ICCV 2025 | CWNet: Causal Wavelet Network for Low-Light Image Enhancement

标题:CWNet: Causal Wavelet Network for Low-Light Image Enhancement
作者:Tongshun Zhang, Pingping Liu, Yubing Lu, Mengen Cai, Zijian Zhang, Zhe Zhang, Qiuzhan Zhou
单位:College of Computer Science and Technology, Jilin University;Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education;College of Communication Engineering, Jilin University
论文链接:https://arxiv.org/html/2507.10689
代码链接:https://github.com/tszhang23/CWNet
传统低光照图像增强(Low-Light Image Enhancement,LLIE)方法主要关注均匀亮度调整,往往忽视实例级语义信息及不同特征的内在特性。
为克服这些局限,本文提出CWNet(Causal Wavelet Network),一种利用小波变换实现因果推理的新颖架构。
具体而言,方法包含两大核心组件:1)受因果中的干预的概念(the concept of intervention in causality)启发,从因果推理(causal reasoning)视角揭示低光照增强中的潜在因果关系;全局上采用度量学习策略保证因果嵌入遵循因果原则,将因果因子与非因果混淆因子分离并关注因果因子不变性;局部上引入实例级CLIP语义损失以精细保持因果因子一致性。2)基于因果分析,提出基于小波变换的主干网络,优化频域信息恢复,确保针对小波变换特有属性的精确增强。
大量实验表明,CWNet在多个数据集上显著优于现有最先进方法,体现其在多样场景下的鲁棒性能。
研究背景
低光照图像增强是计算机视觉的关键任务,旨在解决昏暗与细节丢失导致的图像质量下降。
- 传统方法如gamma correction、Retinex theory、histogram equalization难以应对非均匀光照与极端黑暗。而深度学习方法虽提升适应性,但在特征建模与语义信息利用上仍有不足。例如全局提亮时人脸过曝(颜色不一致),深色纹理被当作噪声抹除(语义不一致)。
- 频域方法通过分离与增强高低频信息改善细节与亮度,但把高低频当作“同质”信号统一放大,仍无法回答“哪些频率分量真正携带语义”。
- 保持颜色与语义一致性仍是重大挑战,许多先进方法忽视这些方面,导致视觉不自然或语义不准确。
研究动机
论文围绕两大问题展开:
- 如何在改善光照条件的同时确保颜色与语义信息一致性?现有方法依赖颜色直方图损失或下游语义分割一致性损失,但主要关注全局一致性,缺乏实例级一致性保证。
- 如何建立充分利用频域特征的鲁棒模型?Fourier transform捕获全局信息却缺乏空间局部性;wavelet transform具备空间局部性却未充分挖掘频域特性。
