推荐系统多目标排序模型以及融合策略
一、模型架构设计
多目标推荐模型采用共享底层参数的神经网络架构,通过多任务学习同时优化多个用户行为指标。如图1所示
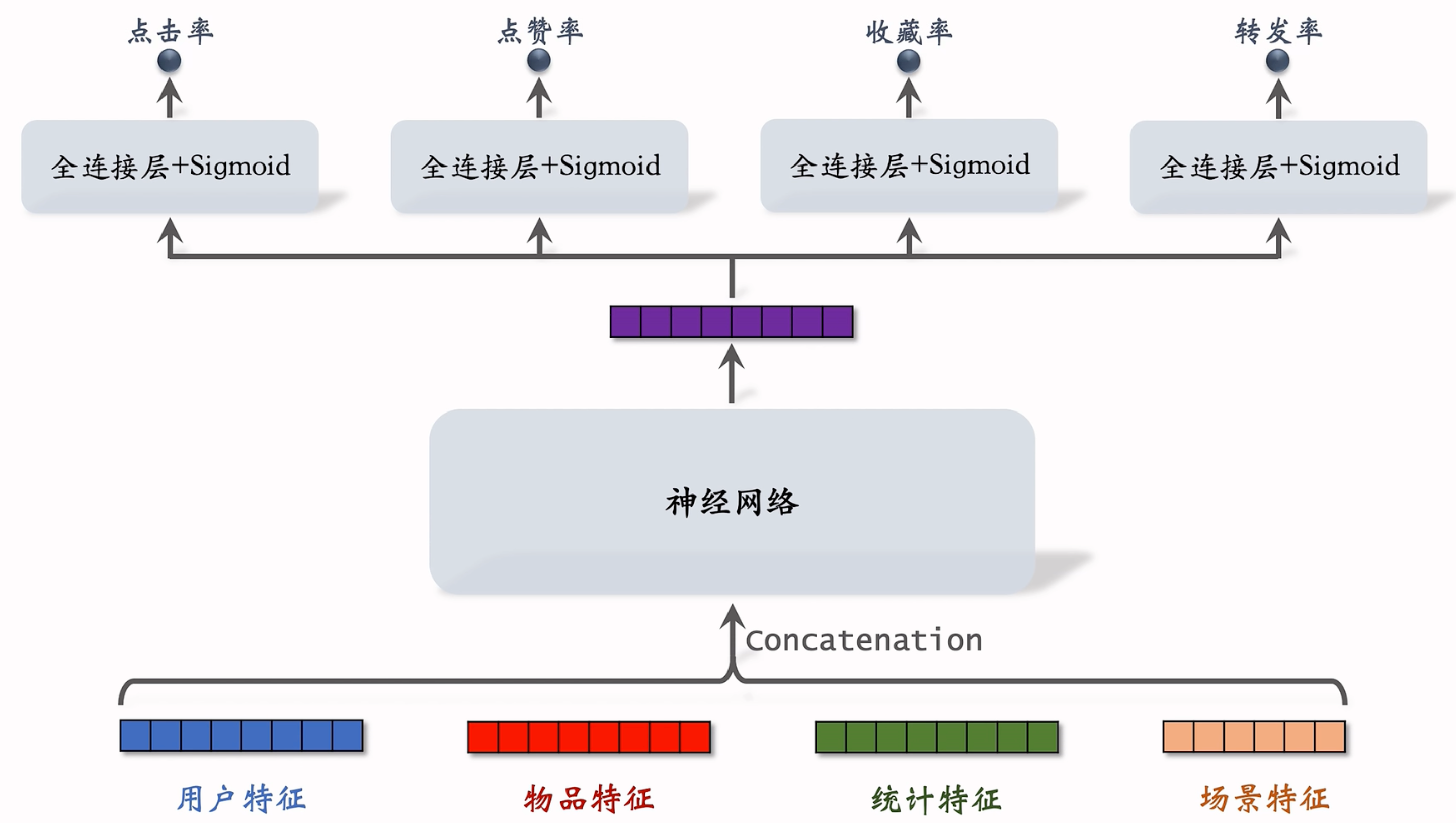
图1. 多目标模型架构(来源:王树森推荐系统课程)
关键行为指标定义
| 指标 | 计算公式 | 业务意义 |
|---|---|---|
| CTR | 点击次数/曝光次数 | 内容基础吸引力 |
| LikeRate | 点赞次数/点击次数 | 内容质量认可度 |
| CollectRate | 收藏次数/点击次数 | 用户长期兴趣强度 |
| ShareRate | 转发次数/点击次数 | 内容传播价值 |
转发行为具有网络效应,能为平台带来跨域流量,是重要的增长杠杆
二、输入特征体系
1. 特征分类
- 用户特征:ID、用户画像
- 物品特征:物品 ID、物品画像、作者信息
- 统计特征:30天窗口的行为统计(曝光、点击、转化)
- 如过去 30 天内用户对物品的曝光次数、点击次数、点赞次数、收藏次数、转发次数等行为数据的统计汇总。
- 物品统计特征:过去 30 天内物品被曝光的总次数、获得的点击次数、点赞次数、收藏次数、转发次数等统计信息。
- 场景特征:时空上下文(地理位置、节假日)
三、训练过程
采用加权多任务损失:
L=∑i=14αi⋅[−yilogpi−(1−yi)log(1−pi)]\mathcal{L} = \sum_{i=1}^4 \alpha_i \cdot [-y_i\log p_i - (1-y_i)\log(1-p_i)] L=i=1∑4αi⋅[−yilogpi−(1−yi)log(1−pi)]

四、负采样与校准技术
类别不平衡问题
以点击率为例,通常每 100 次曝光中仅有约 10 次点击,其余为无点击的负样本,这会导致模型训练时正样本信息被淹没。
| 行为转换 | 典型比例(假设) | 不平衡度 |
|---|---|---|
| 曝光→点击 | 10:90 | 9:1 |
| 点击→点赞 | 10:90 | 9:1 |
负采样解决方案
对负样本进行降采样,仅保留一部分负样本参与训练,使正负样本数量达到相对平衡状态,可减少计算资源消耗并提升模型对正样本特征的学习能力。
-
分层采样策略:
- 保留100%正样本
- 对负样本按比例降采样(采样率α)
- 典型采样率:α ∈ [0.1, 0.3]
-
采样后预估校准:
- 真实点击率:ptrue=n+n++n−p_{\text{true}} = \frac{n_+}{n_+ + n_-}ptrue=n++n−n+
- 采样后预估值:ppred=n+n++α⋅n−p_{\text{pred}} = \frac{n_+}{n_+ + \alpha \cdot n_-}ppred=n++α⋅n−n+
- 校准公式:
