上海AI Lab长时序感知具身导航!StreamVLN:基于慢快上下文建模的流式视觉语言导航


- 作者:Meng Wei1,2^{1,2}1,2, Chenyang Wan1,3^{1,3}1,3, Xiqian Yu1^{1}1, Tai Wang1^{1}1, Yuqiang Yang1^{1}1, Xiaohan Mao1,4^{1,4}1,4, Chenming Zhu1,2^{1,2}1,2, Wenzhe Cai1^{1}1, HanqingWang1^{1}1, YilunChen1^{1}1
- 单位:1^{1}1上海AI Lab,2^{2}2香港大学,3^{3}3浙江大学,4^{4}4上海交通大学
- 论文标题:StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
- 论文链接:https://arxiv.org/pdf/2507.05240
- 项目主页:https://streamvln.github.io/
- 代码链接:https://github.com/OpenRobotLab/StreamVLN
主要贡献
- 提出了基于慢快上下文建模的流式视觉语言导航框架StreamVLN,能够有效处理长视频流并生成低延迟的动作。
- 在 VLN-CE 基准测试中取得了SOTA性能,同时保持了稳定的低延迟,证明了其在实时导航中的潜力。
- 通过滑动窗口KV缓存机制和基于体素的空间剪枝策略,实现了高效的上下文管理和内存优化。
研究背景
- 视觉语言导航(VLN)是具身人工智能中的一个关键任务,要求智能体能够根据语言指令在环境中导航,将语言线索与视觉观察相匹配,并规划出可执行的路径。
- 现有的基于Video-LLM的VLN方法在处理长时序上下文和实时响应性方面存在挑战,如在管理线性增长的视觉token时面临困难,采样固定数量的视频帧可能导致无法准确预测低层次动作,而压缩视觉token则会牺牲时间和视觉细节。
- 为了应对这些挑战,论文提出StreamVLN框架,旨在实现低延迟的动作生成,并通过高效的上下文管理支持长视频流的处理。
方法

基础知识:连续多轮自回归生成
- 多轮对话的背景:StreamVLN 将导航过程设计为多轮对话,每轮对话包含一个观察(observation)和一个动作(action)。具体来说,每轮对话 di=(oi,ai)d_i = (o_i, a_i)di=(oi,ai) 中,模型接收新的观察 oio_ioi,并根据当前输入和对话历史生成动作 aia_iai。
- 输入序列构建:在第 iii 步时,完整的输入序列是 o1a1o2a2…oi−1ai−1o_1 a_1 o_2 a_2 \dots o_{i-1} a_{i-1}o1a1o2a2…oi−1ai−1,新的观察 oio_ioi 的token会持续追加到token流中,动作 aia_iai 通过自回归解码逐token生成。