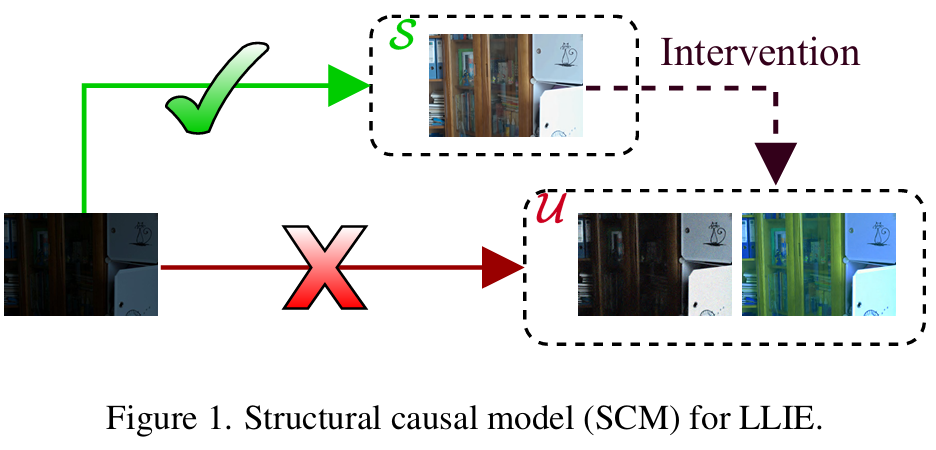
为此,作者提出基于因果推断的Structural Causal Model(SCM)【causality for machine learning】。在这样的因果框架中,把“一致性”转成可学习的目标,将LLIE的核心目标定义为保持因果因子(causal factors,这里指代不随光照变化的语义信息)一致性,过滤非因果因子(non-causal factors,这里指代颜色与亮度异常)。
研究内容
整体框架
CWNet由因果推理(causal inference)与wavelet backbone组成,包含全局级因果度量学习与局部级CLIP语义一致性保持,配合Hierarchical Feature Restoration Block(HFRB)实现频域特征恢复。
因果推理分析
因果干预
为了有效的因果分析,干预必须是有意义且无害的。为此本文参考【Onerestore: A universal restoration frame work for composite degradation】并对正常光的真值图像设计并施加两种退化:
- Light Degradation Intervention:这里使用基于物理的亮度退化模型,对于正常亮度的图像III,生成的亮度退化版本为Il=ILLγ+εI_{l}=\frac{I}{L}L^{\gamma}+\varepsilonIl=LILγ+ε
- LLL为LIME【Lime: Low-light image enhancement via illumination map estimation】生成的亮度图。
- γ∈[2,5]\gamma\in[2,5]γ∈[2,5]控制退化的程度。
- ε∼N(0,σ2),−σ∈[0.03,0.08]\varepsilon\sim\mathcal{N}(0,\sigma^2), - \sigma\in[0.03,0.08]ε∼N(0,σ2),−σ∈[0.03,0.08]是具有非标准方差的高斯噪声。
- Color Anomaly Intervention:为了评估颜色失真的影响,对真值图像施加变换得到生成图像Ic=ΔH(I)+ΔS(I)+∑K=R,G,BΔK(I)+εI_{c}=\Delta H(I)+\Delta S(I)+\sum_{K=R,G,B}\Delta K(I)+\varepsilonIc=ΔH(I)+ΔS(I)+∑K=R,G,BΔK(I)+ε。
- ΔH∈[−30,30]\Delta H\in[-30,30]ΔH∈[−30,30]表示色相偏移。
- ΔS∈[−50,50]\Delta S\in[-50,50]ΔS∈[−50,50]表示饱和度偏移。
- ΔK∈[−50,50]\Delta K\in[-50,50]ΔK∈[−50,50]表示RGB通道偏移。
Average Treatment Effect(ATE)分析

