python—————knn算法
一、knn算法介绍
1.什么是 KNN 算法?
KNN(K-Nearest Neighbors,K 最近邻)是机器学习中最直观、最容易理解的算法之一。它的核心思想源自我们日常生活中的常识:相似的事物总会聚集在一起。
想象一下,如果你走进一个陌生的聚会,看到一群人分成几个小圈子交谈,你想知道自己应该加入哪个圈子,最自然的做法就是看看周围和你最像的几个人(最近邻)在哪个圈子,然后做出选择。这正是 KNN 算法的工作方式。
KNN 属于 "懒惰学习"(Lazy Learning)算法,这意味着它不需要像决策树或神经网络那样进行繁琐的模型训练过程,而是在需要预测时才进行计算。这种特性也让它被称为 "基于实例的学习"。
2.knn算法的工作原理
KNN 算法的工作流程可以概括为三个简单步骤:
计算距离:对于需要预测的新样本,计算它与训练集中所有样本的距离
寻找邻居:找出距离最近的 K 个样本(这就是 "K 近邻" 中的 K)
投票决定:根据这 K 个邻居的类别进行投票,得票最多的类别就是新样本的预测类别
3.距离度量方式
KNN 算法中最常用的距离度量方式有:
欧氏距离:最常用的距离度量,即两点之间的直线距离
曼哈顿距离:各维度差的绝对值之和,适用于高维数据
闵可夫斯基距离:欧氏距离和曼哈顿距离的一般形式
4.k值如何选择
K 值是 KNN 算法中唯一的关键参数,它的选择直接影响模型性能:
K 值过小:模型容易过拟合,对噪声敏感,决策边界复杂
K 值过大:模型过于简单,可能忽略数据的局部模式,决策边界趋于平滑
K 为奇数:可以避免投票时出现平局的情况
通常我们会通过交叉验证来选择最优的 K 值,绘制 K 值与模型准确率的关系图,找到性能最佳的 K 值点。
一、环境配置
1.sklearn库
scikit-learn(简称 sklearn)是 Python 中最流行的机器学习库之一,它提供了简单高效的数据挖掘和数据分析工具,适用于各种监督和无监督学习算法。
主要特点:
- 丰富的算法:包含分类、回归、聚类、降维、模型选择和预处理等多种算法
- 易用性:统一的 API 接口,所有算法都遵循 fit ()、predict () 等一致的方法
- 与其他库集成:与 NumPy、Pandas 和 Matplotlib 等数据科学库无缝协作
- 文档完善:提供详细的文档和丰富的示例
2.knn中sklearn的使用模块
在 scikit-learn(sklearn)中,K 近邻(KNN)算法主要通过 sklearn.neighbors 模块实现,支持分类(KNeighborsClassifier)和回归(KNeighborsRegressor)两种任务。
KNeighborsClassifier 的重要参数:
- n_neighbors:K 值(最关键参数),决定考虑多少个近邻的投票
- weights:
'uniform'(默认):所有近邻权重相同'distance':权重与距离成反比(距离越近影响越大)
- metric:距离度量方式
'euclidean'(默认):欧氏距离'manhattan':曼哈顿距离'minkowski':闵可夫斯基距离(可通过 p 参数调整,p = 1为曼哈顿距离,p=2为欧式距离)
- algorithm:计算近邻的算法
'auto'(默认):自动选择最优算法'ball_tree'、'kd_tree'、'brute'(暴力搜索)
二、代码实现knn算法:
1.读取并提取所需文件数据
读取数据:
使用numpy库读取数据
data = np.load文件类型("文件名")
示例代码:
读取名为datingTestSet2的txt文件
import numpy as npdata = np.loadtxt('datingTestSet2.txt')提取所需文件:
任务目标:
利用matolotkib库实现学生分配。将相同类型的学生在一个三维坐标轴上用同一种形式表达出来。爱学习的一类,爱玩游戏一类,爱旅游一类
示例代码:
import numpy as np
import matplotlib.pyplot as pltdata = np.loadtxt("datingTestSet2.txt")
data_1 = data[data[:,-1]==1]
data_2 = data[data[:,-1]==2]
data_3 = data[data[:,-1]==3]
fig = plt.figure()
ax = plt.axes(projection="3d")
