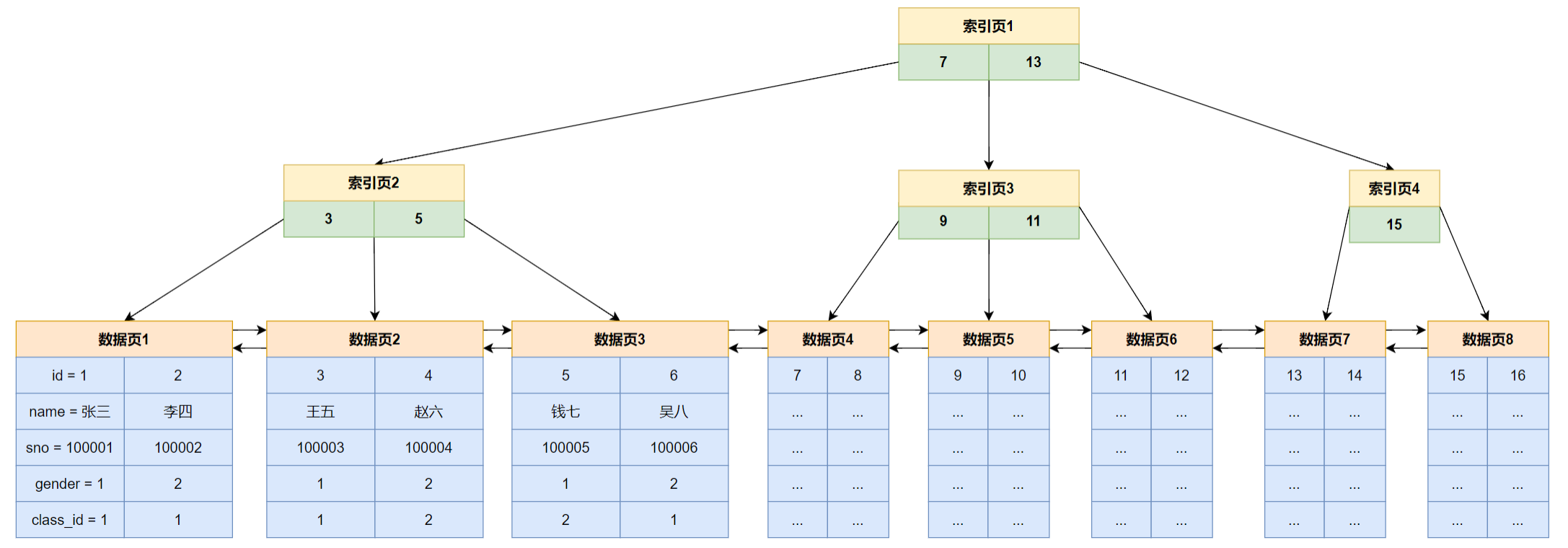
- 非叶子节点(索引页): B+ 树的非叶子节点,其物理载体是“索引页”。这种页只存储两样东西:键值(例如主键 ID)和指向下一层节点的指针(页号)。
- 叶子节点(数据页): B+ 树的叶子节点,其物理载体是“数据页”。这种页存储了完整的行记录。
[自动创建]
只要我们为表定义了主键,InnoDB 就会自动为它创建一个 B+ 树索引(也就是聚集索引)。
小思考
- 页与页之间通过页号建立起父子或兄弟关系,最终构成了完整的 B+ 树。
- 叶子节点(数据页)通过双向指针链接,形成了有序的双向链表。
- 所有对页的访问和操作,都是先将页从磁盘加载到内存的缓冲池(Buffer Pool)中进行的,以提升性能。
我们以查找 id 为 5 的记录为例,完整的检索过程如下:
- 第一次 I/O: 从磁盘加载根节点(图中的页 1)到内存。在页 1 内通过二分查找,发现
5 < 7,因此需要访问其左子节点,得到下一层的页号为 2。 - 第二次 I/O: 从磁盘加载索引页 2 到内存。在页 2 内进行查找,定位到键值为 5 的条目,并获取其指向的数据页号为 3。
- 第三次 I/O: 从磁盘加载数据页 3 到内存。在页 3 内通过页目录查找到
id为 5 的完整行记录。
至此,查询完成。整个过程只涉及三次磁盘 I/O。
5.1 B+ 树的存储能力估算
我们来做一个有趣的估算:一棵三层高的 B+ 树大概能存放多少条记录?