这里是为了定量评估干预对不同图像区域的影响。对于特征或区域pip_{i}pi,定义ATE为:ϕF[pi]=E{MR(I)}−Et∈{1:T}{MR(I∣do(pi=xt))}\phi_{\mathcal{F}}[p_{i}]=\mathbb{E}\{\mathcal{M}_{R}(I)\}-\mathbb{E}_{t\in\{1:T\}}\{\mathcal{M}_{R}(I|do(p_{i}=x_{t}))\}ϕF[pi]=E{MR(I)}−Et∈{1:T}{MR(I∣do(pi=xt))}。
- 其中MR(I)\mathcal{M}_{R}(I)MR(I)为质量指标PSNR。
- I∣do(pi=xt)I|do(p_{i}=x_{t})I∣do(pi=xt)表示在强度xtx_{t}xt下施加干预(光照退化、颜色异常或噪声)的图像。
- 进一步通过ϕF(I)={ϕF∣pi}i=1N\phi_{\mathcal{F}}(I) = \{\phi_{\mathcal{F}} | p_{i}\}_{i=1}^{N}ϕF(I)={ϕF∣pi}i=1N来生成归因图,突出最受干预影响的区域。
因果引导的度量学习
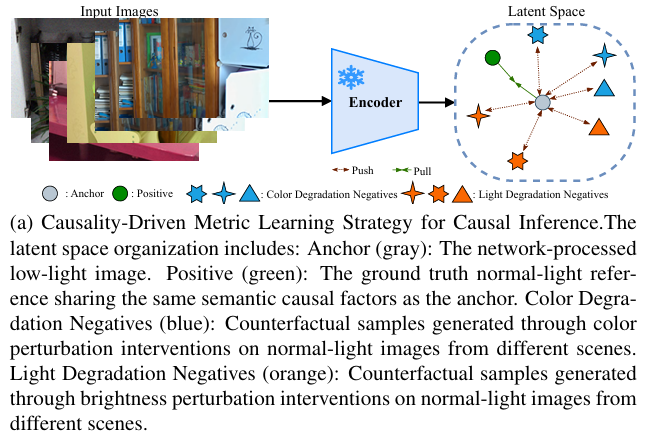
本文引入了一种用于度量学习的样本挖掘策略,以分离光照不变语义特征(因果因子)与退化相关因子(非因果因子)。该策略故意排除其他低光图像(防止因果与非因果特征混淆),而是强制模型区分基本语义差异(不同因果因子),即使非因果特征可能与锚点相似:
- 处理后的低光图像作为锚点,与其对应的正常光参考作为正样本。
- 低光图像是参考在亮度和颜色(非因果因子)上的极度退化实例,形成固有的难正样本对,迫使度量学习关注语义不变性。
- 通过对不同场景正常光图像施加颜色和亮度扰动来构建反事实负样本。
具体而言,以低光照图像为anchor,正常光照图像为正样本,跨场景颜色与亮度扰动后的低光照图像为负样本,定义损失:
Lca(Fp,F^,{Fl},{Fc})=L1(Fp,F^)ξ(∑l=1LL1(Fl,F^)+∑c=1CL1(Fc,F^))
\mathcal{L}_{\mathrm{ca}}(F_p, \hat{F}, \{F_l\}, \{F_c\}) = \frac{\mathcal{L}_1(F_p, \hat{F})}{\xi\left(\sum_{l=1}^L \mathcal{L}_1(F_l, \hat{F}) + \sum_{c=1}^C \mathcal{L}_1(F_c, \hat{F})\right)}
Lca(Fp,F^,{Fl},{Fc})=ξ(∑l=1LL1(Fl,F^)+∑c=1CL1(Fc,F^))L1(Fp,F^)
- Fp,F^,{Fl},{Fc}F_p, \hat{F}, \{F_l\}, \{F_c\}Fp,F^,{Fl},{Fc} 分别为正样本、锚点、光照负样本和颜色异常负样本的特征表示。
- 超参数 ξ=1L+C\xi = \frac{1}{L+C}ξ=L+C1 归一化光照和颜色负样本的贡献。
- LLL 和 CCC 为样本总数。
网络反向传播时,只有保持语义一致、同时抑制光照/颜色扰动的特征才能降低损失 ⇒ 隐空间里非因果因子被压缩,因果因子被显式对齐。
基于CLIP的实例级因果一致性
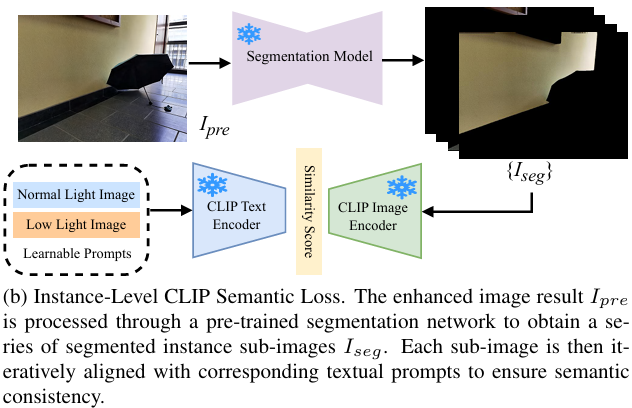