- KV缓存机制:基于Transformer的LLM在预填充(prefill)阶段对输入token进行编码,并在注意力层中缓存它们的key/value(KV)状态。这些缓存的KV对在解码阶段用于生成新token。如果不跨轮次复用KV缓存,模型需要为每个新对话重复预填充所有之前的token,这会导致显著的计算开销。
快速流式对话上下文
- 滑动窗口KV缓存:为了管理对话上下文,StreamVLN采用固定大小的滑动窗口KV缓存机制,保留最近 NNN 轮对话的KV状态。具体来说,当窗口达到容量时,会将非观察对话token(如提示和生成的动作)的KV状态从LLM中卸载,并将这些token的状态处理成记忆token状态。
- 解码过程:对于最新的观察 oio_ioi,解码器基于当前窗口的缓存token状态和KV缓存生成动作 aia_iai,形式化表示为:
aWj+1i=Decoder(oi,{M0,…,Mj},{k(i−N+1)v(i−N+1),…,k(i−1)v(i−1)}) a_{W_{j+1}}^i = \text{Decoder} \left( o_i, \{M_0, \dots, M_j\}, \{k_{(i-N+1)} v_{(i-N+1)}, \dots, k_{(i-1)} v_{(i-1)}\} \right) aWj+1i=Decoder(oi,{M0,…,Mj},{k(i−N+1)v(i−N+1),…,k(i−1)v(i−1)})
慢速更新记忆上下文
- 平衡时间分辨率和空间细节:StreamVLN通过时间采样和基于体素的空间剪枝策略来控制记忆增长,同时保留高图像分辨率,避免因压缩视觉token而导致的细节丢失。
- 时间采样:采用固定数量采样策略,以避免不同长度的记忆token引入的时间持续偏差,从而提高模型在不同规划范围内的鲁棒性。
- 基于体素的空间剪枝:
- 算法描述:将2D图像块反投影到共享的3D空间中,通过深度信息将3D空间离散化为均匀的体素。如果多个来自不同帧的token投影到同一个体素中,则只保留最近观察的token。
- 优势:这种剪枝方法能够在不改变之前计算的token的情况下,高效地复用已卸载的KV缓存,从而在整个导航过程中保持稳定的解码速度。
多源数据联合训练

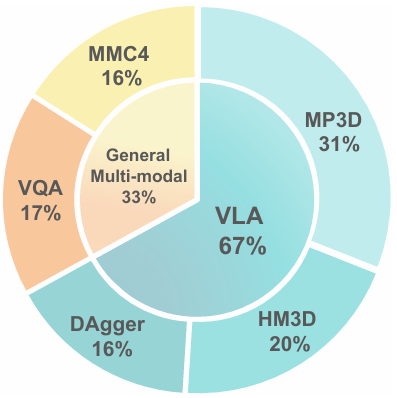
- 导航特定训练数据:使用Habitat模拟器从多个公共VLN数据集中收集导航特定的训练数据,共收集了450K样本,来自60个Matterport3D环境。此外,还加入了300K来自ScaleVLN的样本,以提高模型在新场景中的泛化能力。
