避开算力坑!无人机桥梁检测场景下YOLO模型选型指南

【导读】
本文提出了一种面向无人机(UAV)桥梁检测场景的深度学习模型选型框架,核心在于对YOLO系列最新变体(v5, v6, v7, v8)共23个模型在专用桥梁细节数据集(COCO-Bridge-2021+)上进行了系统性的基准测试,实现了在严格受限的边缘算力(如无人机)与高精度检测需求之间的最佳平衡点识别。>>更多资讯可加入CV技术群获取了解哦
目录
一、相关研究
二、模型与评估方法
深度学习模型
评估方法
三、实验结果
结论
尽管计算机视觉模型与搭载摄像头的无人机相结合是自动化视觉检测的未来趋势,但仍需探讨具体问题。尽管近年来无人机技术发展迅速,但其计算能力和存储空间仍存在局限性。同时,在视觉检测中,需要处理的图像数量可能急剧增加,且数据采集常需重复进行,因为外部因素(如风引起的画面抖动或光线不足导致图像过暗)会显著影响数据质量。图像大小也是一个重大问题,因为处理、存储或传输如此大量数据既耗时又占用大量存储空间。在传统的集中式计算机视觉-无人机方法中,这些问题并未得到妥善解决,因为计算机视觉模型被部署在本地计算机或云端,而无人机还需承担额外任务。
我们发现,在视觉检测领域,特别是桥梁检测领域,发掘边缘人工智能(Edge AI)的潜力是一项至关重要的任务。主要原因是桥梁是敏感的基础设施交通组件,因此必须进行常规检查。有必要开发一种结合边缘人工智能和视觉检查的自动桥梁检查方法,以快速准确地评估桥梁状况,同时减少人力投入。这种方法将有助于桥梁维护过程的顺利进行,从而确保交通参与者的安全以及社会连接性。然而,将计算机视觉(CV)模型集成到无人机中是一项挑战。这是因为一些现代CV模型虽然能实现高精度,但需要巨大的计算和存储能力,而无人机缺乏这些能力。另一方面,一些较旧的CV模型适合无人机的计算和存储能力,但其精度不足。通过这项工作,我们旨在为无人机桥梁检测找到合适的CV模型,并为未来研究提供基准。因此,本文聚焦于视觉识别模型实验,通过准确率和推理时间在桥梁检测数据集COCO-Bridge 2021+上对比其性能。具体而言,我们对四种YOLO变体进行基准测试,包括YOLOv5、YOLOv6、YOLOv7和YOLOv8。实验结果表明,在这些YOLO变体总共23个模型中,YOLOv8n、YOLOv7tiny、YOLOv6m和YOLOv6m6在准确率与推理时间之间实现了最佳平衡。

论文标题:
Deep Learning Models for UAV-Assisted Bridge Inspection: A YOLO Benchmark Analysis
论文链接:
https://arxiv.org/pdf/2411.04475
一、相关研究
在桥梁检测中,视觉检测是一个关键要素。值得注意的是,美国机械工程师协会(American Mechanical Engineers)于2018年进行的一项研究提出了一种基于深度学习的方法,用于桥梁的全面维护和检测。该方法基于一个包含3,832张图像的数据集,这些图像来自互联网,涵盖了拱桥、悬索桥和斜拉桥等类型。该方法采用经过微调的AlexNet模型对桥梁类型进行分类,验证集和测试集的准确率分别达到96%和96.6%。此外,基于ZF-net的Faster R-CNN模型被用于识别和定位桥梁塔架及桥面,在验证集上获得90.45%的平均交集精度(mAP)。通过微调后的GoogLeNet模型实现了桥梁混凝土裂缝的检测,验证集和测试集的准确率分别达到99.39%和99.36%。2017年,另一项值得注意的研究提出了一种基于区域的深度学习策略,用于自主结构视觉检测。研究人员使用Faster R-CNN模型对包含2,366张标注图像的数据集进行实时检测,识别包括螺栓腐蚀、混凝土裂缝、钢材腐蚀及钢材剥离等不同类型损伤。结果显示各类别均达到令人印象深刻的平均精度(AP)评分,整体平均AP达87.8%。