Pandas库全面学习指南(一)
前言
1、Python的Pandas是一个基于Python构建的开源数据分析库,它提供了强大的数据结构和运算功能。
2、Series:一维数组,类似于Numpy中的一维array,但具有索引标签,可以保存不同类型的数据,如字符串、布尔值、数字等。
DataFrame:二维表格型数据结构,与SQL表或Excel工作表类似,每列可以是不同的数据类型(如数值、字符串或日期),并且具有列名和行索引。DataFrame是Pandas的核心数据结构,提供了丰富的数据操作方法。
接下来我们将逐步介绍他的用法:
一.安装pandas库
使用命令 pip install pandas进行安装 ,安装完后导入pandas库,一般简写为pd。
import pandas as pd二、使用Series,创建一维数组
import pandas as pd
s_1 = pd.Series([1,2,3,4,5])
print(s_1)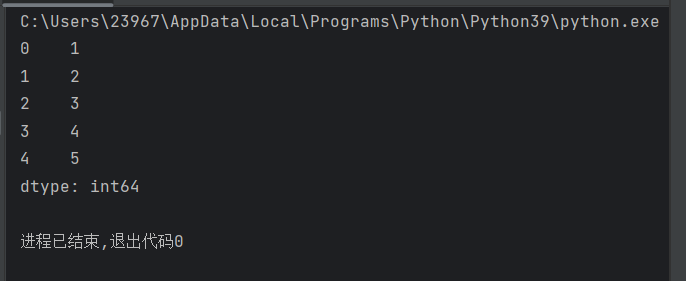
三、index查看下标,values查看下标的值
1、index的输出类似于range:start代表起始标签;stop代表结束标签(不会到这个值,到n-1值);step代表步长。
2、valuses: 直接查看下标的值,记得是从0开始的值
import pandas as pd
s_2 = pd.Series([1,2,3,4,5],index=['a', 'b', 'c', 'd', 'e'])
print(s_2)
print(s_2.index)
print(s_2.values)
四.操作Series数组
1.通过标签访问某个元素或多个元素
import pandas as pd
import pandas as pd
s_1 = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])
print(s_1['d'])
print(s_1['a':'d'])
print(s_1[['a', 'd']])
第一个是访问标签号为d的元素
第二个是访问从标签号从a(包含)到d(包含)的元素
第三个是访问标签号为a和d的元素
2.通过索引号访问某个元素或多个元素
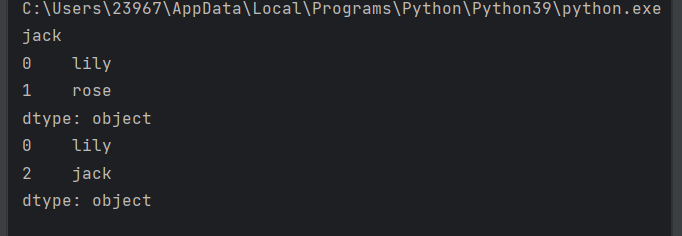
import pandas as pd
s_2 = pd.Series(['lily', 'rose', 'jack'])
"""
(2)通过索引访问
"""
print(s_2[2])
print(s_2[0:2])
print(s_2[[0, 2]])第一个是访问索引号为2的元素
第二个是访问索引号从0(包含)到2(不包含)的元素
第三个是访问索引号为0和2的元素
3.删除标签为()的数据
import pandas as pd
s_1 = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])
s_1 = s_1.drop('a')
print(s_1)删除标签为a的元素
4.判断某个元素是否在数组中,并向数组中加入某个元素。
import pandas as pd
s_1 = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])
print('5' != s_1.values)
s_1[0] = 10
print(s_1)判断5是否在s_1中,并将第0个元素的值改为10
5.创建Series数据
这里的我们所理解的键其实就是数据的标签,大部分的人可能会理解为这里是一个字典或者一个数组,其实都不是,是一个一维数据。
import pandas as pd
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4)
s_4.index = range(0, len(s_4))
print(s_4)创建一个名为dic_1的数据,并将标签号由name1,name2,name3,改为0,1,2。
五、iloc and loc的使用
1、iloc是原下标,也就是默认值,计算机的记忆
2、loc是修改过的下标,我们把他叫作标签,标签是由我们自主给的,计算机并不会自己产生
import pandas as pd
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4.iloc[1])
print(s_4.loc['name1'])六.DataFrame —— 创建二维数组
1.创建DataFrame数据
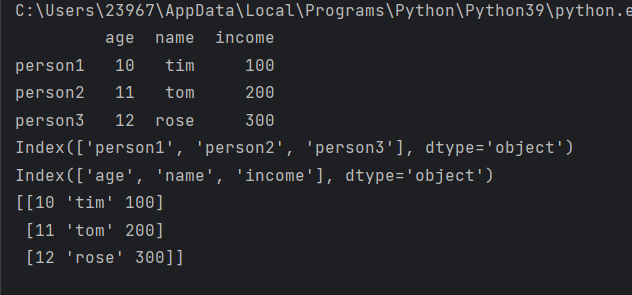
import pandas as pddf_1 = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df_1)