- 数据页容量: 假设一条完整的用户记录大小为 1KB。一个数据页(16KB)在除去页头等固定开销后,大约可以存放
16KB / 1KB = 16条记录。 - 索引页容量: 索引页只存放主键和指针。假设主键是
BIGINT类型(8 字节),指针(页号)大小为 6 字节,那么一条索引条目大约占用8 + 6 = 14字节。一个索引页(16KB)可以存放的索引条目数量约为16 * 1024 / 14 ≈ 1170条。 - 总容量计算:
- 根节点(第 1 层)是一个索引页,可以指向 1170 个二级节点。
- 二级节点(第 2 层)是 1170 个索引页,每个又可以指向 1170 个叶子节点。
- 叶子节点(第 3 层)是数据页,每个可以存放 16 条记录。
- 因此,总记录数约为:
1170 (二级节点数) * 1170 (叶子节点数) * 16 (每页记录数) ≈ 21,902,400。
这个结果相当惊人:对于一个拥有超过两千万条记录的表,通过索引查询,最理想情况下只需要 3 次磁盘 I/O 就能定位到目标数据。这充分展现了 B+ 树索引的强大威力。
6. 索引的分类
在 MySQL 中,索引有多种类型,它们适用于不同的场景。理解这些分类有助于我们更合理地设计和使用索引。
6.1 从功能角度划分
主键索引 (Primary Key Index)
- 当我们在表上定义主键
PRIMARY KEY时,MySQL 会自动为该列(或列组合)创建一个主键索引。 - 主键索引既要求值唯一,也要求值非空。
- 在 InnoDB 中,主键索引是一种特殊的索引,它就是聚集索引(我们稍后会详细讨论)。
- 最佳实践: 强烈推荐为每个表都定义一个主键。如果业务上没有天然的唯一非空列,可以添加一个自增的
id列作为主键。
普通索引 (Normal Index)
- 这是最基本的索引类型,没有任何特殊限制(不要求唯一,允许为空)。
- 它的唯一作用就是加快查询速度。
- 如果一个索引包含了多个列,我们称之为复合索引或组合索引。
小思考
- 我们通常为需要频繁作为查询条件(
WHERE子句)、排序(ORDER BY)或分组(GROUP BY)的列创建普通索引。- 每一个索引都对应一棵独立的 B+ 树。 这意味着创建的索引越多,占用的磁盘空间就越大。
- 更重要的是,当对表进行增、删、改操作时,不仅要修改数据,还需要同步维护相关的索引树,这会带来额外的性能开销。因此,索引并非越多越好,需要权衡利弊,按需创建。
唯一索引 (Unique Index)
- 当我们在表上定义唯一约束
UNIQUE时,会自动创建一个唯一索引。 - 它与普通索引类似,但增加了一个约束:索引列的值必须是唯一的(允许存在多个
NULL值,但在大多数数据库实现中,NULL值本身也被视为一个特殊的值,通常只允许出现一次)。
全文索引 (Full-text Index)
- 专门用于在文本内容(
CHAR,VARCHAR,TEXT列)中进行关键词搜索的索引。 - 它不同于常规的
LIKE '%keyword%'匹配,能够提供更高效、更智能的文本检索能力(例如,处理分词)。 - 在 MySQL 中,只有 MyISAM 和 InnoDB 存储引擎支持全文索引。
6.2 从物理存储角度划分 (InnoDB)
在 InnoDB 存储引擎中,根据索引与数据行的物理存储关系,我们可以将索引分为两大类。这个概念非常重要。
聚集索引 (Clustered Index)
- 定义: 聚集索引的 B+ 树的叶子节点,直接存储了完整的用户数据行。可以理解为“索引和数据是在一起的”。
- 唯一性: 每张表只能有一个聚集索引。
- 选择规则: InnoDB 会按照以下顺序来选择聚集索引:
- 如果表定义了
PRIMARY KEY,则主键索引就是聚集索引。 - 如果没有主键,InnoDB 会选择第一个
UNIQUE且所有列都NOT NULL的索引作为聚集索引。 - 如果以上两者都没有,InnoDB 会在内部隐式地创建一个 6 字节的
ROW_ID字段,并用它作为聚集索引。
- 如果表定义了
非聚集索引 (Non-Clustered Index)
- 定义: 除了聚集索引之外的所有索引,都称为非聚集索引,也叫二级索引 (Secondary Index)。