尽管度量学习方法确保全局因果一致性,ATE 分析发现退化敏感性存在显著区域特异性差异。
为了维护局部语义完整性,这里引入基于 CLIP 的实例级因果一致性模块。其中使用在 PASCAL-Context 上预训练的 HRNet 提取语义实例图。这些实例图与文本提示一起由 CLIP 编码器处理,以评估语义一致性:
y^=1K∑k=1Kecos(Φimage(Isegk),Φtext(Tlow))∑i∈{low,normal}ecos(Φimage(Isegk),Φtext(Ti)),
\hat{y} = \frac{1}{K} \sum_{k=1}^K \frac{e^{\cos(\Phi_{\mathrm{image}}(I_{\mathrm{seg}}^k), \Phi_{\text{text}}(T_{\mathrm{low}}))}}{\sum_{i \in \{\mathrm{low}, \mathrm{normal}\}} e^{\cos(\Phi_{\mathrm{image}}(I_{\mathrm{seg}}^k), \Phi_{\text{text}}(T_i))}},
y^=K1k=1∑K∑i∈{low,normal}ecos(Φimage(Isegk),Φtext(Ti))ecos(Φimage(Isegk),Φtext(Tlow)),
- KKK 为子实例图数量。
- IsegkI_{\mathrm{seg}}^kIsegk 为子实例图。
训练过程中使用交叉熵损失进行优化:
Lsem=−(ylog(y^)+(1−y)log(1−y^))\mathcal{L}_{\mathrm{sem}} = -\left(y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})\right)Lsem=−(ylog(y^)+(1−y)log(1−y^))
- yyy 为当前图像标签,0 表示低光图像,1 表示正常光图像。
通过最小化损失,强制每个实例在增强后必须逼近“正常光语义” ⇒ 像素级因果因子被锁定。
Causal Wavelet Network(CWNet)
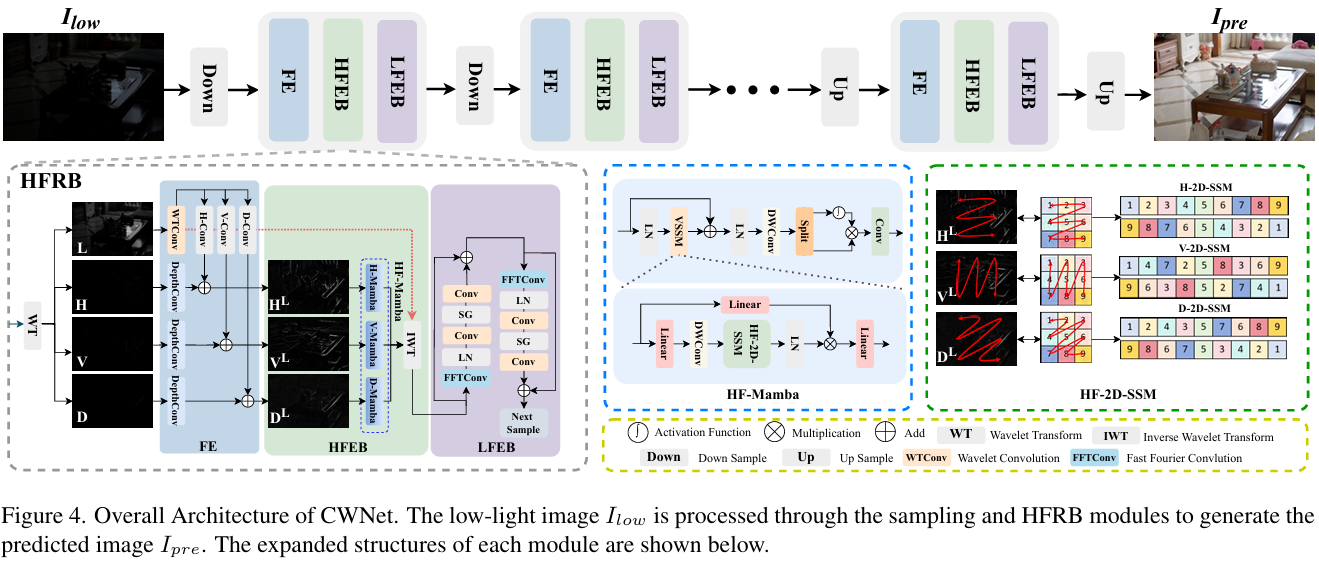
CWNet 架构如图 4 所示,由上下采样层及 FE、HFEB 和 LFEB组成。
Feature Extraction(FE)
对低光图像输入 Ilow∈RH×W×CI_{\mathrm{low}} \in \mathbb{R}^{H \times W \times C}Ilow∈RH×W×C使用小波变换(WT)分解为四个不同频率子带:{L,H,V,D}=WT(Ilow)\{L, H, V, D\} = \text{WT}(I_{\mathrm{low}}){L,H,V,D}=WT(Ilow),其中L,H,V,D∈RH2×W2×CL, H, V, D \in \mathbb{R}^{\frac{H}{2} \times \frac{W}{2} \times C}L,H,V,D∈R2H×2W×C 分别表示低频分量,以及水平、垂直和对角高频分量。同时图像可以通过逆小波变换(IWT)从这些子带重建:Ilow=IWT{L,H,V,D}I_{\mathrm{low}} = \text{IWT}\{L, H, V, D\}Ilow=IWT{L,H,V,D}。