- DAgger算法:采用DAgger算法收集纠正性演示数据,使用Habitat的最短路径跟随器作为专家策略,在初始训练阶段后收集模型rollout的纠正演示数据,共240K样本,用于联合训练。
- 通用视觉语言数据:为了保留预训练Video-LLM的通用推理能力,还纳入了248K视频基础的视觉问答(VQA)样本和230K交错的图像-文本样本,这些数据来自LLaVA-Video-178K、ScanQA和MMC4等公开数据集,以增强模型在多轮视觉语言交互中的能力。
实验设置
仿真基准测试设置
- 数据集:在两个公共VLN-CE基准测试(R2R-CE和RxR-CE)上评估StreamVLN方法。R2R-CE包含5600条英文轨迹,平均长度为10米;RxR-CE包含126000条多语言指令(英文、印地语、泰卢固语),路径更长、更复杂,平均长度为15米。
- 目标:主要关注验证集的未见部分(Val-Unseen),以评估模型的泛化能力。
- 评估指标:采用标准的VLN指标,包括导航误差(NE)、成功率(SR)、Oracle成功率(OS)和按路径长度加权的成功率(SPL)。
真实世界实验设置
- 实验平台:基于Unitree Go2机器狗进行真实世界实验,配备Intel® RealSense™ D455摄像头,用于RGB-D观测。
- 部署方式:将StreamVLN部署在远程工作站上(配备RTX 4090 GPU),机器狗将视觉数据流式传输到工作站进行推理,工作站返回可执行的动作指令。
- 延迟:平均推理时间为0.27秒(4个动作),室内通信延迟为0.2秒,室外通信延迟为1.0秒,能够支持实时物理部署。

实现细节
- 基础模型:StreamVLN基于LLaVA-Video 7B模型构建,使用Qwen2-7B 作为语言模型。
- 训练阶段:
- 第一阶段:仅在Oracle VLN轨迹上进行微调,训练一个epoch。
- 第二阶段:使用DAgger算法收集轨迹数据,并在包含VLN数据和通用多模态数据的混合数据集上继续训练一个epoch。
- 训练参数:
- 在预热阶段,语言模型的学习率为2e-5,视觉编码器的学习率为5e-6。
- 每个训练步骤处理128个视频片段。
- 总训练时间为约1500个A100 GPU小时。
与现有SOTA的对比
VLN-CE基准测试结果
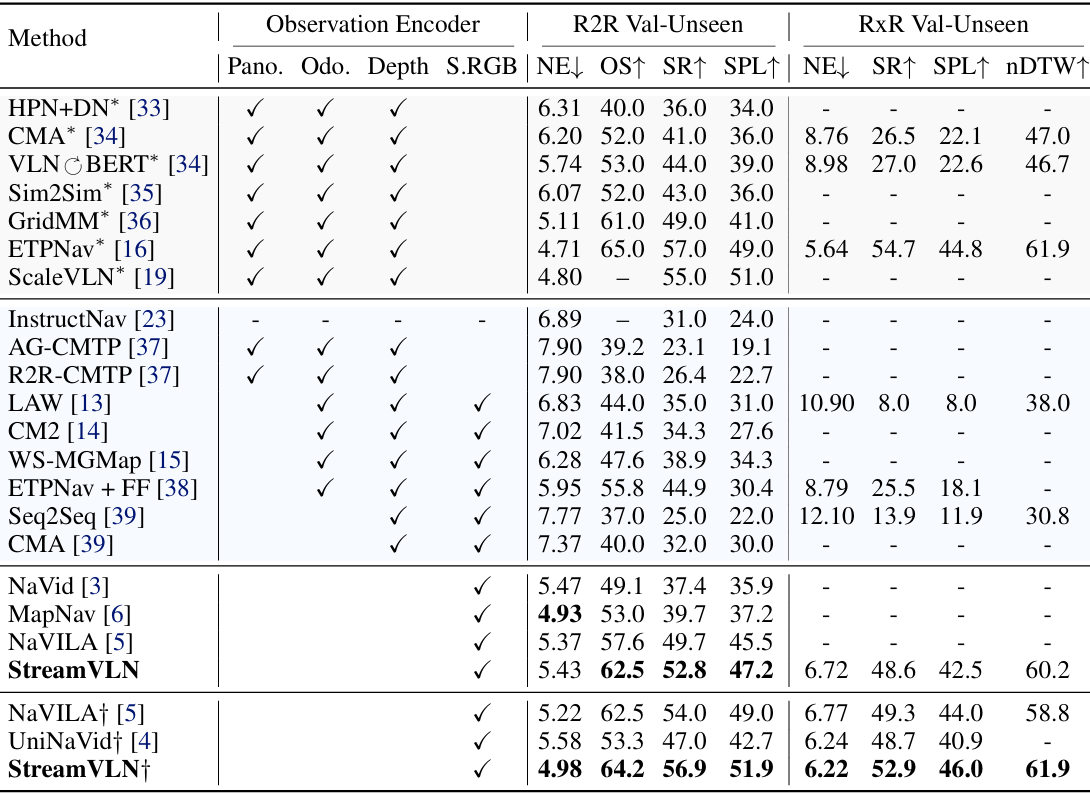
- R2R-CE和RxR-CE Val-Unseen设置:StreamVLN在R2R上达到了56.9%的SR和51.9%的SPL,在RxR上达到了52.9%的SR和46.0%的SPL,均优于现有的RGB-only方法,包括不使用额外导航数据集和使用额外数据集的方法。
- 与ETPNav对比:尽管StreamVLN没有依赖额外的全景或航点监督,但其性能与ETPNav相当。