- 结构: 非聚集索引的 B+ 树的叶子节点,存储的不是完整的数据行,而是索引列的值和该行对应的主键值。
6.3 重要的查询优化概念:回表与索引覆盖
回表查询 (Bookmark Lookup)
当我们使用非聚集索引进行查询时,通常会经历一个两步过程:
- 首先在非聚集索引的 B+ 树中查找到目标记录,从中获取到对应行的主键值。
- 然后拿着这个主键值,再到聚集索引的 B+ 树中去查找,最终定位到完整的行数据。
这个“先查二级索引,再查主键索引”的过程,就叫做回表查询。很显然,回表会增加额外的查询开销和 I/O 次数。
小思考
如何避免回表,提升查询效率呢?这就引出了“索引覆盖”的概念。
索引覆盖 (Covering Index)
- 定义: 如果一个查询语句,它所需要查询的所有列(即
SELECT列表中的列)恰好都能在某一个非聚集索引的 B+ 树中直接找到,那么数据库就无需再进行回表查询了。这种情况,我们就称之为实现了索引覆盖。 - 好处: 索引覆盖可以极大地减少磁盘 I/O,显著提升查询性能,是 SQL 优化的一个重要手段。
[复合索引与最左前缀原则]
假设我们有一个复合索引idx_name_sn(name, sn)。根据最左前缀原则,查询条件必须从索引的最左边列开始,并且不能跳过中间的列。
WHERE name = 'xxx'可以使用该索引。WHERE name = 'xxx' AND sn = 'yyy'可以使用该索引。WHERE sn = 'yyy'则无法有效利用该索引,因为跳过了name列。如果sn列的查询很频繁,我们应该考虑为它单独创建一个索引。
7. 索引的创建与管理
理论知识已经储备得差不多了,接下来,我们把目光投向实践,看看如何在 MySQL 中具体地创建和管理索引。
7.1 索引的创建方式
方式一:自动创建
在一些我们熟悉的操作中,MySQL 会默默地为我们创建好索引。这通常发生在我们为表添加某些约束时:
- 主键约束 (
PRIMARY KEY): 当我们指定一个主键时,MySQL 会自动为它创建一个主键索引。在 InnoDB 引擎中,这个索引就是我们前面提到的聚集索引。 - 唯一约束 (
UNIQUE): 当我们为某个列添加唯一约束时,一个唯一索引也随之被创建。 - 外键约束 (
FOREIGN KEY): 为了保证数据完整性和关联查询的效率,当我们定义一个外键时,MySQL 也会在外键列上自动创建一个普通索引。
深度解析:一个常见的误区
有一种说法是“如果表不指定任何约束,MySQL 会为每一列都生成一个索引”。这种理解其实是不准确的。真实情况是:在 InnoDB 存储引擎中,如果一张表既没有主键,也没有合适的唯一索引(非空),那么 InnoDB 会在内部隐式地创建一个名为
ROW_ID的 6 字节字段作为聚集索引的键。这个ROW_ID保证了行的唯一性,但它并不会导致 MySQL 为其他所有列都创建索引。这是一个为了保证 InnoDB 内部数据组织结构完整性的“兜底”策略。
方式二:手动创建
当然,更多时候我们需要根据实际的业务查询需求,主动地、有针对性地创建索引。手动创建索引主要有两种时机:
场景1:创建表的同时定义索引
我们可以在 CREATE TABLE 语句中,随着列定义一起声明好索引。
-- 在建表时,一次性定义好所有需要的索引
CREATE TABLE t_users (id BIGINT PRIMARY KEY AUTO_INCREMENT, -- 自动创建主键索引username VARCHAR(50) UNIQUE, -- 自动创建唯一索引email VARCHAR(100),city_id INT,-- 手动创建普通索引和复合索引INDEX idx_email (email), -- 为 email 列创建普通索引INDEX idx_city_username (city_id, username) -- 为 city_id 和 username 创建复合索引
);
场景2:为已存在的表添加索引
在表已经存在的情况下,我们可以使用 ALTER TABLE 或 CREATE INDEX 语句来追加索引。这种方式在项目迭代和后期优化中更为常用。
-- 假设我们有一张已存在的表