高频特征使用深度可分离卷积获得,低频特征则使用 WTConv 【Wavelet convolutions for large receptive fields】。 WTConv 层在不增加参数复杂度的情况下实现更大感受野,对捕捉低频信息至关重要。研究【 Low-light image enhancement with wavelet-based diffusion models,Wave-mamba: Waveletstate space modelforultra-high definition low-light image enhancement】表明大多数信息位于低频分量,而高频细节在低光场景中较不敏感。为了提高提取效果,这里使用三个与高频方向对齐的卷积核。提取过程形式化如下:
L′=WTConv(L),HL=DepthConv(H)+H-Conv(L′),VL=DepthConv(V)+V-Conv(L′),DL=DepthConv(D)+D-Conv(L′),
\begin{gathered}
L' = WTConv(L), \\
H^L = DepthConv(H) + H\text{-}Conv(L'), \\
V^L = DepthConv(V) + V\text{-}Conv(L'), \\
D^L = DepthConv(D) + D\text{-}Conv(L'),
\end{gathered}
L′=WTConv(L),HL=DepthConv(H)+H-Conv(L′),VL=DepthConv(V)+V-Conv(L′),DL=DepthConv(D)+D-Conv(L′),
- L′,HL,VL,DLL', H^L, V^L, D^LL′,HL,VL,DL 表示 FE 生成的特征。
- H-Conv,V-Conv,D-ConvH\text{-}Conv, V\text{-}Conv, D\text{-}ConvH-Conv,V-Conv,D-Conv 分别基于特殊构造的卷积核参数来提取水平、垂直和对角特征。
High-Frequency Enhancement Block(HFEB)
SSM 通过线性常微分方程将一维信号转换为输出,通过潜在状态表示。对于输入 x(t)x(t)x(t) 和输出 y(t)y(t)y(t) 的系统,其动力学表示为h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t)h'(t) = Ah(t) + Bx(t), y(t) = Ch(t) + Dx(t)h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t),其中 A,B,C,DA, B, C, DA,B,C,D 为系统参数。