print(df_1.index)
print(df_1.columns)
print(df_1.values)df_1.index为行索引
df_1.columns为列名
df_1.values为值
2.修改列名
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df)
df.columns = range(0, len(df.columns))
print(df)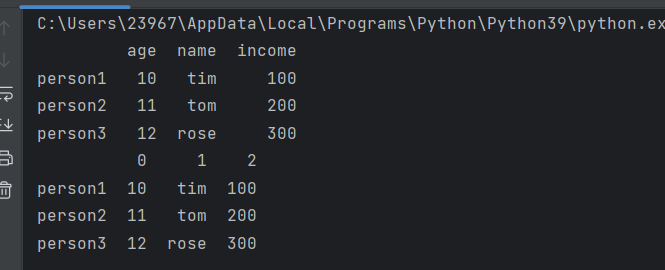
此操作将代码的列名由age,name,income改成了0,1,2
3.修改行名
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df)
df.index = range(0,len(df.index))
print(df)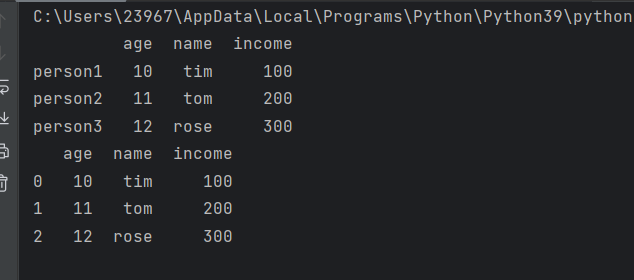
将行名由person1,person2,person3修改为了0,1,2
4.添加一列
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df)
df['pay'] = [20, 30, 40]
print(df)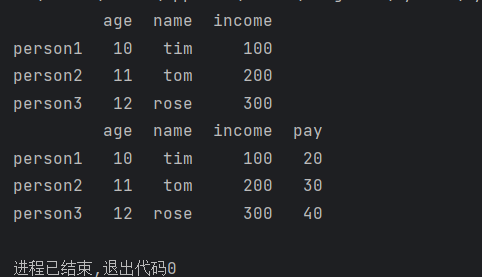
添加了pay这一列数据
5.添加行
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
print(df)
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]
print(df)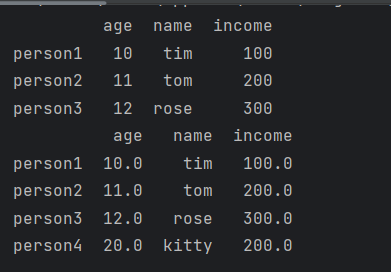
添加了person4这一行数据
6.访问DataFrame
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
#访问某列
print(df.name)
#访问某些列
print(df[['age', 'name']])#访问行
print(df[0:2])
# #使用loc访问
print(df.loc[['person1', 'person3']])
#访问某个值
print(df.loc['person1', 'name'])第一个是打印name这一列
第二个是打印age,name这两列
第三个是打印第0,1行
第四个是打印person1,person3这两行
第五个事打印person1,name中的内容
7.删除列
用drop方法,删除name这一列
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
data = df.drop('name', axis=1, inplace=False)
print(data)axis=1表示沿着列操作,axis=0表示沿着行操作
用del删除age这一列
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
del df['age']
print(df)8.删除行
用drop方法删除person3这一行
import pandas as pd
df = pd.DataFrame({'age':[10,11,12],'name':['tim', 'tom', 'rose'],'income':[100,200,300]},index=['person1', 'person2', 'person3'])
df.drop('person3', axis=0, inplace=True)
print(df)9.对某一行的数据进行排序
import pandas as pddic = {'name': ['kiti', 'beta', 'peter', 'tom'],'age': [20, 18, 35, 21],'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)
df = df.sort_values(by=['age'], ascending=False)
print(df)按照年龄的大小排序,False表示从大到小排序,True表示从小到大排序
10.值的替换
将gender这一行的m用male替换,f用female替换
import pandas as pddic = {'name': ['kiti', 'beta', 'peter', 'tom'],'age': [20, 18, 35, 21],'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)
df['gender'] = df['gender'].replace(['m', 'f'], ['male', 'female'])
print(df)