CREATE TABLE t_articles (id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(200),author_id INT,create_time DATETIME
);-- 使用 ALTER TABLE 添加唯一索引
ALTER TABLE t_articles ADD UNIQUE INDEX uk_title (title);-- 使用 CREATE INDEX 添加普通索引(推荐,语法更清晰)
CREATE INDEX idx_author_time ON t_articles(author_id, create_time);
最佳实践:关于索引命名
为索引起一个清晰、规范的名字非常重要。一个好的命名能让其他开发者(以及未来的自己)快速理解其用途。推荐的命名规范如下:
- 普通索引:
idx_+列名或idx_+列名1_列名2(例如:idx_author_id)- 唯一索引:
uk_+列名(例如:uk_title)这样的命名见名知意,极大地提高了代码的可读性和可维护性。
7.2 查看索引信息
创建了索引之后,我们如何确认它们是否生效了呢?可以通过 SHOW INDEX 或 SHOW KEYS 命令来查看一张表上已有的全部索引信息。
-- 两种命令功能相同,任选其一即可
SHOW INDEX FROM t_articles;
-- SHOW KEYS FROM t_articles;

解读索引信息
输出结果中的关键字段值得我们关注:
Table: 索引所在的表名。Non_unique:0代表这是一个唯一索引(包括主键),1代表这是一个非唯一的普通索引。Key_name: 索引的名称。主键的默认名称是PRIMARY。Seq_in_index: 列在索引中的序列号,从1开始。对于复合索引,这个值非常重要,它标识了列的先后顺序。Column_name: 索引所包含的列名。Index_type: 索引使用的数据结构,在 InnoDB 中我们看到的基本都是BTREE。
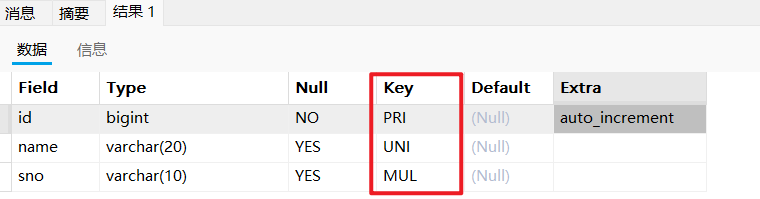
此外,使用 DESC t_articles; 命令也可以快速查看表结构,其中的 Key 列会给我们一些简要的索引提示:
PRI: 表示该列是主键 (PRIMARY KEY) 的一部分。UNI: 表示该列上存在唯一索引 (UNIQUE)。MUL: 表示该列上存在一个非唯一的普通索引。这个“MUL”是 “Multiple” 的缩写,意味着该列的值可以多次出现。
7.3 验证索引是否生效:EXPLAIN
创建了索引,只是第一步。我们的 SQL 查询在执行时,到底有没有用上我们精心设计的索引呢?这需要一个强大的工具来验证,它就是 EXPLAIN。
EXPLAIN 命令可以模拟优化器执行 SQL 查询语句,从而分析出查询的详细计划,让我们清楚地看到 MySQL 是如何处理这条语句的。
-- 准备一个用于测试的表
CREATE TABLE t_explain_test (id INT PRIMARY KEY AUTO_INCREMENT,sno VARCHAR(20),name VARCHAR(50),INDEX idx_sno_name (sno, name)
);
场景1:未使用索引(全表扫描)
EXPLAIN SELECT * FROM t_explain_test WHERE name = '张三';

由于我们的复合索引 (sno, name) 是以 sno 开头的,根据最左前缀原则,直接查询 name 无法使用该索引,导致全表扫描。
场景2:使用主键索引
EXPLAIN SELECT * FROM t_explain_test WHERE id = 1;

通过主键查询,效率极高。
场景3:使用二级索引
EXPLAIN SELECT * FROM t_explain_test WHERE sno = '10001';

查询条件命中了索引 idx_sno_name 的前缀,成功用上了索引。但因为我们查询的是 *(所有列),而索引中只包含了 sno 和 name,所以需要回表去查询其他列的数据。
场景4:实现索引覆盖
EXPLAIN SELECT id, sno, name FROM t_explain_test WHERE sno = '10001';