离散版本如 Mamba 使用零阶保持 (ZOH) 离散化:{ht′=Aˉht−1+Bˉxtyt=Ch+DxtAˉ=eΔABˉ=(ΔA)−1(eΔA−I)ΔB\begin{cases} h_t' = \bar{A}h_{t-1} + \bar{B}x_t & y_t = Ch + Dx_t \\ \bar{A} = e^{\Delta A} & \bar{B} = (\Delta A)^{-1}(e^{\Delta A} - I)\Delta B \end{cases}{ht′=Aˉht−1+BˉxtAˉ=eΔAyt=Ch+DxtBˉ=(ΔA)−1(eΔA−I)ΔB。其中 Aˉ\bar{A}Aˉ 和 Bˉ\bar{B}Bˉ 是 AAA 和 BBB 的离散对应。
这里基于State Space Models (SSM),提出了专为小波高频分量设计的High-Frequency Mamba (HF-Mamba),包括 D-Mamba、V-Mamba 和 H-Mamba 三部分。它应用层归一化 (LN),然后使用Visual State Space Module (VSSM)与残差结构,最后使用门控前馈网络增强通道信息流。尽管许多现有方法直接从 VMamba 适配 2D-SSM 结构,本文则对小波高频分量进行不同处理。水平扫描使用 H-2D-SSM,垂直扫描使用 V-2D-SSM,对角扫描使用 D-2D-SSM:{H~L=H-2D-SSM(HL)V~L=V-2D-SSM(VL)D~L=D-2D-SSM(DL)\begin{cases} \tilde{H}^L = H\text{-}2D\text{-}SSM(H^L) \\ \tilde{V}^L = V\text{-}2D\text{-}SSM(V^L) \\ \tilde{D}^L = D\text{-}2D\text{-}SSM(D^L) \end{cases}⎩⎨⎧H~L=H-2D-SSM(HL)V~L=V-2D-SSM(VL)D~L=D-2D-SSM(DL)。这种高频特征的一致扫描进一步增强了细节表示。
Low-Frequency Enhancement Block(LFEB)
重建图像Iˉlow=IWT{L′,H~L,V~L,D~L}\bar{I}_{\mathrm{low}}=IWT\{L^{\prime},\tilde{H}^{L},\tilde{V}^{L},\tilde{D}^{L}\}Iˉlow=IWT{L′,H~L,V~L,D~L}后,用Fast Fourier Convolution(FFC)与残差块增强低频全局特征,兼顾大感受野与通道间关联。
先前工作【Incremental transformer structure enhanced image inpainting with mask ing positional encoding,Low-light image enhancement via structure modeling and guidance,Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network】 采用结构引导增强技术优化图像生成,表明精细的高频分量可显著帮助生成和恢复任务,特别是在 LLIE 中。因此 HFEB 后进一步增强高频分量,并使用逆小波变换 (IWT) 后的图像来重建频域:Iˉlow=IWT{L′,H~L,V~L,D~L}\bar{I}_{\mathrm{low}} = IWT\{L', \tilde{H}^L, \tilde{V}^L, \tilde{D}^L\}Iˉlow=IWT{L′,H~L,V~L,D~L}。这里的重建图像 Iˉlow\bar{I}_{\mathrm{low}}Iˉlow 会作为 LFEB 的输入。