提出了一种用于混凝土桥梁表面损伤检测的单阶段检测器。该方法使用的图像数据集包含了香港高速公路混凝土桥梁的2,206张检测照片。通过一种新型迁移学习技术对原始YOLOv3模型进行了增强,显著提升了检测准确率,在IoU阈值为0.5和0.75时,准确率分别达到80%和47%。利用深度学习和纹理分析,ASR(抽象碱-硅反应)裂缝诊断是桥梁检测领域的一项新进展。本研究为该调查生成了一个包含35张来自不同昆士兰桥梁的ASR缺陷照片的数据集。通过整合纹理形态学与InceptionV3模型,实现了94.07%的验证准确率。这些结果证明了机器学习在桥梁检测中的可行性,尤其是损伤检测领域。
综上所述,本研究的全面回顾强调了机器学习和深度学习方法在推动各行业视觉检测流程中的重要作用。这些前沿技术不仅在早期识别潜在问题方面表现出色,还显著提升了安全、生产力和整体基础设施质量。
二、模型与评估方法
本节是本研究的核心部分,概述了所采用的模型及评估方法。
-
深度学习模型
目前,物体检测器可分为两类:单阶段检测器和双阶段检测器。与单阶段检测器相比,双阶段检测器通常能实现更高的准确率(包括识别准确率和定位准确率),但推理速度较慢。我们的研究完全聚焦于单阶段检测器,因其适用于实时物体检测。本研究测试的模型包括四种最新模型:YOLOv5、YOLOv6、YOLOv7和YOLOv8。除了它们是物体检测领域的最先进模型外,所有这些模型在不同场景下的表现都存在争议,结果截然相反。因此,这些模型在桥梁视觉检测中 的效率值得怀疑,需要进行深入研究。
-
YOLOv5:YOLOv5由Glenn Jocher于2020年6月发布[8]。YOLOv5在YOLOv4的基础上进行了多项改进,包括对模型大小的灵活控制、应用Hardswish激活函数以及数据增强[22],但最大的区别在于它基于PyTorch框架而非DarkNet构建。根据文献,我们发现YOLOv5在多个数据集上优于大多数SOTA模型。然而,部分研究结果存在矛盾。例如,在自定义的电力杆故障组件检测数据集上,YOLOv4的AP50值优于YOLOv5。
-
YOLOv6:YOLOv6于2022年由美团视觉AI部门发布。其在骨干网络、颈部网络、头部网络及训练策略方面均有显著改进,最突出的特点是采用了无锚点(anchor-free)架构。先前研究表明,与YOLOv5相比,YOLOv6在稳定性和灵活性方面有所欠缺,但其在检测小型密集分布物体方面的能力令人印象深刻。官方YOLOv6论文显示,YOLOv6在几乎所有类别中均优于YOLOv5及所有先前SOTA模型。同时,在采样COCO train2017数据集上,YOLOv6的召回率和mAP@50:95更高,但精度、mAP@50及推理速度均逊于YOLOv5。
-
YOLOv7:YOLOv7由Alexey Bochkovskiy等人于2022年发布。YOLOv7的架构具有三个主要特点:E-ELAN用于高效学习、模型缩放以适应不同尺寸,以及“免费袋”方法以提升准确性和效率。事实上,YOLOv7 展现出巨大潜力,多项研究表明其性能优于所有先前最先进模型(SOTA),尤其在精度方面 。
-
YOLOv8:YOLOv8由YOLOv5的开发公司 Ultralytics 于 2023 年发布。YOLOv8 采用无锚点设计,预测的边界框数量更少,且具有更快的非最大抑制(NMS)过程。由于 YOLOv8 近期才被引入,目前文献中对其研究较少。总体而言,YOLOv8 在训练速度以外的方面似乎优于 YOLOv5,且与 YOLOv7 的性能相当。
在Coovally平台上不仅汇聚国内外开源社区超1000+热门模型,同时还集成400+公开数据集,涵盖VisDrone等热门数据集,一键调用即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!