ptrue=α⋅ppred(1−ppred)+α⋅ppredp_{\text{true}} = \frac{\alpha \cdot p_{\text{pred}}}{(1 - p_{\text{pred}}) + \alpha \cdot p_{\text{pred}}} ptrue=(1−ppred)+α⋅ppredα⋅ppred
校准操作流程
- 训练阶段->>在线服务: 输出原始预估值p_pred
- 在线服务->>校准模块: 输入p_pred
- 校准模块->>排序模块: 返回ptrue=α⋅ppred/[1−ppred+α⋅ppred]p_{true} = α·p_{pred} / [1-p_{pred} + α·{p_pred}]ptrue=α⋅ppred/[1−ppred+α⋅ppred]
- 排序模块->>推荐结果: 使用校准后分数排序
五、排序与融合策略
一、基础加权融合法
1. 线性加权融合
Score=pclick+w1⋅plike+w2⋅pcollect+w3⋅pshare\text{Score} = p_{click} + w_1 \cdot p_{like} + w_2 \cdot p_{collect} + w_3 \cdot p_{share} Score=pclick+w1⋅plike+w2⋅pcollect+w3⋅pshare
特点:
- 实现简单,计算效率高
- 各指标权重需通过A/B测试调优
- 适合指标间相对独立场景
2. 点击率主导融合
Score=pclick×(1+w1⋅plike+w2⋅pcollect+⋯)\text{Score} = p_{click} \times (1 + w_1 \cdot p_{like} + w_2 \cdot p_{collect} + \cdots) Score=pclick×(1+w1⋅plike+w2⋅pcollect+⋯)
数学解释:
- pclick×1p_{click} \times 1pclick×1:基础点击概率
- pclick×plikep_{click} \times p_{like}pclick×plike:曝光→点击→点赞的联合概率
优势:
- 符合用户行为序列的因果逻辑
- 自动放大高点击内容的次级行为价值
二、工业级融合方案
每个指标的意义:
| 指标 | 业务意义 |
|---|---|
| 点击率 | 基础用户体验 |
| 点赞率 | 内容质量感知 |
| 收藏率 | 长期用户价值 |
| 转发率 | 平台增长杠杆 |
1. 海外短视频平台方案
采用幂次连乘法:
Score=(1+w1⋅ptime)a1×(1+w2⋅plike)a2×⋯\text{Score} = (1 + w_1 \cdot p_{time})^{a_1} \times (1 + w_2 \cdot p_{like})^{a_2} \times \cdots Score=(1+w1⋅ptime)a1×(1+w2⋅plike)a2×⋯