提出的LFEB包括两个专为处理低频分量设计的残差块,低频分量需要大感受野。两个块均使用 Fast Fourier Convolution (在神经网络早期层通过通道快速傅里叶变换 (FFT) 集成全局上下文,实现更大感受野)增强全局特征。
- 第一个块应用 5×5 卷积与适当填充扩大感受野以获取局部空间上下文,SimpleGate 机制确保激活期间有效信息流动且损失最小。最后,1×1 卷积恢复特征维度。
- 第二个块强调通道间相关性和特征增强。它通过 1×1 卷积扩展通道维度四倍。SimpleGate 机制选择性保留重要特征,另一个 1×1 卷积将特征压缩回原始通道大小。
在 LFEB 及后续模块之后,低频分量在高频分量指导下细化,产生预测增强输出 IpreI_{\mathrm{pre}}Ipre。
损失函数
整体损失为:
Ltotal=λ1L2+λ2Lssim+λ3Lper+λ4Lca+λ5Lsem
\mathcal{L}_{\mathrm{total}} = \lambda_1 \mathcal{L}_2 + \lambda_2 \mathcal{L}_{\mathrm{ssim}} + \lambda_3 \mathcal{L}_{\mathrm{per}} + \lambda_4 \mathcal{L}_{\mathrm{ca}} + \lambda_5 \mathcal{L}_{\mathrm{sem}}
Ltotal=λ1L2+λ2Lssim+λ3Lper+λ4Lca+λ5Lsem
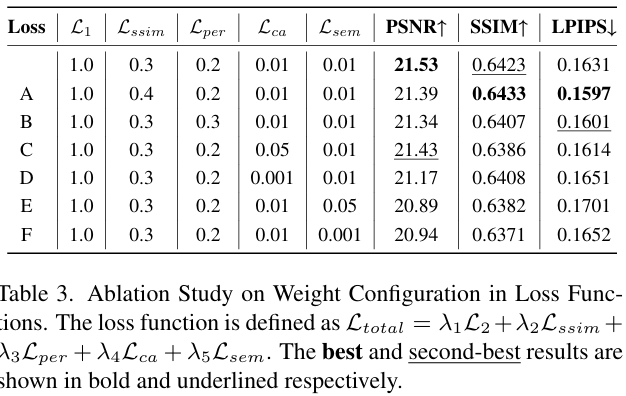
- 损失权重 λ1,λ2,λ3,λ4,λ5=[1.0,0.3,0.2,0.01,0.01]\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5 = [1.0, 0.3, 0.2, 0.01, 0.01]λ1,λ2,λ3,λ4,λ5=[1.0,0.3,0.2,0.01,0.01]。
- L2\mathcal{L}_2L2 表示 ℓ2\ell_2ℓ2 损失。
- Lssim\mathcal{L}_{\mathrm{ssim}}Lssim 为结构相似性损失。
- Lper\mathcal{L}_{\mathrm{per}}Lper 为感知损失,约束 VGG 提取的特征以获得更好视觉效果。
- L2,Lssim\mathcal{L}_2, \mathcal{L}_{\mathrm{ssim}}L2,Lssim 和 Lper\mathcal{L}_{\mathrm{per}}Lper 都是端到端直接约束输出的预测图像 IpreI_{\mathrm{pre}}Ipre 与真值 IgtI_{\mathrm{gt}}Igt。
Causality-Wavelet Connection
CWNet 的可解释性来源于因果与小波结构的有机整合,如图所示。