无论是学术研究还是工业级应用,Coovally均提供云端一体化服务:
-
免环境配置:直接调用预置框架(PyTorch、TensorFlow等);
-
免复杂参数调整:内置自动化训练流程,小白也能轻松上手;
-
高性能算力支持:分布式训练加速,快速产出可用模型;
-
无缝部署:训练完成的模型可直接导出,或通过API接入业务系统。
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
-
评估方法
评估数据集本文使用的评估数据集为Eric Bianchi和Matt Hebdon编写的COCO-Bridge 2021+数据集。弗吉尼亚州交通部(VDOT)提供了真实的桥梁结构检测记录,这些记录构成了用于边界框检测的数据集来源。具体而言,该数据集包含1470张标注的桥梁结构照片,其中约10%来自测试集(136张图像),90%来自训练集(1321张图像)。数据集包含四类桥梁结构细节信息:平面外加强筋、盖板端部、加劲板连接及支座。各类别的样本照片如图1所示。

实现工具所有实验均在配备x86 64位元CPU架構、CUDNN版本9.2.1及两个CUDA裝置的相同电脑上运行。所使用的GPU为NVIDIA GeForce RTX 3060 Ti,记忆体容量约为8.36 GB。使用的软件版本包括Torch版本2.0.1+cu117、Torchvision版本0.15.2+cu117以及Python版本3.9.18。评估指标本节介绍评估模型在检测桥梁细节方面性能的目的。需要特别指出的是,准确的评估对于确保模型在实际应用中有效运行至关重要。