- 与HMAT对比:StreamVLN仅使用ScaleVLN数据集的一个小子集(150k轨迹),就超越了使用大规模数据集(300万轨迹)的HMAT,显示出更高的数据效率。
视频问答(VQA)结果
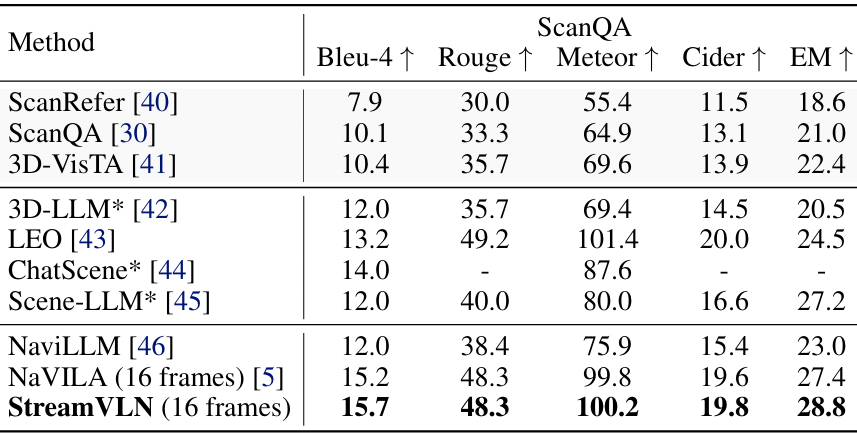
- 在ScanQA基准测试中,StreamVLN在3D问答任务上超越了现有的通用导航模型,如NaviLLM和NaVILA,显示出其强大的空间场景理解能力。
消融研究
数据消融研究
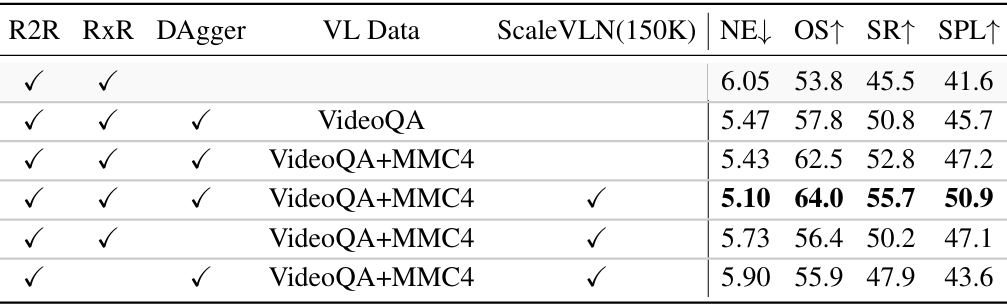
- 仅使用Oracle导航数据:第一阶段训练的性能较低。
- 加入DAgger数据:第二阶段联合训练带来了显著的性能提升(+5.3 SR / +4.1 SPL)。
- 加入VideoQA和MMC4数据:进一步提高了性能(+2.0 SR / +1.5 SPL)。
- 加入ScaleVLN数据:带来了额外的性能提升(+2.9 SR / +3.7 SPL)。
- 移除DAgger数据:性能显著下降(-5.5 SR / -3.8 SPL),表明DAgger数据对性能提升至关重要。
- 加入RxR数据:带来了显著的性能提升(+7.8 SR / +7.3 SPL)。
记忆上下文大小和滑动窗口大小的影响
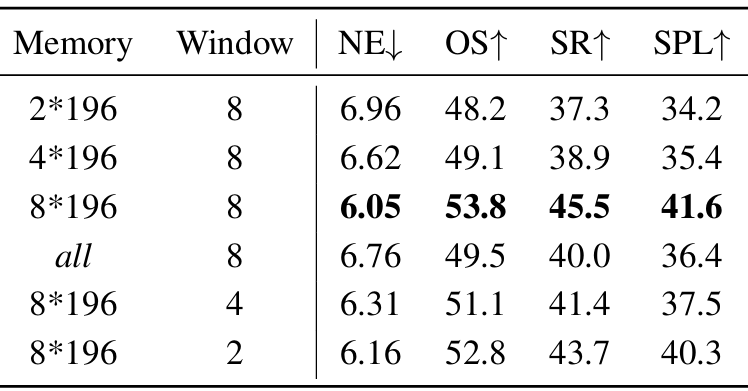
- 记忆上下文大小:增加记忆大小(从2*196到8*196)显著提高了导航性能(SR从37.3%提升到45.5%),但使用全部视觉上下文作为记忆并没有带来最佳性能。
- 滑动窗口大小:保留8轮对话的滑动窗口在训练成本和性能之间取得了最佳平衡。
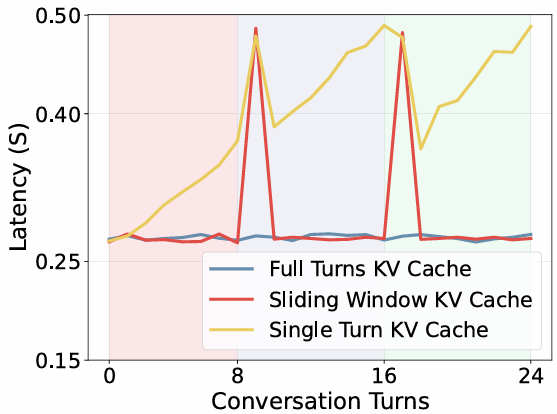
KV缓存复用的有效性
- 全轮次KV缓存复用:始终保持低延迟,因为只有当前观察的token需要预填充计算。
- 滑动窗口KV缓存复用:在每个滑动窗口开始时延迟会增加,因为需要预填充之前的窗口上下文token。
- 单轮次KV缓存:延迟随着轮次增加而稳步上升。
体素空间剪枝的有效性

- 平均减少20%的输入token:在R2R、RxR和HM3D数据集上,体素剪枝平均减少了20%的输入token,同时提高了导航性能(R2R上SR提升1.2%,SPL提升1.0%;RxR上SR提升1.1%,SPL提升1.0%)。
结论与未来工作
- 结论:
- StreamVLN通过其混合上下文建模策略,在保持低延迟的同时,实现了长视频流上的高效、连贯且可扩展的动作生成,为实时、内存高效和长时序感知导航提供了一种新的解决方案。
- 未来工作:
- 未来工作可以进一步探索如何提高模型在更复杂环境中的泛化能力,以及如何优化模型以更好地处理长时序导航任务中的持续推理和决策。
- 此外,还可以研究如何将StreamVLN与其他相关技术相结合,以进一步提升具身智能体在复杂场景中的导航性能。