- 因果视角(Causal Perspective) 本文把场景信息视为 LLIE 中的因果因子;在因果推断的语境下,这相当于“治疗中的测量仪器”(measurement instruments in causal treatment)。通过因果干预确保了增强过程中因果因子的一致性。
- 基于干预的对比度量一致性:只有保持语义一致、同时抑制光照/颜色扰动的特征才能降低损失 ⇒ 隐空间里非因果因子被压缩,因果因子被显式对齐。
- 基于CLIP的实例语义一致性:强制每个实例在增强后必须逼近“正常光语义” ⇒ 像素级因果因子被锁定。
- 小波主干(Wavelet-based Backbone) 为了实现因果因子的一致性,本文设计了小波网络来扮演“治疗中的药物”(medication in treatment)的角色:
- 低频部分通过 LFEB 模块保证颜色与亮度的一致性,专门矫正亮度/颜色,等价于对非因果因子滤波。
- 高频部分借助 HF-Mamba 的方向扫描机制,增强细节建模并提升结构性一致,只增强纹理/边缘,对因果因子放大而几乎不改变均值,避免非因果能量影响。
因此,小波域的物理可解释性与因果推断的语义可解释性被紧密耦合。
要点汇总
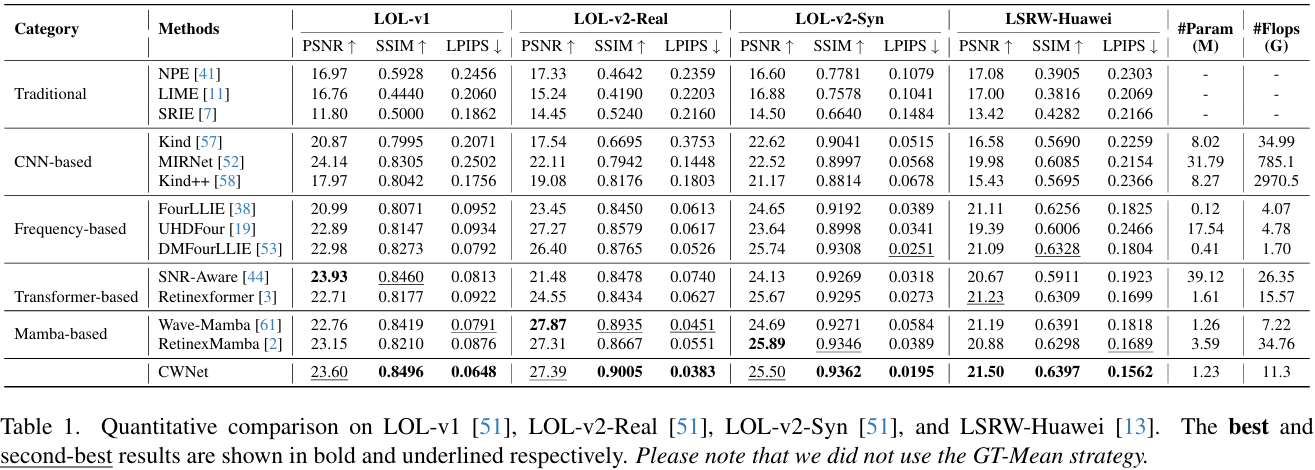
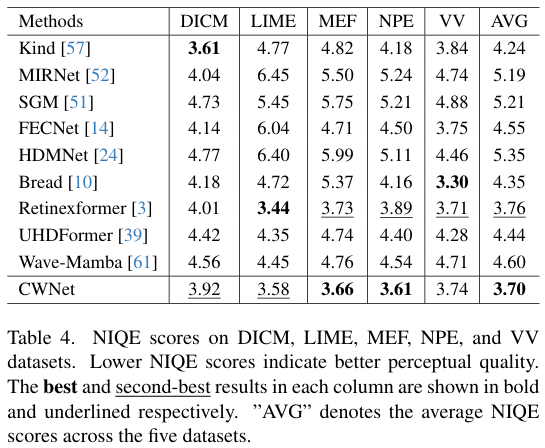

- CWNet在四个公开数据集上取得新的SOTA指标——PSNR、SSIM、LPIPS全面领先,且参数量仅1.23 M,FLOPs仅11.3 G,显著优于MIRNet(31.79 M,785.1 G)等(Table 1)。
- CWNet在跨数据集泛化上表现优异——LOL-v2-Real测试集上的结果是仅用LOL-v1训练后模型的表现。获得27.39 dB PSNR与0.9005 SSIM,超越所有对比方法(Table 1)。
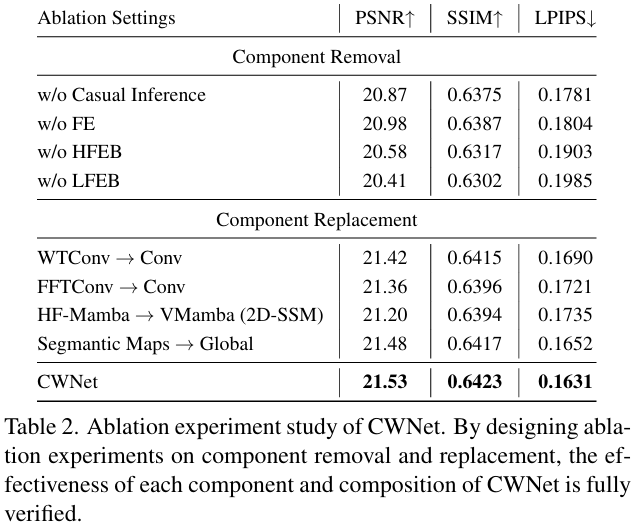
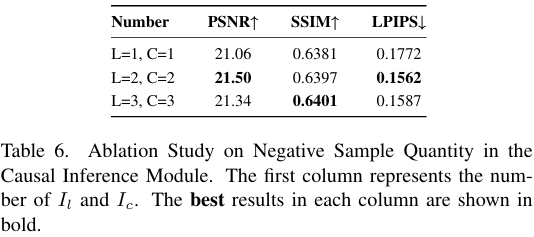
- 因果推理模块通过全局度量学习与实例级CLIP损失提升颜色与语义一致性——去除该模块PSNR从21.53 dB降至20.87 dB,且视觉结果出现亮度与语义不一致(Table 2 & Fig. 9)。
- HFEB采用方向敏感的HF-Mamba模块显著提升高频细节恢复——将HF-Mamba替换为标准VMamba 2D-SSM后PSNR降至21.20 dB,证明其方向扫描机制对wavelet高频分量更有效(Table 2)。
- LFEB通过FFC与残差结构强化低频全局信息,对整体性能贡献最大——移除LFEB后PSNR跌至20.41 dB,是所有消融中下降最剧烈的(Table 2)。
- CWNet增强后的图像在下游目标检测与边缘检测任务中带来显著提升——在DarkFace数据集上,YOLOv5检测置信度提高,误检减少;边缘检测在放大区域更锐利(Fig. 16 & 18)。

- CWNet对多重退化场景(如同时含模糊与雾霾)的恢复质量仍有限——图7显示,CWNet虽能保持颜色与亮度,但细节恢复欠佳,提示未来需研究复合退化处理(4.4)。