ClickHouse 高性能实时分析数据库-物化视图篇
告别等待,秒级响应!这不只是教程,这是你驾驭PB级数据的超能力!我的ClickHouse视频课,凝练十年实战精华,从入门到精通,从单机到集群。点开它,让数据处理速度快到飞起,让你的职业生涯从此开挂!
全套视频教程联系博主
1 写在前面
clickhouse的物化视图你用对了吗???
在数据仓库领域,我们经常会遇到这样的场景:
原始数据量巨大:日志、事件流等数据以极高的速度写入。
查询模式固定:分析师或仪表盘(Dashboard)总是对这些原始数据进行固定的聚合查询,例如:
每分钟的网站访问量 (PV/UV)
每个商品的日销售额
每个接口的平均响应时间
如果每次查询都直接扫描原始数据表,即使 ClickHouse 性能卓越,当数据量达到千亿甚至万亿级别时,查询延迟也会增加,计算资源消耗巨大。
普通视图 (View) 能解决问题吗? 不能。普通视图只是一个查询别名,它不存储任何数据。每次查询视图时,实际上还是在执行视图定义中的那个复杂查询,扫描原始表。
物化视图 (Materialized View) 的诞生 为了解决这个问题,物化视图应运而生。
核心思想:物化视图是一种预计算和持久化存储的机制。它像一个“数据触发器”,当其监控的源表有新数据写入时,它会自动对这些新数据执行一个
SELECT查询,并将结果**物化(存储)**到一个独立的目标表中。后续的查询可以直接访问这个小得多的、预聚合过的目标表,从而实现毫秒级的查询响应。
在 ClickHouse 中,物化视图的概念与其他数据库(如 Oracle, PostgreSQL)有本质区别。理解这一点至关重要。
ClickHouse 物化视图 = 触发器 (Trigger)
你可以把 ClickHouse 的物化视图理解为一个插入触发器。它本身不存储数据,它只是一个数据转换和搬运的规则。
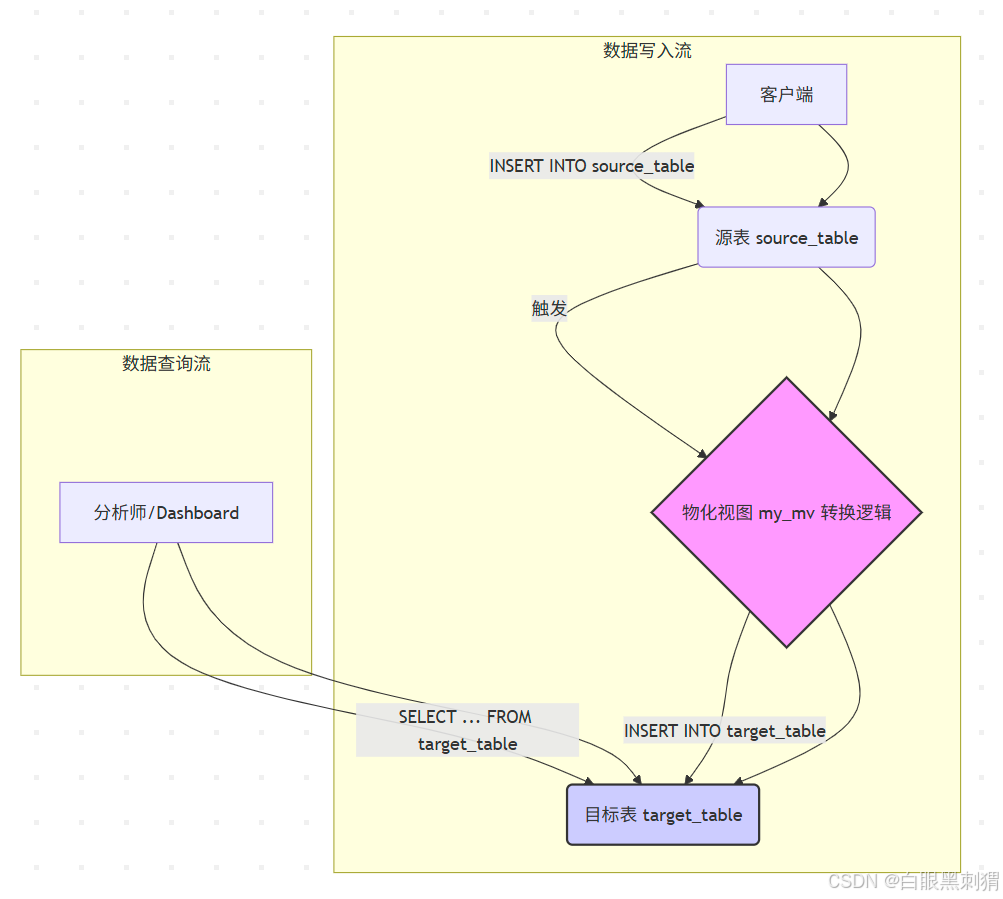
数据写入:当有
INSERT操作将一批数据写入源表 (Source Table) 时。触发执行:该
INSERT操作会自动触发所有监听此源表的物化视图。数据转换:物化视图执行其
AS SELECT ...子句中定义的查询,但只针对刚刚插入的新数据块进行计算。写入目标表:物化视图将转换后的结果集,以
INSERT的方式写入到预先定义好的目标表 (Target Table) 中。查询加速:用户查询时,直接查询这个已经预聚合过的、数据量小得多的目标表,而不是庞大的源表。
重要区别:
物化视图本身 (my_mv): 是一个没有数据的逻辑定义/触发器。
SELECT * FROM my_mv通常是无意义的。目标表 (target_table): 是一个真实的、存储了预计算结果的物理表。我们最终查询的是它。
2 使用示例
场景:实时统计网站每分钟的页面浏览量(PV)和独立访客数(UV)。
-- 存储原始访问日志
CREATE TABLE visits_raw
(`timestamp` DateTime,`url` String,`user_id` String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (timestamp, url);INSERT INTO visits_raw (timestamp, url, user_id) VALUES
(now(), '/page/1', 'user-a'),
