国产化PDF处理控件Spire.PDF教程:Python 将 PDF 转换为 Markdown (含批量转换示例)
PDF 是数字文档管理的普遍格式,但其固定布局特性限制了在需要灵活编辑、更新或现代工作流集成场景下的应用。相比之下,Markdown(.md)语法轻量、易读,非常适合网页发布、文档编写和版本控制。
E-iceblue旗下Spire系列产品是国产文档处理领域的优秀产品,支持国产化信创,帮助企业高效构建文档处理的应用程序。本文将介绍如何使用 Spire.PDF for Python 库,在 Python 中高效实现 PDF 到 Markdown 的单文件转换与批量转换。
Spire.PDF for Python免费试用下载
PDF 转 Markdown 的优势
在内容创作与管理中,Markdown 相比 PDF 有显著优势:
- 适配版本控制:可在 Git 中轻松追踪内容变更
- 轻量易读:采用纯文本格式,语法简单直观
- 易编辑性:无需专用软件即可快速修改内容
- 网页集成:原生支持 GitHub、GitLab 等平台以及静态网站生成器(如 Jekyll、Hugo)
Spire.PDF for Python 提供了一套强大的解决方案,能从 PDF 中提取文本和结构信息,同时保留表格、列表、基础样式等关键格式元素。
安装 Python PDF 转换库
要在项目中使用 Spire.PDF for Python,需通过 PyPI 使用 pip 安装该库。打开终端或命令提示符,运行:
pip install Spire.PDF
若需将已安装版本升级至最新版,运行:
pip install --upgrade spire.pdf
使用 Python 将 PDF 转换为 Markdown
以下基本示例展示了如何使用 Python 将 PDF 文件转换为 Markdown(.md)文件。
from spire.pdf.common import *
from spire.pdf import *# 创建PdfDocument类的实例
pdf = PdfDocument()# 加载PDF文档
pdf.LoadFromFile("测试.pdf")# 将PDF转换为Markdown文件
pdf.SaveToFile("PDF转Markdown.md", FileFormat.Markdown)
pdf.Close()
这段Python 代码的逻辑很简单:先加载 PDF 文件,再通过 SaveToFile() 方法将其转为 Markdown 格式,其中 FileFormat.Markdown 参数用于指定输出格式。
转换说明
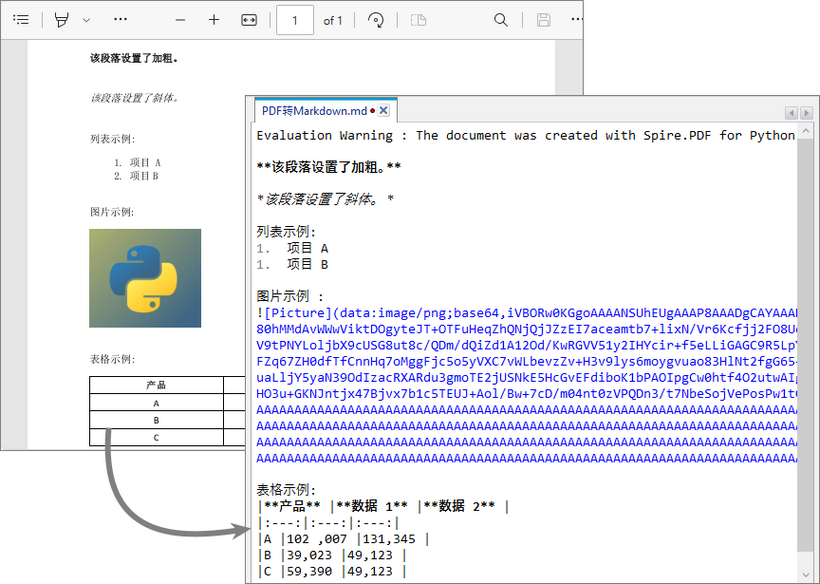
该库从 PDF 中提取文本、图片、表格和基本格式,并将它们转换为 Markdown 语法。
- 文本:保留段落结构与换行格式。
- 图片:PDF 中的图片会转换为 base64 编码的 PNG 格式,并直接嵌入到 Markdown 中。
- 表格:表格数据会转换为 Markdown 表格语法(使用竖线 | 分隔行和列)。