-
交并比(IoU):该指标衡量预测边界框与真实边界框之间的重叠程度。IoU可通过以下公式计算:
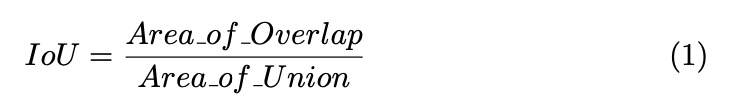
IoU = 重叠面积 / 并集面积
-
平均精度(AP):该指标将精度-召回率曲线的形状简化为单一数值,从而简化模型评估任务。我们工作中所有模型均采用Object-Detection-Metrics的Every Points Interpolation AP。
-
平均平均精度(mAP):这是衡量目标检测模型性能的常用指标。它计算所有类别平均精度(AP)的平均值。我们工作中使用了两个mAP指标:mAP@50和mAP@50:95。mAP@50在IoU阈值为0.5时计算mAP,而mAP@50:95则考虑从0.5到0.9的不同IoU阈值。
-
推理时间:指模型处理输入并生成对应输出所需的时间。这涵盖了从模型接收输入到交付最终结果的整个过程。该指标对实时应用至关重要,受模型结构和可用计算资源的双重影响。
-
参数数量:参数数量会影响模型的计算效率和学习能力。参数过多的模型可能对训练数据过拟合,而参数过少的模型可能无法学习数据中的潜在模式。
-