参数说明:
- wiw_iwi:行为权重系数
- aia_iai:非线性放大系数
- ptimep_{time}ptime:预估观看时长(秒)
设计原理:
1 + w*p保证基础分不为零- 幂次运算增强头部效应
- 连乘突出综合体验
2. 国内某短视频方案(排序分转换)
分阶段处理:
-
单指标排序:
- 对每个指标独立排序得到排名rir_iri
-
排名分转换:
f(ri)=wiriai+βif(r_i) = \frac{w_i}{r_i^{a_i} + \beta_i} f(ri)=riai+βiwi -
最终融合:
w1rtimea1+β1+w2rclicka2+β2+w3rlikea3+β3+...\frac{w_1}{r_{time}^{a_1} + \beta_1 } + \frac{w_2}{r_{click}^{a_2} + \beta_2} + \frac{w_3}{r_{like}^{a_3} + \beta_3 } + ... rtimea1+β1w1+rclicka2+β2w2+rlikea3+β3w3+...
关键参数:
| 参数 | 作用 |
|---|---|
| aaa | 头部集中度 |
| β\betaβ | 平滑因子 |
优势:
- 消除不同指标量纲差异
- 自动处理长尾分布
- 增强头部内容区分度
3. 电商平台方案(行为链模型)
用户路径:
融合公式:
GMS=pclicka1×pcarta2×ppaya3×pricea4\text{GMS} = p_{click}^{a1} \times p_{cart}^{a2} \times p_{pay}^{a3} \times \text{price}^{a4} GMS=pclicka1×pcarta2×ppaya3×pricea4
参数设计:
- 当a1=a2=a3=a4=1a1=a2=a3=a4=1a1=a2=a3=a4=1时:
- GMS = 点击率 × 加购率 × 付款率 × 价格
- = 期望GMV(商品交易总额)
三、方案对比
| 方案类型 | 适用场景 | 计算复杂度 |
|---|---|---|
| 线性加权 | 快速迭代 | 低 |
| 点击率主导 | 内容推荐 | 中 |
| 幂次连乘 | 视频/图文 | 高 |
| 排序分转换 | 多目标长尾分布 | 高 |
| 行为链模型 | 电商交易场景 | 中 |
结论:多目标模型通过联合优化多个用户行为目标,显著优于单目标模型,尤其在提升用户长期价值和平台增长方面效果突出。负采样与校准技术有效解决了样本不平衡问题,使模型预估更贴近真实场景。
引用
参考文献:
[1] Shusen Wang. 推荐系统课程. Bilibili, 2022.
[2] Facebook. Practical Lessons from Predicting Clicks. 2014.