- 样式:粗体、斜体等基础格式会通过 Markdown 语法保留。
转换结果:
使用 Python 批量转换多个 PDF 到 Markdown
以下 Python 代码通过循环将指定目录中的所有 PDF 文件批量转换为 Markdown 格式。
import os
from spire.pdf import *# 配置路径
input_folder = "PDF文件/"
output_folder = "转换结果/"# 创建输出目录
os.makedirs(output_folder, exist_ok=True)# 处理文件夹中的所有PDF
for file_name in os.listdir(input_folder):if file_name.endswith(".pdf"):# 初始化文档pdf = PdfDocument()pdf.LoadFromFile(os.path.join(input_folder, file_name))# 生成输出路径md_name = os.path.splitext(file_name)[0] + ".md"output_path = os.path.join(output_folder, md_name)# 转换为Markdownpdf.SaveToFile(output_path, FileFormat.Markdown)pdf.Close()
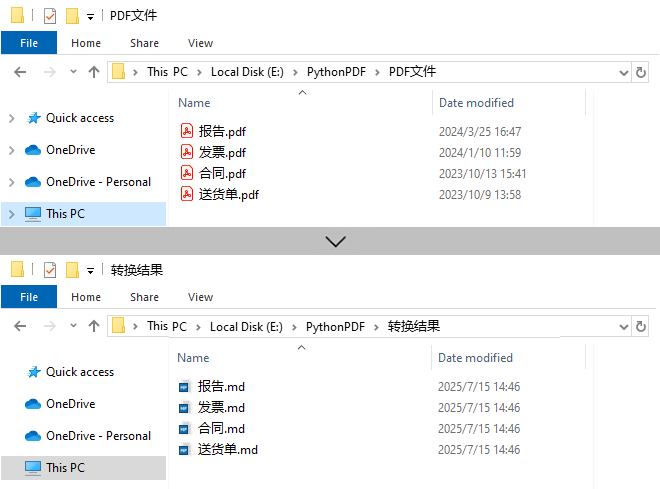
转换特点:
- 批量处理:自动转换文件夹中的所有 PDF,提高批量操作效率。
- 一对一转换:每个 PDF 对应生成一个 Markdown 文件。
- 顺序执行:按文件名字母顺序处理文件。
- 资源管理:转换后立即关闭 PDF 文档,优化资源占用。
转换效果:
常见问题(FAQ)
问题 1:Spire.PDF for Python 是免费的吗?
答:Spire.PDF 提供免费版本,但有使用限制(例如,每次转换最多 3 页)。如需无限制使用,可申请 30 天免费试用授权进行评估。
问题 2:能否将受密码保护的 PDF 文档转换为 Markdown?
答:可以。使用 LoadFromFile 方法时,将密码作为第二个参数传入即可:
pdf.LoadFromFile("ProtectedFile.pdf", "your_password")
问题 3:Spire.PDF 能否将扫描版(图片型) PDF 转换为 Markdown?
答:无法直接转换。该库仅提取文本类内容。对于扫描版 PDF,需先使用 OCR 工具(如 Spire.OCR)将其转为可搜索的 PDF 文档。
结论
Spire.PDF for Python 简化了 PDF 到 Markdown 的转换流程,无论单文件还是批量处理均能轻松应对。其核心优势包括:
- 简单的 API,代码量少
- 精准保留文档结构
- 支持批量转换
- 跨平台兼容性
无论你是迁移文档、处理研究论文,还是搭建内容处理流水线,按照本文中的示例操作,都能高效将静态 PDF 转为灵活可编辑的 Markdown 内容,进而简化工作流程并提高协作效率。