ax.scatter(data_1[:,0],data_1[:,1],zs=data_1[:,2],c="red",marker="o")
ax.scatter(data_2[:,0],data_2[:,1],zs=data_2[:,2],c="blue",marker="^")
ax.scatter(data_3[:,0],data_3[:,1],zs=data_3[:,2],c="black",marker="+")
ax.set(xlabel='x',ylabel='y',zlabel='z')
plt.show()
运行结果:
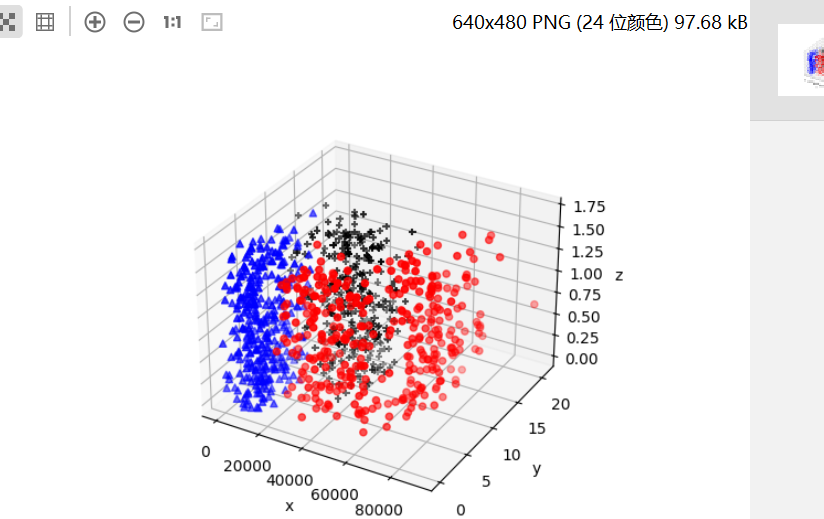
代码解析:
data = np.loadtxt("datingTestSet2.txt") :读取txt文件
data_1 = data[data[:,-1]==1] :文件内已经做好分类,最后一列有1,2,3分别代表各自属于的类型,该行代码表示最后一列为1,即为第一类学生
ax = plt.axes(projection="3d"): 建立3d坐标系
ax.scatter(data_1[:,0],data_1[:,1],zs=data_1[:,2],c="red",marker="o"):scatter:表示为散点图,括号内表示分别为x,y,z赋值。
三、knn项目实战:
前情提要:
fit(x,y)训练:将x,y数据分布传入进去模型就训练好了
predict(数据集)预测:新的数据集输入进行预测
score(x,y):计算模型的准确率
示例代码:
任务目标1:利用人工智能模型knn 实现宿舍寝室的分配。将相同类型的学生
分配在同一个寝室。爱学习的在一起,一般般在一起,爱玩在一起
1.历史数据 通过调查问卷的形式调查学生的特征,由辅导员来决定
第一列:旅游的路程 第二列:玩游戏所有时间百分比 第三列:每个礼拜消耗零食的重量
最后一列学生类别
2.knn算法实现模型
3.新的数据(大一新生,提前预判学生是1,2,3)
数据集内1000个数据,前800个进行训练,后200进行预测
示例代码:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
data = np.loadtxt('datingTestSet2.txt')
X = data[0:800,0:3]
y = data[0:800,-1]
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(X,y)
text_x = data[800:1000,0:3]
text_y = data[800:1000,-1]
a_predict = neigh.predict(text_x)
a_score = neigh.score(text_x,text_y)
print(a_score)
print(a_predict)任务目标2:鸢尾花判断
我们使用了 sklearn 内置的鸢尾花数据集,包含 2种鸢尾花的 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)进行训练
示例代码:
import pandas as pd
train = pd.read_excel("D:\pythonProject11\class\鸢尾花训练数据.xlsx")
text = pd.read_excel("D:\pythonProject11\class\鸢尾花测试数据.xlsx")
train_X = train[["萼片长(cm)","萼片宽(cm)","花瓣长(cm)","花瓣宽(cm)"]]
train_y = train[["类型_num"]]
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(train_X,train_y)
train_predict = knn.predict(train_X)
score = knn.score(train_X,train_y)
text_x = text[["萼片长(cm)","萼片宽(cm)","花瓣长(cm)","花瓣宽(cm)"]]
text_y = text[["类型_num"]]text_predicted = knn.predict(text_x)
score = knn.score(text_x,text_y)
print(score)在鸢尾花数据集上,KNN 算法通常能取得非常高的准确率(通常在 95% 以上)。这是因为鸢尾花的三类样本在特征空间中具有较好的可分性。