(now(), '/page/2', 'user-b'),
(now(), '/page/1', 'user-a'),
(now() + 2, '/page/3', 'user-c');目标表用于存储预聚合的结果。这里的表引擎选择至关重要。对于聚合场景,AggregatingMergeTree 是最佳选择。
AggregatingMergeTree 引擎: 它专门用于增量聚合。它会将
SELECT查询中带有-State后缀的聚合函数(如countState,uniqState)的中间状态存储起来。在查询时,再使用-Merge后缀的函数(如countMerge,uniqMerge)来完成最终计算。这使得后台合并和最终查询都极为高效。
-- 存储每分钟的 PV/UV 聚合结果
CREATE TABLE visits_agg_daily
(`minute` DateTime, -- 聚合时间粒度:分钟`pv` AggregateFunction(count), -- 存储 PV 的中间状态`uv` AggregateFunction(uniq, String) -- 存储 UV 的中间状态
)
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMMDD(minute)
ORDER BY minute;现在,我们创建物化视图,将源表和目标表连接起来。
CREATE MATERIALIZED VIEW visits_mv TO visits_agg_daily -- 关键:指定数据流向的目标表
AS
SELECTtoStartOfMinute(timestamp) AS minute, -- 按分钟聚合countState() AS pv, -- 计算 PV 的中间状态uniqState(user_id) AS uv -- 计算 UV 的中间状态
FROMvisits_raw -- 关键:指定监听的源表
GROUP BYminute;代码解析:
TO visits_agg_daily: 明确指出,计算结果将写入visits_agg_daily表。AS SELECT ... FROM visits_raw: 定义了转换逻辑。当visits_raw插入新数据时,就执行这个SELECT。toStartOfMinute(timestamp): 将时间戳对齐到分钟级别。countState(),uniqState(user_id): 使用-State函数,生成与AggregatingMergeTree兼容的聚合中间态。GROUP BY minute: 按分钟进行聚合。
正确的查询方式
SELECTminute,countMerge(pv) AS page_views,uniqMerge(uv) AS unique_visitors
FROMvisits_agg_daily
GROUP BYminute
ORDER BYminute;结果:
| minute | page_views | unique_visitors |
| 2023/11/20 10:30 | 4 | 3 |
至此,我们成功搭建了一个全自动的实时聚合系统! 后续任何写入 visits_raw 的数据,都会被 visits_mv 自动处理并更新到 visits_agg_daily 中。分析查询只需要访问 visits_agg_daily 即可。物化视图只对创建之后新插入的数据生效。如果源表在创建物化视图之前就已经存在大量数据,怎么办?