GFLOPs:即十亿次浮点运算,用于衡量模型的计算复杂度。它是模型执行前向传播所需的浮点运算(加法、乘法等)总数。GFLOPs 较少的模型通常运行速度更快且能耗更低。
三、实验结果
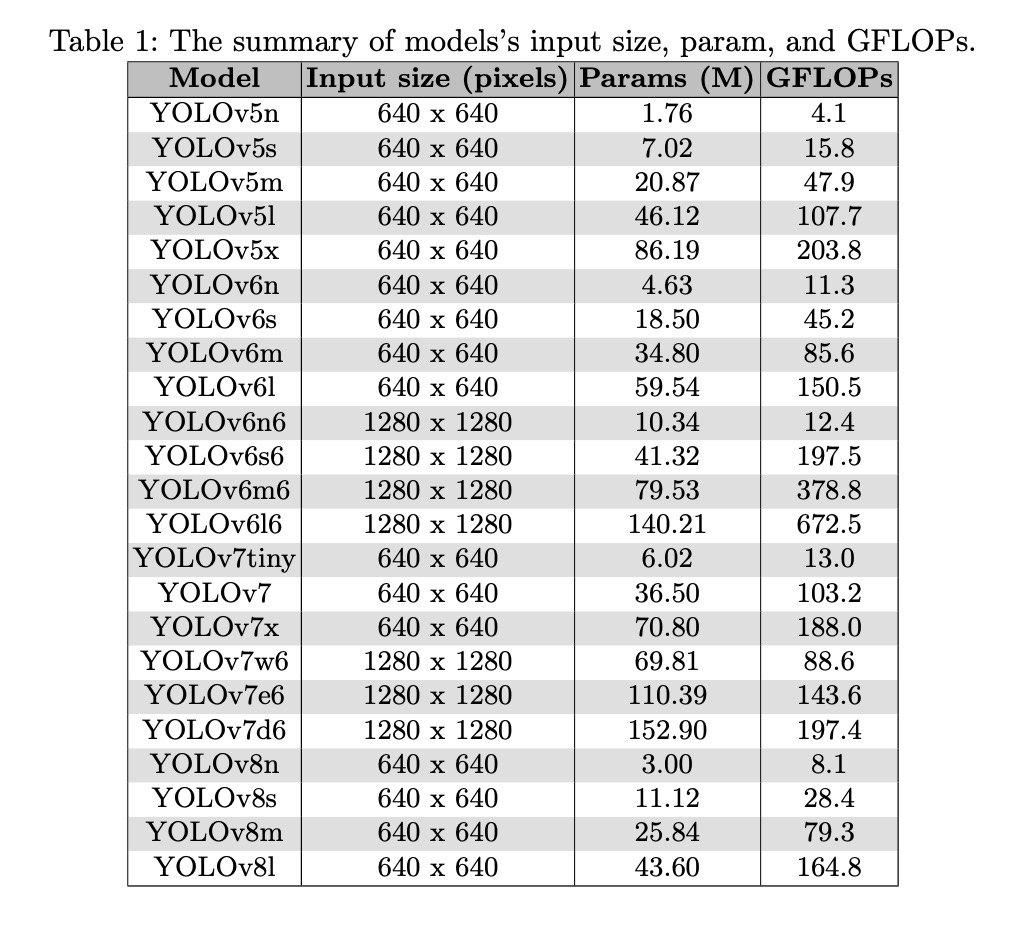
在本节中,我们描述了在COCO-bridge-2021+数据集上的实验结果。表1展示了YOLO变体模型的输入尺寸、参数数量及GFLOPs值,表明这些模型在输入尺寸和复杂度方面具有广泛的适用范围。具体而言,模型支持640x640像素或1280x1280像素的输入尺寸,参数数量大致在176万至1.529亿之间,GFLOPs值则在4.1至672.5之间。640x640像素的输入尺寸足以让模型检测图像中的大多数物体,但更大的1280x1280像素输入尺寸可能在处理模糊图像或远距离物体时更有效,但会增加模型复杂度。
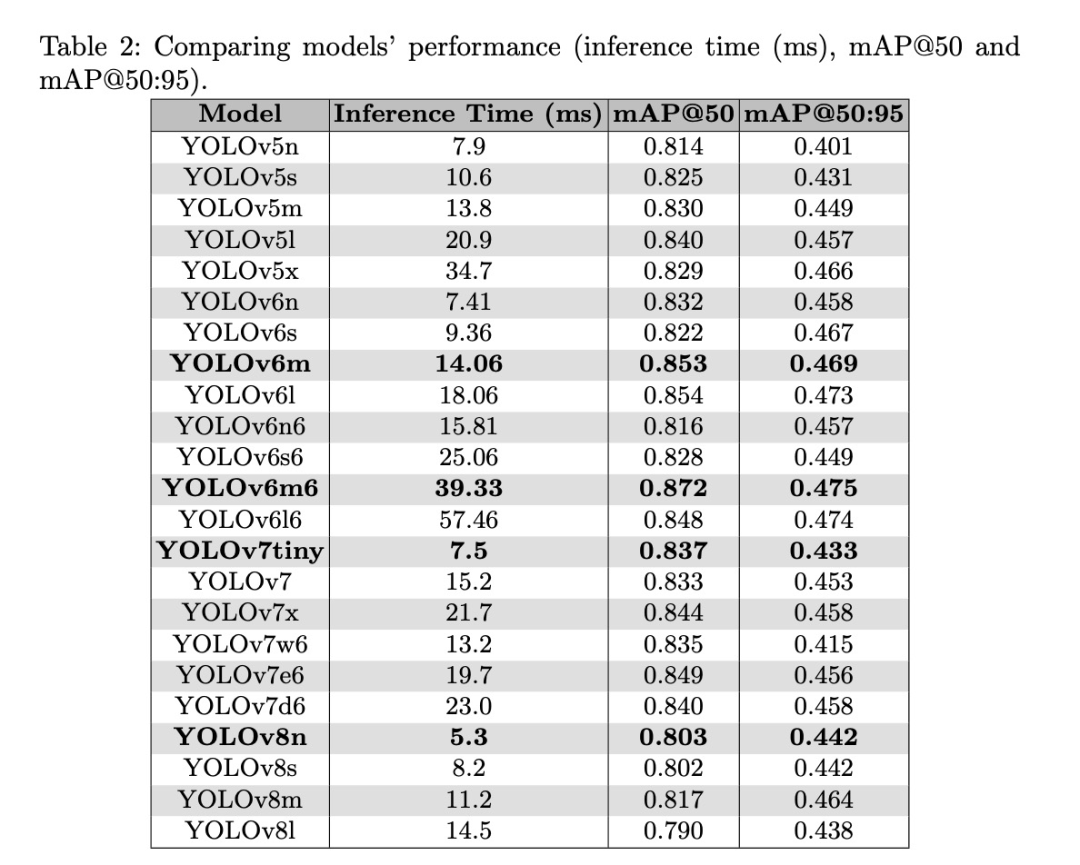
如表2所示,mAP@50:95和mAP@50分别在0.401至0.475和0.790至0.872之间波动,而推理时间则在5.3毫秒至57.46毫秒之间。基于mAP@50和mAP@50:95,YOLOv6m6获得了最高的准确率,分别为0.872和0.475,而YOLOv8n观察到最快的推理时间,为0.803。
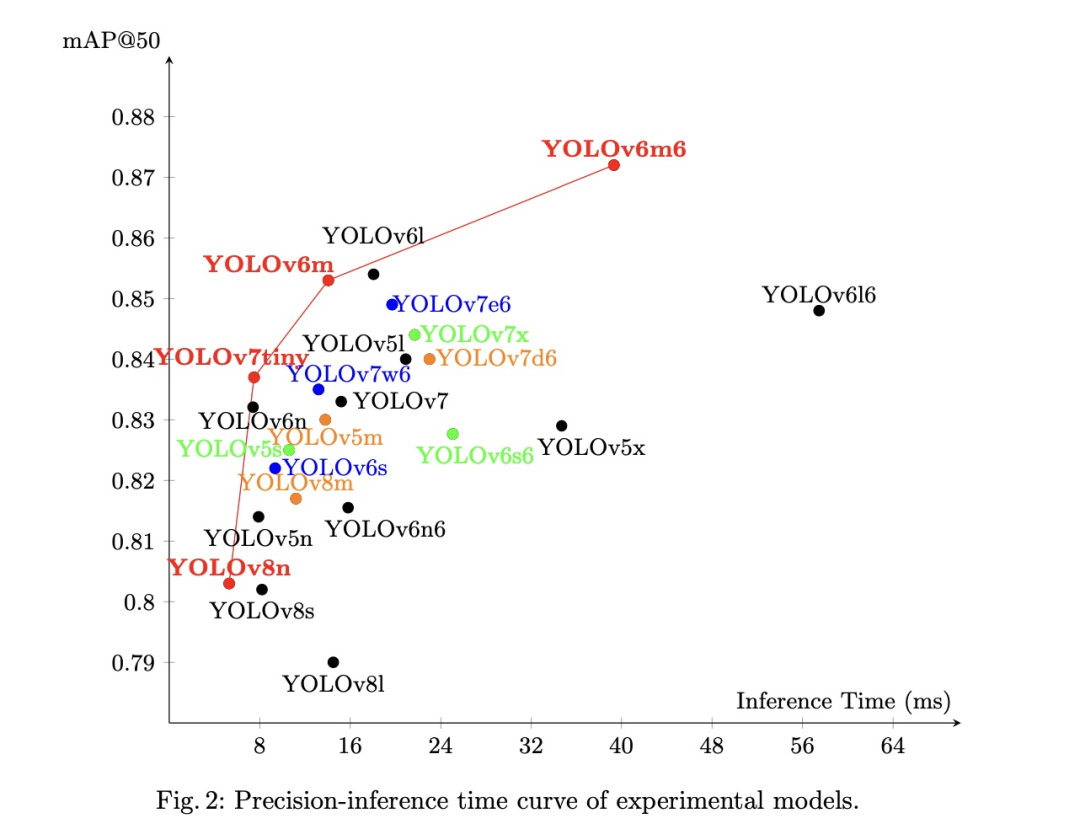