这次,我们只查询 id, sno, name 这三列。sno 和 name 本身就在 idx_sno_name 索引树中,而主键 id 也默认包含在所有二级索引的叶子节点里。因此,MySQL 只需扫描索引树即可获取全部所需数据,无需回表,实现了“索引覆盖”。
补充内容:
EXPLAIN的关键指标
type(访问类型): 这是衡量查询好坏的重要指标,性能从优到劣依次为:system>const>eq_ref>ref>range>index>ALL。
const: 基于主键或唯一索引的等值查询,最多返回一条记录,速度最快。ref: 使用非唯一索引进行的等值查询。range: 对索引进行范围扫描,常见于BETWEEN,>,<等操作。index: 扫描整个索引树,通常比ALL快,因为索引文件通常比数据文件小。ALL: 全表扫描,这是最坏的情况,应极力避免。Extra(额外信息): 提供了更多执行细节。
Using index: 表明查询使用了“索引覆盖”,性能很高,因为无需回表。Using where: 表示在存储引擎层获取数据后,还需要在服务层通过WHERE条件进行过滤。Using filesort: 说明 MySQL 需要进行额外的排序操作,这通常是性能瓶颈,应设法优化。- 一个小补充:只要查询条件中使用了索引包含的所有列,就会走索引和SQL的执行顺序没关系
7.4 删除索引
有增就有删。当一个索引被证明是冗余的、低效的,或者业务场景发生变化不再需要时,我们就应该果断地删除它,以回收磁盘空间并减轻数据写入时的维护负担。
删除主键索引
删除主键索引的操作需要特别注意,因为它通常与表的结构紧密相关。
-- 语法
ALTER TABLE 表名 DROP PRIMARY KEY;-- 示例
-- 假设要删除 t_articles 表的主键
-- 如果主键列是自增的(AUTO_INCREMENT),必须先移除它的自增属性
ALTER TABLE t_articles MODIFY id INT; -- 移除 AUTO_INCREMENT
ALTER TABLE t_articles DROP PRIMARY KEY;

小思考:为何要先移除 AUTO_INCREMENT?
这是一个非常好的问题,能帮助我们理解 MySQL 的设计。AUTO_INCREMENT属性是依附于键(Key)存在的,尤其是主键。MySQL 规定,一个列如果它不是键(主键或唯一键),那么它就不能被设置为自增列。因此,当我们想删除主键时,就必须先“解绑”这个依附在它身上的
AUTO_INCREMENT属性,否则 MySQL 会阻止这个操作以维护规则的完整性。
删除其他索引(普通/唯一)
删除普通索引和唯一索引则相对简单,我们只需要指定索引的名称即可。
-- 语法一:使用 ALTER TABLE
ALTER TABLE 表名 DROP INDEX 索引名;-- 语法二:使用 DROP INDEX(推荐,意图更明确)
DROP INDEX 索引名 ON 表名;-- 示例
DROP INDEX idx_author_time ON t_articles;
DROP INDEX uk_title ON t_articles;

7.5 创建索引的核心原则
最后,我们用几个核心原则来总结索引创建的智慧。这更像是一种权衡的艺术,而非死板的规则。
- 为高频访问的列服务: 索引的首要目标是加速查询。因此,请将宝贵的索引资源用在“刀刃”上,优先为那些最常出现在
WHERE子句、ORDER BY排序以及JOIN关联条件中的列建立索引。 - 理解索引的维护成本: 索引并非没有代价。它需要占用实实在在的磁盘空间。更重要的是,每当表中的数据发生
INSERT、UPDATE、DELETE时,数据库都必须同步更新相关的 B+ 树索引,这会带来额外的性能开销。查询有多爽,写入就有多累。 - 宁缺毋滥,保持克制: 创建过多或设计不合理的索引,是数据库性能的常见杀手。它们不仅无法提升查询效率,反而会因为高昂的维护成本拖慢整体系统。因此,我们必须保持克制,谨慎规划,并养成定期审查和清理无用索引的好习惯。
关于更高级的索引优化策略,例如如何避免索引失效、如何利用好复合索引等,我们将在后续的文章中进行更深入的探讨。