使用 POPULATE 关键字!它会在创建视图的同时,将源表中的存量数据也进行一次转换并插入目标表。
CREATE MATERIALIZED VIEW visits_mv TO visits_agg_daily
POPULATE -- <<<<<<<<<<<<<<<<
AS
SELECT ...AggregatingMergeTree: 最常用,适用于需要复杂聚合(如uniq,avg,quantile)且要求高性能的场景。SummingMergeTree: 如果你的聚合需求只有“求和”与“计数”,可以使用它。它会自动合并具有相同排序键的行,将度量列相加。比AggregatingMergeTree更简单。普通
MergeTree: 如果你不需要预聚合,只是想对数据进行ETL(比如清洗、转换、拆分列),可以将目标表设置为普通MergeTree。删除物化视图:
DROP VIEW visits_mv;注意:删除物化视图不会删除目标表
visits_agg_daily。它只是切断了自动的数据流。目标表中的数据仍然存在。
暂停/恢复:
DETACH TABLE visits_mv;可以临时禁用物化视图。ATTACH TABLE visits_mv;可以重新激活它。
你可以创建一个物化视图,其目标表同时是另一个物化视图的源表,形成数据处理流水线(Pipeline)
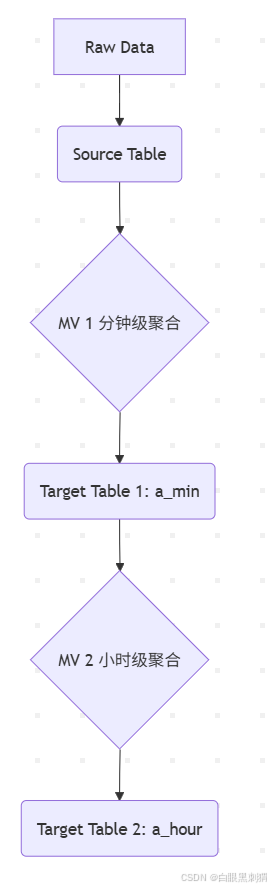
MV1从Source Table读取数据,聚合后写入a_min。MV2监听a_min,当a_min有新数据时,MV2将其进一步聚合到a_hour。
总结
| 特性 | 普通视图 (View) | 物化视图 (Materialized View) |
| 存储数据 | 否,只是查询别名 | 否(本身是触发器),但其结果存储在物理目标表中 |
| 数据来源 | 查询时实时计算 | 源表 INSERT 时触发,增量计算 |
| 查询性能 | 等同于其定义的复杂查询 | 极高,直接查询预计算好的小表 |
| 数据新鲜度 | 实时 | 准实时(有微小延迟) |
| 资源消耗 | 查询时消耗大 | 写入时有额外计算开销,查询时消耗小 |
| 核心作用 | 简化复杂查询,权限控制 | 查询加速,实时聚合,数据ETL |
何时使用物化视图?
当你有高频的、固定的聚合查询,且无法接受直接扫描原始大表的延迟时。
当需要构建实时数据看板或实时报表系统时。
当需要对写入的数据流进行持续的ETL转换时。