如图2所示,该图展示了mAP@50与推理时间之间的权衡曲线,从中选出了四个最佳模型,包括:YOLOv8n、YOLOv7tiny、YOLOv6m和YOLOv6m6。
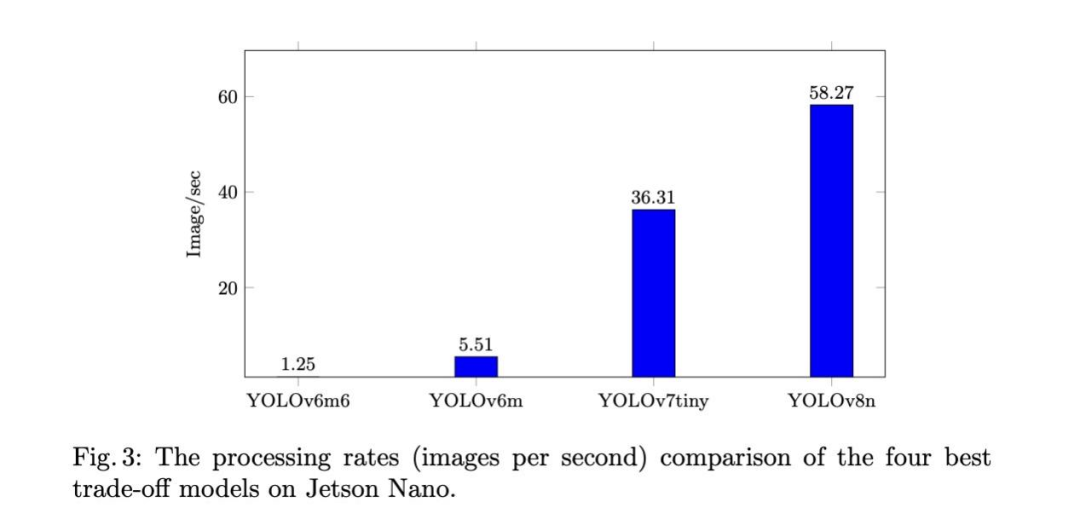
随后,我们将这四个最佳模型部署在边缘设备上,具体为Jet-son Nano,该设备可安装于无人机进行自动视觉检测。图3显示,仅YOLOv7tiny和YOLOv8n能实现实时处理速率,分别为36.308和58.272帧/秒。同时,YOLOv6m6和YOLOv6m虽具有更高的mAP,但处理速率仅为1.246和5.512帧/秒。
结论
本研究在COCO-Bridge-2021+数据集上对YOLO家族的最新模型进行了基准测试,部分帮助检查员选择最适合细节检测问题的模型。结果表明,YOLOv5n、YOLOv7tiny、YOLOv6m和YOLOv6m6是准确率和推理速度最高的最佳模型。我们的工作为一个新领域“桥梁细节检测”铺平了道路。我们的工作仍有很大的改进和发展的潜力。目前基准测试的模型数量仍然有限,且模型的架构尚未针对该问题进行优化。未来研究可探索各种新架构的潜力以及对已知架构的修改。通过利用领域知识进行更好的预处理和特征工程,也可实现性能提升。更多数据可提升实际应用性能,因其有助于改善模型泛化能力并减少过拟合。更精准的桥梁细节检测有助于对环境和缺陷进行上下文分析,从而提升桥梁的视觉检测效果。
